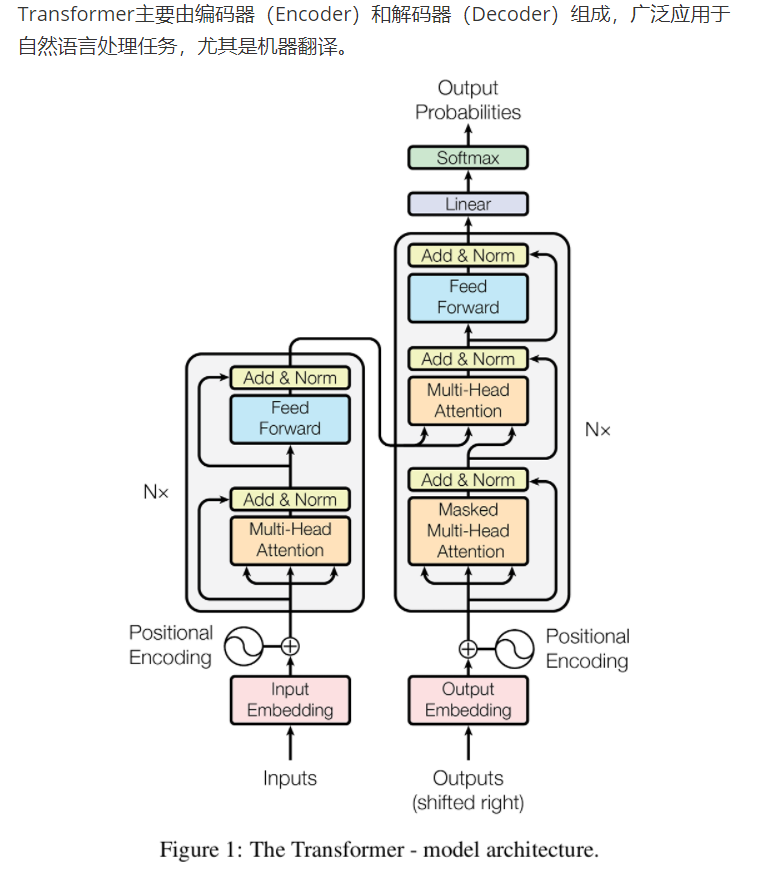
Transformer开端
- 相比于LSTM于GRU的记忆功能Transformer的记忆更为深刻
- 因为LSTM与GRU极易发生梯度爆炸:具体推导可看这篇文章
- LSTM从入门到精通(形象的图解,详细的代码和注释,完美的数学推导过程)_lstm模型-CSDN博客
- 关于反向传播中梯度爆炸/消失推导非常的完美
- Transformer的关键在于引进了自注意力机制(多头注意力机制)
一.自注意力机制
自注意力机制关键在于对上下文的理解
1.1专业术语
自注意力机制通过引入查询向量(Query)、键向量(Key)、值向量(Value)概念来实现序列中各元素之间的信息交互和依赖建模。
-
Q:Query
表示当前查询者的位置,用来发出问题:“我想知道对我来说谁重要”。
-
K:Key
表示被查询者的身份,是所有位置给出的“介绍信”或“标签”,告诉别人自己是个啥玩意。
-
V:Value
表示被查询者实际信息,也就是一旦你决定“关注我了”,我就把这份
解释较为复杂不太推荐,总的来说就是把词向量通过线性变换为三个不同的向量,即下图所示
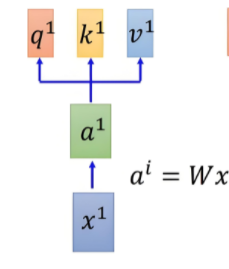
1.2注意力得分
参考余铉相似度而来,即向量和向量之间的相似度
余铉相似度公式: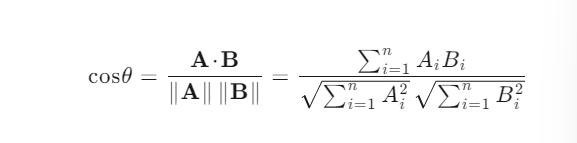
注意力得分矩阵:点积计算相似度
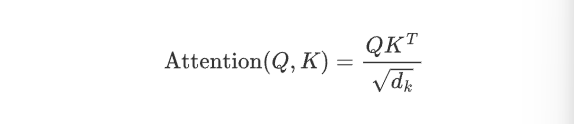
分母用来避免数值过大
1.3归一化(对矩阵进行softmax操作)
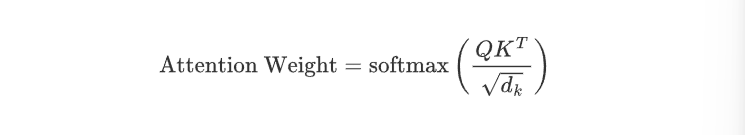
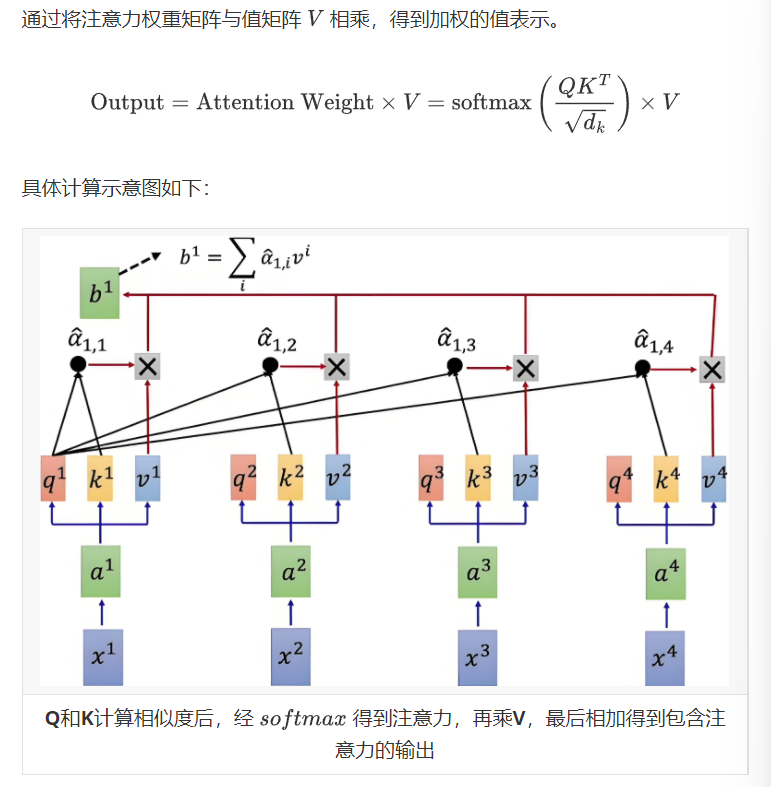
1.4加权求和【关键】
1.5多头注意力机制【重要】
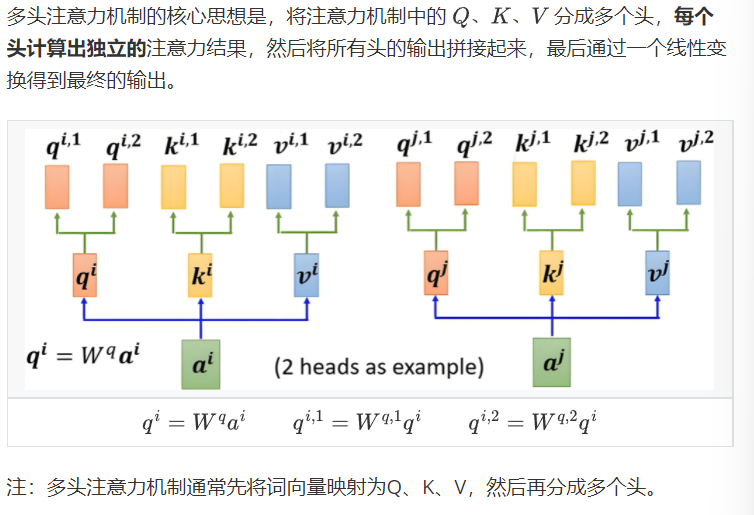
- 与CNN中的分组卷积类似
- 与上述单头注意力相似稍微多一点的就是剪切与拼接
1.6位置编码
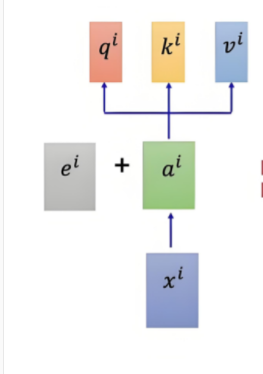
ei 即位置编码类似独热编码
二.transformer结构