机器学习之数据预处理(一)
目录
一、数据预处理
1、数据清洗
(1) 处理缺失值
(2)处理异常值
2、特征转换
(1)特征标准化 / 归一化
(2)处理类别特征
3、特征选择与降维
1. 特征选择
2. 降维(高维数据)
4、数据划分
二、真实案例中的数据清洗
项目背景
环境准备
1. 导入必要库
2. 加载原始数据并筛选
3. 缺失值统计
4. 分离特征与标签
5. 标签编码(文本转数值)
6. 特征数值化(处理非数值特征)
7. 特征标准化(消除量级差异)
8. 划分训练集与测试集
9. 缺失值填充(随机森林法)
10. 类别不平衡处理(SMOTE 过采样)
11. 数据集拼接与打乱
12. 保存预处理后的数据
数据预处理是机器学习流程中至关重要的一步,直接影响模型性能。其核心目标是:将原始数据转换为适合模型输入的格式,包括处理缺失值、异常值、标准化特征、编码类别变量等。以下是常见的数据预处理步骤及实现方法:
一、数据预处理
1、数据清洗
(1) 处理缺失值
原始数据中常存在缺失值(NaN/None),需根据特征类型处理:
- 数值型特征:填充均值、中位数、众数或用模型预测缺失值。
- 类别型特征:填充众数或新增 “未知” 类别。
(2)处理异常值
异常值会干扰模型学习,可通过标准差法或四分位法(IQR) 检测并处理
2、特征转换
(1)特征标准化 / 归一化
- 标准化(Standardization):将特征转换为均值为 0、标准差为 1 的分布(适用于正态分布特征)。
公式:x' = (x - μ) / σ - 归一化(Normalization):将特征缩放到
[0,1]区间(适用于均匀分布特征)。
公式:x' = (x - min) / (max - min)
(2)处理类别特征
类别特征(如性别、城市)需转换为数值型
- 标签编码(Label Encoding):适用于有序类别(如 “低 / 中 / 高”),转换为
0,1,2...。 - 独热编码(One-Hot Encoding):适用于无序类别(如 “北京 / 上海 / 广州”),转换为哑变量。
3、特征选择与降维
1. 特征选择
移除冗余或无关特征,减少噪声:
- 方差选择:移除方差过小的特征(几乎无变化)。
- 相关性分析:移除高相关性特征(如皮尔逊系数 > 0.8)。
2. 降维(高维数据)
当特征维度极高(如文本、图像),可通过 PCA 降低维度
4、数据划分
将数据集分为训练集(模型训练)和测试集(性能评估)
二、真实案例中的数据清洗
矿物类型分类数据预处理全流程(含缺失值填充与类别平衡):在机器学习项目中,数据预处理的质量直接决定模型性能。本文以矿物类型分类任务为例,详细讲解从原始数据到建模输入的完整预处理流程,包括标签编码、特征转换、标准化、缺失值填充、类别平衡等关键步骤,并提供可复用的代码实现。
项目背景
本案例针对矿物类型分类任务,原始数据包含多个特征(如化学成分、物理属性等)和矿物类型标签。数据存在以下问题:
- 特征可能包含非数值类型
- 存在缺失值
- 类别分布可能不平衡(部分矿物样本少)
- 特征量级差异大
预处理目标:将原始数据转换为适合模型训练的格式,提升后续分类模型的精度和稳定性。
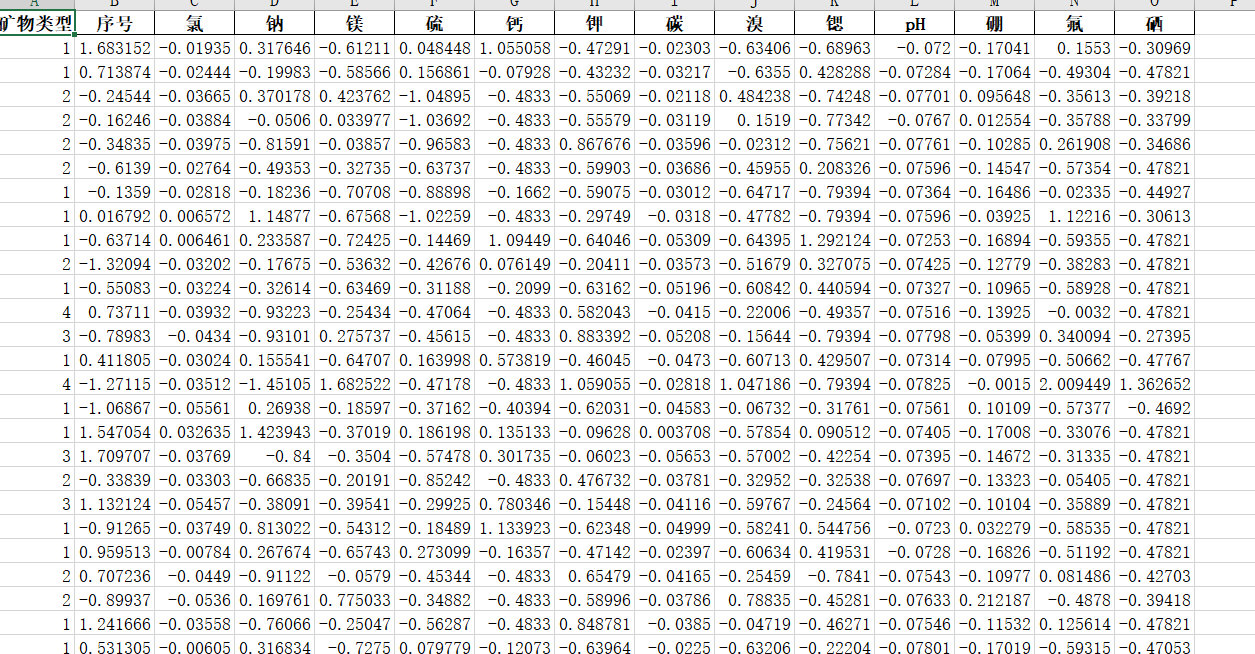
原始数据集如下:
此时图中有一些无用的字符,还有一些空值,接下来要对这组数据进行数据预处理
环境准备
需要安装的库:
pip install pandas scikit-learn imblearn openpyxl1. 导入必要库
import pandas as pd- 作用:导入 pandas 库(数据处理的核心工具),用于读取、清洗和转换数据。
- 必要性:pandas 提供了 DataFrame 数据结构,方便处理表格型数据(如 Excel 中的矿物数据)。
2. 加载原始数据并筛选
# data = pd.read_excel('矿物数据.xls') # 加载原始数据
# data = data[data['矿物类型'] != 'E'] # 过滤掉矿物类型为'E'的样本pd.read_excel:读取 Excel 文件,返回 DataFrame 格式(表格数据)。假设矿物数据.xls包含特征列(如化学成分、物理属性)和标签列'矿物类型'。- 筛选操作
data['矿物类型'] != 'E':排除标签为'E'的样本(可能是异常类别、无效数据或无需预测的类别)。
3. 缺失值统计
null_num = data.isnull() # 生成布尔矩阵,标记每个单元格是否为缺失值(True/False)
null_total = null_num.sum() # 按列统计缺失值总数(True计为1,False计为0)- 作用:分析数据中缺失值的分布情况,为后续缺失值处理提供依据(例如:若某列缺失值占比过高,可能需要删除该特征)。
4. 分离特征与标签
x = data.drop('矿物类型', axis=1) # 特征数据:删除标签列,保留所有特征列
y = data.矿物类型 # 标签数据:仅保留"矿物类型"列(预测目标)机器学习数据格式要求:特征(x)和标签(y)需分开存储,符合模型输入格式(如model.fit(x, y))
5. 标签编码(文本转数值)
lable_dict = {'A': 1, 'B': 2, 'C': 3, 'D': 4} # 定义标签映射规则(文本→数值)
encoded_label = [lable_dict[label] for label in y] # 批量转换标签
y = pd.Series(encoded_label, name='矿物类型') # 转换为Series并保留列名- 必要性:机器学习模型只能处理数值输入,需将原始文本标签(如 'A'、'B')转换为整数(1、2 等)。
- 细节:
- 列表推导式
[lable_dict[label] for label in y]高效完成批量转换。 - 用
pd.Series封装确保标签格式与后续特征数据兼容(均为 pandas 数据结构)。
- 列表推导式
6. 特征数值化(处理非数值特征)
for column_name in x.columns:x[column_name] = pd.to_numeric(x[column_name], errors='coerce')- 作用:将所有特征列强制转换为数值类型,无法转换的值标记为缺失值(
NaN)。 - 参数解析:
pd.to_numeric:尝试将列转换为 int/float 类型。errors='coerce':遇到非数值(如文本、特殊符号)时不报错,而是转为NaN(后续统一处理缺失值)。
- 背景:原始特征可能包含文本描述(如 "高 / 中 / 低"),必须转为数值才能被模型识别。
7. 特征标准化(消除量级差异)
from sklearn.preprocessing import StandardScaler # 导入标准化工具
scaler = StandardScaler() # 初始化标准化器
x_z = scaler.fit_transform(x) # 对特征进行标准化
x = pd.DataFrame(x_z, columns=x.columns) # 转换回DataFrame并保留列名- 原理:标准化公式为
x' = (x - 均值) / 标准差,将所有特征缩放至均值 = 0、标准差 = 1 的分布。 - 必要性:不同特征可能有不同量级(如 "硬度" 范围 1-10,"密度" 范围 2-5),标准化可避免量级大的特征主导模型训练(对 SVM、逻辑回归等模型尤为重要)。
- 细节:
scaler.fit_transform(x)同时完成 "计算均值 / 标准差" 和 "转换数据" 两步,转换后用pd.DataFrame保留列名,方便后续处理。
8. 划分训练集与测试集
from sklearn.model_selection import train_test_split # 导入数据集划分工具
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=5
)- 作用:将数据分为训练集(80%,用于模型学习)和测试集(20%,用于评估模型泛化能力)。
- 参数解析:
test_size=0.2:测试集占比 20%。random_state=5:固定随机种子,确保每次运行划分结果一致(可复现性)。
- 关键原则:划分必须在缺失值填充、过采样等步骤之前,避免测试集信息泄露到训练集(如用测试集的均值填充训练集)。
9. 缺失值填充(随机森林法)
import fill_na # 导入自定义缺失值填充模块
# 填充训练集缺失值
x_train_fill, y_train_fill = fill_na.rf_train_fill(x_train, y_train)
# 用训练集的规则填充测试集缺失值(避免数据泄露)
x_test_fill, y_test_fill = fill_na.rf_test_fill(x_train_fill, y_train_fill, x_test, y_test)- 作用:用随机森林模型预测缺失值(比均值 / 中位数填充更精准)。
- 自定义函数逻辑:
rf_train_fill:对训练集,用无缺失的特征训练随机森林,预测并填充缺失值(利用特征间的相关性,如 "硬度高的矿物密度可能也高")。rf_test_fill:对测试集,严格使用训练集的模型参数填充(确保测试集不影响填充规则,避免数据泄露)。
- 优势:相比简单填充(如均值),随机森林填充考虑了特征关联,结果更接近真实值。
10. 类别不平衡处理(SMOTE 过采样)
from imblearn.over_sampling import SMOTE # 导入SMOTE过采样工具
oversampler = SMOTE(k_neighbors=1, random_state=0) # 初始化SMOTE
# 对训练集进行过采样(仅训练集!)
os_x_train, os_y_train = oversampler.fit_resample(x_train_fill, y_train_fill)- 问题背景:若某些矿物类型样本极少(如 'A' 占 90%,'B' 仅占 10%),模型可能倾向于预测多数类,导致少数类识别效果差。
- SMOTE 原理:在少数类样本的近邻之间合成新样本,平衡类别比例(如将 'B' 的样本从 100 条增至与 'A' 相同的 900 条)。
- 参数解析:
k_neighbors=1:基于最近的 1 个样本合成新数据(k 值越小,合成样本越接近原始样本,减少噪声)。- 仅对训练集过采样:测试集需保持原始分布(反映真实场景的类别比例)。
11. 数据集拼接与打乱
# 拼接训练集标签和特征,并打乱顺序
data_train = pd.concat([os_y_train, os_x_train], axis=1).sample(frac=1, random_state=0)
# 拼接测试集标签和特征(无需打乱)
data_test = pd.concat([y_test_fill, x_test_fill], axis=1)- 作用:将标签与特征合并为完整数据集,方便保存和后续建模。
- 细节:
pd.concat(..., axis=1):按列拼接(标签列 + 特征列),形成完整表格。sample(frac=1):将训练集随机打乱(避免模型学习数据顺序,与任务无关的规律)。- 测试集无需打乱:评估时顺序不影响结果。
12. 保存预处理后的数据
data_train.to_excel(r'./训练数据集[随机森林填充数填充].xlsx', index=False)
data_test.to_excel(r'./测试数据集[随机森林数填充数填充].xlsx', index=False)- 作用:将预处理后的数据集保存为 Excel,供后续模型训练直接使用(无需重复预处理)。
- 参数解析:
to_excel:pandas 保存 Excel 文件的函数,路径./表示当前目录。index=False:不保存 DataFrame 的索引列(索引对建模无用,节省空间)。
根据如上步骤就完成了本数据集的数据预处理,完整数据预处理代码如下:
import pandas as pd
data=pd.read_excel('矿物数据.xls')
data=data[data['矿物类型']!='E']
null_num=data.isnull()
null_total=null_num.sum()
x=data.drop('矿物类型',axis=1)
y=data.矿物类型
lable_dict={'A':1,'B':2,'C':3,'D':4}
encoded_label=[lable_dict[label] for label in y]
y=pd.Series(encoded_label,name='矿物类型')
for column_name in x.columns:x[column_name]=pd.to_numeric(x[column_name],errors='coerce')
from sklearn.preprocessing import StandardScaler
scaler=StandardScaler()
x_z=scaler.fit_transform(x)
x=pd.DataFrame(x_z,columns=x.columns)
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.2,random_state=5)
import fill_na
x_train_fill, y_train_fill = fill_na.rf_train_fill(x_train, y_train)
x_test_fill, y_test_fill = fill_na.rf_test_fill(x_train_fill, y_train_fill, x_test, y_test)
from imblearn.over_sampling import SMOTE
oversampler = SMOTE(k_neighbors=1, random_state=0)
os_x_train, os_y_train = oversampler.fit_resample(x_train_fill, y_train_fill)
data_train = pd.concat([os_y_train, os_x_train], axis=1).sample(frac=1,random_state=0)
data_test = pd.concat([y_test_fill, x_test_fill], axis=1)
data_train.to_excel(r'./训练数据集[随机森林填充数填充].xlsx',index=False)
data_test.to_excel(r'./测试数据集[随机森林数填充数填充].xlsx',index=False)
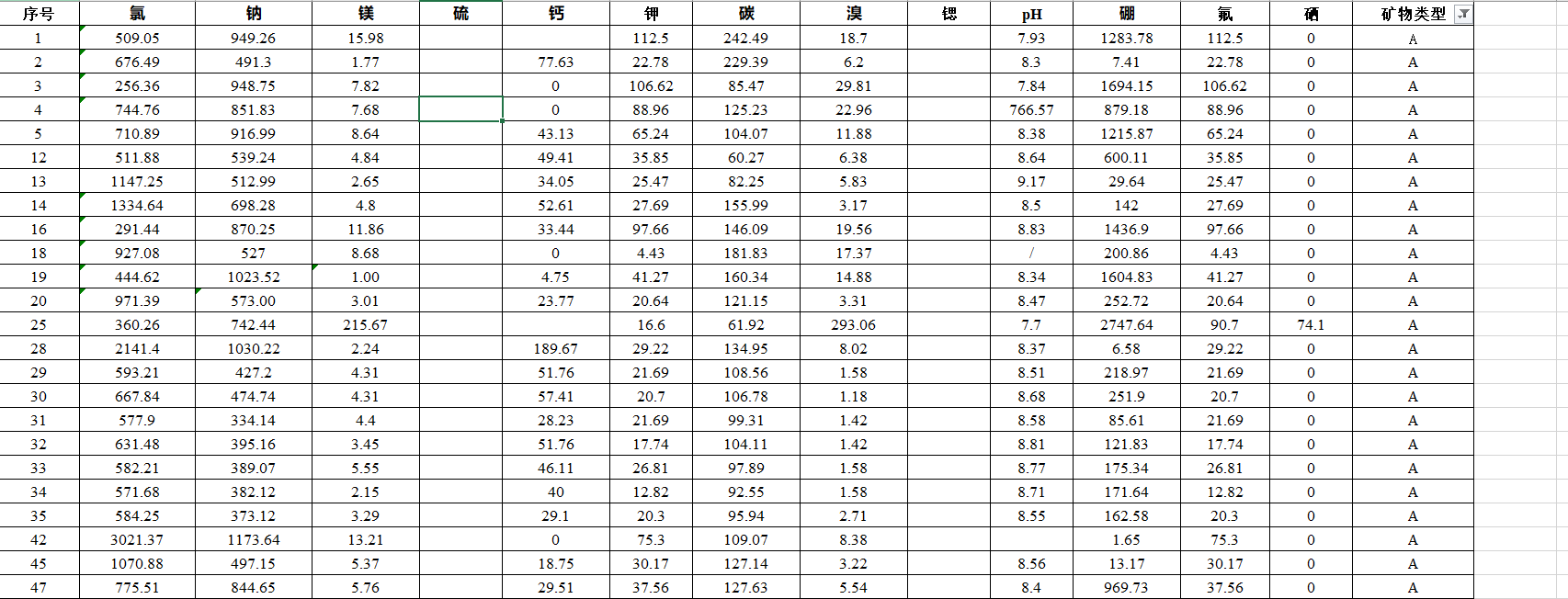
处理之后的数据如下: