【跨国数仓迁移最佳实践6】MaxCompute SQL语法及函数功能增强,10万条SQL转写顺利迁移
本系列文章将围绕东南亚头部科技集团的真实迁移历程展开,逐步拆解 BigQuery 迁移至 MaxCompute 过程中的关键挑战与技术创新。本篇为第六篇,MaxCompute SQL语法及函数功能增强。
注:客户背景为东南亚头部科技集团,文中用 GoTerra 表示。
业务背景和痛点
MaxCompute 和BigQuery 都是业界领先的大数据处理平台,而SQL又是用户进行数据分析的主要工具。虽然大数据环境下的SQL语言通常都是基于ANSI SQL标准扩展而来的,但是每一个系统都有自己的方言特色,在一些语言细节和行为上存在着微妙的差别。
GoTerra 业务迁移面临着多方面全方位的挑战,其中最大的挑战之一是10万条SQL的转写问题。这些SQL有一部分复杂度非常高,有一两万行SQL代码,而且其中使用了非常多的比较高级的SQL特性。为了支持SQL转写,我们从多个团队调集了精兵强将,成立了专门的团队进行转换工具的开发工作。但是转换工具并不能解决所有的问题,有一些业务特性的差异必须通过对MaxCompute平台自身能力的增强和调整来实现。
方案概述
为了使用户业务能够平滑地从BigQuery迁移到MaxCompute,首先需要对两者之间的SQL语法差异进行了详细地分析,并基于分析结果进行方案设计。迁移过程中,我们需要重点关注BigQuery中的如下两类特性:
- BigQuery独有特性:这是指在启动业务迁移的时候,MaxCompute还没有提供的语法特性或者功能。针对这一类的特性,需要对MaxCompute进行增强,提供和BigQuery类似的业务功能。
- 两个平台都提供但是具体行为存在差异的那些特性。对于这种情况,MaxCompute为了保持行为兼容,不能直接修改自己的行为。MaxCompute的做法是增加一个odps.sql.bigquery.compatible语法开关,打开这个开关之后的语法行为会尽量和BigQuery保持一致。
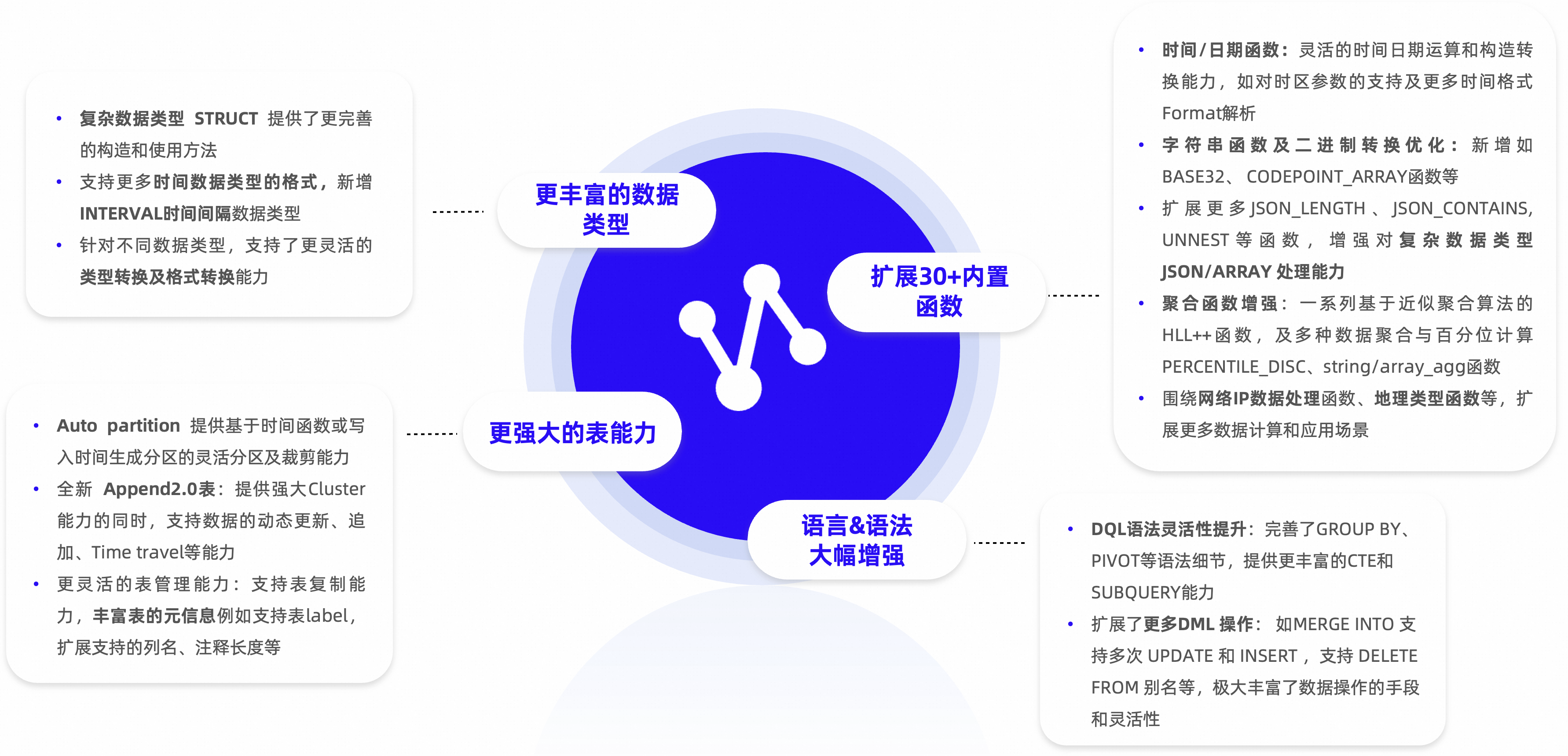
在本次GoTerra 搬栈项目中,MaxCompute SQL主要新增了如下功能:
- auto partition表
- unnest语法
- Delta Table能力增强
a. Merge INTO支持多次update和insert
b. delete from支持别名 - 新增30+内建函数
在bigquery兼容模式下调整如下语法行为以保持和BigQuery一致:
- 列别名解析
- CTE支持输出同名列
- 隐式类型转换规则
- 某些类型转换行为
- pivot列名生成规则
下文中我们选取部分重点内容进行进一步描述
MaxCompute新增功能
一、Auto partition
MaxCompute 和BigQuery 的分区表概念说明
MaxCompute 和BigQuery 都支持分区表,但是它们的底层设计思路有很大的差异。
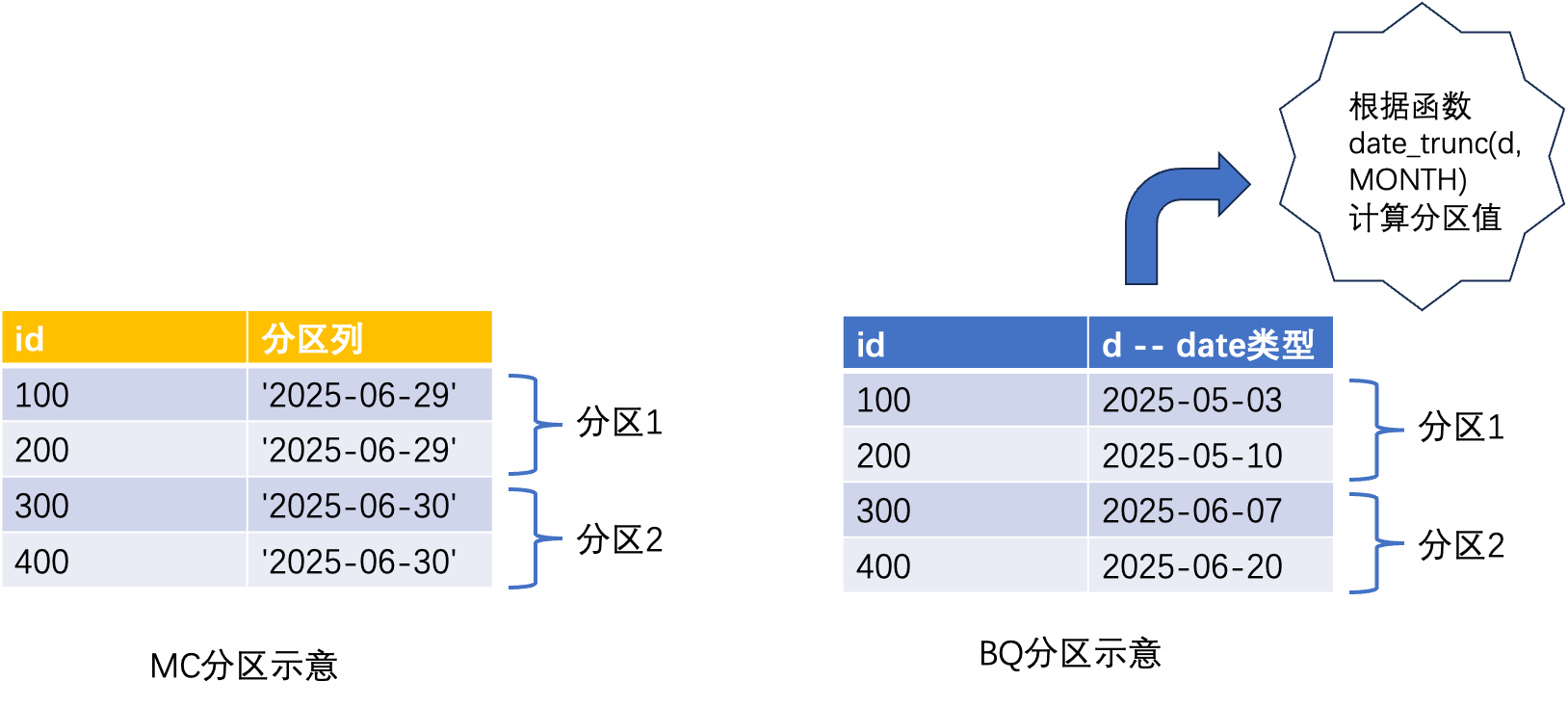
MaxCompute关于分区表的底层设计思路和Hive类似。它允许用户根据一个或多个列对表进行划分,从而将表中的数据分散存储在不同的物理位置上。下面是MaxCompute创建分区表的一个例子:
create table foo_table(id bigint) partitioned by (pt string);假如这个table有两个partition pt='2025-06-29'和pt='2025-06-30',那么这两个partition中的数据,它们的pt列的取值分别为'2025-06-29'和'2025-06-30'。
BigQuery支持时间单位列分区(Time-unit column partitioning)和提取时间分区(Ingestion time partitioning),分区列的数据类型只能是时间类型,包括DATE、TIMESTAMP 或 DATETIME。Time-unit column partitioning表的建表语句如下:
create table my_dataset.foo_table (id int64, d date)
partition by date_trunc(d, MONTH);从这个建表语句中可以看到,它的底层逻辑是先对时间列按照指定的函数进行运算,上面的例子是使用date_trunc函数对时间列进行截取操作,截取的粒度是MONTH,然后根据截取的结果来作为分区的依据。也就是说,对于同一个分区中的数据,它们的时间列的具体取值可能是不同的,但是都处于相同的某个时间区间内。
BigQuery在Time-unit column partitioning的基础上,又提供了Ingestion time partitioning功能。表中有一个名字为_PARTITIONTIME的伪列,标记每行数据的提取时间,它会按照建表语句被截取至相应的边界(例如每小时或每天)。建表语句如下:
create table my_dataset.foo_ingestion_hour (a string)
PARTITION BY TIMESTAMP_TRUNC(_PARTITIONTIME, HOUR);向Ingestion time partitioning表里插入数据的时候,可以指定伪列_PARTITIONTIME的值,也可以不指定。假如不指定,则系统会根据当前时间来自动填充。
-- 插入数据,不指定伪列_PARTITIONTIME的值,由系统自动填充
insert into my_dataset.foo_ingestion_hour(a) values('hi1');-- 插入数据,指定伪列_PARTITIONTIME的值
insert into my_dataset.foo_ingestion_hour(_PARTITIONTIME, a)
values (timestamp '2024-11-02 14:00:00', 'hi2');
Auto partition表
MaxCompute通过Auto partition表来实现和BigQuery Time-unit column partitioning类似的功能。在建表语句中,通过如下语法来创建auto partition表:
AUTO PARTITIONED BY (trunc_time(<col>, <datePart>) [as alias])举例如下:
CREATE TABLE newtable (id INT64, d DATE)
AUTO PARTITIONED BY (trunc_time(d, 'month') as ds);上述建表语句生成的table有3列,分别是id, d和ds。ds是一个string类型的伪列(pseduo-column),它对应于对于列d的取值进行trunc_time运算后的取值。
Ingestion time partition表
MaxCompute在auto partition table的基础上来构建ingestion time partition表的能力。建表的时候通过指定tblproperties来标识ingestion time partition表。建表语句示例如下:
-- 指定分区的粒度是hour
create table foo_ingestion_hourly(_partitiontime timestamp_ntz, a string)
auto partitioned by (trunc_time(_partitiontime, 'hour'))
tblproperties('ingestion_time_partition'='true');-- 指定分区的粒度是day
create table foo_ingestion_daily(_partitiontime timestamp_ntz, a bigint)
auto partitioned by (trunc_time(_partitiontime, 'day'))
tblproperties('ingestion_time_partition'='true');使用如下方式插入数据:
-- 不指定伪列_PARTITIONTIME,由系统自动生成
insert into foo_ingestion_hourly(a) values('hi1');
insert into foo_ingestion_daily(a) values(100);-- 指定伪列_PARTITIONTIME的值
insert into foo_ingestion_hourly(_PARTITIONTIME, a) values (timestamp_ntz '2024-11-02 14:00:00', 'hi2');
insert into foo_ingestion_daily(_PARTITIONTIME, a) values (timestamp_ntz '2024-11-02 00:00:00', 200);auto partition表支持分区裁剪
分区表的主要优势在于它可以显著减少扫描的数据量。例如,在查询时如果指定了某个分区的条件,则只需扫描该分区的数据而不是整个表的数据,从而大大加快了查询速度。
为了下面的举例中描述方便,首先假设建表语句为:
create table table_daily(a bigint, ts timestamp)
auto partitioned by (trunc_time(ts, 'day') as pt);它支持在如下一些条件下进行分区裁剪:
- 使用partition列来进行数据过滤。例如:
select * from table_daily where pt >= '2024-09-14'; - 直接使用时间列来进行数据过滤,例如:
select * from table_daily where ts between timestamp '2024-09-14 00:00:00' and timestamp '2024-09-15 00:00:00'; - 对时间列调用trunc_time函数,并且trunc的粒度(year/month/day/hour)和建表语句对应,支持分区裁剪。例如:
select * from table_daily where trunc_time(ts, 'day') = '2024-09-14'; - 对时间列调用datetrunc函数,并且trunc的粒度(year/month/day/hour)和建表语句对应,支持分区裁剪
select * from table_daily where datetrunc(ts, 'day') = timestamp '2024-09-14 00:00:00'; - 对于其他的时间函数,部分函数支持分区裁剪(具体可以参考后续产品文档的说明),例如:
select * from table_daily where to_date(ts, 'Asia/Jakarta') > date '2024-03-14' - 假如分区裁剪条件涉及到scalar suBigQueryuery,系统会先计算scalar suBigQueryuery的值,然后根据suBigQueryuery的返回值来进行分区裁剪,例如:
-- 系统会先计算select max(ts) from other_table的值,根据所得到的结果来对table_daily进行分区裁剪 select * from table_daily where ts = (select max(ts) from other_table);
二、内建函数能力增强
我们对MaxCompute的内置函数能力进行了扩展,增加新的内建函数,并对已有内建函数的功能进行增强。
时间/时期函数
1. 日期时间构造能力增强,增加新的format,构造的时候允许指定时区信息
- 新增TO_TIME/TO_TIMESTAMP/TO_TIMESTAMP_NTZ/TIMESTAMP函数
- 新增TIME_ADD/TIME_SUB/TIME_DIFF/TIME_TRUNC/FORMAT_TIME函数
- 新增CURRENT_DATE/CURRENT_TIMESTAMP_NTZ/CURRENT_MICROS函数
- 增强TO_DATE/TO_CHAR函数功能
- DATETRUNC/TO_CHAR/TO_DATE/TO_TIMESTAMP_NTZ/TO_TIME/TIMESTAMP支持时区参数
- 增强时区格式
2. 时间函数支持指定更多的处理格式
- DATETRUNC支持quarter/week(weekday)/isoweek参数
- DATEDIFF支持week/week(weekday)/isoweek/ff6参数
- DATEADD支持quarter/week/ff6参数
- LAST_DAY支持year/isoyear/quarter/month/week/week(weekday)/isoweek参数
- WEEKOFYEAR支持week(weekday)参数
- 新增ISOYEAR函数
网络IP数据处理相关函数
- 新增NET_IP_NET_MASK函数
- 新增NET_IP_FROM_STRING/NET_SAFE_IP_FROM_STRING函数
- 新增NET_IP_TO_STRING/NET_IPV4_TO_INT64函数
- 新增NET_HOST/NET_PUBLIC_SUFFIX/NET_REG_DOMAIN函数
字符串及二进制转换
- 新增BASE32函数
- 新增CODEPOINT_ARRAY函数
- 新增SAFE_CONVERT_BYTES_TO_STRING函数
- 新增FORMAT_STRING函数
- 增强REGEXP_EXTRACT函数功能
- REVERSE函数支持输入binary
正则表达式相关函数
- 新增REGEXP_CONTAINS函数
- 增强REGEXP_EXTRACT/REGEXP_EXTRACT_ALL函数功能
Json类型相关函数
- 新增JSON_STRIP_NULLS函数
- 增强JSON_EXTRACT函数功能
- TO_JSON函数对于struct value为NULL时做兼容性处理
聚合函数
- 新增基于近似聚合算法的HLL++函数HLL_COUNT_INIT/HLL_COUNT_MERGE/HLL_COUNT_MERGE_PARTIAL/HLL_COUNT_EXTRACT
- 新增PERCENTILE_CONT/PERCENTILE_DISC函数
- 新增STRING_AGG/ARRAY_AGG函数
- 新增APPROX_QUANTILES函数
地理函数
- 新增ST_S2CELLIDFROMPOINT/ST_S2CELLIDNUMFROMPOINT函数
- ST_UNION函数支持输入array
除了新增函数和增强已有函数来提供和BigQuery相同的计算能力,对于部分具有相近功能的函数,设计了精准的函数转换规则,将两个平台的内建函数进行了一对一映射,确保搬迁后函数行为一致。
三、bigquery兼容模式
通过设置odps.sql.bigquery.compatible的取值,可以调整MaxCompute的行为和BigQuery尽量保持一致,下面举几个例子
对列别名(alias)解析的影响
如下query,MaxCompute默认会报错,因为用户的query中group by a,这里的a是ambiguous,可能是t1.a,也可能是t2.a
-- MaxCompute默认行为
set odps.sql.bigquery.compatible=false;
witht1 as (select 1 a, 2 b),t2 as (select 1 a, 2 b)
select t1.a as a from t1 join t2 on t1.a=t2.a group by a;-- 会报错:
Semantic analysis exception - a is ambiguous, can be both t1.a or t2.a但是同样的query在BigQuery里可以运行。原因是在select语句中有t1.a as a,也就是说为t1.a分配了一个别名a,导致group by a中的a被解释成了t1.a
-- BigQuery的行为:
witht1 as (select 1 a, 2 b),t2 as (select 1 a, 2 b)
select t1.a as a from t1 join t2 on t1.a=t2.a group by a;-- 输出结果
1bigquery兼容模式下,上述query也能在MaxCompute运行
-- MaxCompute在bigquery兼容模式下的行为
set odps.sql.bigquery.compatible=true;
witht1 as (select 1 a, 2 b),t2 as (select 1 a, 2 b)
select t1.a as a from t1 join t2 on t1.a=t2.a group by a;-- 输出
+------------+
| a |
+------------+
| 1 |
+------------+CTE输出支持同名列
如下query,MaxCompute默认会报错。原因是MaxCompute检查出CTE的输出列中有重名,输出了两个列的列名都是a
-- MaxCompute默认行为
set odps.sql.bigquery.compatible=false;
with t as (select 1 as a, 2 as a, 3 as b)
select b from t;-- 会报错:
Semantic analysis exception - column reference xxx is ambiguous但是同样的query在BigQuery里可以运行
-- BigQuery的行为:
with t as (select 1 as a, 2 as a, 3 as b)
select b from t;-- 输出结果
3bigquery兼容模式下,上述query也能在MaxCompute运行
-- MaxCompute在bigquery兼容模式下的行为
set odps.sql.bigquery.compatible=true;
with t as (select 1 as a, 2 as a, 3 as b)
select b from t;-- 输出隐式类型转换规则
如下query,MaxCompute默认会报错。
-- MaxCompute默认行为
set odps.sql.type.system.odps2=true;
set odps.sql.bigquery.compatible=false;select '1970-1-2' + interval 1 day;
-- 报错,原因是类型不匹配,string类型和interval类型之间不能进行相加操作
Semantic analysis exception - invalid operand type(s) STRING,INTERVAL_DAY_TIME for operator '+'但是上述query在BigQuery可以运行,它可以把这个query中的string类型隐式类型转换为date类型,相当于select date '1970-1-2' + interval 1 day;
-- BigQuery的行为:
select '1970-1-2' + interval 1 day;-- 输出结果
1970-01-03T00:00:00bigquery兼容模式下,上述query也能在MaxCompute运行,并且行为和BigQuery保持一致
-- MaxCompute在bigquery兼容模式下的行为
set odps.sql.type.system.odps2=true;
set odps.sql.bigquery.compatible=true;select '1970-1-2' + interval 1 day-- 输出结果
1970-01-03 00:00:00业务价值
经过前文所描述的SQL语法功能增强之后,在bigquery兼容模式下,MaxCompute的语法特性已经能够非常好的兼容BigQuery。配合转换工具,GoTerra项目组顺利地完成了客户SQL的转写工作,有力地支撑客户的业务从GCP平台迁移到MaxCompute平台。整个业务切换中用户的业务运行平稳,用户体验良好。
迁移到MaxCompute之后,配合MaxCompute平台的其他核心业务特性和性能优化措施,SQL的整体查询性能和效率也有了很大的提高,这进一步体现了MaxCompute平台在语法兼容性、高性能和稳定性等诸多方面的整体优势。