深度学习必然用到的概率知识
深度学习作为一种数据驱动的预测技术,本质上是处理不确定性的,而概率论正是刻画和度量不确定性的数学语言。无论是软件测试领域的AI赋能,还是AI模型自身性能评测,都需要通过概率来描述数据、模型与现实世界之间的偶然与必然关系。
1 随机变量与概率分布
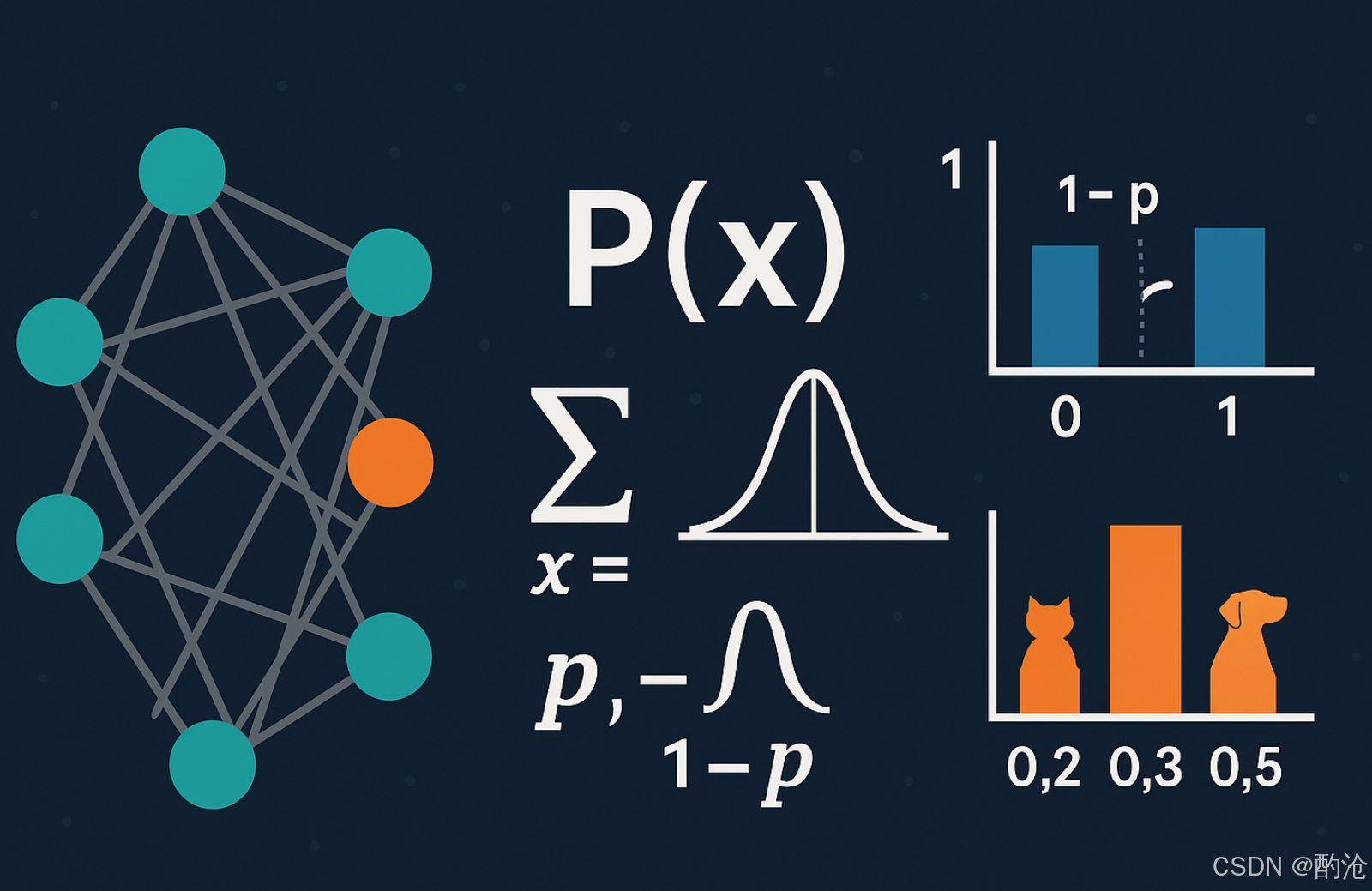
📊 在概率论中,我们用随机变量描述具有不确定性的量,并用概率分布定义其取值的规律。概率分布分为离散分布和连续分布两类。前者例如伯努利分布和多项分布,后者如正态分布。
✅ 伯努利分布:广泛用于二分类任务,例如在图像分类任务中,模型判断图像是猫的概率为ppp,不是猫的概率为1−p1-p1−p。再如Dropout策略以概率ppp随机关闭某些神经元,提升模型泛化性能。
✅ 多项分布:用于多类别问题。一个经典示例是图像分类中输出Softmax概率,如识别动物时,神经网络输出每个类别(猫、狗、兔子)出现的概率,这些概率之和恒等于1。
✅ 均匀分布与正态分布:权重初始化通常服从均值为0、方差为0.01的正态分布(记作w∼N(0,0.01)w \sim N(0, 0.01)w∼N(0,0.01)),通过随机初始化的方式打破神经网络各层神经元间的对称性,帮助网络在优化初期更容易进入有效的学习轨道。
深入思考:不确定性的本质是什么?
世界的复杂性决定了我们不可能完全准确地预知所有事件的结果,这迫使我们寻找一种表达不确定性的方法。概率论正是人类将不确定性变成可计算、可理解、可优化的一种方式,它用数字化的概率分布赋予未知事物以明确的意义。
📊 深入思考:不确定性的本质是什么?世界的复杂性决定了我们不可能完全准确地预知所有事件的结果,这迫使我们寻找一种表达不确定性的方法。概率论正是人类将不确定性变成可计算、可理解、可优化的一种方式,它用数字化的概率分布赋予未知事物以明确的意义。
2 条件概率与贝叶斯公式
深度学习模型学习的核心内容就是条件概率P(Y∣X)P(Y|X)P(Y∣X),即给定输入XXX时输出YYY的概率。例如:
✅ 语言模型预测句子下一个词的概率,即P(next word∣previous words)P(\text{next word}|\text{previous words})P(next word∣previous words)。
- 在自动驾驶场景中,系统给定前方障碍物位置XXX,预测刹车或转向行为YYY的条件概率P(Y∣X)P(Y|X)P(Y∣X)。
条件概率通过链式法则分解复杂问题。贝叶斯公式进一步刻画了条件概率之间的关系:
P(A∣B)=P(B∣A)P(A)P(B) P(A|B) = \frac{P(B|A)P(A)}{P(B)} P(A∣B)=P(B)P(B∣A)P(A)
实践中,朴素贝叶斯分类器广泛应用于垃圾邮件识别;而贝叶斯神经网络则通过参数的先验与后验分布建模不确定性,增强模型的可靠性。
深入思考:贝叶斯公式为何如此重要?
贝叶斯公式从根本上将我们对世界的主观先验知识与客观观测数据连接起来,这种融合主观与客观的能力,是人类理性思考和决策的核心机制,也是深度学习追求泛化能力的本质体现。
📊 深入思考 贝叶斯公式为何如此重要?叶斯公式从根本上将我们对世界的主观先验知识与客观观测数据连接起来,这种融合主观与客观的能力,是人类理性思考和决策的核心机制,也是深度学习追求泛化能力的本质体现。
3 期望、方差与统计特征量
概率论还提供了刻画随机变量分布特征的工具,最基础的是期望(均值)和方差。
✅ 期望(均值) 表示随机变量的平均状态,如通过随机梯度下降法近似模型在全部数据上的损失期望。
✅ 方差 则反映随机变量围绕期望的波动大小,例如在评测不同数据集上的模型性能波动。模型预测的不确定性高,意味着输出概率分布更均匀,方差较大。
例如,一款医疗诊断模型输出患者患病概率为0.9,表示期望较明确,方差低,预测有较高确定性;若输出为0.5,则表明模型高度不确定。
深入思考:为何方差和期望共同构成了稳健的基础?
期望刻画了事物的平均表现,而方差描述了这种表现的不稳定性。只有同时考虑两者,才能全面评估一个模型在现实世界中的实际表现与风险。
📊 深入思考 为何方差和期望共同构成了稳健的基础?期望刻画了事物的平均表现,而方差描述了这种表现的不稳定性。只有同时考虑两者,才能全面评估一个模型在现实世界中的实际表现与风险。
4 最大似然估计与对数似然
最大似然估计(Maximum Likelihood Estimation, MLE) 是统计学中估计模型参数的核心方法,思想是:
『给定一组观测数据,选择一组参数,使这些数据在模型下发生的可能性最大。』
MLE方法的一般步骤如下:
- 首先,假设观测的数据服从某个概率分布;
- 然后,写出所有观测数据的联合概率(称为似然函数);
- 最后,找到使得这个似然函数值最大的参数,即为所需的参数估计值。
由于似然函数通常是多个概率项的连乘,数值计算时容易导致数值溢出或精度损失。因此通常会对似然函数取自然对数,称为对数似然函数:
对数似然函数=logL(θ)=∑i=1nlogP(xi∣θ) \text{对数似然函数} = \log L(\theta) = \sum_{i=1}^{n}\log P(x_i|\theta) 对数似然函数=logL(θ)=i=1∑nlogP(xi∣θ)
这里的θ\thetaθ表示待估计的模型参数,xix_ixi表示第iii个观测数据。
深入思考:概率乘积为何容易崩?
如果每个样本的概率是 0.1,10个样本连乘的总概率是 10−1010^{-10}10−10,非常接近零。这种指数级缩小在浮点数中容易造成下溢。而对数转换将乘法变为加法,保持了梯度信息的同时也更稳定。
📊 深入思考 概率乘积为何容易崩?如果每个样本的概率是 0.1,10个样本连乘的总概率是 10−1010^{-10}10−10,非常接近零。这种指数级缩小在浮点数中容易造成下溢。而对数转换将乘法变为加法,保持了梯度信息的同时也更稳定。
场景:抛硬币问题(伯努利分布)
我们现在有一枚不确定是否公平的硬币,想确定这枚硬币正面朝上的真实概率ppp。
实验过程:
我们抛掷10次,观测到了7次正面,3次反面。
MLE步骤解析:
- 假设概率模型,每次抛掷的结果服从伯努利分布:
- 正面概率为ppp,反面概率为1−p1-p1−p。
则观测到的10次实验数据(7次正面,3次反面)的联合概率为:
L(p)=p7(1−p)3 L(p) = p^7(1-p)^3 L(p)=p7(1−p)3
- 写出对数似然函数
取自然对数将乘法转为加法:
logL(p)=7logp+3log(1−p) \log L(p) = 7\log p + 3\log(1-p) logL(p)=7logp+3log(1−p)
- 求最大似然估计
我们希望找到一个ppp,使得对数似然函数达到最大值,因此需要求导并令导数等于0:
ddplogL(p)=7p−31−p=0 \frac{d}{dp}\log L(p) = \frac{7}{p} - \frac{3}{1-p} = 0 dpdlogL(p)=p7−1−p3=0
解得:
7(1−p)=3p⇒p=710=0.7 7(1-p) = 3p \quad \Rightarrow \quad p = \frac{7}{10} = 0.7 7(1−p)=3p⇒p=107=0.7
所以,通过MLE估计,我们推断这枚硬币的正面概率是0.70.70.7。
直观理解:
MLE的本质是『哪种概率最可能解释我们所看到的数据?』。比如上述例子中,直观来看,抛掷10次,正面朝上了7次,那么硬币更可能是偏向正面的(概率0.70.70.7),而不是完全公平的(概率0.50.50.5)。
深入思考:为什么深度学习普遍采用最大似然估计?
MLE之所以广泛应用,是因为它给出了一个清晰而直观的优化目标:让模型捕捉到数据出现的最可能模式,从而具备泛化到新数据的能力。换句话说,MLE试图反向推理出哪个模型最可能生成了我们看到的数据。
📊 深入思考 为什么深度学习普遍采用最大似然估计?MLE之所以广泛应用,是因为它给出了一个清晰而直观的优化目标:让模型捕捉到数据出现的最可能模式,从而具备泛化到新数据的能力。换句话说,MLE试图反向推理出哪个模型最可能生成了我们看到的数据。
场景:房价预测中的MSE与MLE
我们常在回归任务中使用 均方误差(MSE, Mean Squared Error) 作为损失函数:
MSE=1n∑i=1n(yi−y^i)2 \text{MSE} = \frac{1}{n} \sum_{i=1}^{n} (y_i - \hat{y}_i)^2 MSE=n1i=1∑n(yi−y^i)2
其中,yiy_iyi 是真实标签,y^i\hat{y}_iy^i 是模型预测值。MSE看似只是一个简单的数值偏差度量,但它背后其实隐藏着最大似然估计的原理。
| 面积(平方米)xxx | 价格(万元)yyy |
|---|---|
| 60 | 120 |
| 80 | 150 |
| 100 | 200 |
| 120 | 230 |
| 150 | 300 |
📊 我们要根据房屋的面积xxx预测它的价格yyy。收集了n=5n=5n=5条数据如下:我们使用一个简单的线性回归模型。
y^=wx+b \hat{y} = wx + b y^=wx+b
也就是说,我们想找到一组参数(w,b)(w, b)(w,b),使得预测值y^\hat{y}y^尽可能接近真实值yyy。假设每个真实的价格yiy_iyi是在模型预测值y^i=wxi+b\hat{y}_i = wx_i + by^i=wxi+b的基础上,加上了一点高斯噪声ϵi\epsilon_iϵi,即:
yi=wxi+b+ϵi,ϵi∼N(0,σ2) y_i = wx_i + b + \epsilon_i, \quad \epsilon_i \sim \mathcal{N}(0, \sigma^2) yi=wxi+b+ϵi,ϵi∼N(0,σ2)
即我们认为每个观测yiy_iyi是服从正态分布的随机变量,其均值为预测值y^i\hat{y}_iy^i,方差为常数σ2\sigma^2σ2。
于是,可以写出每个样本点的概率密度函数:
P(yi∣xi;w,b)=12πσ2exp(−(yi−(wxi+b))22σ2) P(y_i|x_i; w, b) = \frac{1}{\sqrt{2\pi\sigma^2}} \exp\left( -\frac{(y_i - (wx_i + b))^2}{2\sigma^2} \right) P(yi∣xi;w,b)=2πσ21exp(−2σ2(yi−(wxi+b))2)
所有样本的联合似然函数为:
L(w,b)=∏i=1nP(yi∣xi;w,b) L(w, b) = \prod_{i=1}^{n} P(y_i|x_i; w, b) L(w,b)=i=1∏nP(yi∣xi;w,b)
对数似然函数为:
logL(w,b)=−n2log(2πσ2)−12σ2∑i=1n(yi−(wxi+b))2 \log L(w, b) = -\frac{n}{2} \log(2\pi\sigma^2) - \frac{1}{2\sigma^2} \sum_{i=1}^{n} (y_i - (wx_i + b))^2 logL(w,b)=−2nlog(2πσ2)−2σ21i=1∑n(yi−(wxi+b))2
由于第一个项是常数,最大化对数似然函数等价于最小化误差平方和:这正是最小化MSE的目标函数!
minw,b∑i=1n(yi−(wxi+b))2 \min_{w,b} \sum_{i=1}^{n} (y_i - (wx_i + b))^2 w,bmini=1∑n(yi−(wxi+b))2
直观理解,我们假设了模型预测值附近是最可能出现真实标签的地方,而这个附近是用正态分布来度量的。
- 如果一个点的误差很大(比如预测的是200,但实际是120),它在高斯分布中出现的概率很小,对似然函数的贡献也小;
- 所以,最大化似然 = 减小误差 = MSE最小化。
深入思考:模型训练真的只是在拟合函数吗?
如果我们只是简单地让预测值逼近标签,可能看起来只是在画一条最接近的线。但从最大似然的角度来看,我们实际上是在假设一种现实生成数据的机制,并找到最有可能导致观测数据的参数组合。这种从数据反推世界的方式,让机器学习更接近科学建模本身的过程。
📊 深入思考 模型训练真的只是在拟合函数吗?如果我们只是简单地让预测值逼近标签,可能看起来只是在画一条最接近的线。但从最大似然的角度来看,我们实际上是在假设一种现实生成数据的机制,并找到最有可能导致观测数据的参数组合。这种从数据反推世界的方式,让机器学习更接近科学建模本身的过程。
5 概率在AI测试中的应用
概率论在实际中广泛应用,例如:
-
模型评测中使用ROC曲线和AUC指标来评价二分类模型的整体预测性能。
-
在AI驱动的测试用例生成中,通过模型输出的概率分布进行随机抽样,生成多样化的测试数据,以覆盖更多的边界场景。
例如使用大语言模型(如GPT-4)生成测试用例,通过调整采样温度控制生成的随机性,以概率的形式确保测试覆盖各种可能情况。
深入思考:概率如何赋予AI探索世界的能力?
通过概率抽样,我们能够跳出确定性规则的束缚,让AI以类似人类想象和探索的方式发现潜在问题和未知情况,从而显著提升测试覆盖率与发现异常的能力。
📊 深入思考 概率如何赋予AI探索世界的能力?通过概率抽样,我们能够跳出确定性规则的束缚,让AI以类似人类想象和探索的方式发现潜在问题和未知情况,从而显著提升测试覆盖率与发现异常的能力。