码上爬第七题【协程+参数加密+响应解密+格式化检测】
前言:此题请求参数m和x需要逆向,请求时要带上时间戳ts,服务器返回给我们的数据是加密了的,我们需要解密,需要注意,此题含格式化检测和无限debugger。
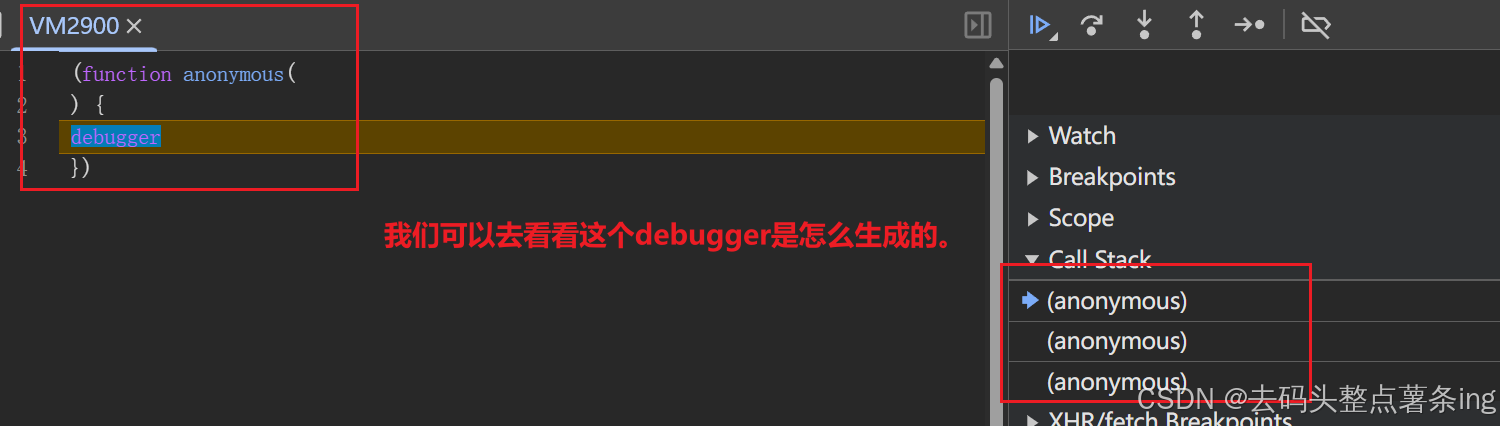
- 第一步:翻页抓包,你会发现虚拟机执行了一个匿名函数,里面是一个debugger,导致我们未能成功抓包,如图所示:

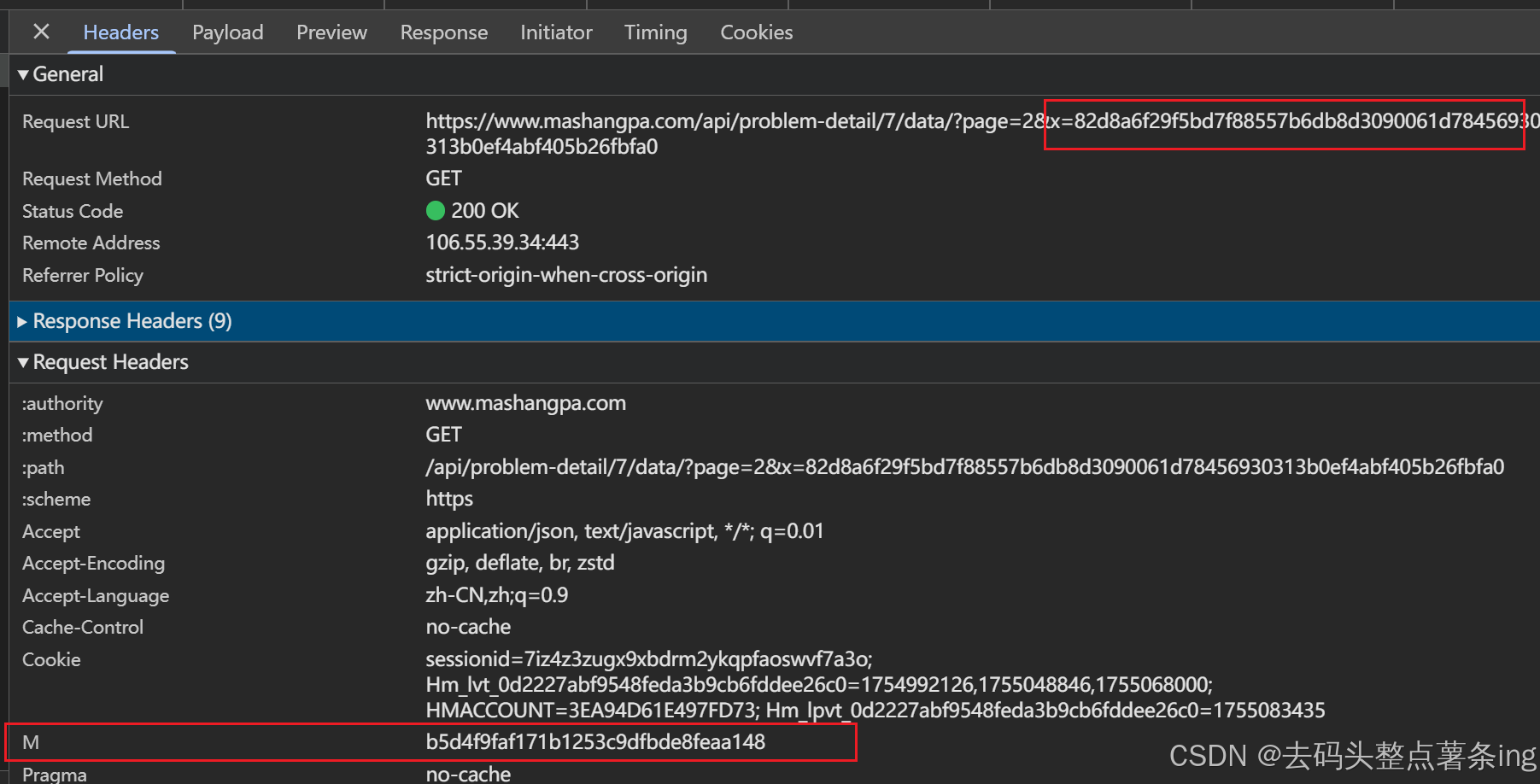
- 第二步:我们never parse here后翻页抓到数据包,观察到需要逆向m,x参数,还要解密响应密文,如图所示:

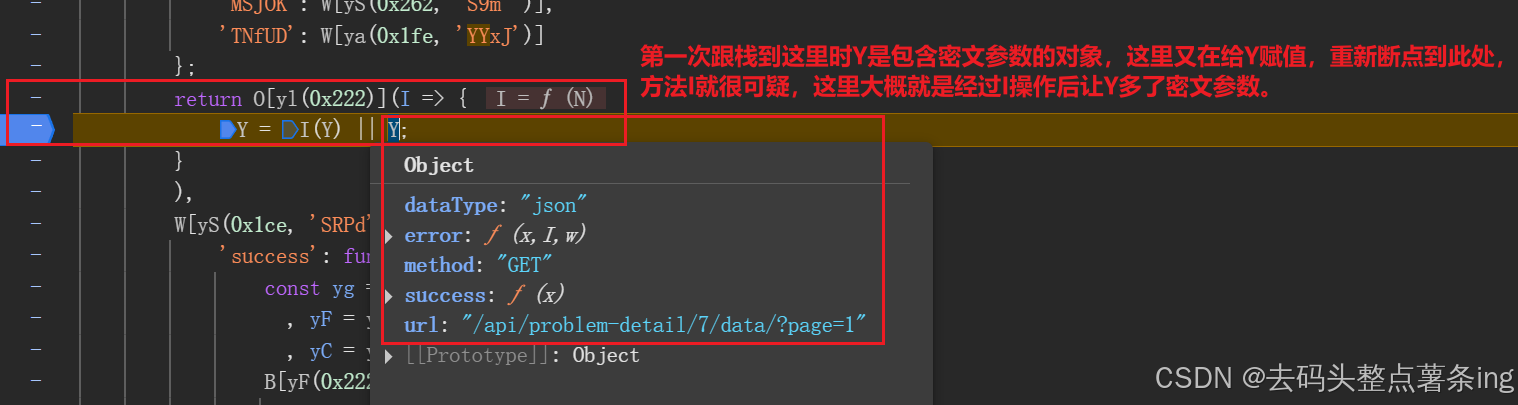
- 第三步:定位加密参数方法有很多,这里我选择直接跟栈,如图所示:
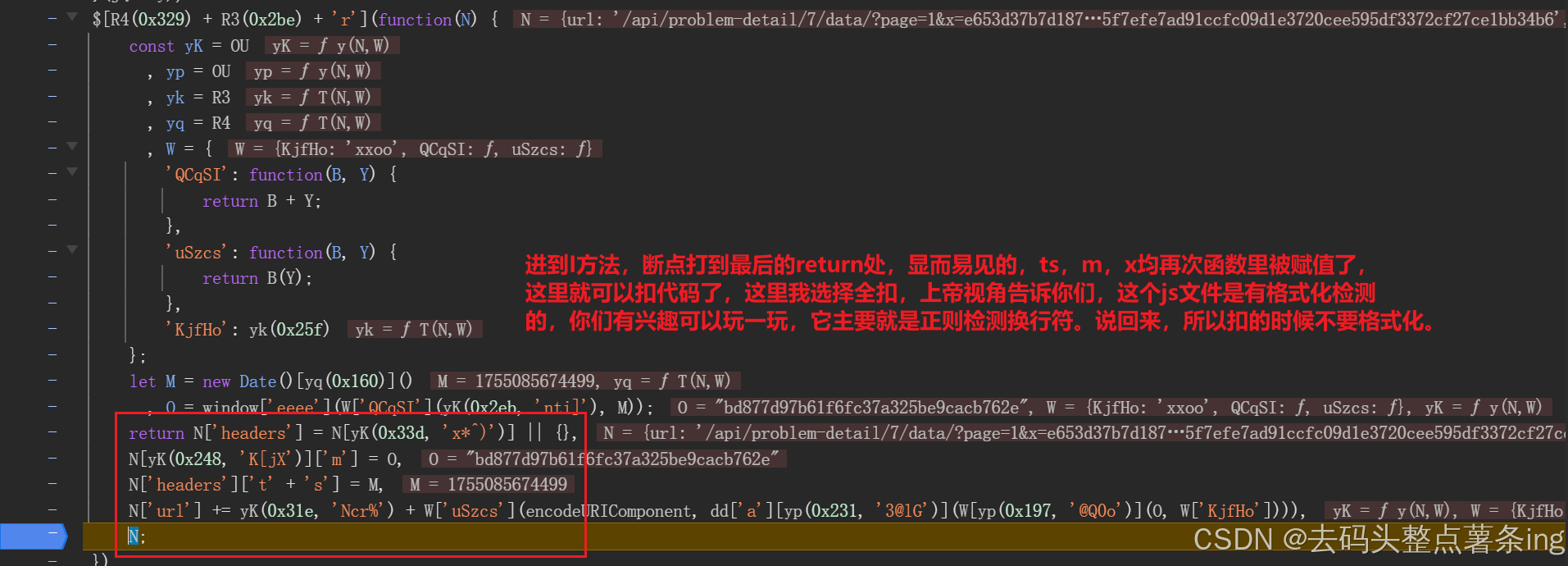
- 第四步:扣代码,如图所示:
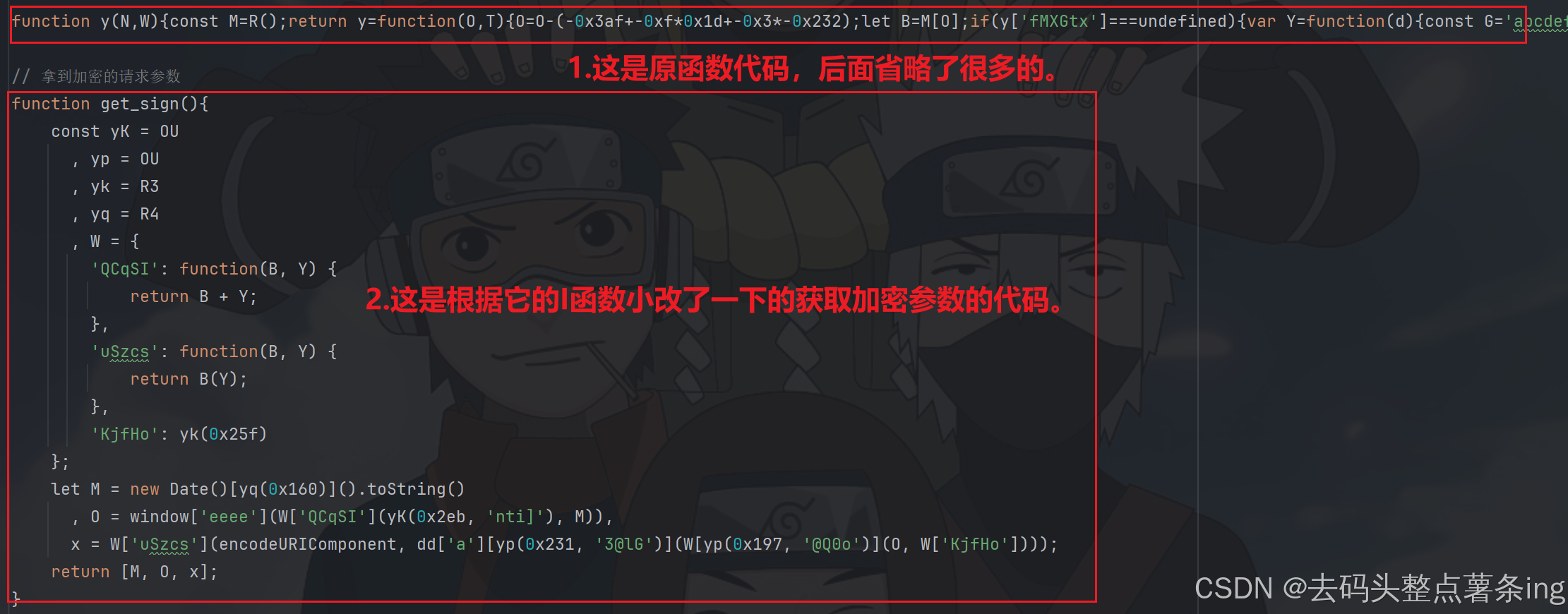
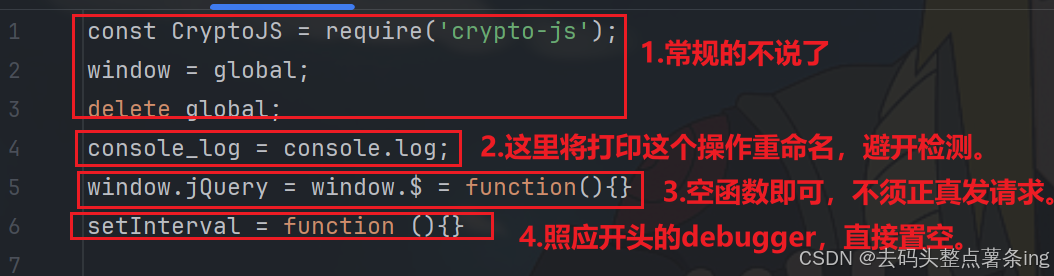
- 第五步:补环境,全扣代码难免会要补环境的,如图所示:
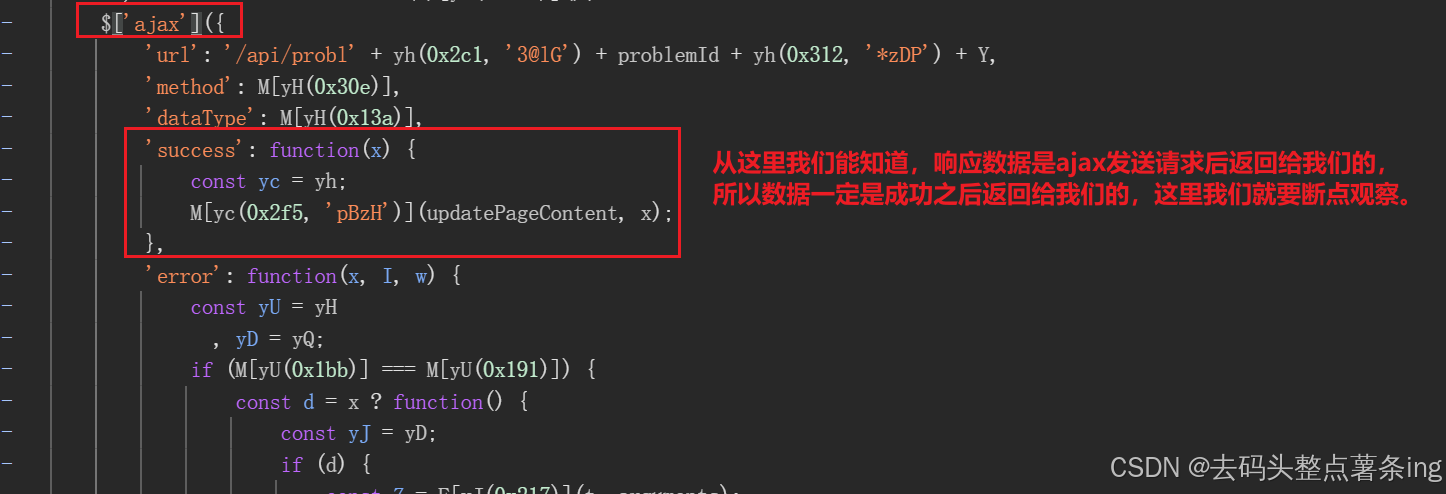
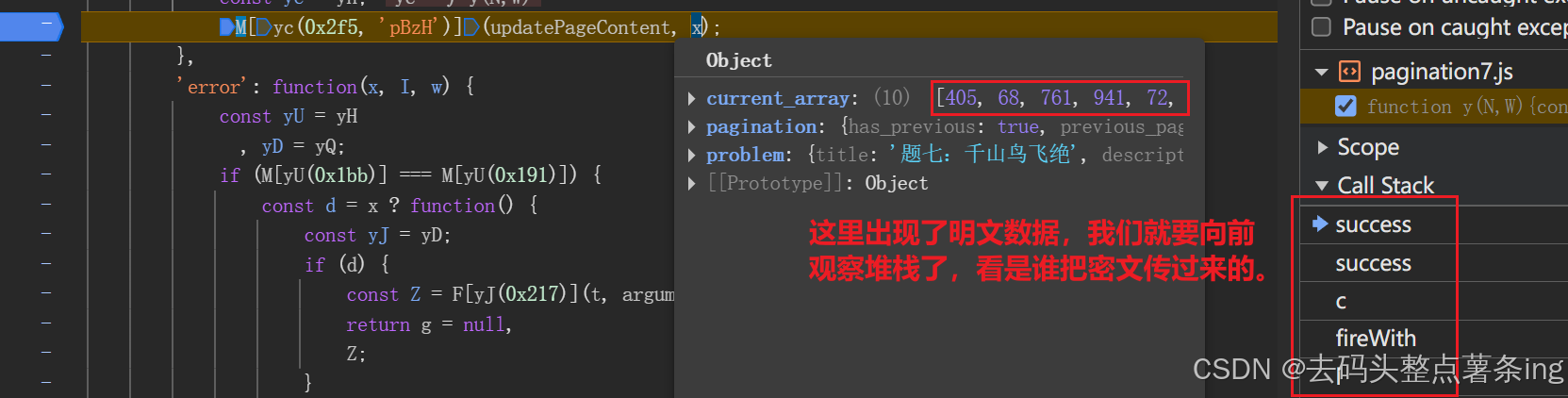
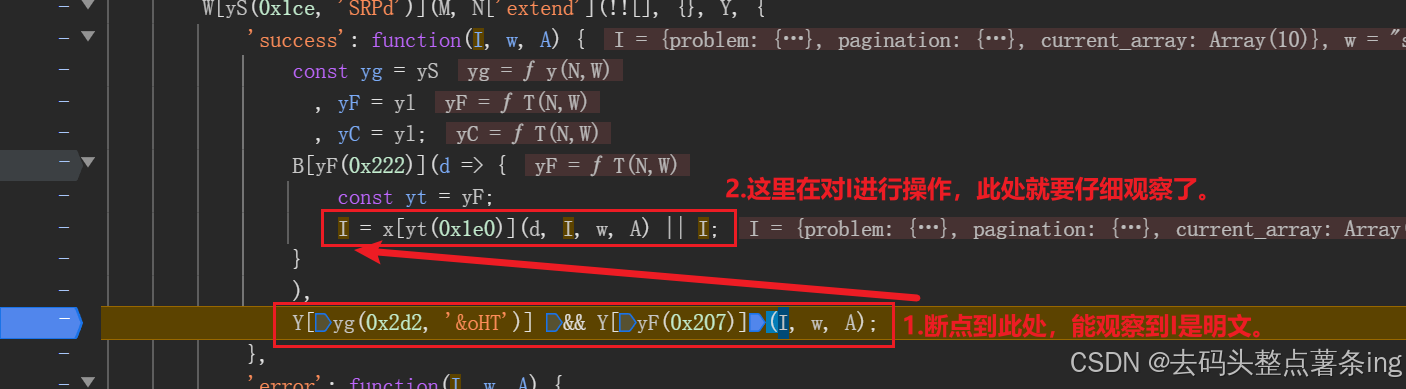
- 第六步:加密参数拿到后,还要去找解密代码在哪里,继续跟栈,如图所示:

- 第七步:开始写代码,如下:
js代码
const CryptoJS = require('crypto-js');
window = global;
delete global;
console_log = console.log;
window.jQuery = window.$ = function(){}
setInterval = function (){}// 这里未格式化的js代码就不展示了,实在太多……// 拿到加密的请求参数
function get_sign(){const yK = OU, yp = OU, yk = R3, yq = R4, W = {'QCqSI': function(B, Y) {return B + Y;},'uSzcs': function(B, Y) {return B(Y);},'KjfHo': yk(0x25f)};let M = new Date()[yq(0x160)]().toString(), O = window['eeee'](W['QCqSI'](yK(0x2eb, 'nti]'), M)),x = W['uSzcs'](encodeURIComponent, dd['a'][yp(0x231, '3@lG')](W[yp(0x197, '@Q0o')](O, W['KjfHo'])));return [M, O, x];
}
//console_log(get_sign())// 解密密文
function des_data(encrypt_data){return xxxxoooo(encrypt_data)
}py代码
import asyncio, aiohttp, execjs, jsonclass AsyncSpider(object):def __init__(self):self.url = 'https://www.mashangpa.com/api/problem-detail/7/data/'self.cookies = {'sessionid':'7iz4z3zugx9xbdrm2ykqpfaoswvf7a3o'}self.semaphore = asyncio.Semaphore(3)with open('7_1.js', 'r', encoding='utf-8') as f:self.js_code = execjs.compile(f.read())async def fetch_page(self, session, page):async with self.semaphore:sign = self.js_code.call('get_sign')params = {'page': page,'x': sign[2]}headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/138.0.0.0 Safari/537.36','m': sign[1],'ts': sign[0]}async with session.get(self.url, headers = headers, cookies = self.cookies, params = params, timeout = 10) as res:encrypt_data = await res.json()r = encrypt_data['r']data = json.loads(self.js_code.call('des_data', r))return data.get('current_array', [])async def parse_all_pages(self):total_sum = 0async with aiohttp.ClientSession() as session:tasks = [self.fetch_page(session, page) for page in range(1, 21)]results = await asyncio.gather(*tasks)for array in results:if array:total_sum += sum(array)print(total_sum)if __name__ == '__main__':spider = AsyncSpider()asyncio.run(spider.parse_all_pages())