考研408《计算机组成原理》复习笔记,第五章(2)——CPU指令执行过程

一、指令执行基本流程
为了方便下面的知识点理解,要先明白一个指令到底是怎样一个执完整行流程
中断是操作系统OS的知识点,各位应该都学过,这里懒得解释了
二、指令周期
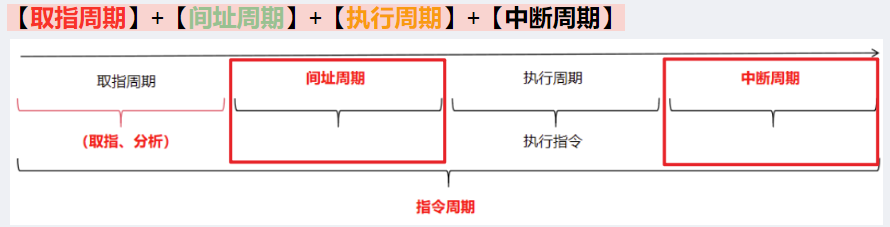
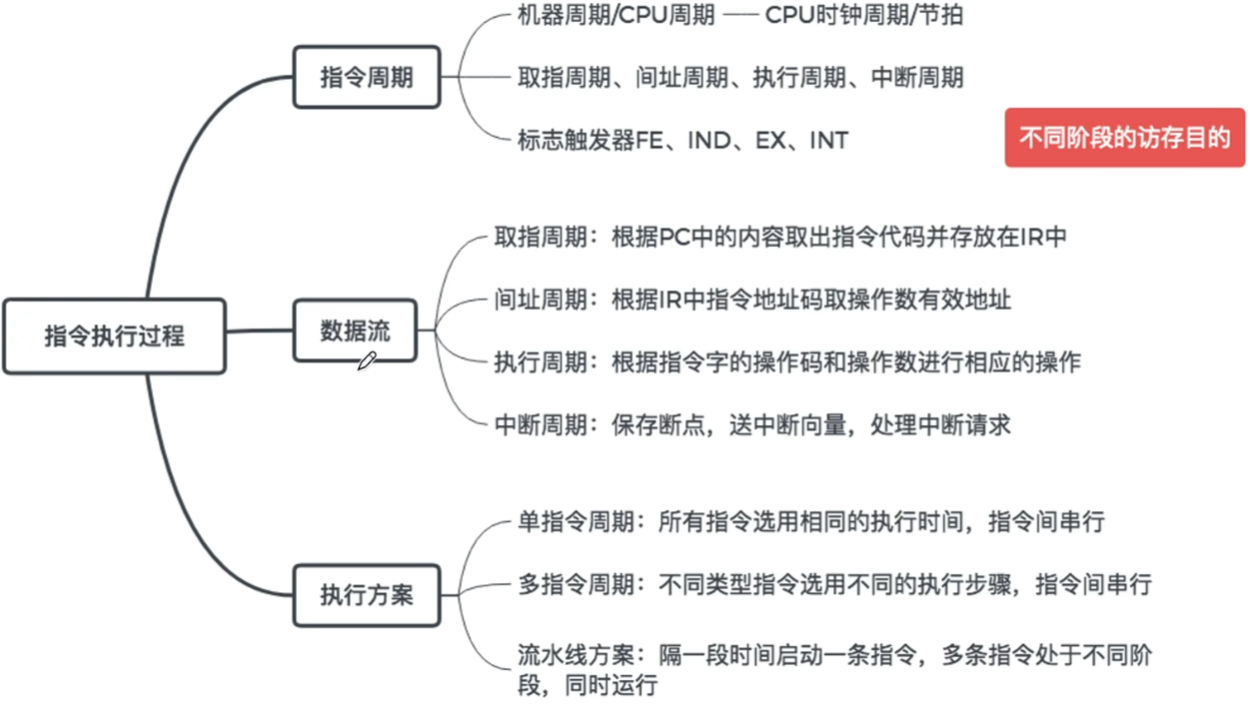
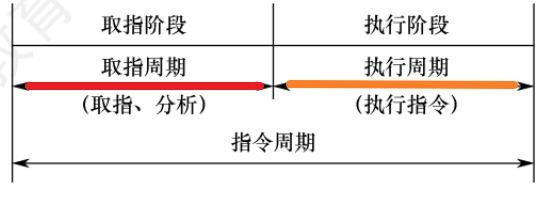
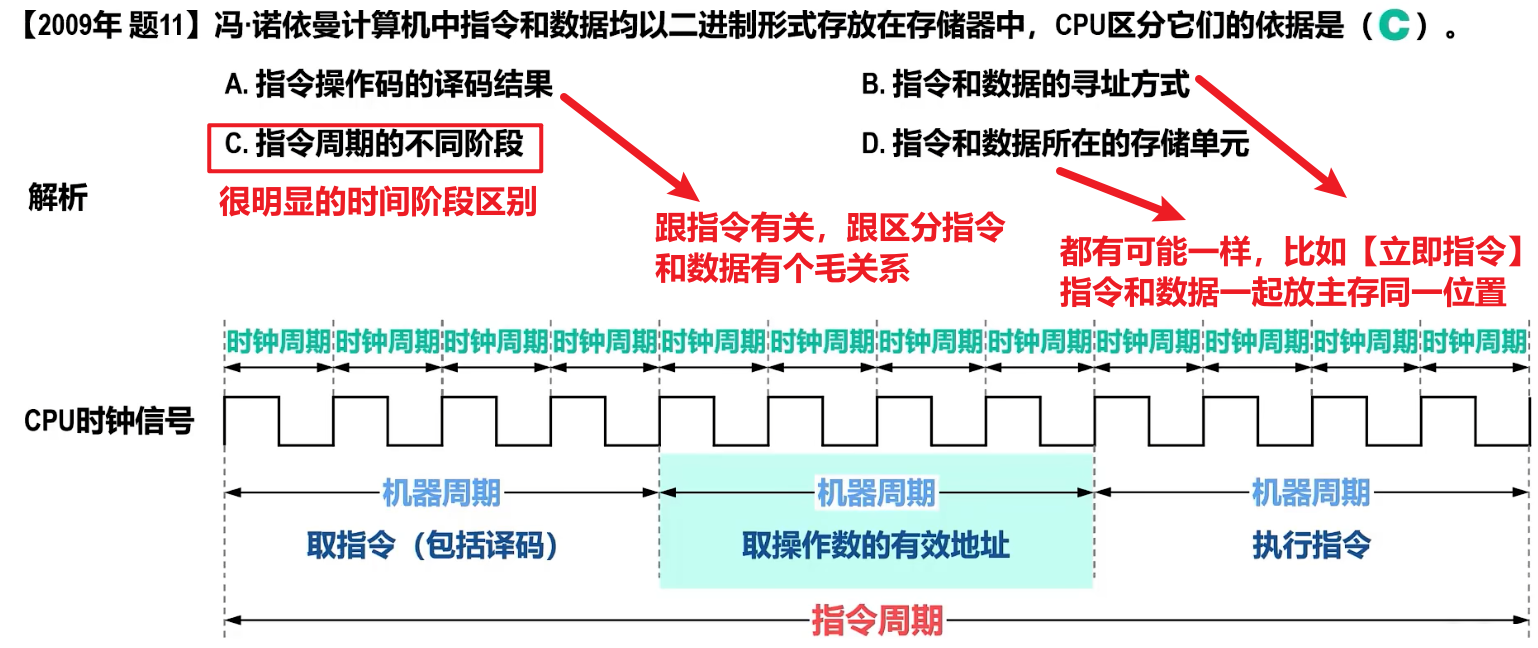
【指令周期】:就是CPU【取出指令 并 执行完一条指令】所需要的时间
1、【指令周期】分为哪些阶段
回顾指令知识点:
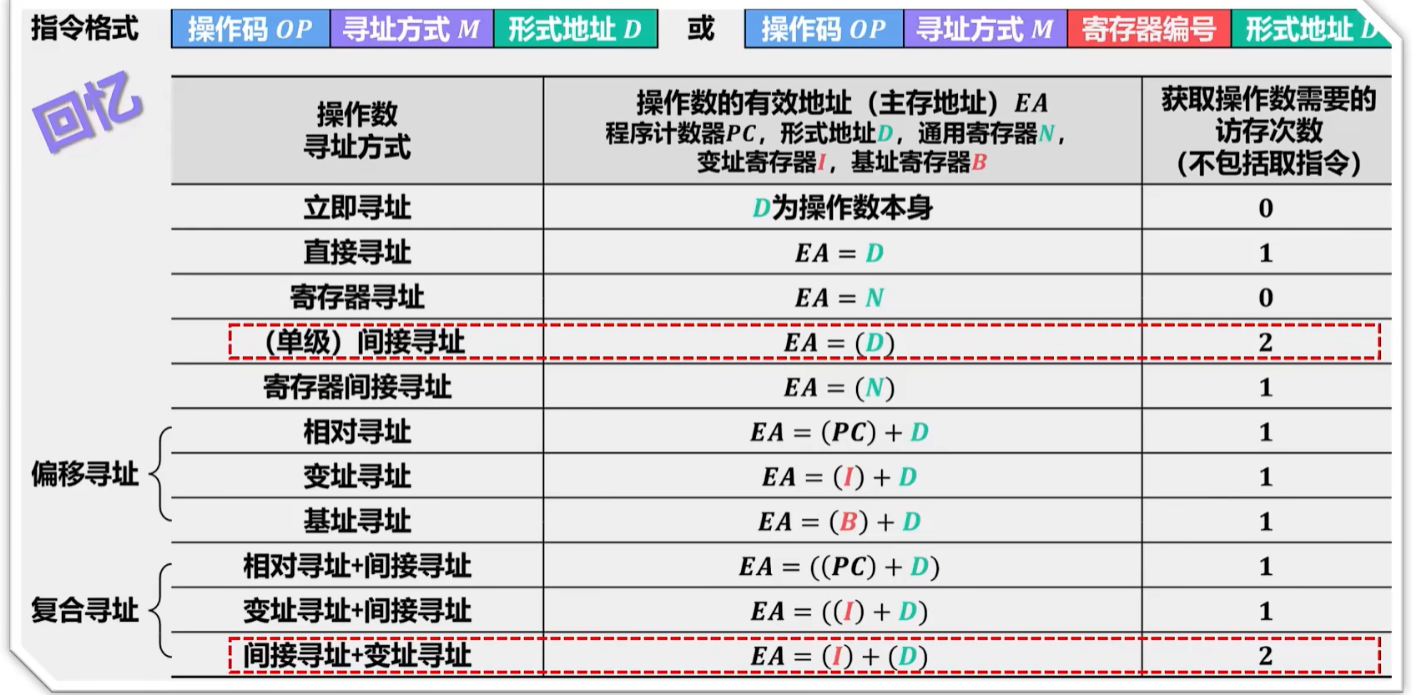
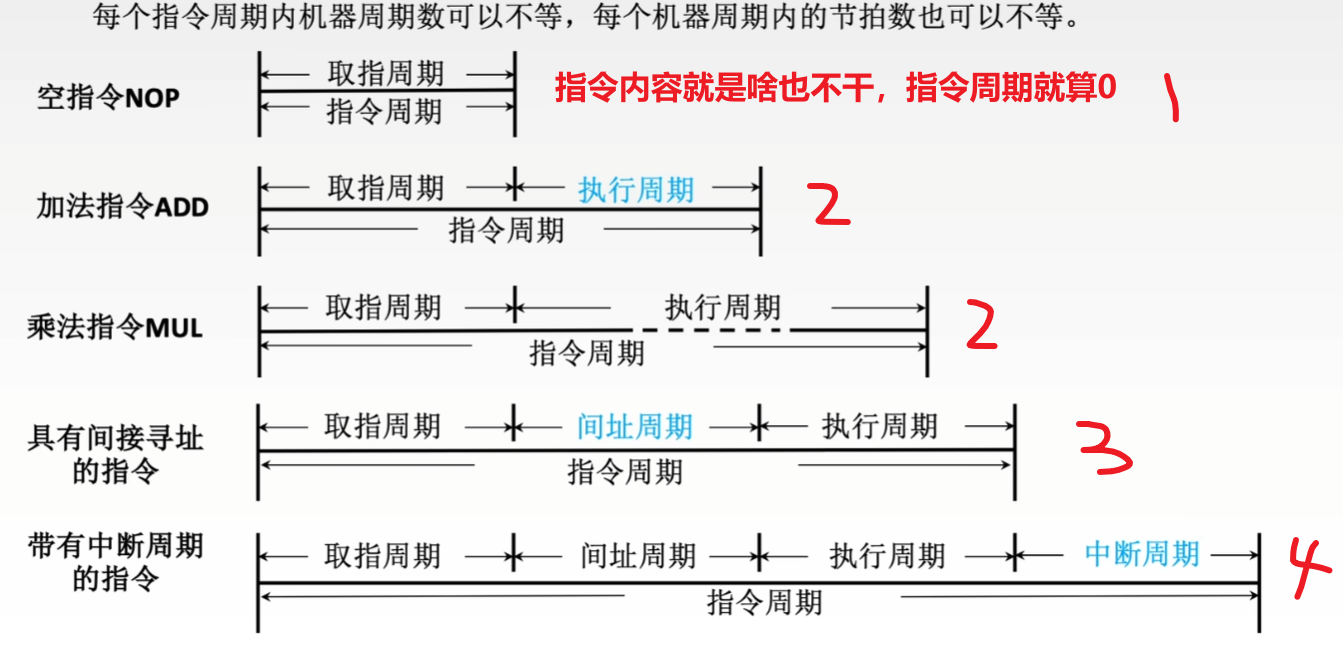
根据指令类型不同,【指令周期】分为两种:
- 1、【无条件转移指令】:通常执行阶段无需访问主存,就算取指阶段也只用访问一次主存
- 所以只包含【取指阶段】+【执行阶段】
- 【取指阶段】还包括【取指】+【分析】(不然看不懂指令怎么执行?)
- 对应所花费的时间就叫【取指周期】+【执行周期】
- 2、【间接寻址指令】:给出的是形式地址,需要先去主存取指令有效地址,然后再访问主存取出指令,要访问2次主存
- 所以需要【取指阶段】+【间址阶段】+【执行阶段】
- 对应所花费的时间就叫【取指周期】+【间址周期】+【执行周期】
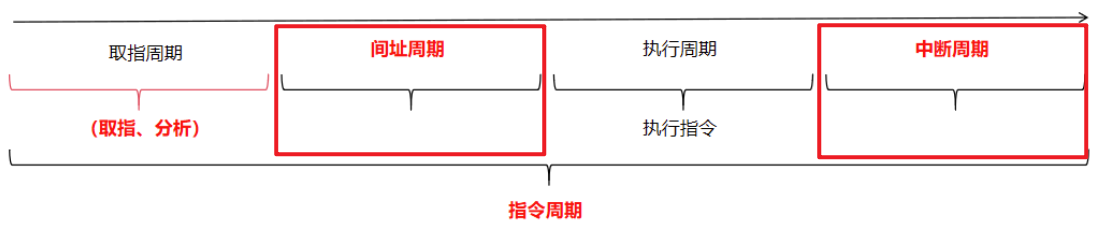
- 最后不管是哪种指令,如果CPU采用中断方式,指令结束前CPU会发出中断查询,若有【中断请求】,CPU还会进入【中断阶段】
- 所以!最完整的【指令周期】(包含间接寻址的指令)是4个阶段!
- 【取指周期】+【间址周期】+【执行周期】+【中断周期】
注意:
- 题目没提到上面提到的【总线周期】或【I/O周期】,默认不存在、不用管
- 然后我说的最完整的【指令周期】是涵盖了【间接寻址】的
- 如果是直接【无条件转移指令】就无需考虑【间址周期】


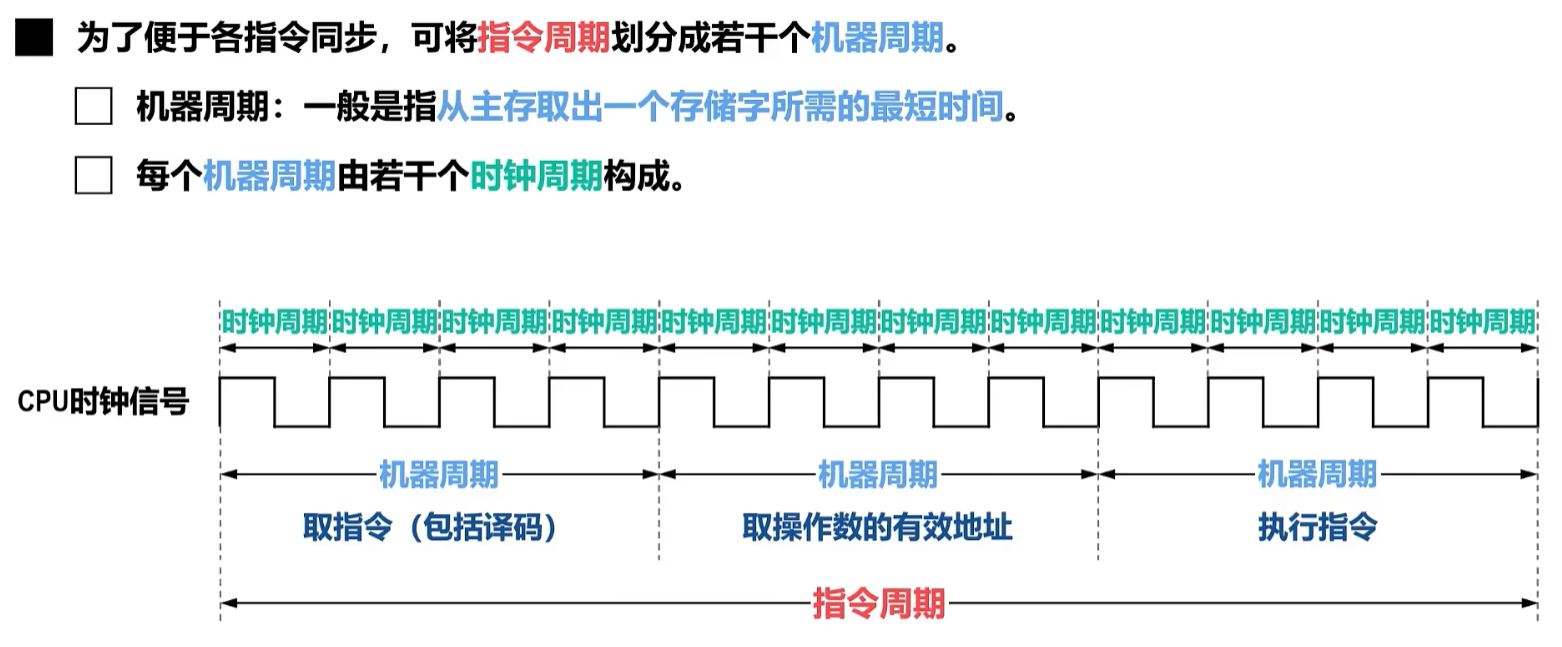
2、机器周期、时钟周期回顾
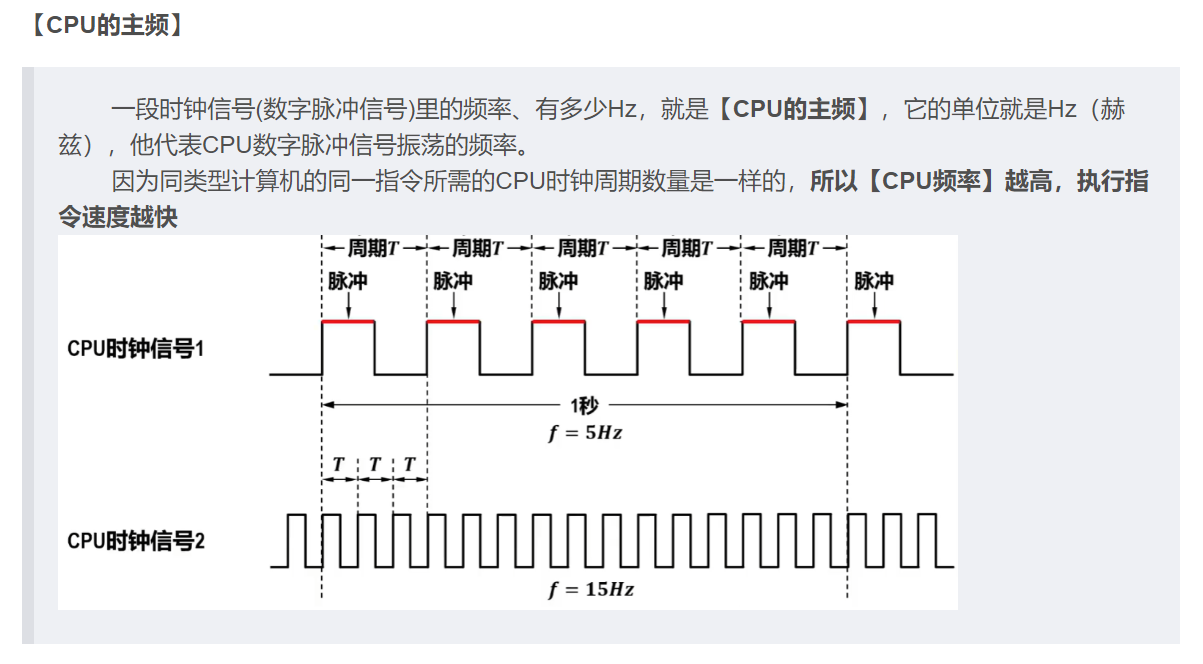
那么一个指令周期究竟多长怎么表达?那就是用到专门的单位【机器周期】、【时钟周期】了(就像描述时间的单位是小时、分钟、秒.......)
注意:
- 【时钟周期】又称【节拍】、【CPU时钟周期】
- 是最小的时间单位、cpu操作的最基本单位,一段信号里【时间周期】之间都是固定一样大小;
- 【主频】是数字脉冲信号震荡的频率,是【时钟周期的倒数】(可以理解【时间周期】是【主频】的份数),频率越高,则时钟周期越短
- 一个【机器周期】又叫【CPU周期】
- 包含多个【时钟周期】,一段信号里各个【机器周期】之间没有固定的长度

那么一个【指令周期】又由多个【机器周期】组成
;
;
然后【指令周期】又分为【定长指令周期】和【变长指令周期】:
- 【定长指令周期】:1个指令内的【机器周期】长度一样
- 【变长指令周期】:1个指令内的【机器周期】长度不一样
- 因为【取指令】需要访问【主存】
- 但是【执行指令】时只要指令到了CPU,若不再需要访问主存的话,就会以飞快的速度执行
- 所以不同阶段所需要的【机器周期长度】应该是不同的,就会有【变长指令周期】
甚至可以说【变长指令周期】的依据是【时钟周期】
;
不同指令所需要的【机器周期数量】也是不同的:

3、例题
三、指令周期数据流
由于教材和视频的写法不统一,很乱,所以我做了一个统一的写法
而且标出了专业的流程写法,比如(PC)—>MAR,请务必记住
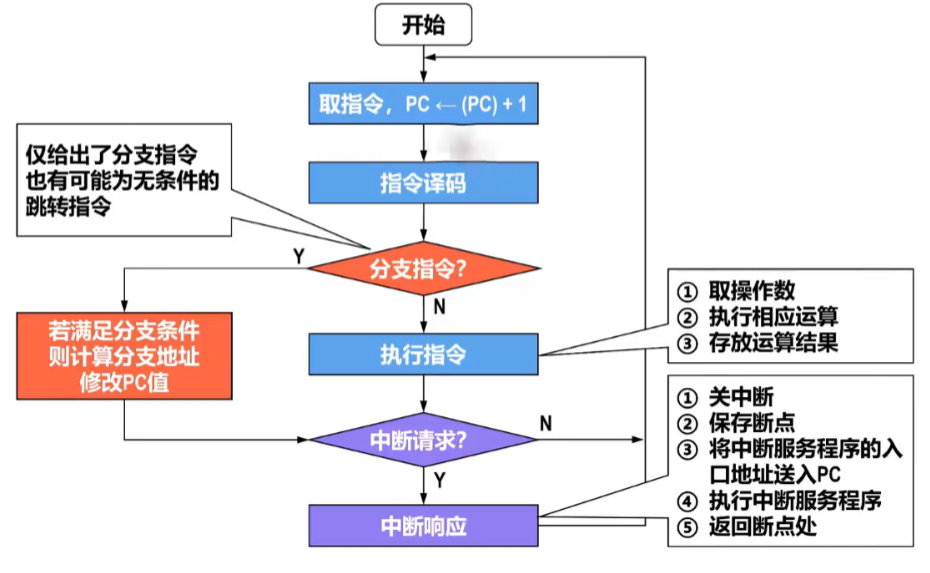
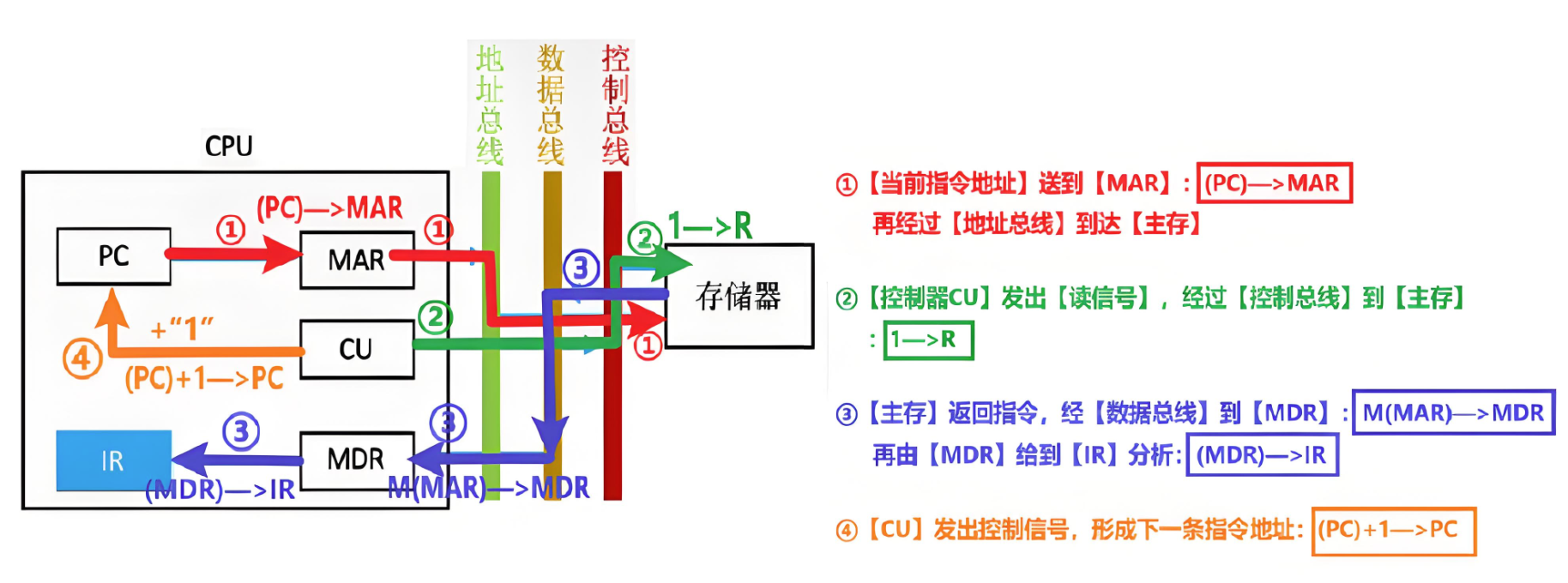
1、【取指周期】
取指周期的任务是:根据PC中的指令地址,从主存里取出指令并送到IR进行分析指令
注意:
- 取指令的同时,CU会发出控制信号,让【PC+“1”】
- 但要留意后面我们会学到【中断周期】,涉及到的是【堆栈】,堆栈地址是自上到下、地址高位到低位,所以【PC+“1”】对应【SP-“1”】
- 【1—>R】意思是【Read读信号】为【1】,发出【读命令】
- 【M(MAR)—>MDR】是【MEM(MAR)—>MDR】的缩写,【MEM(M)】就是【Memory寄存器】
- 之所以是(MAR)—>(MDR),并不是主存会把数据先给MAR再给MDR,而是因为主存收到读命令后,根据MAR指向的地址找到内容,再给MDR
- 或者你可以理解为CPU里的MAR把地址给到主存的MAR,在CU发出读命令后,主存再根据自己的MAR去找该地址指令
说白了就是:1去(去主存) ——> CU发命令(读命令) ——> 1回(回CPU的IR) ——> 下一轮

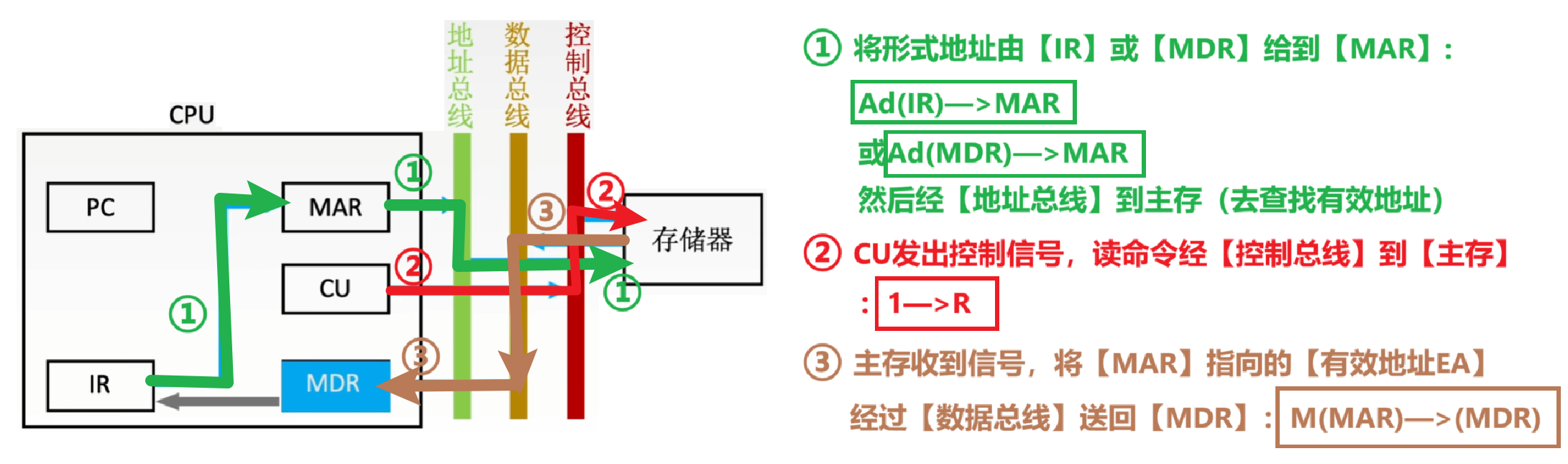
2、【间址周期】
间址周期的任务:根据指令地址码的形式地址,去主存取出操作数有效地址
- 将指令中的【地址码】送到【MAR】并经过【地址总线】送到主存,CU发出读命令存取出有效地址,最后返回【MDR】
注意:
- 其中【Ad(IR)】表示取出IR中存放指令的地址字段,也就是【操作码的形式地址】
说白了就是:1去(去主存) ——> CU发命令(读命令) ——> 1回(回CPU的MDR)
3、【执行周期】

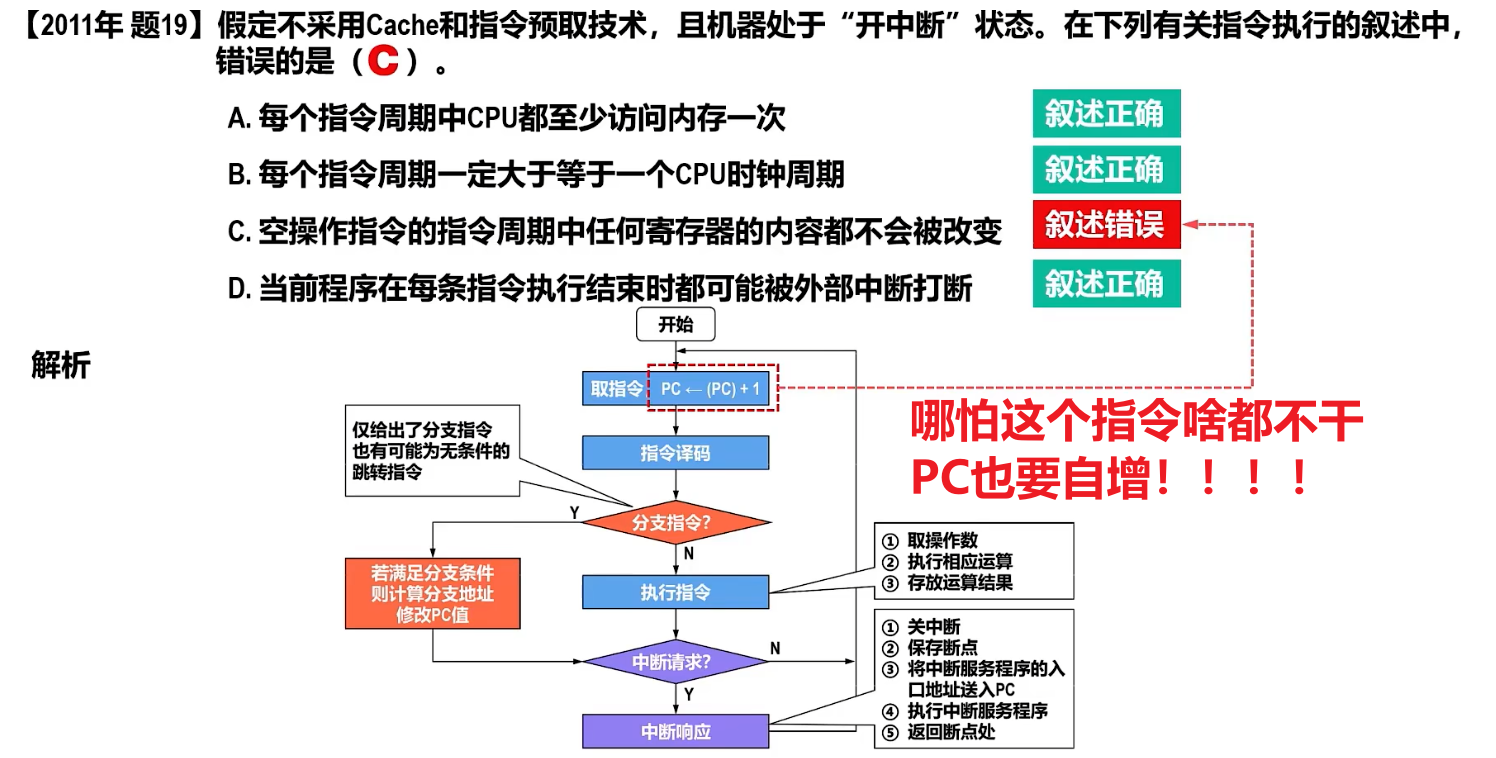
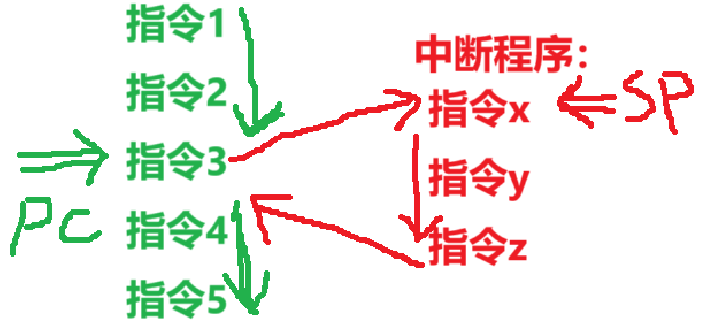
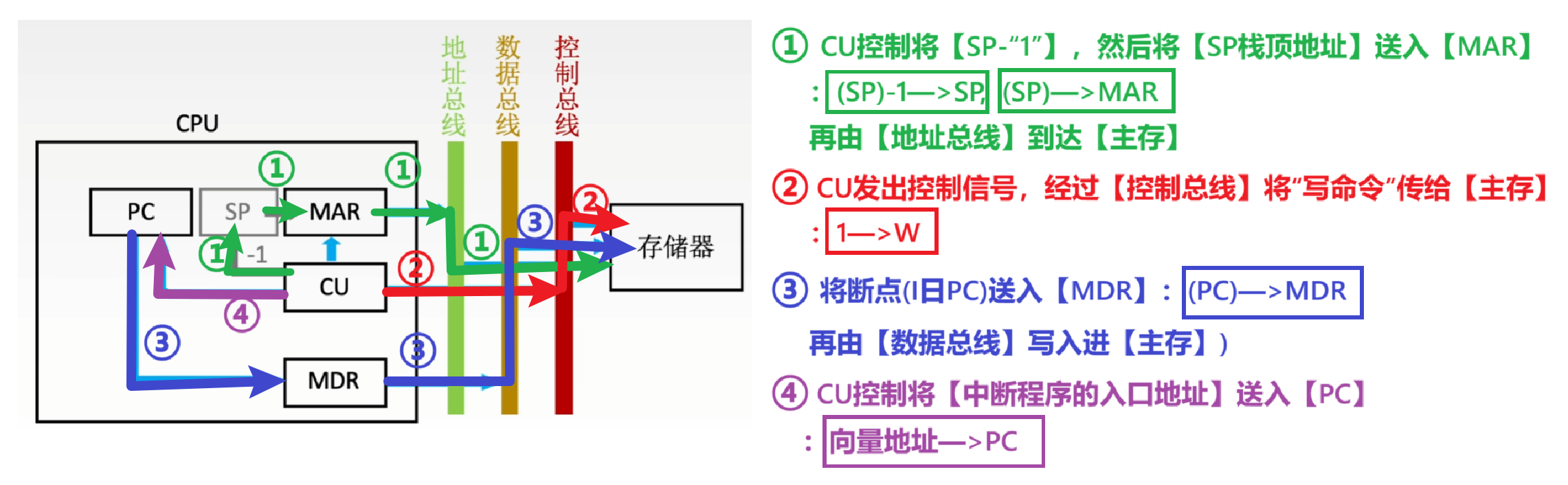
4、【中断周期】
中断周期的任务:保存断点,将【中断程序的入口地址】给到【PC】
- PC放下一次预执行的指令嘛,把中断程序的起始指令地址给他就能开始执行中断的程序指令了;同时还得保存老PC值,一遍执行完中断回来干旧活
要理解中断周期,需要先知道几个事:
- 1、中断其实有点像函数调用,CPU收到【中断请求】,就会暂停当前任务,转而处理【中断程序】,也就暂时改变【PC+“1”】流程,跳转到别的指令
- 那么【新PC】记录的会是【中断程序】里的指令位置,为了处理完中断程序后能恢复原来任务,还得考虑保存断点(【旧PC】)
- 2、中断阶段一般采用【堆栈】保存断点,而堆栈用的是【SP指针】
- 保存在【栈顶】
- 然后由于【堆栈】和【主存】的地址顺序不一样(从栈底到栈顶,由高地址到低地址)
- 所以【PC+“1”】对应【SP-“1”】
- 【堆栈】是主存中的一部分数据结构,所以本质还是【写入主存】
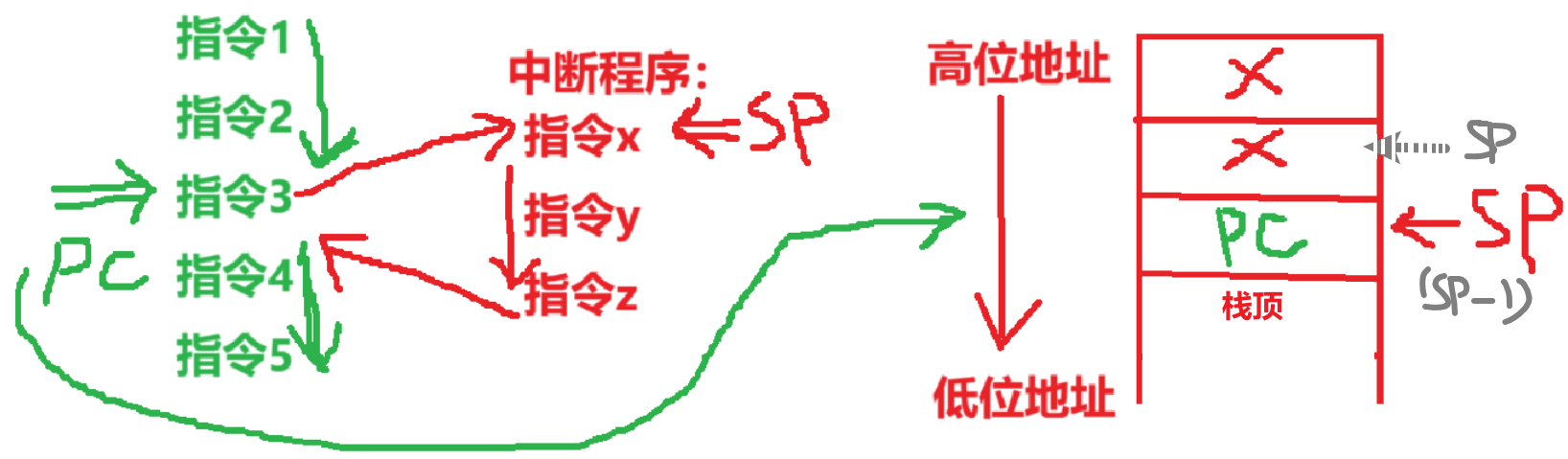
注意:
- 【1 —> W】意思是【Write写信号】为【1】,发出【写命令】
- 因为【SP】代表【旧PC】存在堆栈栈顶,但是堆栈本质也是【主存一部分】,所以要【写入主存】
说白了就是:存旧PC —> CU发命令(写命令) ——> 改新PC(CU设置)
【总结特点】(重要!!)
所以其实可以发现,这些流程都是有特点的,如果你死记硬背就会崩溃(我靠单押了)
CU的【读 / 写控制信号】有很大的作用:
- 1、控制数据总线上数据流的方向:
- 是流入存储器
- 还是流出存储器
- 2、控制存储器操作的是【读信息】还是【写信息】
- 那我画一下大致套路:
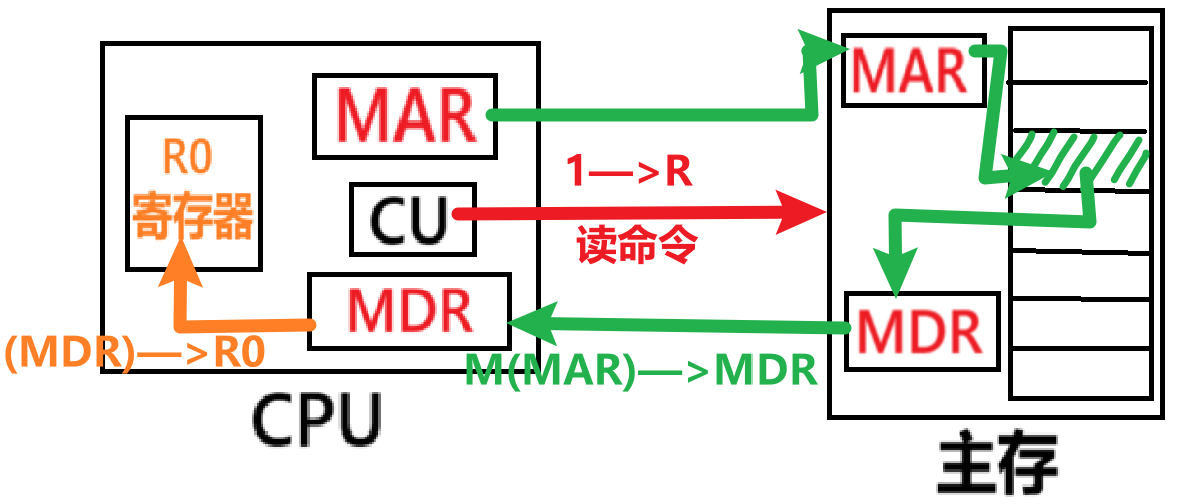
- 【读信号】:让主存数据流出存储器,读入到R0寄存器,套路都是:
- 1——>R
- M(MAR)——>MDR
- (MDR)——>R0
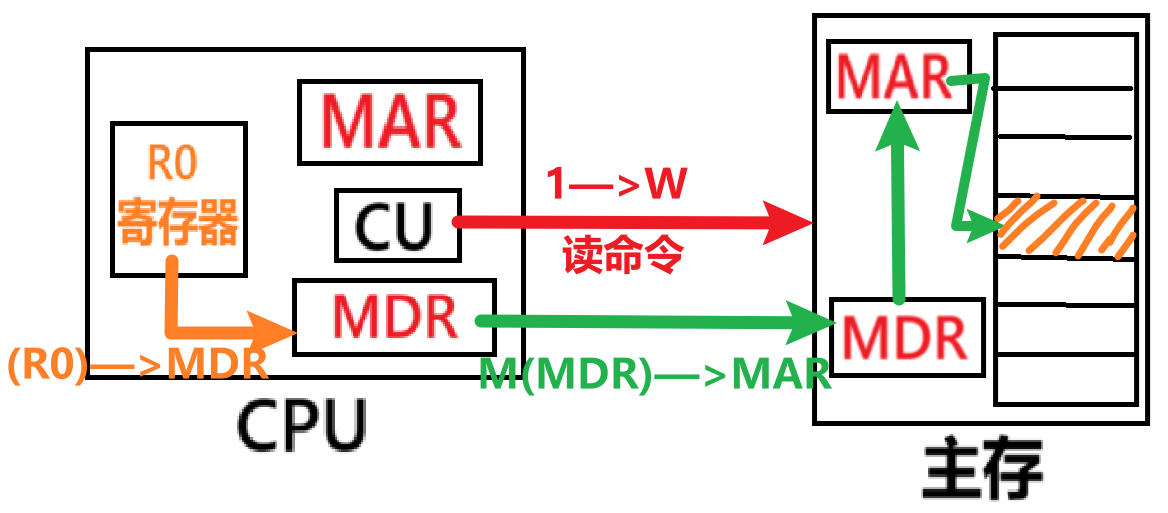
- 【写信号】:让数据流出R0,流入主存存储器,写入到主存,套路都是:
- 1——>W
- R0——>MDR
- M(MDR)——> MAR
【例题】

四、指令执行方案
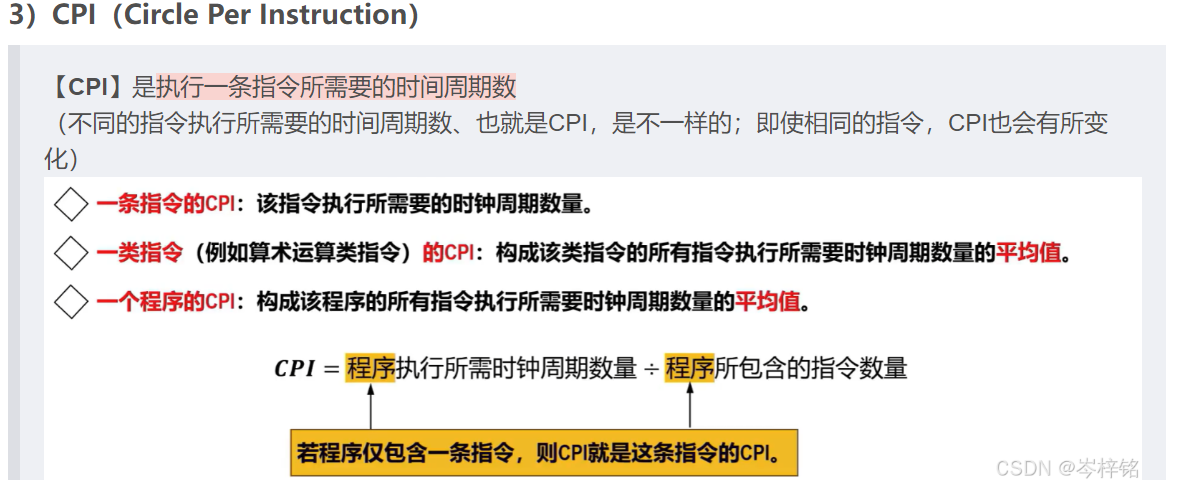
首先回顾一下知识点【CPI】、【IPS】

1、单周期处理器(CPI=1)
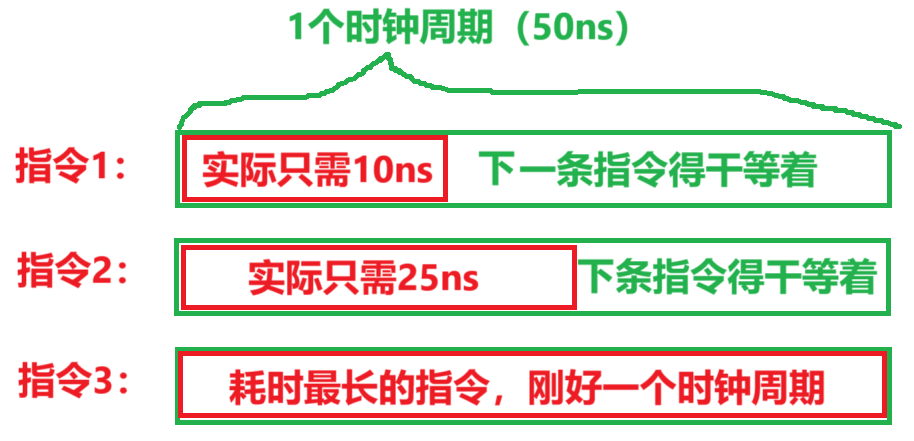
第一种方案是采用【单指令周期】,重点:
- 所有指令都规定用【1个时钟周期】完成,【CPI = 1】
- 而【时钟周期大小】取【需耗时最长的指令的执行时间】
- 指令之间【串行】执行!!
- 看似很快很牛逼,但是实则还是要适应最久的指令,还是大家要干等着浪费时间
- 注意:下一条指令只能等上一条指令结束才能启动
- 【难点】:
- 留意这么个知识点:
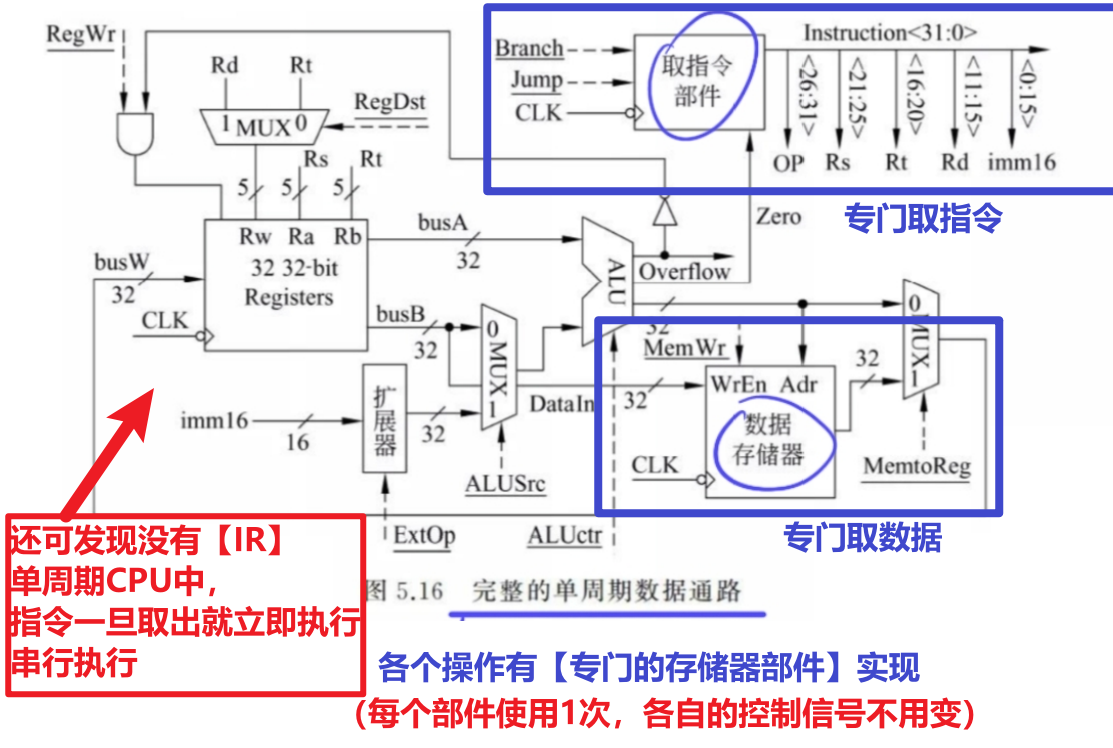
- 1、单周期CPU没有【IR】,因为每个指令固定用【1个时钟周期】,所以指令一取出直接执行,以最快速度完成一条指令
- 2、【控制信号不会变】:【取指令】、【取数据】有专门的部件分开工作,所以不需要改变控制信号,记住就行了
- 3、单周期CPU需要搭配【多总线CPU结构】或【专用通道结构】、不能用【单总线CPU结构】,这里不理解可以看下一节的笔记会讲,大概原因就是单总线会导致数据冲突,所以单总线只允许同一时刻一个部件允许、发数据,那要想在一个时钟周期完成一个指令的那么阶段操作,肯定得要求同一时刻各个部件能够同时工作
2、多周期处理器(CPI>1)
第二种方案是采用【多指令周期】,重点:
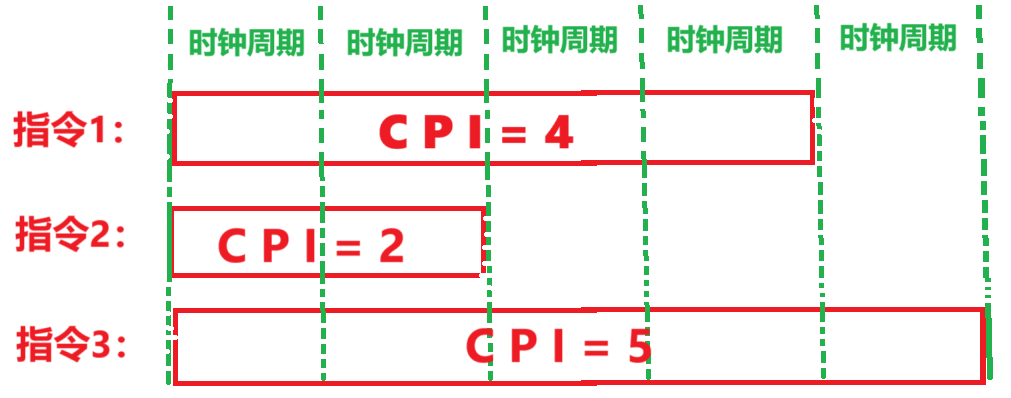
- 【不同类型】的指令都选用【不同时钟周期】完成,【CPI > 1】
- 而【时钟周期大小】取【需耗时最长的指令的执行时间】
- 指令之间【串行】执行!!
- 但是多周期处理器需要更复杂的硬件设计,总体上还是又快性能又好
- 【难点】:
- 留意这么个知识点:
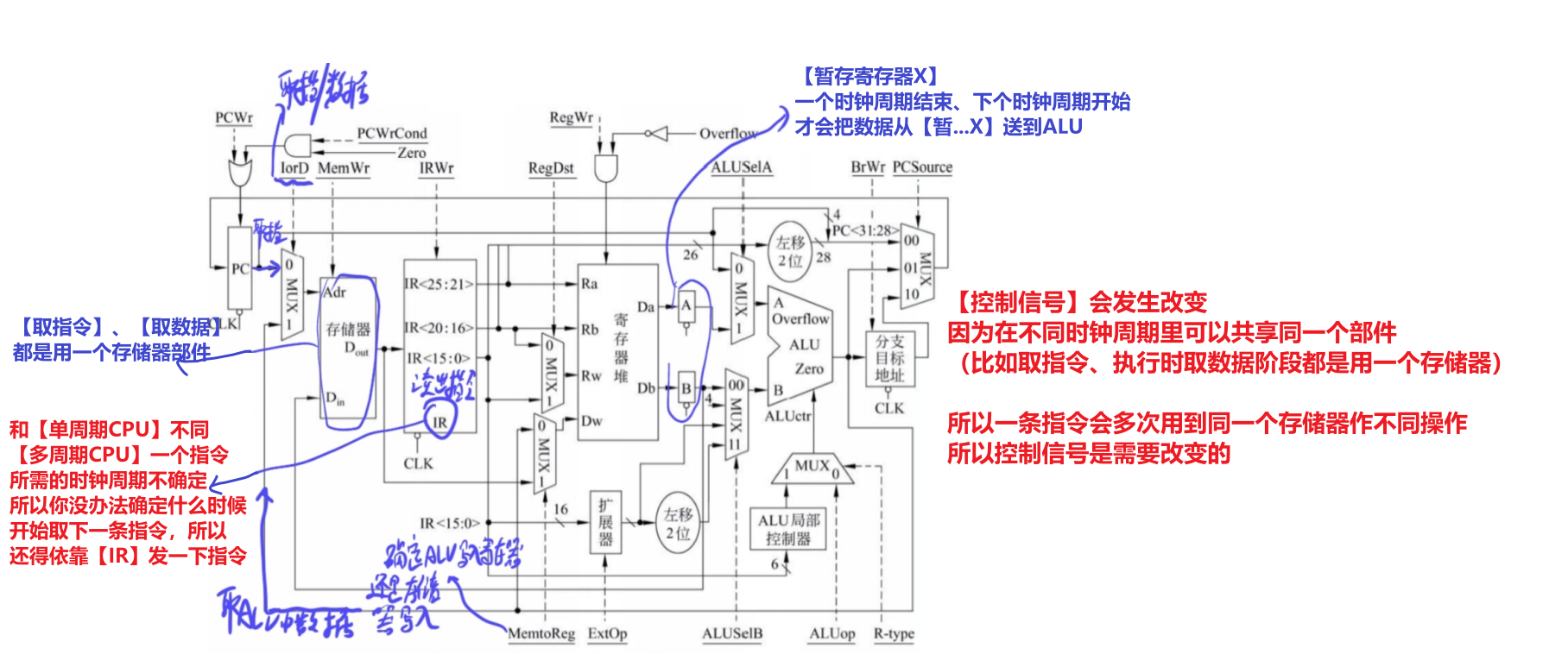
- 1、多周期CPU有【IR】,因为每个指令不确定要用几个时钟周期,不知道啥时候取下一指令,就需要IR控制发一下指令
- 2、【控制信号会改变】:因为在不同的时钟周期里(取指阶段、执行指令时取数据...)都共享一个部件(比如存储器),所以一条指令会多次用到同一个部件做不同操作,就需要改变控制信号
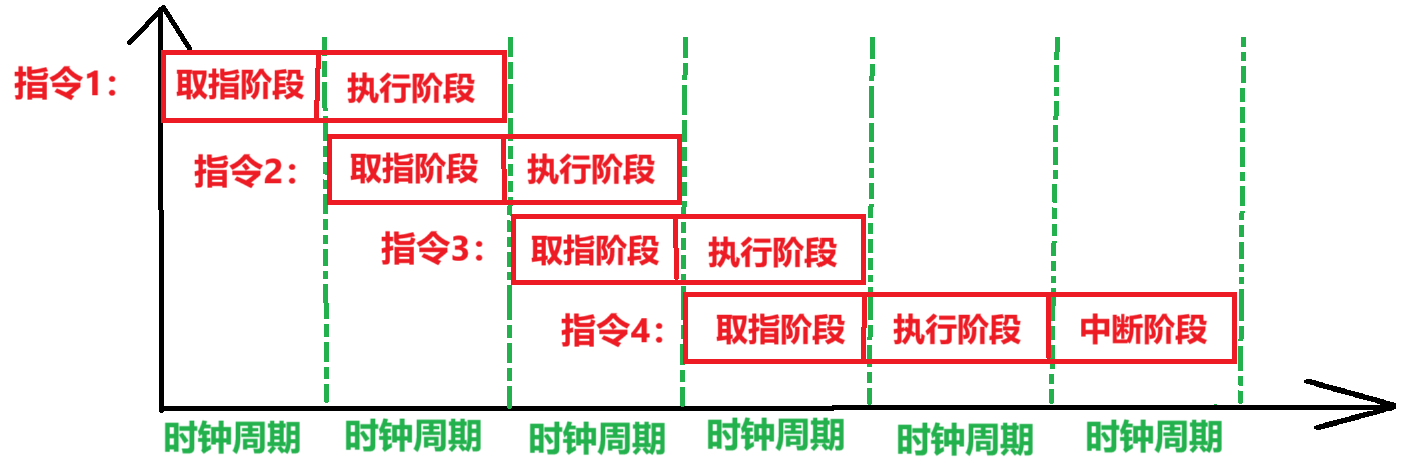
3、流水线处理器(CPI=1)
第3种方案是采用【流水线方案】,重点:
- 【每1个时钟周期】启动一条指令
- 注意,并不是一个时钟周期执行完一条指令,启动下一条指令的时候,可能上一条指令并没有执行完
- 前面我们学过【一条指令的执行】可以分为【多个阶段】,所以这里意思就是上一指令或许刚完成一个阶段,有一些部件比如PC、IR用完了空闲了,下一条指令刚好可以使用这些部件,就马上启动了
- 只有【理想状态】下,真的每一个指令能达到一个时钟周期就执行完毕,才会【CPI = 1】
- 指令之间【并行】执行!!尽量让多个指令近乎同时执行
具体后面会研究