视觉语言导航(6)——Speaker-Follower模型 数据增强 混合学习 CLIP 3.1后半段
这是课上做的笔记,因此很多记得比较急,之后会逐步完善,每节课的逻辑流程写在大纲部分。
SF模型
为什么?
如何实现的?
这就像老师让学生复述课文,来检查他是否真的听懂了。
什么问题?——语义对齐
人类与机器的“房间计数”可能根本不在一个频道上
举个例子:
指令:“从厨房出发,穿过客厅,进入第二个卧室。”
🔹 你的理解(人类):
- “第二个卧室” = 从起点开始,按路径顺序数过来的第二个卧室。
- 或者 = 房子平面图上的“主卧”和“次卧”中的“第二个”。
- 甚至可能是:“带书桌的那个卧室”,你心里知道那是“第二个”。
🔹 机器的理解(纯数据驱动):
- 它没有“顺序”概念,除非被训练过。
- 它看到两个看起来都很像的卧室,它只能靠细微视觉差异(床的大小、窗帘颜色)或路径历史来判断。
- 更糟的是:如果训练数据中“第二个卧室”总是带双人床,它就学会了“双人床 ⇒ 第二个卧室”,哪怕这次不是。
👉 所以,“第二个”这个序数词,在人类心中是动态的、基于路径的;在机器眼中,可能是一个静态的视觉模式匹配结果。
这就是所谓的 “语义鸿沟”(Semantics Gap)。
🧩 二、为什么这个问题如此难?
语言是模糊的、上下文依赖的
- “第二个房间”可能指:
- 第二个经过的房间
- 第二个打开的房间
- 第二个有床的房间
- 甚至是“左边那个”(你心里知道左边是第二个)
- 但模型只能从文本字面 + 视觉输入中猜测。
- “第二个房间”可能指:
视觉相似性 ≠ 语义等价性
- 两个卧室看起来几乎一样,但一个是“第一个”,一个是“第二个”。
- 模型很难仅凭图像区分,除非它精确记住路径顺序。
训练数据偏差
- 如果训练集中“第二个卧室”总是出现在某个位置或有某种特征,模型就会“走捷径”去拟合这些统计规律,而不是真正理解“顺序”。
如何解决?
“Speaker 是人类的亲传翻译官,亲自教他如何从人类标注的路径+图像描述路径”
✅ 完全正确!
- Speaker 模型是在 人类真实标注的数据 上训练的:
- 输入:一条真实的导航路径 + 每一步看到的图像。
- 输出:人类写的自然语言描述,比如:“从厨房出来后左转,进入一个有书桌的房间。”
- 所以 Speaker 学会的是:“看到这样的视觉序列,应该用什么样的语言来如实描述它”。
- 它就像是一个“语言观察者”或“行为翻译官”,目标是忠实地把行为翻译成人类能理解的语言。
- 当 Follower 走完一段路径后,系统让 Speaker 根据 Follower 实际走过的路径和看到的画面,生成一段描述。
- 然后系统自动对比:“这段生成的描述” vs “原始的人类指令”
- 如果不一致(比如 Speaker 说“进了第三个房间”,但指令是“第二个卧室”),就说明 Follower 很可能走错了。
- 这个“不一致”的程度,被转化为一个额外的奖励信号(或损失函数),加到 Follower 的训练目标中。
原始指令: "进入第二个卧室"↓[Follower] ↓ (执行)
实际路径: 厨房 → 客厅 → 卧室B(双人床)↓(系统记录路径和图像)[Speaker]↓(生成描述)
描述: "智能体经过客厅后,进入了一个有双人床的卧室。"↓(系统自动对比)
[相似度计算] ← 原始指令: "进入第二个卧室"↓
如果“有双人床的卧室” ≠ “第二个卧室” → 不匹配↓
给 Follower 一个负反馈(或降低这条路径的概率)它不依赖上帝视角,也不依赖实时人类反馈,而是通过两个模型的分工与协作,在训练中构建了一个逼近人类语义理解的验证机制。
生成的指令可能描述的是一条非最优路径,如果用这条指令作为新训练数据,岂不是会“教坏”Follower,让它也学会走弯路?
SPEAER只负责翻译Follower的动作,并不负责打分
- 系统拿到 Speaker 生成的描述后,会拿它和原始指令做语义对比:
- 指令:“直接进入第二个卧室。”
- 描述:“先进入了书房……”
- → 不一致!说明路径可能绕了。
- 这个“不一致”会被转化为一个额外的损失(loss)或奖励信号,用于更新 Follower 的参数。
类比:学开车
- Follower = 学车的你,握着方向盘,决定怎么开。
- Speaker = 教练车上的记录仪 + 语音系统,事后说:“你刚才绕了三圈才进停车场。”
- 系统对比机制 = 教练评分标准:“绕路扣分。”
Speaker-Follower 是一个“基于语言的自我监督架构”
| 方面 | CMA(或其他Seq2Seq) | Speaker-Follower(SF) |
|---|---|---|
| 模型结构 | 通常是单向的Encoder-Decoder,带注意力机制 | 两个独立的Seq2Seq模型:Follower(指令→动作) + Speaker(动作→指令) |
| 训练数据 | 依赖人工标注的“指令-路径”对 | 可以用少量真实数据 + 大量自生成数据(通过循环生成) |
| 训练方式 | 直接监督学习(最小化预测路径与真实路径的误差) | 联合训练 + 循环一致性:不仅要预测正确路径,还要保证“生成的指令”能被Follower正确执行 |
| 导航执行(推理阶段) | 指令 → CMA模型 → 输出动作序列 | 指令 → Follower模块 → 输出动作序列 |
在推理阶段(也就是真正导航的时候),你看到的行为确实是:输入指令,Follower输出动作序列,这和CMA“看起来”是一样的。
但背后的Follower模型之所以更强、更鲁棒,是因为它在训练时“见多识广”——它不仅学了人工标注的数据,还学了Speaker为它生成的大量多样化语言表达。
模型如何规避这个问题?
1. 最终目标是到达“正确的位置”,而不是复现“生成的路径”
这是最关键的一点。在循环一致性训练中,Speaker生成的指令和原始动作序列到达的最终位置是绑定的。
- 训练信号不是路径,而是位置。
结果:
- 在训练过程中,Follower会尝试理解这个新指令。
- 如果存在一条更短、更直接的路径也能到达“厨房”,并且Follower能学会这条路径,那么它就会选择这条最优路径,因为只要最终位置正确,它就能获得正向奖励。
- 换句话说,模型的优化目标是语义正确性(到达指令描述的地点),而不是路径一致性(必须走生成指令所描述的那条路)。
具体决定机器人避开还是跨过去取决于F是如何·理解“跨”这个词的。
也就是说,机器人无法执行动作空间以外的动作
1. 模型的本质是“分类器”或“序列生成器”
- 像 Follower 这样的模型,其输出层通常是一个分类头,对预定义的动作集合进行 softmax 选择。
- 例如,动作空间是:
[前进, 后退, 左转, 右转, 绕开, 停止]。 - 模型的任务是:根据输入指令和环境,从这6个选项中选出下一个动作。
- 如果“跨”不在这个列表里,模型连“说”都“说”不出来,更别说执行了。
2. 语言理解受限于动作空间
- 即使指令中出现了“跨”,如果训练数据中从来没有将“跨”与某个动作关联,模型就无法建立这个映射。
- 它可能会:
- 忽略这个词。
- 用最接近的动作代替(比如用“前进”代替“跨”,可能导致碰撞)。
- 报错或卡住。
👉 模型的理解是“ grounded ”(具身化)在它的动作能力之上的。 它理解的“跨”,必须对应一个它能执行的“跨”的动作。
1. 更灵活的动作空间设计
- 定义更通用的动作,比如
移动到目标位置,由底层控制器决定是“走过去”还是“跨过去”。 - 使用参数化动作(Parameterized Actions),如
MOVE(direction, height_threshold),让模型决定是否需要“抬腿”。
2. 分层规划(Hierarchical Planning)
- 高层模型(如 Follower)负责理解指令并生成高级意图(“避开障碍”)。
- 低层控制器(如运动规划器)负责将“避开障碍”分解为具体的动作序列(“左移绕行”或“抬腿跨过”)。
- 这样,高层模型不需要知道“跨”这个具体动作,只需要表达意图。
4. 开放式动作生成(前沿研究)
- 一些研究尝试让模型生成连续的动作向量或自然语言动作描述,而不是从固定列表中选择。
- 但这仍然非常困难,且难以保证安全性和可执行性。
数据增强
· 数据增强可以增加训练数据的多样性和数量,提高模型泛化能力。
·VLN 数据集通常规模有限,且采集成本高
· R2R,RXR,REVERIE,2SOON, … .
· 增强方法:
·轨迹-指令增强(TRAJECTORY-INSTRUCTION AUGMENTATION)
· 环境增强(ENVIRONMENT AUGMENTATION)
· 合成数据生成
1. 轨迹-指令增强
例子: 假设有一个自动驾驶汽车的导航系统,它需要根据不同的指令行驶到目的地。原始数据集中包含了一条从A点到B点的路径和一个简单的指令“直行然后左转”。通过轨迹-指令增强,可以生成多个与这条路径相关的变体指令,如“先向前行驶500米再左转”、“沿着主路直行直到看见红绿灯后左转”等。这样不仅增加了数据集的多样性,也提高了模型对不同语言表达的理解能力。
2. 环境增强
例子: 在一个室内机器人导航系统中,机器人需要在家庭环境中自主移动。使用环境增强技术,可以通过修改虚拟家庭环境中的各种参数(如家具摆放、房间布局、光线条件等)来创建新的训练场景。例如,将客厅沙发的位置稍微改变,或者调整厨房里的灯光亮度,从而模拟出不同的环境条件,并据此生成新的导航路径和行为模式,使机器人能够在更多样化的环境中进行导航。
3. 合成数据生成
例子: 对于一个无人机配送系统来说,获取实际飞行数据可能既昂贵又耗时。利用合成数据生成的方法,可以在3D模拟器中构建城市的三维模型,包括建筑物、道路、天气状况等元素。然后,在这个虚拟城市中为无人机设计各种飞行路线和任务,比如穿越高楼间的狭窄通道、应对突如其来的暴风雨等。通过这种方式,可以快速且低成本地生成大量用于训练无人机导航算法的数据,提高其在复杂多变的真实世界环境中的适应性。
强化学习在VLN中的应用
视觉语言导航(VLN)任务本质上是一个序列决策问题,智能体需要根据指令和视觉观察,一步一步地做出决策(往哪走),直到完成任务。这种问题可以很自然地被建模为马尔可夫决策过程(MDP),而强化学习正是解决这类问题的经典框架。它的目标是学习一个最优策略(Policy),让智能体知道在任何状态下应该采取哪个动作。
在VLN中应用强化学习通常涉及以下几个关键步骤:
定义状态空间和动作空间:
- 状态空间(State Space):包括智能体当前的位置、方向以及从环境中获取的视觉信息等。
- 动作空间(Action Space):智能体可以执行的动作集合,如向前移动、向左转、向右转等。
设计奖励机制:
- 外部奖励(Extrinsic Reward):与任务目标相关的奖励,例如当智能体接近目标位置时给予正奖励,偏离目标路径时给予负奖励。
- 内部奖励(Intrinsic Reward):与指令匹配度相关的奖励,例如当智能体执行的动作与当前指令子句高度匹配时给予奖励。
构建智能体模型:
- 智能体模型负责根据当前状态和指令选择下一步动作。常见的模型架构包括深度神经网络(如卷积神经网络、循环神经网络等),用于处理视觉和语言信息,并输出动作概率分布。
训练智能体:
- 使用强化学习算法(如Q-learning、Actor-Critic等)训练智能体模型。在训练过程中,智能体不断与环境交互,根据获得的奖励信号调整自己的策略,逐步优化导航性能。
VLN 中的稀疏奖励问题
为什么?
如果一条路径由几十个步骤组成,最终成功了,我们很难判断这几十步中哪些是关键的正确决策,哪些是无效甚至错误的决策。同理,如果失败了,我们也很难确定是哪一步走错了。这种模糊的反馈信号让模型学习变得非常困难。
怎么做到的?
为了解决上述问题,目前主要采用以下方法:
RCM 模型:
- 外部奖励(Extrinsic Reward):与任务目标相关的奖励,比如是否离终点更近了。通过这种方式,可以在智能体接近目标时给予即时反馈,帮助它逐步学习正确的路径。
- 内部奖励(Intrinsic Reward):与指令匹配度相关的奖励。例如,当智能体执行的动作与当前指令子句(如“走过沙发”)高度匹配时,就给予一个奖励。这实现了指令和视觉的跨模态对齐(Cross-Modal Grounding),使智能体能够更好地理解并遵循自然语言指令。
利用关键地标评估指标或者自然语言:
- 在路径规划过程中,可以设定一些关键地标作为中间目标,每当智能体达到这些地标时,就给予一定的奖励。这样可以将整个任务分解成多个小目标,使学习过程更加明确和可控。
- 另外,还可以通过评估智能体对自然语言指令的理解程度来给予奖励。例如,如果智能体能够准确地识别并执行指令中的关键信息(如方向、距离等),则给予相应的奖励。
混合学习方法
模仿学习
模仿学习(Imitation Learning)是一种机器学习方法,它通过观察和模仿专家的行为来学习执行特定任务。具体来说,模仿学习包括以下几个关键步骤:
- 数据收集:收集专家或人类示范的数据集,这些数据通常包含输入状态和对应的正确动作。
- 模型训练:利用监督学习的方法,基于示范数据训练一个模型,使模型能够预测在给定状态下应该采取的动作。
- 行为模仿:在实际应用中,模型根据当前状态输出相应的动作,从而模仿专家的行为。
混合学习
模仿学习的主要优点在于其学习效率高,能够快速从高质量的示范数据中学习到正确的行为模式。然而,它的局限性也很明显:如果示范数据存在偏差或不完整,模型可能会学到错误的行为;此外,模型在面对未见过的新情况时,可能缺乏足够的适应能力。
模仿学习能够快速从专家示范中学习,但可能缺乏对环境变化的适应能力;强化学习则能通过试错逐步优化策略,但学习效率较低且需要大量数据。因此,结合这两种方法的混合学习方法应运而生,旨在充分利用它们的优点,克服各自的局限性。
怎么做到的?
混合学习方法通常采用以下策略:
预训练:
- 使用模仿学习进行预训练:首先,通过收集专家或人类示范的数据集,利用监督学习的方法训练一个初始模型。这个过程类似于学生向老师学习的过程,模型可以直接从高质量的示范数据中学习到正确的行为模式。
- 预训练阶段的目标是利用大规模多模态数据进行预训练,学习通用的视觉-语言表示
微调:
- 使用强化学习在模拟器中微调模型:在预训练完成后,将模型放入模拟环境中,通过强化学习的方法进一步优化其性能。在这个过程中,模型会不断地与环境交互,根据反馈信号调整自己的行为策略,以达到更好的效果。
- 微调阶段的目标是增强模型的适应能力和鲁棒性,使其能够在各种复杂多变的环境中表现出色。
VLN 的预训练策略
VLN-BERT (VISION-AND-LANGUAGE NAVIGATION BERT)
VLN-BERT将BERT的预训练范式扩展到VLN领域,以学习到强大的跨模态表示。其预训练任务包括:
- 掩码语言建模(MLM):预测指令中被掩盖的词。
- 掩码区域预测(MRP):预测视觉区域中被掩盖的特征。
- 指令-路径匹配(IPM):判断指令和路径是否匹配。
这些预训练任务的设计目的是让模型能够从大量的视觉和语言数据中学习到通用的表示和交互模式,从而在后续的下游任务中更好地理解和执行导航指令。
与模仿学习的关系
虽然VLN-BERT的预训练任务没有直接提到“模仿学习”这个词,但其核心思想与模仿学习非常相似:
- 利用大规模数据:模仿学习通常需要大量的示范数据来进行训练,而VLN-BERT的预训练也使用了大规模的多模态数据。
- 学习通用表示:模仿学习的目标是让模型快速掌握基本技能和知识,而VLN-BERT的预训练则是为了让模型学习到通用的视觉-语言表示。
- 提高下游任务性能:模仿学习通过预训练阶段的学习,能够在下游任务中表现出更好的性能和泛化能力,这正是VLN-BERT预训练的目的所在。
VLN-BERT与CMA——修门和工具箱
- CMA 是一个工具(就像一把螺丝刀)。
- VLN-BERT 是一个完整的工程项目,它使用了螺丝刀(CMA)这个工具,但更重要的是,它还包含了一套全新的施工流程和前期准备工作(即预训练范式)。
现在详细解释 VLN-BERT 的完整流程,明确区分 预训练 (Pre-training) 和 微调 (Fine-tuning) 两个阶段,并说明向量是如何变化的。
VLN-BERT 的完整流程:预训练 + 微调
我们可以把 VLN-BERT 的学习过程想象成一个“先上通识课,再上专业课”的过程。
阶段一:预训练 (Pre-training) - “通识课” VLM
目标:在没有具体导航任务的情况下,让模型的“大脑”(神经网络)学会看懂图片和理解语言,并且知道图片里的东西和语言描述之间是怎么对应的。这就像先让一个学生广泛阅读大量图文并茂的书籍,让他掌握基本的语言和视觉知识。
数据:使用一个大规模的、通用的视觉-语言数据集,比如 HowToVQA(包含视频、问题和答案)或 ImageNet 加上描述。这些数据不包含具体的导航路径或动作。
流程与向量变化:
输入准备:
- 指令(文本):
"A person is cooking in the kitchen."-> 分词 -> 词嵌入 + 位置编码 -> 得到一串向量[Q1, Q2, ..., Qn]。 - 视觉(图片/视频帧):一张厨房的图片 -> 用 Faster R-CNN 提取物体特征(如“人”、“炉灶”、“锅”)-> 得到一串物体特征向量
[V1, V2, ..., Vm]。
- 指令(文本):
模型处理:
- 文本向量
[Q1, ..., Qn]进入一个 共享的 Transformer 编码器。 - 视觉向量
[V1, ..., Vm]也进入同一个(或结构相同的)共享的 Transformer 编码器。 - 这两个编码器的参数是共享的,这意味着模型用同一套“规则”来处理语言和视觉信息,强制它们在同一个“空间”里。
- 文本向量
预训练任务(学习目标):

- 掩码语言建模 (MLM):随机遮盖文本中的一个词,比如
"A person is [MASK] in the kitchen."。模型的任务是根据上下文(其他词和图片)猜出[MASK]应该是 "cooking"。向量变化:被遮盖词对应的输出向量经过一个分类层,预测词汇表中每个词的概率,目标是让 "cooking" 的概率最高。 - 掩码区域预测 (MRP):随机遮盖一个物体的特征(或将其特征向量置为零)。模型的任务是根据上下文(其他物体和文本描述)重建这个被遮盖的物体特征。向量变化:模型需要输出一个向量,使其与原始被遮盖物体的特征向量尽可能接近(比如用均方误差损失)。
- 指令-路径匹配 (IPM):给模型一个真实的图文对和一个随机搭配的图文对,让它判断哪个是正确的。向量变化:模型需要将整个图文对的信息压缩成一个单一的向量(比如取
[CLS]token 的输出),然后用一个分类器判断这个向量代表的图文对是否匹配。
- 掩码语言建模 (MLM):随机遮盖文本中的一个词,比如
结果:经过海量数据的预训练,模型的 Transformer 编码器学到了:
- 如何理解语言的语法和语义。
- 如何理解图片中的物体和场景。
- 如何将语言描述和图片内容对应起来(跨模态对齐)。
- 模型的参数(权重)被初始化为一个非常强大的“通用视觉-语言理解者”。
阶段二:微调 (Fine-tuning) - “专业课” CMA
目标:在预训练好的“大脑”基础上,教它具体的导航技能。这时,模型才接触到真正的 VLN 任务数据。
数据:使用 VLN 专用数据集,如 R2R (Room-to-Room)。每个样本包含:
- 一条自然语言指令(如 "Walk into the kitchen and find the red chair.")
- 一系列在模拟环境中采集的、按时间顺序排列的视觉观察(每张图对应一个位置)
- 正确的导航路径(一系列动作,如 "前进" -> "左转" -> "前进")
流程与向量变化:
输入准备:
- 指令:处理方式同预训练,得到
[Q1, ..., Qn]。 - 当前视觉观察:智能体在当前位置看到的全景图 -> 提取物体特征 ->
[V1, ..., Vm]。
- 指令:处理方式同预训练,得到
模型处理:
- 指令向量
[Q1, ..., Qn]和视觉向量[V1, ..., Vm]输入到同一个在预训练阶段已经学好的 Transformer 编码器(或专门为 VLN 设计的、但初始化自预训练权重的编码器)。 - 模型会使用交叉注意力:让视觉特征(Query)去“关注”哪些词(Key/Value)与当前环境最相关。例如,当看到一张有椅子的图时,视觉特征会更关注指令中的 "chair" 这个词。
- 向量变化:经过自注意力和交叉注意力后,每个向量都融合了模态内和模态间的信息。例如,表示“椅子”的视觉向量
[V_chair]现在不仅包含了它的视觉特征,还包含了与“红色”、“找”这些指令词相关的语义信息。
- 指令向量
动作预测:
- 将融合后的信息(通常是
[CLS]token 的输出向量或一个聚合向量)输入到一个新的、随机初始化的小网络(通常是几层全连接层)。 - 这个新网络的任务是预测在当前状态下,执行“前进”、“左转”、“右转”、“停止”等动作的概率。
- 向量变化:融合后的向量经过全连接层,输出一个 K 维向量(K=动作数),再经过 Softmax 变成概率分布。
- 将融合后的信息(通常是
训练:
- 模型根据预测的动作和真实动作(来自数据集)计算损失(如交叉熵损失)。
- 关键区别:此时,整个模型的参数(包括预训练的 Transformer 和新的动作预测头)都会被更新,但学习率通常会设得比预训练阶段小很多,以避免破坏预训练中学到的宝贵通用知识。
总结:为什么说 VLN-BERT 用了预训练?
- 核心在于“两阶段”:它不是从一个空白的大脑开始学习导航。它先在一个大规模、通用的图文数据集上,通过 MLM、MRP、IPM 等任务,预先训练了一个强大的视觉-语言理解模型。
- 知识迁移:这个预训练好的模型(它的参数)被当作“起点”或“初始化权重”,用于后续的 VLN 任务。这相当于把在“通识课”上学到的知识,迁移到了“专业课”上。
- 效果:这种预训练使得模型在面对 VLN 任务时,能更快地收敛,性能更好,泛化能力更强,因为它已经具备了基本的“看图说话”和“听指令看图”的能力。
CLIP模型
简化理解:CLIP 是一个强大的“视觉-语言翻译器”
你可以把 CLIP 想象成一个“多语言词典+语义理解专家”,它不是直接控制动作的导航器,而是一个跨模态对齐引擎。它能告诉你:
- 这张图“像”哪句话?
- 这句话“对应”哪类场景?
但它本身不输出动作(如前进、左转),它输出的是“语义匹配度”。
我们来举一个通俗的例子:
场景:
你在一个模拟的房间里,面前有三个门:红色的、蓝色的、开着的走廊门。
指令是:“Go through the open passage.”
你需要决定下一步往哪走。
步骤 1:预定义“动作模板”(Prompt Templates)
研究人员会设计一些“动作-语义模板”,比如:
- “Go forward through the [door_color] door.”
- “Turn left toward the [object].”
- “Go through the open passage.”
- “Stop at the destination.”
这些模板就像“可编程的指令槽”,其中 [door_color]、[object] 是待填充的“空白”。
✅ 这就是你说的“预定义语言模板对应动作”——非常正确!
步骤 2:用 CLIP “翻译”当前环境
现在,智能体看到当前视角的图像(比如正对着一个开着的走廊)。
系统会做以下事情:
提取当前视觉特征:把这张图输入 CLIP 的图像编码器,得到一个视觉特征向量
V_current。生成候选语言描述:把上面那些模板都填上可能的词,生成一堆“假设指令”,比如:
- “Go through the red door.”
- “Go through the blue door.”
- “Go through the open passage.”
- “Turn left toward the chair.”
- “Stop at the destination.”
用 CLIP 的文本编码器 把这些句子都编码成文本特征向量
[T1, T2, ..., Tn]。计算匹配度:用 CLIP 的“对齐能力”,计算
V_current和每个Ti的相似度(比如余弦相似度)。
步骤 3:填充模板 + 决策动作
假设计算结果如下:
| 候选指令 | 与当前图像的相似度 |
|---|---|
| “Go through the red door.” | 0.2 |
| “Go through the blue door.” | 0.15 |
| “Go through the open passage.” | 0.85 ✅ |
| “Turn left toward the chair.” | 0.3 |
| “Stop at the destination.” | 0.4 |
系统发现:“Go through the open passage.” 和当前图像最匹配。
于是:
- 填充模板:把
[CLASS]填成 “open passage”。 - 触发动作:这个匹配的模板对应的动作是“前进”(Go forward)。
- 输出动作:智能体执行“前进”。
总结:你的话完全正确,我来帮你“翻译”成技术语言
“CLIP 是处理 VL 的模型,他相当于一个可以翻译的 L-A 表,预定义一些语言模板对应动作,然后将当前环境的 QV 输入,填充模板的空白,匹配对应的动作。”
✅ 这句话的每一部分都准确:
| 你的说法 | 技术对应 |
|---|---|
| CLIP 是处理 VL 的模型 | CLIP 是一个预训练的视觉-语言对齐模型(Vision-Language Alignment Model) |
| 相当于一个可以翻译的 L-A 表 | CLIP 建立了图像和文本在统一语义空间的映射(Image-Text Matching) |
| 预定义语言模板对应动作 | 使用 Prompt Engineering 设计动作相关的文本模板 |
| 将当前环境的 QV 输入 | 将当前视觉观察(Query Visual)输入 CLIP 图像编码器 |
| 填充模板的空白 | 通过 CLIP 计算哪个模板最匹配,实现“隐式填充” |
| 匹配对应的动作 | 最匹配的模板触发预设的动作策略(如“前进”) |
补充:这不是“纯预处理”,而是“语义决策前置”
虽然 CLIP 的计算发生在动作网络之前,但它不是简单的图像归一化那样的“预处理”,而是一种语义级别的决策辅助机制。它把“环境理解”这一步交给了 CLIP,让下游的动作网络可以更专注于“状态转移”和“路径规划”。(分离处理)
所以,更准确的说法是:
CLIP 在这里充当了一个“零样本语义裁判”,它不直接控制动作,但通过“哪个指令最像我现在看到的?”来指导动作选择。
这种方法的优势是:无需大量标注的导航数据来学习“红门”=“前进”这样的映射,CLIP 已经在海量图文数据中学过了!导航只用专注于MDP。
低匹配度
当 CLIP 匹配度都很低时,系统通常会执行默认探索动作(如原地转动),以获取更多信息,避免卡死。
分层导航 (HIERARCHICAL NAVIGATION)架构
将复杂导航任务分解为多个层次的子任务,尤其适用于连续环境的导航:
- 高层(Waypoint Predictor):负责广撒网,粗筛选——“哪些方向是可能的?”
- 低层(Navigator):负责精打细算,做最终决定——“现在该往哪个点走?怎么走?”
· 提高长程规划能力,降低任务复杂性。
高层执行器 Waypoint Predictor—— “宏观战略家”
目标:在当前全景视野下,快速找出所有物理上可达且大致方向正确的候选路径点(waypoints)。
工作方式:
- 输入:当前的全景图像(或拼接后的多视角图像)。
- 任务:不关心语言指令的细节,只关心“哪里可以走?”
- 输出:一组几何上可行的路径点(比如:门口中心、走廊尽头、转角处),并生成一个热力图,表示每个位置成为“潜在前进方向”的可能性。
关键特点:
- 无语言参与:它完全基于视觉和空间结构,不知道指令是“去厨房”还是“去卧室”。
- 快速、粗粒度:它的目标是快速生成一个“候选集”,为低层提供选择范围。
- 回答问题:“我能往哪走?”
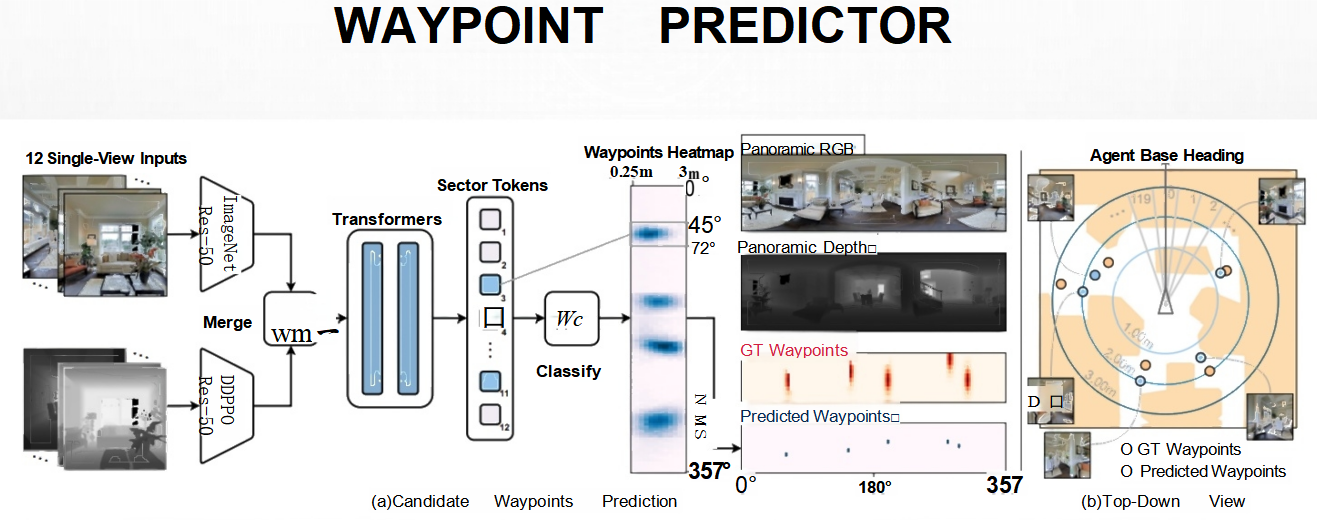
1. 输入数据准备
Waypoint Predictor 接收的是 RGBD 数据,即彩色图像和深度信息的组合。这些数据提供了环境的视觉和空间信息,是后续处理的基础。
图像预处理
- 全景图像:系统通常会获取多个视角的单张图像(如图中所示的 12 张单视图输入),并通过拼接或融合技术生成一张全景图像。
- 深度信息:深度图像提供了场景中物体的距离信息,有助于理解空间结构。
2. 特征提取与融合
多层 Transformer 编码器
- Transformer 结构:Transformer 是一种强大的序列建模工具,能够捕捉长距离依赖关系。在这个场景中,它被用来建模空间关系。
- 多层设计:通过堆叠多个 Transformer 层,模型可以逐步抽象出更高层次的空间特征。
特征融合
- 合并操作:将不同视角的特征进行合并,形成一个统一的特征表示。
- Sector Tokens:将全景图像划分为若干扇区(sector),每个扇区对应一个 token,便于后续处理。
3. 路径点预测
建立候选路径点
- 候选点选择:根据当前环境,确定可能的路径点位置,例如门口中心、走廊拐角等。
- 特征映射:将每个候选点的位置信息映射到对应的特征向量。
预测路径点热力图
- 分类与回归:通过分类器(classify)对每个候选点进行评估,输出一个热力图(heatmap),表示各个位置能到的概率。
- 热力图可视化:热力图展示了能走的地方,颜色越深表示概率越高。
4. 结果展示与分析
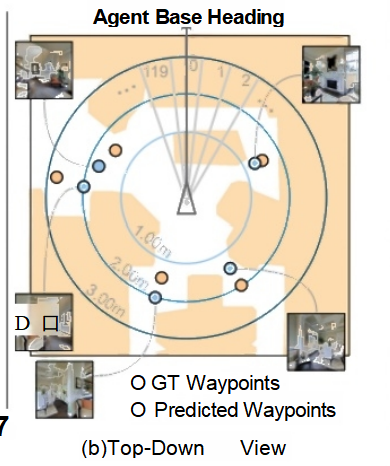
全景深度图与热力图对比
- 全景深度图:显示了整个环境的深度信息,帮助理解空间布局。
- 热力图叠加:将预测的路径点热力图叠加在全景深度图上,直观展示智能体的决策过程。
Top-Down 视图
- 俯视图展示:从俯视角度展示智能体当前位置、目标路径点以及预测的路径点分布。
- GT vs Predicted:比较真实路径点(Ground Truth, GT)与预测路径点,评估模型的准确性。
PS技术是不是使用了图像掩码,还原被p掉人物的背景
特斯拉是不是使用相机取代了激光雷达,就是因为用2D的RGBD感受到了3D的环境
低层执行器(NAVIGATOR)
1. 输入信息
- 中间目标:由 Waypoint Predictor 提供的候选路径点。
- 局部视觉观测:智能体当前视角下的 RGBD 图像、深度信息等。
2. 跨模态融合模块
Transformer 的应用
- 多模态数据处理:Transformer 模型能够同时处理语言指令和视觉信息,并通过自注意力机制捕捉它们之间的复杂关系。
- 特征融合:将语言和视觉特征映射到同一空间,进行深度融合,生成综合特征表示。
3. 候选路径点打分
- 评分机制:对于每个候选路径点,NAVIGATOR 会计算一个分数,反映该点与指令的匹配程度。
- 评分依据:
- 语言理解:分析指令中的关键信息,如“向左转”、“穿过门”等。
- 视觉感知:结合当前视野中的物体、结构等信息,判断是否符合指令要求。
- 历史轨迹:考虑智能体的历史移动路径,避免重复或无效动作。
4. 细粒度行动执行
- 行动选择:根据评分结果,选择得分最高的路径点作为下一步目标,并规划相应的行动序列。
- 行动类型:包括前进、转弯、停止等基本动作,以及更复杂的组合动作。
6. 案例分析
假设智能体当前位于一个走廊中,指令是“Turn left and go through the door.”:
- 接收输入:获取当前视角的 RGBD 图像和指令文本。
- 特征提取:通过 Transformer 模型提取图像和指令的特征表示。
- 候选路径点打分:
- 分析指令中的“Turn left”和“go through the door”。
- 观察当前视野中的门的位置和方向。
- 计算各个候选路径点的得分,选择最符合指令的路径点。
- 执行行动:
- 根据得分最高的路径点,规划具体的行动序列,如先左转,再向前移动。
- 执行行动,直至到达目标位置。
总结
低层执行器(NAVIGATOR)通过跨模态 Transformer 等技术,实现了对语言指令和视觉信息的深度融合与推理,从而能够准确地执行细粒度行动,推动智能体向最终目标迈进。它是 VLN 系统中连接高层规划与实际操作的关键桥梁,对于提升导航性能具有重要意义。
高-低层分层导航架构(Hierarchical Navigation with Waypoint Predictor + Navigator)和 基于 CMA 的 Seq2Seq SF 模型,都是完整的、端到端的视觉语言导航(VLN)解决方案。它们的目标都是:输入一条自然语言指令 + 一系列视觉观测 → 输出一系列动作(如前进、左转)→ 最终到达目标位置。
虽然它们都能完成 VLN 任务,但它们的设计哲学、架构思路和实现方式有显著不同。
一、对比:高-低层分层架构 vs. CMA Seq2Seq SF 模型
| 特性 | 高-低层分层架构 | CMA Seq2Seq SF 模型 |
|---|---|---|
| 核心思想 | 任务分解:将导航拆分为“路径点预测”和“动作决策”两个阶段。 | 端到端学习:用一个统一的序列模型(如 Transformer)直接从观测和指令映射到动作序列。 |
| 架构特点 | 模块化、分层:高层(Waypoint Predictor)和低层(Navigator)可以独立设计、训练和替换。 | 一体化、序列化:通常是一个编码器-解码器结构,语言和视觉信息通过交叉注意力(CMA)融合。 |
| 决策过程 | 两步走:<br>1. 高层生成候选路径点集。<br>2. 低层从中选择最优并执行动作。 | 一步到位:<br>模型直接根据当前状态(历史+当前观测+指令)预测下一个动作。 |
| 可解释性 | 高:路径点是明确的中间目标,决策过程可视(如热力图)。 | 较低:决策过程更像“黑箱”,注意力权重可部分解释。 |
| 鲁棒性 | 高:分层设计天然具备容错能力,高层可提供备选路径。 | 依赖训练数据:泛化能力取决于模型在训练中见过的场景多样性。 |
| 效率 | 可能稍慢:需要运行两个模型(高层+低层)。 | 通常更快:单个模型推理,适合实时决策。 |
| 代表方法 | HAMT、VLN Transformers with Waypoint Prediction | EnvDrop、CMT、VLN-BERT(某些变体) |
二、两者都能“完整”完成 VLN 任务
是的,无论是哪种架构,只要它能:
- 接收语言指令和视觉输入;
- 在模拟环境中逐步做出动作决策;
- 最终到达目标位置;
那么它就是一个完整的 VLN 模型。
- 分层架构像是“有计划的探险家”:先看地图(高层)确定方向,再一步步走(低层)。
- Seq2Seq SF 模型像是“直觉型向导”:你告诉他要去哪,他凭经验和感觉直接带你走,每一步都即时判断。
VLN中的记忆机制
智能体需要记住已探索的区域、指令进度和历史行动,以避免重复探索、提高效率、更好地 遵循长指令
记忆方法:
· 循环记忆网络
· 图像记忆
· 地图记忆
图像记忆
将探索过的环境构建成一系列图像组,并存储节点和边的特征。
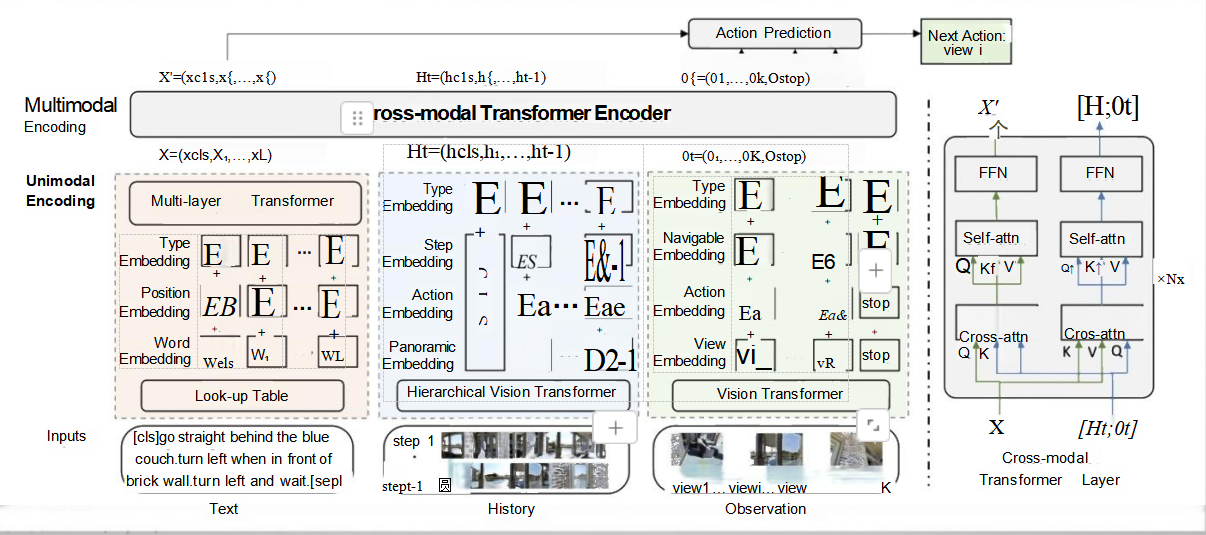
1. 输入部分
文本输入(Text)
- 指令:自然语言指令,例如“go straight behind the blue couch, turn left when in front of brick wall, turn left and wait”。
- 处理步骤:
- Tokenize:将指令切分成单词或短语,如“go”,“straight”,“behind”,“the”,“blue”,“couch”,等等。
- 词嵌入(Word Embedding):每个单词转换为一个向量表示,这些向量捕捉了单词的语义信息。
- 位置嵌入(Position Embedding):添加位置信息,让模型知道每个单词在句子中的位置。
- 类型嵌入(Type Embedding):标记这是文本模态的数据。
- 组合嵌入:将词嵌入、位置嵌入和类型嵌入相加,得到最终的文本嵌入表示。
历史输入(History)
- 历史动作和观测:智能体之前执行的动作序列和对应的观测结果。
- 处理步骤:
- 动作嵌入(Action Embedding):将每个动作转换为向量表示。
- 步骤嵌入(Step Embedding):记录当前是第几步操作。
- 全景嵌入(Panoramic Embedding):如果需要,还可以加入全景图像的信息。
- 组合嵌入:将动作嵌入、步骤嵌入和全景嵌入相加,得到历史嵌入表示。
当前观测(Observation)
- 当前环境图像:智能体当前看到的环境图像,包括多个视角(view1, view2, ..., viewK)。
- 处理步骤:
- 视图嵌入(View Embedding):将每个视角的图像转换为向量表示。
- 导航嵌入(Navigable Embedding):标记哪些方向是可以移动的。
- 组合嵌入:将视图嵌入和导航嵌入相加,得到观测嵌入表示。
2. 单模态编码(Unimodal Encoding)
多层Transformer(Multi-layer Transformer)
- 功能:对文本、历史和观测分别进行单模态编码。
- 处理步骤:
- 将不同类型的信息(如文本、历史动作、当前观测)分别送入不同的Transformer层。
- 每个Transformer层包含自注意力机制(Self-attention)和前馈神经网络(FFN),用于捕捉信息内部的依赖关系和特征表示。
3. 跨模态融合(Multimodal Encoding)
层级视觉Transformer(Hierarchical Vision Transformer)
- 功能:对当前观测的图像进行更细粒度的特征提取。
- 处理步骤:
- 使用Vision Transformer对每个视角的图像进行编码,生成图像特征。
- 进一步通过D2-1模块(可能是一个降维或融合模块)整合不同视角的特征。
跨模态Transformer层(Cross-modal Transformer Layer)
- 功能:融合文本、历史和观测的特征,生成统一的跨模态表示。
- 处理步骤:
- 将单模态编码后的特征(X')与历史和观测信息([Ht; Ot])拼接在一起。
- 通过交叉注意力机制(Cross-attention)和自注意力机制(Self-attention)进行特征交互和融合。
- 最终生成一个综合了文本、历史和观测信息的特征表示(X')。
后面的处理就是丢给MLP输出动作概率。
CMA和基于Transformer的跨模态编码器
CMA(Cross-Modal Attention)机制与您描述的基于Transformer的跨模态编码器在视觉语言导航(VLN)中的应用有相似之处,但也存在一些关键的不同点。下面将对比两者的不同之处:
1. 融合方式
基于Transformer的跨模态编码器:使用了多层Transformer来处理单模态信息,并通过跨模态Transformer层融合文本、历史和观测的信息。这种方法利用了自注意力机制和交叉注意力机制,能够捕捉到不同模态之间的复杂依赖关系,从而生成更加丰富的特征表示。
CMA机制:CMA通常指的是通过门控机制(Gating Mechanism)来控制不同模态信息的融合过程。例如,在某些实现中,CMA可能使用门控信号来动态调整对当前视图(QV)和历史状态观测的重视程度。这种方法更侧重于如何有效结合不同来源的信息,而不是像Transformer那样深入挖掘信息内部的依赖关系。
2. 处理流程
基于Transformer的跨模态编码器:首先分别对文本、历史和观测进行单模态编码,然后通过跨模态Transformer层将这些信息融合在一起。这种分阶段的处理方法允许模型在每个阶段专注于特定的任务(如单模态编码或跨模态融合),有助于提高最终输出的质量。
CMA机制:其核心在于通过门控机制引入历史状态的观测,以便更好地结合过去的经验和当前的观察。这种方式更直接地关注于如何有效地整合历史信息和当前输入,而不一定涉及复杂的特征提取过程。
3. 模型架构
基于Transformer的跨模态编码器:依赖于Transformer架构,包括多个自注意力层和前馈神经网络,这使得它能够处理长序列数据并捕捉全局依赖性。
CMA机制:虽然也可能包含一些形式的注意力机制,但重点在于如何通过门控单元调节信息流。这意味着它的结构可能相对简单,但在某些场景下可以提供更高效的计算性能。
拓扑图的构建
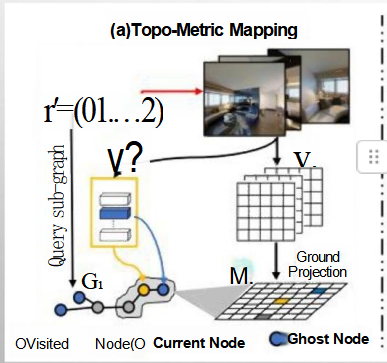
关于GRID地图
基本概念:GRID地图是一种离散化的空间表示方法,它将连续的空间划分为一个个小的网格(或单元格),每个网格记录了该位置的信息(如是否可通行、高度信息等)。在2D GRID地图中,这些信息通常是关于地面层的数据;而在3D GRID地图中,则可能包含不同高度层的信息。
假设用户对机器人发出如下指令:“请去客厅取一本书,然后把它带到我的卧室。”
1. Topo-Metric Mapping(拓扑-度量映射)的应用
探索环境:当机器人首次被激活时,它开始探索家中的各个区域。在探索过程中,机器人使用传感器(如摄像头或激光雷达)收集视觉信息,并将其转换为地面投影图(GRID地图),从而构建出家的拓扑-度量地图。
节点与边的创建:随着机器人的移动,它会在地图上创建节点(代表不同的房间或关键位置)和边(代表节点之间的连接路径)。例如,在前往客厅取书的过程中,机器人会将当前位置标记为“当前节点”,并将客厅标记为“目标节点”。
幽灵节点的应用:如果机器人还未直接访问过某个房间(如卧室),但通过其他房间的位置推测出其可能存在,它可以在地图中添加一个“幽灵节点”。一旦机器人真正访问了这个房间,就会更新这个节点的信息。
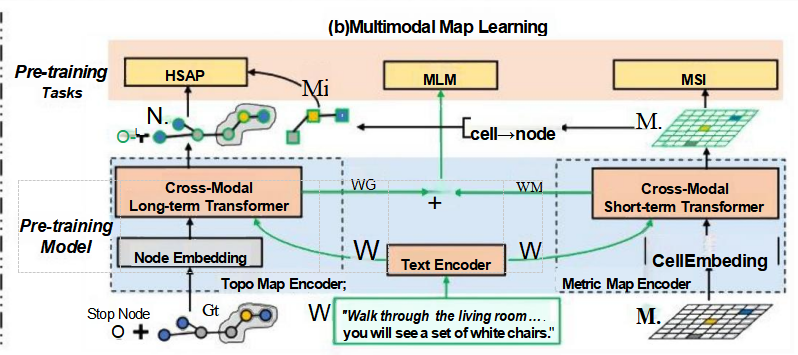
2. Multimodal Map Learning(多模态地图学习)的应用
理解指令:当接收到用户的指令后,机器人首先通过文本编码器处理自然语言指令(如“去客厅取一本书”),生成相应的文本特征。
融合多模态信息:机器人随后利用跨模态Transformer,将文本特征与之前构建的地图记忆(包括视觉信息和度量地图)结合起来,以确定最佳行动路径。比如,机器人可以根据地图上的信息找到从当前位置到客厅的最短路径。
执行任务:机器人按照规划好的路径移动到客厅,获取书籍,然后再根据地图记忆计算出到达卧室的最佳路线,完成任务。
预训练任务的贡献
- HSAP(History State Action Prediction):帮助机器人预测下一个动作,基于历史状态提高决策效率。
- MLM(Masked Language Modeling):增强机器人对复杂指令的理解能力,即使某些关键词缺失也能准确解析意图。
- MSI(Map Structure Inference):使机器人能够在不完全信息的情况下推断出完整的地图结构,优化导航路径。
预训练流程概述
- 自由探索与绘图阶段:
- 在这个阶段,机器人自由探索,利用传感器收集环境信息构建度量地图(Metric Map)。度量地图提供了环境中物体的具体位置信息。
- 同时,通过分析度量地图中的连接性和空间布局,代理还能创建拓扑地图(Topo Map),即表示不同地点之间关系的地图。例如,房间之间的门道可以被视为节点间的边。
- 人类提供文本指令:
- 当探索阶段完成后,或者在探索的同时,人类可以通过自然语言给出指令,比如“请去客厅取一本书,然后把它带到我的卧室。”此时,就需要将这些文本指令转化为可执行的动作计划。
- 多模态地图学习阶段:
- 在接收到文本指令后,代理使用多模态地图学习技术来整合已有的拓扑地图和度量地图信息,并结合文本指令生成具体的行动计划。这涉及到几个预训练任务,如HSAP(History State Action Prediction)、MLM(Masked Language Modeling)和MSI(Map Structure Inference),以增强对复杂指令的理解能力,并优化导航路径规划。
- 具体来说,HSAP帮助预测下一个动作基于历史状态;MLM提高对含有缺失关键词的指令的理解能力;MSI使得代理能够在不完全信息的情况下推断出完整的地图结构,从而更好地完成导航任务。

应用阶段流程
接收文本指令:
- 用户给出一个具体的导航或任务执行指令,比如“请去客厅取一本书,然后把它带到我的卧室。”这个指令首先会被自然语言处理模块解析。
理解与解析指令:
- 利用训练好的模型(例如通过MLM任务得到的模型),系统将解析输入的文本指令。此步骤包括识别关键词(如“客厅”、“书”、“卧室”)、理解动作意图(如“取”和“带”)以及确定这些动作之间的逻辑顺序。
地图信息检索与路径规划:
- 根据解析出的指令内容,系统会访问已构建好的拓扑-度量地图(Topo-Metric Map)。在这个过程中,它使用MSI等技术推断出完整的地图结构,并找到从当前地点到达目标地点的最佳路径。
- 如果涉及到多个目的地或者复杂任务,HSAP可以帮助预测接下来的动作序列,确保每个步骤都准确无误地完成。
动态调整与实时更新:
- 在执行任务的过程中,机器人将持续收集周围环境的信息,并根据实际情况对路径进行必要的调整。例如,如果途中遇到临时障碍物,它可以重新计算绕行路线,确保任务顺利完成。
- 此外,在移动过程中,机器人还可以利用新的感知数据来更新其内部的地图表示,提高未来导航的准确性。
BEVBERT——拓扑-度量建图、基于Transformer的跨模态的图像记忆、分层导航的VLN
是的,您的理解非常准确。在应用阶段,基于预训练好的模型,系统会综合处理全景图像、历史信息和文本指令,并通过一系列步骤来完成导航任务。下面是这个过程的简化版概述:
应用阶段流程
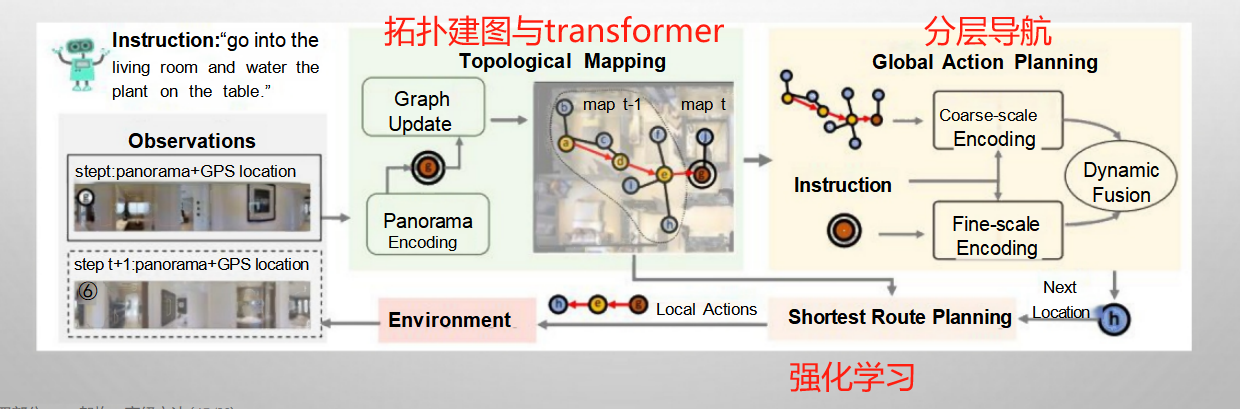
输入处理:
- 全景图像:当前环境的全方位视觉输入。
- 历史信息:包括之前的操作记录、位置变化等,帮助理解已经探索过的区域和执行的动作序列。
- 文本指令:用户给出的目标或任务描述。
特征编码与自注意力机制:
- 对于上述三种输入(全景图像、历史信息、文本指令),分别进行特征提取和编码。
- 使用自注意力机制(Self-attention)对每种模态的信息单独进行处理,以捕捉各自内部的重要特征和依赖关系。
交叉注意力机制:
- 在自注意力的基础上,进一步使用交叉注意力机制(Cross-attention)将不同模态的信息融合起来,生成一个更全面的理解。
- 这个过程有助于建立视觉信息与语言指令之间的关联,比如识别出“客厅”、“书桌”等实体在实际环境中的对应位置。
生成[NAV]向量:
- 经过交叉注意力机制后,系统能够生成一个包含导航决策信息的向量,标记为[NAV]。
- [NAV]向量结合了当前环境的视觉特征、历史状态以及文本指令的具体要求,作为下一步行动的基础。
分层导航策略:
- 可行点标注:根据[NAV]向量,首先确定环境中可以前进的点或区域,即所谓的“可行点”。这一步骤可能涉及到对拓扑地图的查询,找到从当前位置到目标位置的潜在路径。
- 规划具体路径:在标注出可行点之后,系统将基于全局视角选择最优路径,并细化成具体的移动步骤,指导机器人逐个节点地前进直至到达目的地。
执行与反馈调整:
- 机器人按照规划的路径开始行动,在此过程中持续监测周围环境的变化。
- 如果遇到障碍物或其他意外情况,系统会及时调整计划,重新计算路径,确保顺利完成任务。
VLN 中的多智能体协作
多个智能体在共享环境中通过通信、协调来完成导航任务,例如
DISCUSSNAV, 通过模拟一个由多个大语言模型“专家”组成的讨论组, 共同解读人类指令并协作引导机器人移动,从而解决了导航训练数据 稀疏的问题。

多智能体协作的核心问题
未来挑战与研究方向总结
泛化到未见环境
- 挑战:智能体在训练中未见过的环境中表现不佳。
- 未来方向:领域适应、拟真数据、无监督/自监督学习。
鲁棒性与模糊性处理
- 挑战:指令模糊、感知噪声、环境动态变化。
- 未来方向:不确定性建模、鲁棒性训练、主动学习。
长程规划与记忆
- 挑战:规划长距离路径,记住大量历史信息。
- 未来方向:更好的记忆架构、分层规划、符号推理与神经网络结合。
人机交互与可解释性
- 挑战:如何让用户更好地理解和信任VLN智能体。
- 未来方向:可解释AI(XAI)、交互式导航、自然语言反馈。
真实世界部署
- 挑战:模拟器与真实世界之间的域间隙,硬件限制,安全性。
- 未来方向:真实世界数据收集、多模态大模型、物理仿真与现实世界的桥接。
多模态融合 BEYOND VLN
- 挑战:除了视觉和语言,如何整合其他模态(例如:触觉)。
- 未来方向:多感官融合、更全面的具身感知。
从示范和人类反馈中学习
- 挑战:如何有效地从人类示范和实时反馈中学习。
- 未来方向:交互式模仿学习、人类在环学习、逆强化学习。
人在环学习:
人类在环学习(Human-in-the-Loop Learning, HITL)是一种机器学习方法,它强调在模型训练和优化过程中融入人类专家的知识和判断。这种方法认为,尽管自动化算法和机器学习模型能够处理大量数据并从中学习,但它们可能在某些情况下缺乏对复杂情况的理解或无法达到所需的准确性。因此,通过将人类的直觉、专业知识和决策能力纳入学习循环中,可以显著提高模型的表现,并确保其在实际应用中的有效性和可靠性。
人类在环学习的关键点
持续反馈:在HITL框架下,人类提供实时反馈给机器学习模型,帮助其识别错误、修正偏差并改进预测。这种反馈机制使得模型可以在实际操作中不断学习和调整。
主动学习:这是一种特殊的HITL形式,其中系统会主动选择那些最有可能改进模型的数据样本给人类专家标注。这样可以更高效地利用有限的人力资源来提升模型性能。
解释性与透明度:为了更好地理解模型决策过程,有时需要开发更具解释性的AI工具。这有助于人类专家评估模型输出的质量,并据此作出相应的指导。
协作式决策制定:HITL不仅仅局限于纠正错误;它还涉及到人类与AI系统的紧密合作,共同完成任务。例如,在医疗诊断中,医生可能会参考AI提出的初步诊断建议,然后结合自己的经验和判断给出最终结论。