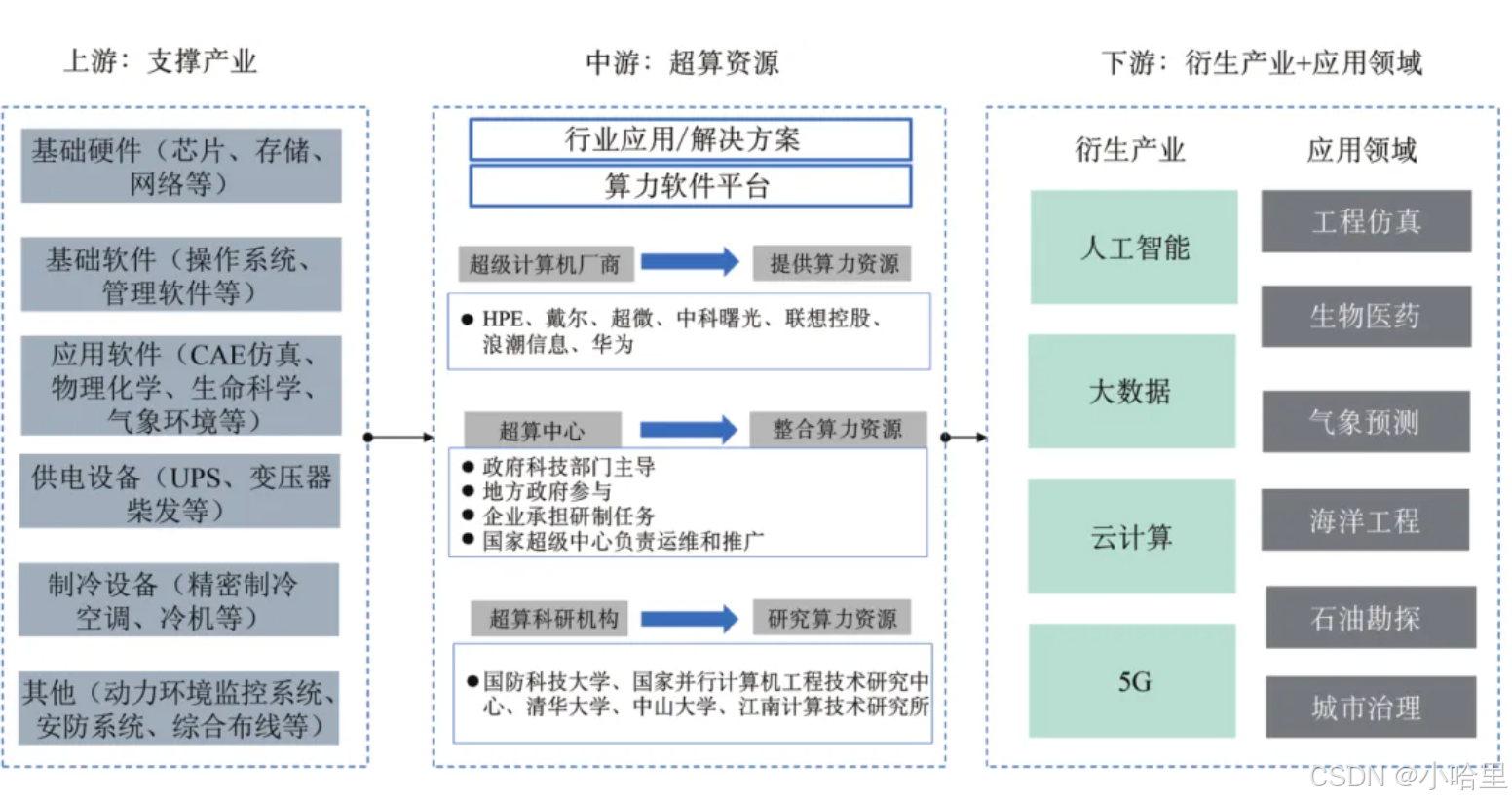
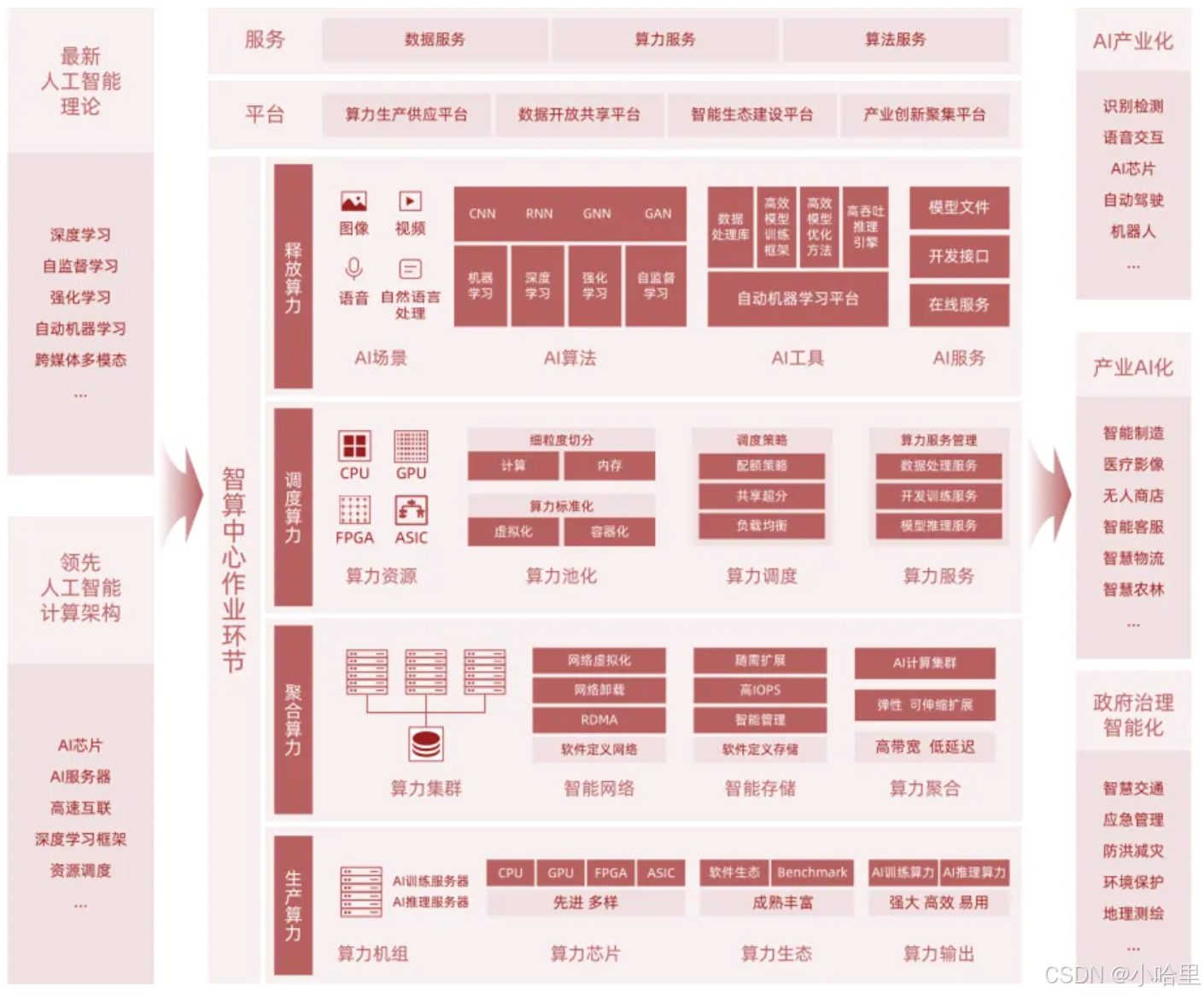
【超算】算力的精度,数据中心的划分标准与行业现状(国家超级计算机,企业万卡GPU集群)
【超算】算力的精度,数据中心的划分标准与行业现状(国家超级计算机,企业万卡GPU集群)
文章目录
- 1、算力的精度、CPU/GPU算力区别(FP64/FP16)
- 1.1 算力的单位、精度
- 1.2 CPU和GPU的算力区别
- 1.3 稀疏算力与稠密算力
- 2、国家超级计算机(FP64)
- 2.1 超算是什么?行业现状,技术细节
- 2.2 为什么超算用CPU & FP64?
- 2.3 超算 VS GPU集群
- 3、企业万卡GPU集群(FP16)
- 3.1 AI算力与传统算力的区别
- 3.2 数据中心的划分标准
- 3.3 万卡GPU集群搭建
这两天突然看到超算这个词,唤醒了遥远的回忆,感觉上次听到这个还是高中的时候。天河二号,神威太湖之光,这些当年都是新闻里的词汇。
时境过迁,看着手上的手机,从中学时期的iPhone5,换到了现在的13,到即将新出的17,这么多年过去,个人终端领域的算力都早已大不同前,当年每次的性能提高20%,现在早已不再关注。
在企业里,日常中也会接触到密集的大模型GPU算力,就很好奇,眼前这千卡,万卡的GPU集群,比起多年前的超算,究竟威力如何。
1、算力的精度、CPU/GPU算力区别(FP64/FP16)
1.1 算力的单位、精度
算力的单位
- 常用算力的衡量指标包括FLOPS(每秒浮点运算次数)、OPS (每秒运算次数)。
FLOPS (每秒浮点运算次数)特别适用于评估超级计算机、高性能计算服务器和GPU等设备的计算性能。 - AI 算力常见单位分为TOPS和TFLOPS。
推理算力,即通常用设备处理实时任务的能力,通常以TOPS(每秒万亿次操作)为单位来衡量。
训练算力,即设备的学习能力和数据处理能力,常用TFLOPS(每秒万亿次浮点操作)来衡量。
ai算力芯片知识
GPU服务器计算精度是什么?
不同精度的使用场景
- FP32:1符号位 + 8指数位 + 23尾数位(IEEE 754标准)
- FP16:1符号位 + 5指数位 + 10尾数位
- BF16:1符号位 + 8指数位 + 7尾数位(与FP32指数对齐)
- FP8标准:NVIDIA Hopper支持的新格式(E5M2/E4M3)
- 大模型时代:BF16已成为训练事实标准,而INT4/FP8正在重塑推理市场格局。
| 精度类型 | 优点 | 缺点 | 典型应用场景 |
|---|---|---|---|
| FP64 | 超高精度(15-17位有效数字) | 计算速度慢,显存占用高 | 气候模拟、量子化学、航天轨道计算 |
| FP32 | 通用性强,硬件广泛支持 | 速度/精度折中 | 传统HPC、3D游戏渲染、CAD设计 |
| FP16 | 速度快,显存节省50% | 需处理数值稳定性(梯度消失) | DL训练(混合精度)、实时渲染 |
| INT8 | 极致推理速度,功耗极低 | 需量化校准,精度损失明显 | 手机AI芯片、边缘设备、自动驾驶感知 |
| BF16 | 保留指数范围,训练稳定性好 | 尾数精度仅7位 | 大语言模型训练(GPT/LLaMA系列) |
1.2 CPU和GPU的算力区别
CPU和GPU的算力区别
- 单核CPU的FP64性能是GPU单核心的37倍(0.052 vs 0.0014),但GPU靠「人海战术」(数万核心并行)实现总算力反超。
- GPU的24 TFLOPS需完美并行化才能发挥,实际科学计算中利用率常低于50%
| 维度 | GPU | CPU |
|---|---|---|
| 设计目标 | 高吞吐、大规模并行(SIMD) | 低延迟、复杂逻辑控制(分支预测、乱序执行) |
| 核心架构 | 数千个轻量级核心(如NVIDIA H100: 16,896 CUDA核心) | 少数高性能核心(如AMD EPYC: 96核) |
| 内存系统 | 高带宽显存(HBM3: 4.8TB/s) | 低延迟缓存(DDR5 + 多级缓存) |
| 算力类型 | 稠密算力王者(FP16/FP32矩阵乘法) | 稀疏算力优势(条件判断、不规则数据访问) |
CPU和GPU的算力区别-例子
| 硬件 | FP64算力(TFLOPS) | 核心数 | 每核心FP64性能 | 功耗 |
|---|---|---|---|---|
| AMD EPYC 9654 (96核) | ~5 TFLOPS | 96 | 0.052 TFLOPS/核 | 360W |
| NVIDIA H200 | ~24 TFLOPS | 16,896 CUDA核心 | 0.0014 TFLOPS/核 | 700W |
1.3 稀疏算力与稠密算力
稀疏算力与稠密算力
- 稠密算力:GPU占绝对优势(高并行 + 高带宽显存)。
如ResNet-50训练(GPU比CPU快100倍)。 - 稀疏算力:CPU更高效(依赖缓存和分支预测,避免无效计算)。
如推荐系统的Embedding查找(CPU延迟更低)
| 算力类型 | 数据特征 | 典型应用场景 | 硬件优化方向 |
|---|---|---|---|
| 稠密算力(Sparse Compute) | 数据连续、规整(如全连接矩阵) | 图像处理、AI训练(矩阵乘法) | GPU Tensor Core(并行计算优化) |
| 稀疏算力(Dense Compute) | 数据稀疏(多数元素为0) | 推荐系统、自然语言处理(NLP) | CPU缓存优化、专用稀疏加速单元 |
稀疏算力与稠密算力-例子
| 任务类型 | GPU算力 | CPU算力 | GPU vs. CPU优势倍数 |
|---|---|---|---|
| 稠密FP16(AI训练) | 1,979 TFLOPS | ~0.5 TFLOPS | 3,958x |
| 稠密FP64(科学计算) | 24 TFLOPS | 5 TFLOPS | 4.8x |
| 稀疏计算(推荐系统) | 效率低(显存带宽浪费) | 效率高(缓存命中优化) | CPU胜出 |
2、国家超级计算机(FP64)
2.1 超算是什么?行业现状,技术细节
超算科普 算力的历史
行业现状 1, 2,3
定义,超级计算机(Supercomputer)
- 是指性能远超通用计算机的高性能计算系统,通常用于解决复杂科学计算、工程模拟和大规模数据处理等问题。
- 其计算能力以FLOPS(每秒浮点运算次数)衡量,现代顶级超算的算力可达每秒百亿亿次(EFLOPS)级别。
- 2023年全球超算市场规模约150亿USD,预计2027年达300亿(CAGR 15%)
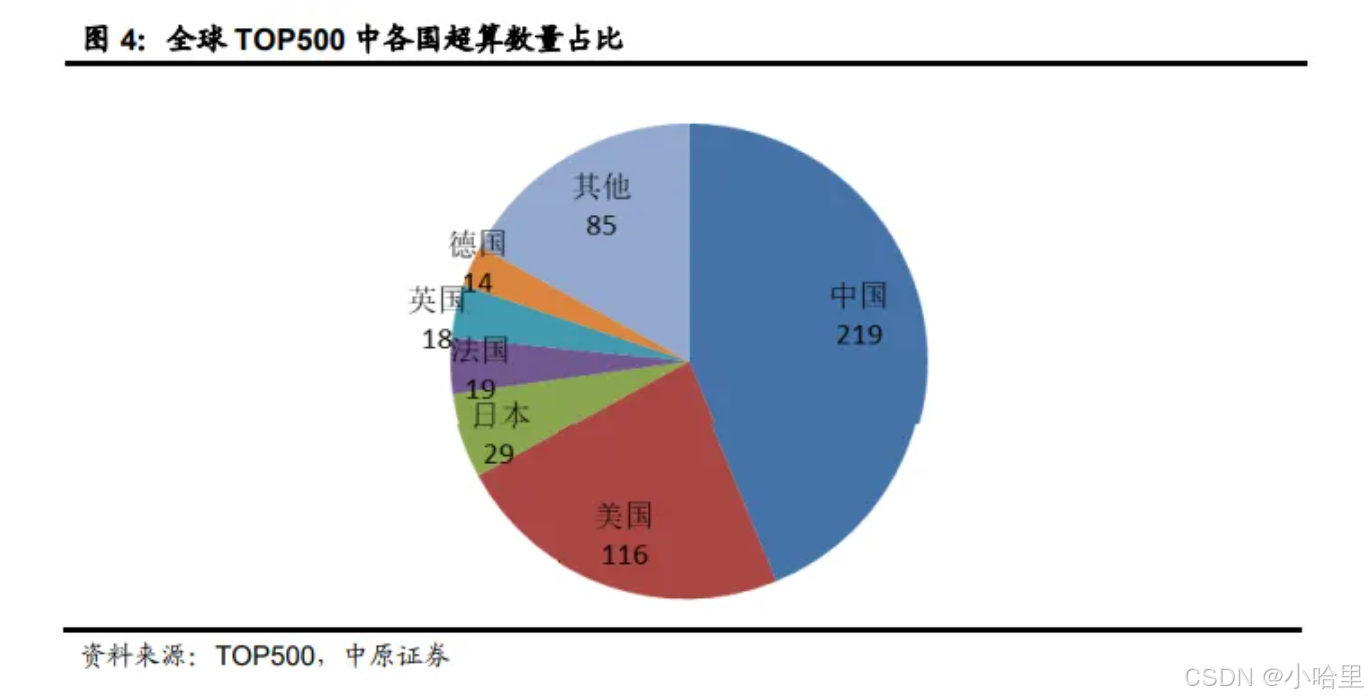
行业案例
- 全球超级计算机500强(TOP500) 排行榜
每半年发布一次,榜单由国际组织“TOP500”编制,旨在对全球已安装的超级计算机进行排名。目前,日本超级计算机“富岳”位列榜首,中国有186台上榜,数量位居第一。
1, 2, 3 - El Capitan:以 1.742 exaFLOPS 的峰值算力位居第一。
该超算位于美国加州劳伦斯利弗莫尔国家实验室,基于 AMD 第四代 EPYC 处理器(24 核,1.8GHz)和 AMD Instinct MI300A 加速器,拥有 11,039,616 个计算核心,运行于 HPE Cray EX255a 架构下,并使用 HPE Slingshot 网路互连技术,能效达到 58.9Gigaflop / 瓦。 - Frontier:以 1.353 EFlop/s 的 HPL 性能排名第二。
该超算位于美国田纳西州的橡树岭国家实验室,由美国能源部运营。其采用了 HPE Cray EX235a 架构,配备 2GHz AMD EPYC 64C CPU 和 AMD Instinct 250X GPU,共有 8699904 个 CPU 和 GPU 核心,并借助于 HPE Slingshot 11 网络进行数据传输。 - 根据第 65 届超级计算机 TOP500 榜单(2025 年 6 月 10 日榜单),中国超算由于不再参与 HPL 基准测试的数据更新,没有进入前十。
其中,神威太湖之光排名跌至第 21 名,天河 2A 则跌至了第 31 名。
神威·太湖之光超级计算机最高排名是世界第一,它在2016年6月和2017年6月两次登上全球超级计算机TOP500榜单的首位。
技术细节
- 超级计算机的技术实现涉及硬件架构、并行计算框架、编程模型和优化技术等多个层面。
- 1、硬件架构
(1)异构计算节点:
-CPU:多路多核(如AMD EPYC 96核/Intel Xeon 56核),负责逻辑控制。
-加速器:GPU(NVIDIA H100)、FPGA或专用芯片(如TPU),负责密集计算。
-互联网络:InfiniBand(200Gbps以上)或定制互联(如Cray的Slingshot)。
(2)存储分层:
-L1 Cache(每核心独占) → L2/L3 Cache(共享)→ HBM(High Bandwidth Memory,如H100的3TB/s)→ 节点本地NVMe → 全局并行文件系统(如Lustre) - 2、并行计算框架
(1)MPI(消息传递接口):跨节点通信,实现任务级并行
(2)OpenMP(共享内存并行)
(3)CUDA/HIP(GPU加速) - 3、典型软件栈(编程模型和优化技术)
(1)数学库:BLAS/LAPACK:基础线性代数运算(如Intel MKL);FFTW:快速傅里叶变换;cuDNN/cuBLAS:GPU加速库;
(2)性能分析工具:Gprof:函数级耗时分析;Nsight/NVProf:GPU内核性能剖析;TAU:跨平台性能监控;
应用层│├─MPI+OpenMP+CUDA(并行模型)│├─PETSc/Trilinos(数学框架)│├─HDF5/NetCDF(数据IO)│└─Slurm/LSF(资源调度)
代码示例:
// (C+MPI)
#include <mpi.h>
int main(int argc, char** argv) {MPI_Init(&argc, &argv);int rank, size;MPI_Comm_rank(MPI_COMM_WORLD, &rank); // 获取当前进程IDMPI_Comm_size(MPI_COMM_WORLD, &size); // 获取总进程数double data = rank * 1.0;double sum;MPI_Allreduce(&data, &sum, 1, MPI_DOUBLE, MPI_SUM, MPI_COMM_WORLD); // 全局求和if (rank == 0) printf("Global sum: %f\n", sum);MPI_Finalize();return 0;
}// (C+OpenMP)
#pragma omp parallel for reduction(+:sum)
for (int i = 0; i < N; i++) {sum += compute_heavy_task(i); // 自动线程分配
}// 使用MPI派生数据类型减少通信次数
MPI_Datatype subarray;
int sizes[2] = {N, N}, subsizes[2] = {M, M}, starts[2] = {0, 0};
MPI_Type_create_subarray(2, sizes, subsizes, starts, MPI_ORDER_C, MPI_FLOAT, &subarray);
MPI_Type_commit(&subarray);// (矩阵乘法,CUDA)
__global__ void matmul_kernel(float *A, float *B, float *C, int N) {int i = blockIdx.x * blockDim.x + threadIdx.x;int j = blockIdx.y * blockDim.y + threadIdx.y;if (i < N && j < N) {float sum = 0;for (int k = 0; k < N; k++) sum += A[i*N+k] * B[k*N+j];C[i*N+j] = sum;}
}
// 调用:dim3 blocks(32,32); dim3 threads(16,16); matmul_kernel<<<blocks,threads>>>(A,B,C,N);// Slurm作业提交示例
#!/bin/bash
#SBATCH --nodes=4 # 4个节点
#SBATCH --ntasks-per-node=8 # 每节点8进程
#SBATCH --gres=gpu:4 # 每节点4块GPU
mpirun -np 32 ./parallel_app
2.2 为什么超算用CPU & FP64?
为什么科学计算FP64仍以CPU为主?
- 内存访问模式:
CPU的大缓存+低延迟内存(DDR5)更适合科学计算的不规则内存访问(如稀疏矩阵)。
GPU的HBM显存带宽高但延迟高,适合规整的并行计算(如矩阵乘法)。 - 编程模型:
传统科学代码(Fortran/MPI)针对CPU优化,移植到GPU需重写为CUDA/OpenACC。 - 精度稳定性:
CPU的FP64计算单元更成熟,避免累积误差(如航天器轨道计算)。 - FP64算力峰值:
GPU(如H200)确实高于单颗CPU,但 实际科学计算中,CPU的架构优势(低延迟、易编程)更关键
不要只看峰值算力,实际科学计算中「有效算力」取决于内存、编程、算法协同
何时用GPU跑FP64?
| 场景 | 推荐方案 | 案例 |
|---|---|---|
| 高并行FP64(如CFD) | GPU加速(CUDA Fortran) | NVIDIA的Simulia Abaqus |
| 强依赖分支判断 | CPU集群(MPI) | 核爆模拟(如美国LANL实验室) |
| 混合精度AI+科学计算 | CPU+GPU异构 | Frontier超算的癌症研究 |
UTSC-MPI
2.3 超算 VS GPU集群
超算 VS GPU集群
- 超算在FP64领域绝对领先,GPU集群无法替代
- 企业GPU集群在AI算力上碾压传统超算
| 对比项 | 国家超算(如Frontier) | 企业H200集群(10,000张) |
|---|---|---|
| FP64算力 | 1.2 ExaFLOPS(1,200 PetaFLOPS) | 240 PetaFLOPS(单卡24 TFLOPS×10k) |
| 能效比 | 较低(功耗≈20MW) | 较高(H200能效优化) |
| 优势场景 | 核模拟、流体力学 | 无直接竞争力(FP64非设计重点) |
| FP16算力 | 200 PetaFLOPS(转换效率低) | 19,790 PetaFLOPS(单卡1,979 TFLOPS×10k) |
| 显存带宽 | 一般(依赖CPU内存) | 48 PB/s(单卡4.8 TB/s×10k) |
| 优势场景 | 小规模AI辅助研究 | 大模型训练、实时推理 |
3、企业万卡GPU集群(FP16)
3.1 AI算力与传统算力的区别
AI算力与传统算力的区别
- 本质区别:AI算力是“速度优先,容忍误差”,FP64算力是 “精度优先,严控误差”。
- 硬件分工:GPU的Tensor Core为AI而生,CPU/传统超算的FP64单元为科学护航。
- 协作未来:AI与科学计算的边界逐渐模糊,但FP64在关键领域仍不可替代。
| 维度/指标 | AI算力 | FP64算力 |
|---|---|---|
| 编程模型 | PyTorch/TensorFlow(自动微分/梯度下降) | MPI/OpenMP(手动并行化) |
| 计算模式 | 数据并行(分批次处理) | 任务并行(分布式协同计算) |
| 库支持 | cuDNN、TensorRT | BLAS、LAPACK、FFTW |
| 峰值算力 | 单卡可达数千TFLOPS | 单卡通常<100 TFLOPS |
| 能效比 | 极高(TOPS/Watt) | 较低(高功耗换精确性) |
| 延迟敏感度 | 批处理优先(高吞吐) | 强依赖低延迟(紧耦合计算) |
| 核心单元 | Tensor Core/矩阵加速器(专为矩阵乘法优化) | 通用浮点单元(支持复杂数学函数) |
| 内存带宽 | 极高(HBM3达4.8TB/s,满足数据吞吐) | 中等(依赖CPU内存带宽,通常<1TB/s) |
| 芯片面积 | 大量晶体管用于并行低精度计算 | 晶体管优先保障高精度运算稳定性 |
| 精度等级 | 低精度(16位浮点/8位整数) | 高精度(64位浮点) |
| 典型场景 | 深度学习训练/推理 (容忍数值误差) | 科学计算(气候模拟、核物理,需绝对精确) |
| 数据范围 | 牺牲动态范围,专注模式识别 | 保留极大/极小数值,避免累积误差 |
3.2 数据中心的划分标准
传统数据中心大小
通常根据标准机架数量、设计最大用电负荷等指标进行划分,以下是常见的划分标准:
-
按标准机架数量划分:
我国新制定的《电子信息机房设计规范》GB 50174-2008,将电子信息机房定义为A、B、C三类
超大型数据中心,通常面积大于2000m2,服务器机柜数量大于1000个;
大型数据中心,通常介于800~2000m2,服务器机柜数量200~1000个;
中型数据中心,面积为200~800m2,机柜数量为50~200个;
小型数据中心,面积为30~200m2,机柜数量为10~50个; -
按设计最大用电负荷划分:
超大型数据中心:设计最大用电负荷 P≥40MVA。
大型数据中心:设计最大用电负荷满足 40>P≥10MVA。
中型数据中心:设计最大用电负荷满足 10>P≥5MVA。
小型数据中心:设计最大用电负荷 P<5MVA。
GPU集群常见规模划分
- NVIDIA DGX 集群标准
NVIDIA 作为 GPU 领域龙头,其 DGX 系列集群(如 DGX A100、DGX H100)的规模划分具有行业参考性:
小型集群:1-8 台 DGX 服务器(每台 8 张 GPU,即 8-64 张 GPU);
中型集群:8-32 台 DGX 服务器(64-256 张 GPU);
大型集群:32 台以上 DGX 服务器(≥256 张 GPU),可扩展至数千台形成 “AI 超级计算机”(如 NVIDIA 的 Selene 超级计算机,含 4480 张 A100 GPU)。 - 国内 “智算中心” 分级
中国信通院《新型数据中心发展白皮书》中,对 “智能计算中心”(以 GPU 集群为核心)的规模划分参考:
中小型智算中心:总算力≤100 PFLOPS(AI 算力);
大型智算中心:总算力 100-1000 PFLOPS;
超大型智算中心:总算力≥1000 PFLOPS。
3.3 万卡GPU集群搭建
2024年图
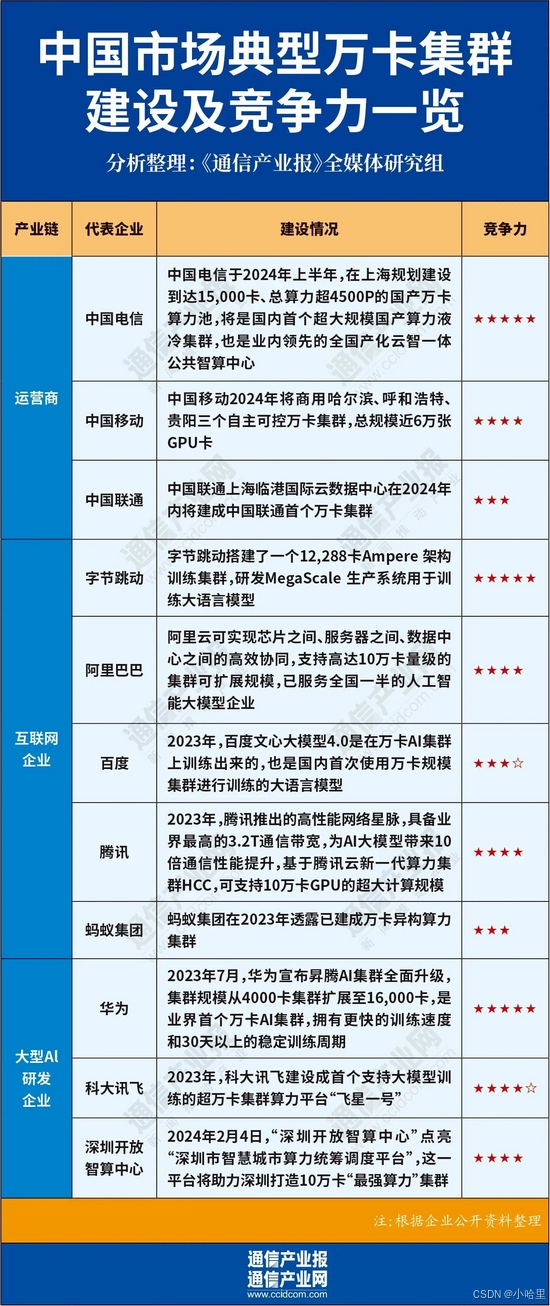
硬件选型
-
服务器与拓扑:
标准机架式服务器(10000/8卡每台 ~= 1024台服务器)
内存(每GPU配1:4显存比例配置,如A100 80GB配320GB内存)
CPU(每GPU配1-2个CPU核,AMD EPYC或Intel Xeon) -
计算GPU选择:
显存带宽(如H100的3TB/s)、互联技术(NVLink/NVSwitch)、单卡算力(FP32/TFLOPS)
计算优化:混合精度训练(FP16/BF16)+ Tensor Core利用 -
网络架构:
InfiniBand:使用NVIDIA Quantum-2 InfiniBand(400Gbps)或更高,支持RDMA
NVLink/NVSwitch:节点内GPU通过NVLink全互联(如DGX A100的NVSwitch),节点间通过InfiniBand
通信优化:NCCL调优:设置NCCL_ALGO=Tree、NCCL_PROTO=LL。GPUDirect RDMA避免CPU拷贝。 -
存储系统:
高性能并行存储:Lustre、GPFS或CephFS,带宽需≥100GB/s。全闪存阵列(如NVMe SSD),元数据服务器独立部署。
数据流水线:预处理与训练分离,避免IO瓶颈。
软件栈部署
-
集群管理
调度系统:Slurm、Kubernetes(KubeFlow)+ NVIDIA GPU Operator。
容器化:使用NGC(NVIDIA GPU Cloud)镜像或自定义Docker,集成CUDA/cuDNN。 -
分布式训练框架
PyTorch:torch.distributed+ NCCL后端,支持FSDP(全共享数据并行)。
TensorFlow:MultiWorkerMirroredStrategy。
定制方案:Megatron-LM(3D并行)、DeepSpeed(ZeRO-3优化) -
监控与运维
硬件监控:Prometheus + Grafana,跟踪GPU温度、功耗、利用率。
日志系统:ELK Stack(Elasticsearch, Logstash, Kibana)。
故障自愈:自动化脚本检测GPU故障并隔离节点。
估算
- 自建大约估计
核心硬件,H100单个2.5~4w,加服务器网络存储等(约 40 亿US)
电力与散热,电力与液冷(年运营 1.7 亿US)
配套基础设施,场地与人员(约 5.5 亿US)
10 年总:约 77 亿US - 租赁 1
H200租赁约2~5 US per hour,2*7*8*24*30=80640~400000/month/单台8卡
万卡约1024台服务器,1个小目标每month
部分参考资料
- 行业统计 , 字节万卡-论文 , DS-万卡, 移动-万卡
- 万卡集群搭建 , 万卡集群搭建-网络 , 万卡集群运维, h200
更多有趣的探索:
- 万卡集群的日常运营运维
1、需实时监控数万节点的算力负载与网络拥塞,通过智能调度算法避免单点故障扩散,同时最大化集群利用率。
2、长期运维的关键在于预判性损耗管理,通过硬件健康度建模提前替换老化部件,将非计划停机率压降至 1% 以下。 - AI基础设施与传统基础设施的区别,硬件上的全链路
1、AI Infra 处于垂直整合的关键节点,必须针对特定硬件进行模型的定制化设计与深度优化。
2、强化学习的融入,绝非仅停留在算法层面的调整,而是对硬件选型、系统架构乃至模型设计产生全链路影响。
3、能最充分发挥计算效能的方法,才是长远竞争中的胜出者;延续并极致利用摩尔定律,是 Infra 领域的终极命题。