01数据结构-Kruskal算法
01数据结构-Kruskal算法
- 1.最小生成树
- 1.1生成树的定义
- 1.2生成树的属性
- 1.3最小生成树
- 2.克鲁斯卡尔(Kruskal)算法
- 3.Kruskal算法代码实现
1.最小生成树
1.1生成树的定义
在含有n个顶点的连通图中选择n-1条边,构成一颗极小的连通子图,并使该连通子图中n-1条边上的权值之和达到最小,则称其为连通网的最小生成树
一个连通网的生成树是一个极小的连通子图,它包含图中全部的n个顶点,但只有构成一棵树的n-1条边
连通图和它对应的生成树,可以用于解决实际生活中的问题:假设A,B,C和D4座城市,为了方便生产生活,要为这4座城市建立通信,对于4个城市来讲,本着节约经费的原则,只需要建立3个通信路线即可,如图1右边。在具体选择哪一种方式的时候,需要综合考虑城市之间间隔的距离,建设通信线路的难度等各种因素,将这些因素综合起来用一个数值表示,当作这条路的权值。
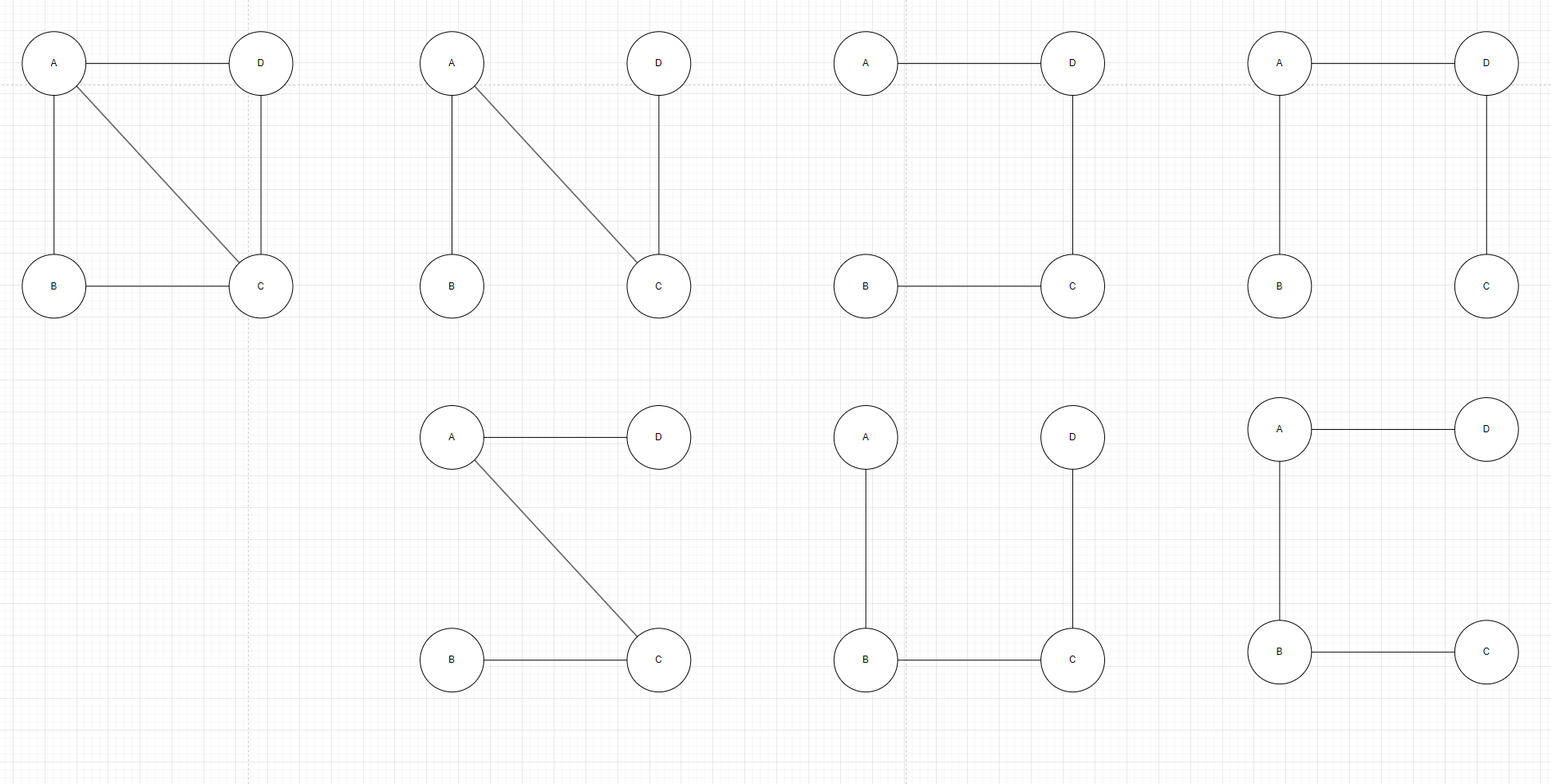
图1
1.2生成树的属性
- 一个连通图可以有多个生成树
- 一个连通图的所有生成树都包含相同的顶点个数和边数
- 生成树中不存在环
- 生成树是一棵树(Tree),即不存在环路(无闭合路径),并且所有顶点通过边相互连通。
- 移除生成树中的任意一边都会导致图的不连通,生成树的边最少的特性
- 在生成树中添加一条边会构成环,对于包含n个顶点的连通图,生成树包含n个顶点和n-1条边
- 对于包含n个顶点的无向图最多包含nn-2棵生成树
1.3最小生成树
所谓一个带权图的最小生成树,就是原图中的边的权值最小的生成树,最小是指边的权值之和小于或者等于其他生成树的边的权值之和。
最小生成树的算法思想是从顶点集或边集的角度进行贪婪化。
2.克鲁斯卡尔(Kruskal)算法
克鲁斯卡尔算法(Kruskal)是⼀种使⽤贪婪⽅法的最⼩⽣成树算法。该算法初始将图视为森林,图中的每⼀个顶点视为⼀棵单独的树。⼀棵树只与它的邻接顶点中权值最⼩且不违反最⼩⽣成树属性(不构成环)的树之间建⽴连边。
如图2,是一个带权图,我们要找到最小生成树,一共7个顶点我们需要从这么多边中选出7-1=6条边来构成我们的生成树,我们采用贪心的思想,只要是权值小的边我们统统加入生成树,但是需要有一个约束,因为生成树中不能有环,所以我们的约束条件是每加一个权值小的边,就去看是否与之前已经加上的边构成了一个环,如果没有我们就加入这条边。
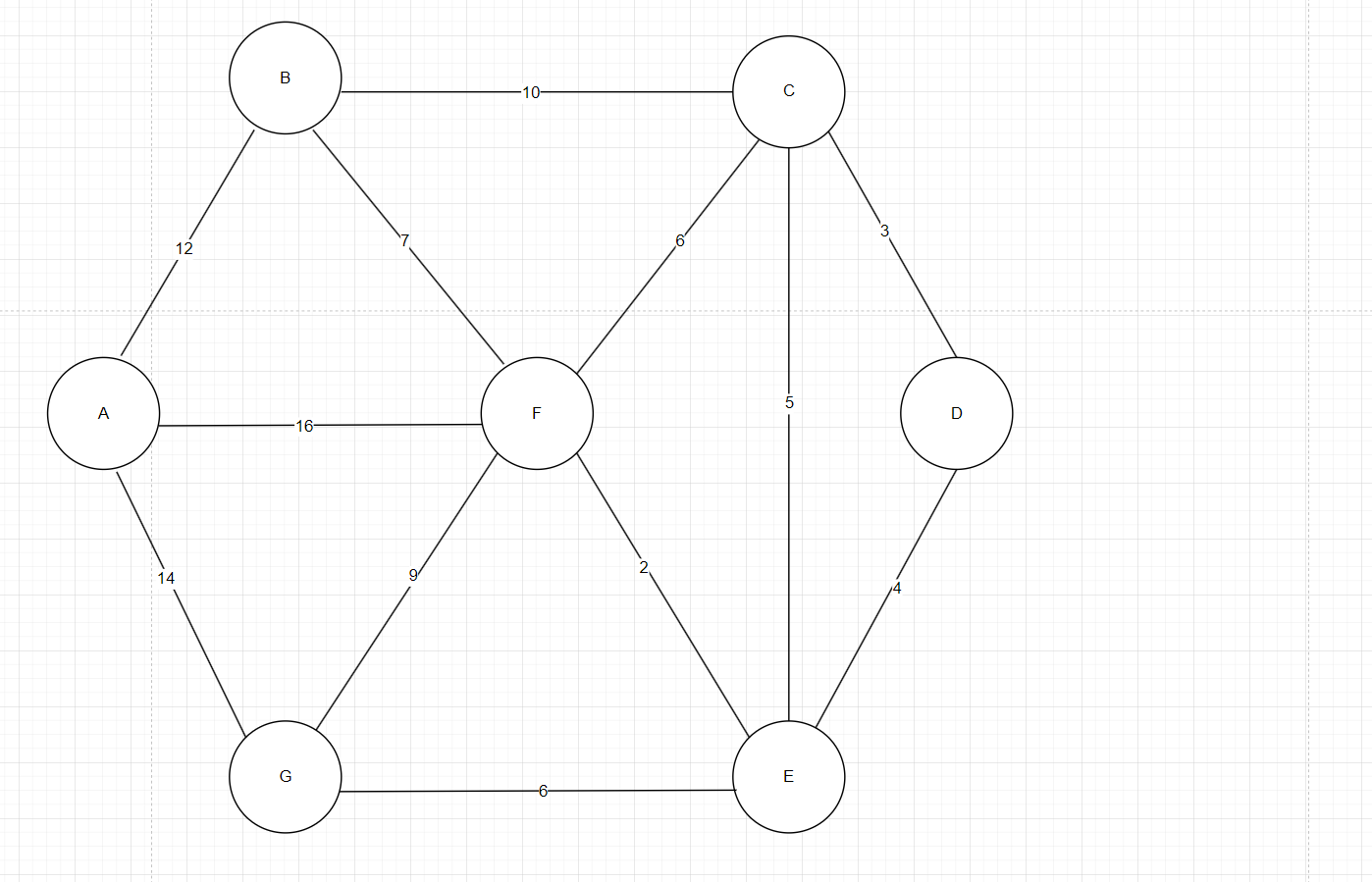
图2
如图3我们采用贪心,在所有边中找到权值最小的边是2,这条边连接的是F和E,由于是第一条边所以直接连,这样F和E就连通了,我们认为F和E在同一个集合中,再找权值最小的边是3,这条边连接的是C和D,和之前的FE集合不在一起,所以可以直接连接,这样C和D就连通了,我们认为CD在同一集合中,再找权值最小的边是4,这条边连接的是D和E,在连接这条边之前,CD集合和FE集合各是独立的,所以连接了这条边后没问题,连接这条边把FE集合和CD集合融在同一集合中,再找权值最小的边是5,这条边连接的是C和E,在连接这条边之前,CD集合和FE集合已经是在同一集合中了,即C和E肯定有间接连接的,所以这条边是不能连接的。
如何判断某条边加入后是否会形成环:
A点 边 B边,A点和B点已经有间接路径(在同一集合中)了,这个时候再连肯定就会出现环了。
我们之前学过的一个数据结构叫做并查集,就是专门来干这件事的,判断两个顶点在不在同一集合中和Union(a,b)。我们采用quickUnion的思想
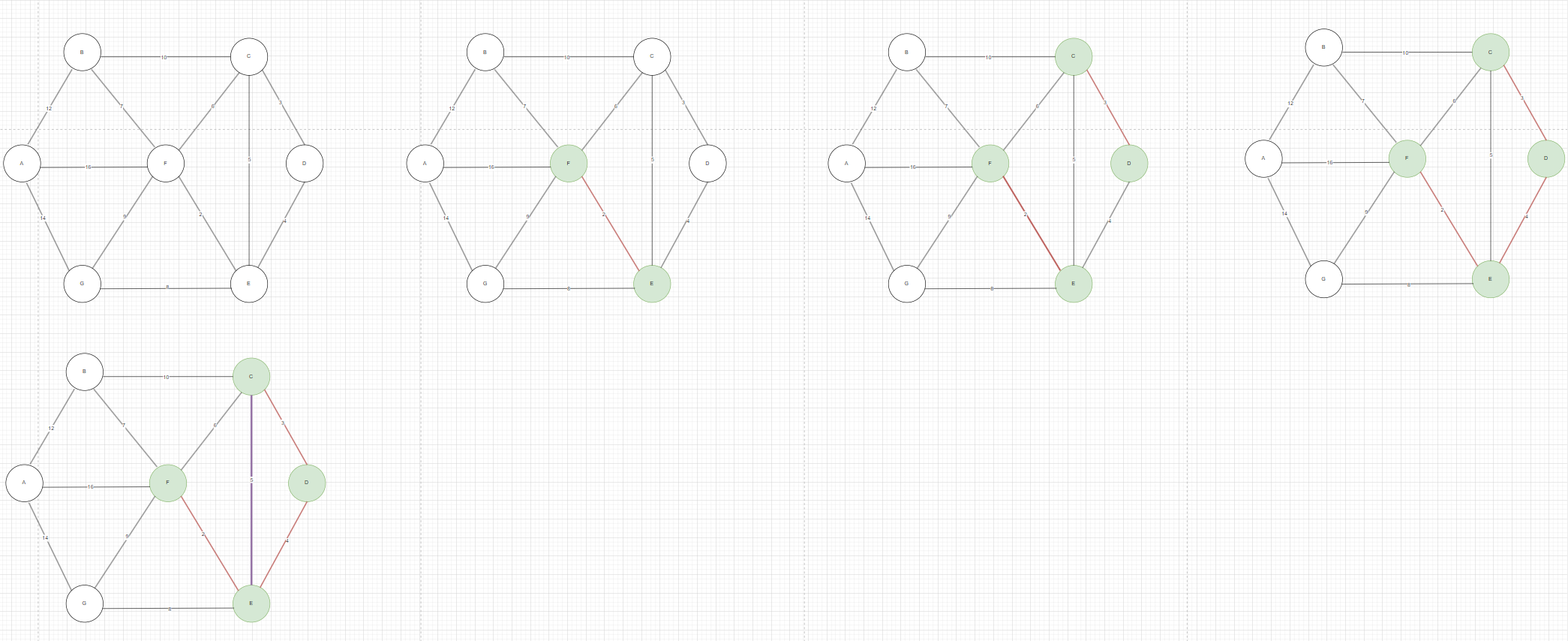
图3
如图4,很明显权值为6的这条边也不能连接,再找下一个7,F的父节点是C,B的父节点是B,两者不同,所以可以连接F和B,再找8,连接G和E,再找12,连接A和B。最后这个最小生成树的权值为36。
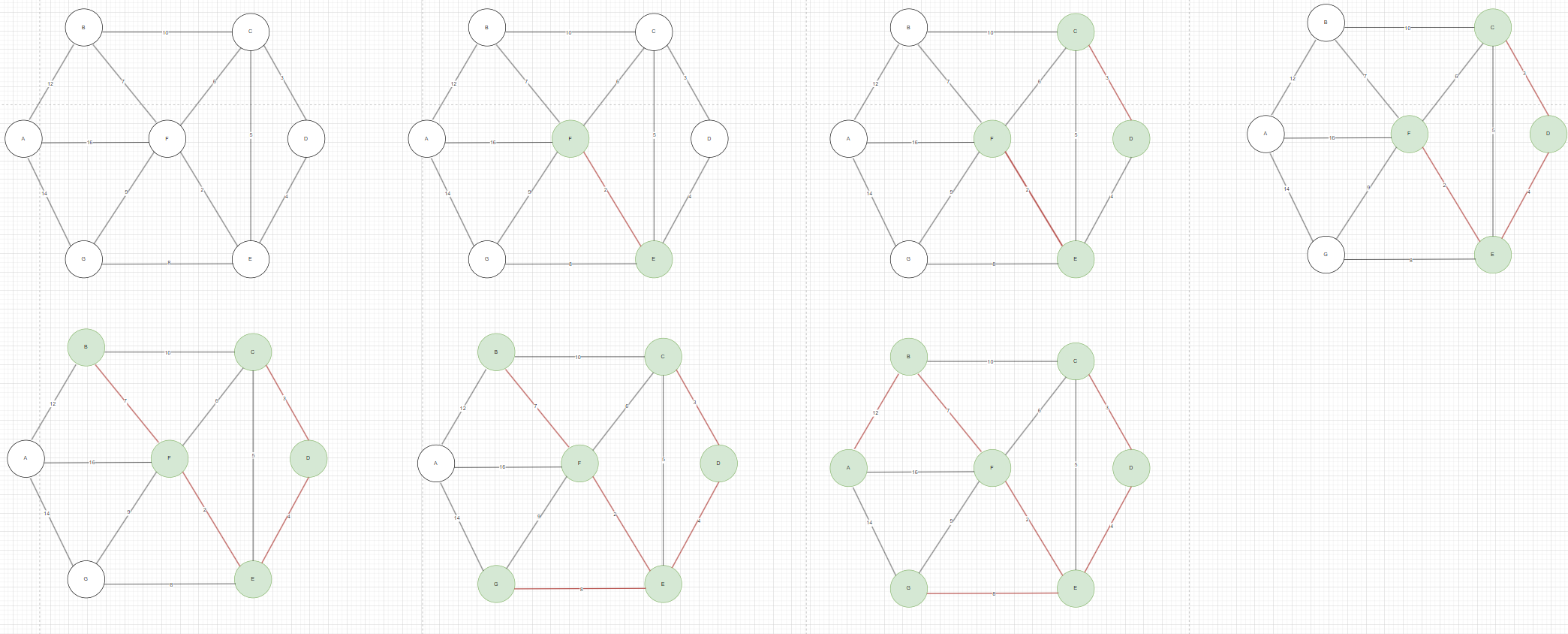
图4
我们知道5种图的存储方式:邻接矩阵,邻接表,十字链表,多重邻接表,边集数组,我们暂时学过前面4种,那用哪一种方式来存这个带权图呢?
回想一下我们对这个带权图的操作,我们是在找图中的边的最小值,意思是我们就存边,把边的权值从小到大排个序,在满足条件的情况下,一直找边的权值的最小值,咋一看这里应该使用边集数组来存这个带权图,但是又有一个问题,边集数组只存了边,我们的顶点在哪里存呢?不适用通用性。所以边集数组只是一个临时空间,我们可以先用邻接矩阵表示通用图,这个通用图我们把它转成边集数组,有了边集数组我们再实现Kruskal算法,来寻找最小生成树。
3.Kruskal算法代码实现
头文件定义:
我们需要用到之前写的邻接矩阵的结构,common里面写的是边集数组的结构,由于后面Prim算法也会用到这个,所以干脆把这个结构体封装成一个文件了。
#ifndef COMMON_H
#define COMMON_H
/*边集数组的结构*/
typedef struct {int begin; //边的起点 (顶点1)int end; //边的终点 (顶点2)int weight; //边的权值
}EdgeSet;
#endif //COMMON_H在Kruskal头文件里写三个接口函数,分别是用来从邻接矩阵中初始化边集数组,排序边集数组和实现Kruskal算法。
#ifndef KRUSKAL_H
#define KRUSKAL_H
/* 利用邻接矩阵 生成一个边集数组,利用边集数组实现Kruskal算法* 算法思路:* a. 将所有的边按权值的大小进行升序排序,从小到大依次提取边的情况,满足条件* b. 加入这条边,和之前已经选中的边不能组成环路,如果不能,这条边就归入生成树的结果部分* c. 如果能,舍去,再找下一条,直到筛选出n - 1条边*/
#include"matrixGraph.h"
#include"common.h"// 从邻接矩阵中初始化边集数组,返回值表示边集数组的个数
void initEdgeSet(const MatrixGraph *graph, EdgeSet *edges);// 排序边集数组
void sortEdgeSet(EdgeSet *edges, int num);// Kruskal算法
int KruskalMGraph(const EdgeSet *edges, int num, int node_num, EdgeSet *result);
#endif //KRUSKAL_H初始化边集数组:void initEdgeSet(const MatrixGraph *graph, EdgeSet *edges);
void initEdgeSet(const MatrixGraph* graph, EdgeSet* edges) {int k = 0;for (int i = 0; i < graph->nodeNum; ++i) { // 遍历每个顶点for (int j = i + 1; j < graph->nodeNum; ++j) { // 遍历上三角(无向图所以只需遍历一半)if (graph->edges[i][j] > 0) {edges[k].begin = i;edges[k].end = j;edges[k].weight = graph->edges[i][j];k++;}}}
}这个接口是用原来邻接矩阵存的有权图来初始化边集数组Edge,因为是无向图,邻接矩阵的边的集合是对称矩阵,我们只需要遍历一半就行。
排序:void sortEdgeSet(EdgeSet* edges, int num);
void sortEdgeSet(EdgeSet* edges, int num) {EdgeSet tmp;for (int i = 0; i < num; ++i) {for (int j = i + 1; j < num; ++j) {if (edges[j].weight < edges[i].weight) {memcpy(&tmp, &edges[i], sizeof(EdgeSet));memcpy(&edges[i], &edges[j], sizeof(EdgeSet));memcpy(&edges[j], &tmp, sizeof(EdgeSet));}}}
}
将边集数组中的边的权值按从小到大排好。
先来简单测试下我们这两个接口的正确性:
#include <stdlib.h>#include"Kruskal.h"
#include"stdio.h"void setUpMatrixGraph(MatrixGraph *graph) {// 0 1 2 3 4 5 6char *names[] = {"A", "B", "C", "D", "E", "F", "G"};initMatrixGraph(graph, names, sizeof(names)/sizeof(names[0]), 0, 0);addMGraphEdge(graph, 0, 1, 12);addMGraphEdge(graph, 0, 5, 16);addMGraphEdge(graph, 0, 6, 14);addMGraphEdge(graph, 1, 2, 10);addMGraphEdge(graph, 1, 5, 7);addMGraphEdge(graph, 2, 3, 3);addMGraphEdge(graph, 2, 4, 5);addMGraphEdge(graph, 2, 5, 6);addMGraphEdge(graph, 3, 4, 4);addMGraphEdge(graph, 4, 5, 2);addMGraphEdge(graph, 4, 6, 8);addMGraphEdge(graph, 5, 6, 9);
}void showEdges(EdgeSet *edges,int num) {for (int i = 0; i < num; ++i) {printf("<%d>---<%d>---<%d>\n",edges[i].begin,edges[i].end,edges[i].weight);}
}void test01() {MatrixGraph graph;EdgeSet *edges;setUpMatrixGraph(&graph);edges=malloc(sizeof(EdgeSet)*graph.edgeNum);if (edges==NULL) {printf("malloc error");return;}initEdgeSet(&graph,edges);sortEdgeSet(edges,graph.edgeNum);showEdges(edges,graph.edgeNum);free(edges);
}int main() {test01();return 0;
}
我们以图2举例,void setUpMatrixGraph(MatrixGraph *graph)这个函数就是在初始化图2的这个带权图的过程,在test01中调用void setUpMatrixGraph(MatrixGraph *graph)初始化好后,动态申请一个边集数组,调用Kruskal.h中写的初始化函数:void initEdgeSet(const MatrixGraph *graph, EdgeSet *edges);再调用写的排序函数void sortEdgeSet(EdgeSet * edges, int num);最后打印出结果如下:
D:\work\DataStruct\cmake-build-debug\03_GraphStruct\MiniTree.exe
<4>---<5>---<2>
<2>---<3>---<3>
<3>---<4>---<4>
<2>---<4>---<5>
<2>---<5>---<6>
<1>---<5>---<7>
<4>---<6>---<8>
<5>---<6>---<9>
<1>---<2>---<10>
<0>---<1>---<12>
<0>---<6>---<14>
<0>---<5>---<16>进程已结束,退出代码为 0
可以看到第三列的权值是从小到大排列的。
Kruskal算法:int KruskalMGraph(const EdgeSet* edges, int num, int node_num, EdgeSet* result);
static int getRoot(const int *uSet, int a) {while (uSet[a] != a) {a = uSet[a];}return a;
}int KruskalMGraph(const EdgeSet* edges, int num, int node_num, EdgeSet* result) {int *uSet;int count = 0;int sum = 0;// 1. 初始化并查集uSet = malloc(sizeof(int) * node_num);if (uSet == NULL) {printf("malloc failed\n");return -1;}for (int i = 0; i < node_num; ++i) {uSet[i] = i;}// 2. 从已经排序好的边集中,找到最小的边,不构成环for (int i = 0; i < num; ++i) {int a = getRoot(uSet, edges[i].begin);int b = getRoot(uSet, edges[i].end);if (a != b) {// 不构成环uSet[a] = b;result[count].begin = edges[i].begin;result[count].end = edges[i].end;result[count].weight = edges[i].weight;sum += edges[i].weight;count++;if (count == node_num - 1) {break;}}}free(uSet);return sum;
}
先申请并查集的的空间,然后初始化它,初始时并查集中的每一个顶点的父节点都指向的是自己,然后开始贪心,如果两个集合的root不一样,把一个集合的root交给另一个集合,即合并集合,一直循环到count(边数)等于顶点-1,最小生成树已构建完成,free掉并查集。
最后来测一下:
#include <stdlib.h>#include"Kruskal.h"
#include"stdio.h"void setUpMatrixGraph(MatrixGraph *graph) {// 0 1 2 3 4 5 6char *names[] = {"A", "B", "C", "D", "E", "F", "G"};initMatrixGraph(graph, names, sizeof(names)/sizeof(names[0]), 0, 0);addMGraphEdge(graph, 0, 1, 12);addMGraphEdge(graph, 0, 5, 16);addMGraphEdge(graph, 0, 6, 14);addMGraphEdge(graph, 1, 2, 10);addMGraphEdge(graph, 1, 5, 7);addMGraphEdge(graph, 2, 3, 3);addMGraphEdge(graph, 2, 4, 5);addMGraphEdge(graph, 2, 5, 6);addMGraphEdge(graph, 3, 4, 4);addMGraphEdge(graph, 4, 5, 2);addMGraphEdge(graph, 4, 6, 8);addMGraphEdge(graph, 5, 6, 9);
}// void showEdges(EdgeSet *edges, int num) {
// for (int i = 0; i < num; ++i) {
// printf("<%d>---<%d>---<%d>\n", edges[i].begin, edges[i].end, edges[i].weight);
// }
// }void test01() {MatrixGraph graph;EdgeSet *edges;EdgeSet *result;setUpMatrixGraph(&graph);edges=malloc(sizeof(EdgeSet)*graph.edgeNum);if (edges==NULL) {printf("malloc error");return;}initEdgeSet(&graph,edges);sortEdgeSet(edges,graph.edgeNum);//showEdges(edges,graph.edgeNum);result = malloc(sizeof(EdgeSet) * (graph.nodeNum - 1));if (result == NULL) {free(edges);return;}int sum = KruskalMGraph(edges, graph.edgeNum, graph.nodeNum, result);for (int i = 0; i < graph.nodeNum - 1; i++) {printf("edge %d: <%s> --- <%d> ---- <%s>\n", i + 1,graph.vex[result[i].begin].show, result[i].weight, graph.vex[result[i].end].show);}printf("sum = %d\n", sum);free(result);free(edges);
}int main() {test01();return 0;
}
由于边集数组中没有顶点,要想打出顶点,要用 graph.vex(顶点集)下的result[i].begin(下标)下的显示行为。
结果:
D:\work\DataStruct\cmake-build-debug\03_GraphStruct\MiniTree.exe
edge 1: <E> --- <2> ---- <F>
edge 2: <C> --- <3> ---- <D>
edge 3: <D> --- <4> ---- <E>
edge 4: <B> --- <7> ---- <F>
edge 5: <E> --- <8> ---- <G>
edge 6: <A> --- <12> ---- <B>
sum = 36进程已结束,退出代码为 0大概先写这些吧,今天的博客就先写到这,谢谢您的观看。