Python网络爬虫(一) - 爬取静态网页
文章目录
- 一、静态网页概述
- 1. 静态网页介绍
- 2. 静态网页爬取技术Requests介绍
- 二、安装 Requests 库
- 三、发送请求并获取响应
- 1. 发送 GET 请求
- 1.1 get() 方法介绍
- 1.2 get() 方法签名介绍
- 1.3 get() 方法参数介绍
- 1.4 示例:发送get请求
- 2. 发送 POST 请求
- 2.1 post() 方法介绍
- 2.2 post() 方法签名介绍
- 2.3 post() 方法参数介绍
- 2.4 请求与响应测试服务网站介绍
- 2.5 示例:发送 POST 请求
- 四、处理响应
- 1. 响应类 Response 介绍
- 2. Response 类的属性介绍
- 3. 示例:处理响应
- 五、处理复杂 GET 请求
- 1. 定制请求头
- 1.1 User-Agent 介绍
- 1.2 Cookie 介绍
- 1.3 示例:访问登录后的网易云阅读
- 2. 保持会话
- 2.1 Session 介绍
- 2.2 示例:使用 Session 保持会话
- 2.2.1 基本用法示例
- 2.2.2 进阶:设置全局请求头
- 3. SSL证书验证
- 3.1 SSL证书介绍
- 3.2 关闭SSL证书验证
- 3.2.1 全局关闭
- 3.2.2 在Session中关闭
- 4. 代理服务器
- 4.1 代理服务器介绍
- 4.2 代理服务器的作用
- 4.3 设置代理服务器
- 4.3.1 常见的代理网站介绍
- 4.3.2 检测免费代理IP的有效性
- 4.3.3 设置代理服务器
- 六、实战:爬取豆瓣读书中小说的网页
一、静态网页概述
1. 静态网页介绍
静态网页是指内容固定不变的网页,其页面代码(HTML、CSS、JavaScript等)预先编写完成并存储在服务器上,当用户访问时,服务器直接将现成的网页文件发送到用户浏览器进行展示。页面内容不会因用户操作或其他因素动态改变,所有访问者看到的内容完全一致。常见的静态网页文件后缀有.html、.htm等,适用于内容更新频率低的场景。
2. 静态网页爬取技术Requests介绍
Requests是Python中一款简洁高效的HTTP库,专门用于发送HTTP请求,是爬取静态网页的常用工具。使用时,通过导入requests库,调用get()、post()等方法即可向目标网页服务器发送请求,获取网页的HTML源代码。其操作流程简单:先使用requests.get(url)向指定URL发送GET请求,再通过response.text获取响应的网页文本内容,后续可结合解析库(如BeautifulSoup)提取所需数据。相比Python内置的urllib库,Requests语法更简洁,支持自动处理Cookie、设置请求头、处理编码等功能,大幅降低了静态网页爬取的实现难度。
二、安装 Requests 库
在开始使用 Python 发送网络请求前,需要先安装 Requests 库。Requests 是 Python 生态中最受欢迎的 HTTP 客户端库之一,它简化了网络请求的流程,支持 GET、POST 等多种请求方法,并能轻松处理响应数据、Cookie、 headers 等细节,极大降低了网络编程的门槛。
为了确保安装过程稳定高效,同时避免版本兼容性问题,推荐指定具体版本(本教程使用 2.31.0 版本),并通过国内镜像源加速下载。以下是具体的安装命令:
pip install requests==2.31.0 -i https://mirrors.aliyun.com/pypi/simple/
三、发送请求并获取响应
1. 发送 GET 请求
GET 请求是 HTTP 协议中最常用的请求方法之一,主要用于从服务器获取资源(如网页内容、API 数据等)。Requests 库通过 requests.get() 方法实现 GET 请求的发送,使用简单且功能强大。
1.1 get() 方法介绍
requests.get() 是 Requests 库中用于发送 HTTP GET 请求的核心方法。它的作用是向指定的 URL 发送 GET 请求,并返回服务器响应的结果(封装在 Response 对象中)。
1.2 get() 方法签名介绍
方法签名(Signature)描述了方法的定义形式,包括方法名、参数列表和返回值。requests.get() 方法的完整签名如下:
def get(url, params=None, *args, **kwargs):return request('get', url, params=params,** kwargs)
从签名可以看出:
- 该方法本质上是对
requests.request()方法的封装,指定了请求方法为'get'; url是必填参数,其余参数为可选;- 返回值是一个
Response对象,包含服务器响应的所有信息(状态码、响应体、headers 等)。
1.3 get() 方法参数介绍
requests.get() 方法的参数可分为 URL 相关参数和请求配置参数,以下是常用参数的详细说明(按使用频率排序):
| 参数名 | 类型 | 是否必填 | 说明 | 示例 |
|---|---|---|---|---|
url | str | 是 | 目标资源的 URL 地址,即需要发送请求的服务器端点。 | url="https://api.example.com/data" |
params | dict/list/bytes | 否 | 用于构建 URL 的查询参数(Query String),会自动转换为 URL 中的键值对并进行 URL 编码。 | params={"id": 1, "name": "test"}(等价于 URL 后拼接 ?id=1&name=test) |
headers | dict | 否 | 请求头信息,用于模拟浏览器环境、传递认证信息等,如 User-Agent、Authorization 等。 | headers={"User-Agent": "Mozilla/5.0"} |
timeout | float/tuple | 否 | 请求超时时间(单位:秒)。单值表示总超时时间;元组表示(连接超时,读取超时)。 | timeout=3 或 timeout=(2, 5) |
cookies | dict/CookieJar | 否 | 携带的 Cookie 信息,用于维持会话状态(如登录状态)。 | cookies={"session_id": "abc123"} |
verify | bool/str | 否 | 是否验证 SSL 证书。默认 True(验证);设为 False 可跳过验证(不建议生产环境使用)。 | verify=False(跳过 SSL 验证) |
allow_redirects | bool | 否 | 是否允许自动处理重定向(如 301、302 状态码)。默认 True(允许)。 | allow_redirects=False(禁止自动重定向) |
auth | tuple/AuthBase | 否 | 用于 HTTP 认证的信息,如 Basic Auth、Digest Auth 等。 | auth=("username", "password")(Basic 认证) |
proxies | dict | 否 | 代理服务器配置,用于通过代理发送请求。 | proxies={"http": "http://127.0.0.1:8080"} |
1.4 示例:发送get请求
# 导入 requests 库,用于发送 HTTP 请求
import requests# 定义目标网站的基础 URL(豆瓣图书中“小说”标签的页面)
base_url = 'https://book.douban.com/tag/小说'# 设置请求头(headers),模拟浏览器访问,避免被服务器识别为爬虫而拒绝请求
# User-Agent 表示客户端信息,这里模拟的是 Chrome 浏览器在 Windows 10 系统上的访问
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.0.0 Safari/537.36'
}# 定义 URL 的查询参数(query parameters)
# 这些参数会自动拼接到 URL 后面,形成完整的请求地址
params = {'start': 20, 'type': 'T'}# 发送 GET 请求到目标 URL
# 请求会自动将 base_url 与 params 拼接成完整地址:https://book.douban.com/tag/小说?start=20&type=T
# 同时携带 headers 中的请求头信息
response = requests.get(base_url, headers=headers, params=params)# 输出响应的状态码
# 200 表示请求成功,404 表示页面未找到,403 表示禁止访问等
print(response.status_code)# 输出最终请求的完整 URL(包含查询参数)
# 用于确认实际请求的地址是否正确
print(response.url)
打印结果如下图所示:
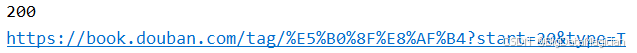
2. 发送 POST 请求
POST 请求是 HTTP 协议中另一种常用的请求方法,主要用于向服务器提交数据(如表单提交、API 数据提交等),数据通常包含在请求体中,而非 URL 中,适用于传输敏感信息或大量数据的场景。Requests 库通过 requests.post() 方法实现 POST 请求的发送,功能灵活且易于扩展。
2.1 post() 方法介绍
requests.post() 是 Requests 库中用于发送 HTTP POST 请求的核心方法。它的作用是向指定的 URL 发送包含数据的 POST 请求,并返回服务器响应的结果(封装在 Response 对象中)。
与 GET 请求相比,POST 请求的核心特点是数据放在请求体中传输,因此更适合以下场景:
- 提交用户表单数据(如登录、注册);
- 向服务器发送 JSON 格式的 API 数据;
- 上传文件或二进制数据;
- 传输需要隐藏的敏感信息(如密码、Token)。
2.2 post() 方法签名介绍
requests.post() 方法的签名与 get() 类似,本质上也是对 requests.request() 方法的封装,只是固定了请求方法为 'post'。其完整签名如下:
def post(url, data=None, json=None, *args, **kwargs):return request('post', url, data=data, json=json,** kwargs)
从签名可以看出:
url是必填参数,用于指定请求的目标 URL;data和json是 POST 请求特有的参数,用于传递请求体数据;- 其他参数(如
headers、timeout等)与get()方法一致,通过**kwargs传入; - 返回值为
Response对象,包含服务器响应的状态码、响应体、headers 等信息。
2.3 post() 方法参数介绍
requests.post() 方法的参数在继承 get() 方法通用参数(如 url、headers、timeout 等)的基础上,增加了两个核心参数用于传递请求体数据。以下是常用参数的详细说明(重点标注 POST 特有参数):
| 参数名 | 类型 | 是否必填 | 说明 | 示例 |
|---|---|---|---|---|
url | str | 是 | 目标资源的 URL 地址,即接收 POST 数据的服务器端点。 | url="https://api.example.com/login" |
data | dict/str/bytes | 否 | POST 请求体数据,适用于表单提交(application/x-www-form-urlencoded 格式)或二进制数据。 | data={"username": "test", "age": 20} 或 data="key=value&key2=value2" |
json | dict/list | 否 | POST 请求体数据,自动序列化为 JSON 格式(application/json 格式),适用于 API 接口调用。 | json={"user": {"name": "test", "role": "admin"}} |
headers | dict | 否 | 请求头信息,可指定数据格式(如 Content-Type: application/json)、认证信息等。 | headers={"Content-Type": "application/json", "Token": "xxx"} |
timeout | float/tuple | 否 | 请求超时时间(单位:秒),同 get() 方法。 | timeout=5 或 timeout=(3, 7) |
cookies | dict/CookieJar | 否 | 携带的 Cookie 信息,用于维持会话状态,同 get() 方法。 | cookies={"session": "abc123"} |
files | dict | 否 | 文件上传参数,键为字段名,值为文件对象或路径(multipart/form-data 格式)。 | files={"avatar": open("test.jpg", "rb")} |
verify | bool/str | 否 | 是否验证 SSL 证书,同 get() 方法。 | verify=True(默认验证) |
allow_redirects | bool | 否 | 是否允许自动重定向,同 get() 方法,默认 True。 | allow_redirects=False |
auth | tuple/AuthBase | 否 | HTTP 认证信息,同 get() 方法。 | auth=("admin", "123456") |
注意:
data和json参数通常二选一:
- 若提交表单数据或键值对,用
data;- 若提交 JSON 格式数据,用
json(Requests会自动设置Content-Type: application/json头)。
2.4 请求与响应测试服务网站介绍
https://httpbin.org/是一个开源的HTTP请求与响应测试服务网站,基于Python的Flask框架开发,能为开发者提供多种实用功能,在开发和测试工作中作用显著。
- 核心功能
- HTTP方法测试:支持GET、POST、PUT、PATCH、DELETE等所有HTTP动词,可返回请求的完整信息,像参数、头部、URL等,方便开发者测试不同类型请求。
- 状态码测试:能生成指定状态码的响应,例如200 OK、404 Not Found、500 Internal Server Error等,有助于测试客户端的错误处理机制。
- 请求与响应检查:允许开发者查看请求的详细信息,包括头部、查询参数、请求体内容等;也能检查响应数据,如缓存信息、响应头。
- 多种响应格式:可返回JSON、HTML、图片等不同格式的响应,方便测试客户端对不同内容类型的处理能力。
- 动态数据生成:能生成随机和动态数据,例如随机的JSON响应或指定尺寸的图片,便于测试客户端在各种边界情况下的表现。
- Cookie操作:支持创建、读取和删除Cookie,方便测试涉及Cookie的业务逻辑。
- 重定向测试:可以返回不同的重定向响应,用于测试客户端对重定向的处理。
- 应用场景
- 接口测试:快速验证请求和响应的结构是否正确,检查接口是否按预期工作。
- 网络诊断:帮助检查代理、IP、头部等网络层问题,例如确定代理是否正常工作、请求的IP是否正确。
- 开发调试:在开发HTTP客户端或涉及网络请求的应用时,借助该网站模拟各种请求和响应情况,辅助调试代码。
- 优势与不足:该网站轻量且功能全面,支持复杂场景测试;但由于服务器在国外,可能存在访问速度慢的问题。
2.5 示例:发送 POST 请求
模拟网页表单提交(如登录、注册),数据格式为 application/x-www-form-urlencoded。
# 导入 requests 库,用于发送 HTTP 请求
import requests# 定义目标 URL,这里使用的是 httpbin.org 的 POST 测试接口
# 该网站用于测试 HTTP 请求,/post 接口会接收并返回你发送的数据
url = "https://httpbin.org/post"# 定义要发送的表单数据(字典格式)
# 通常用于模拟用户登录、提交表单等场景
data = {"username": "username","password": "password"
}# 使用 POST 方法向指定 URL 发送请求
# 参数说明:
# - url: 目标地址
# - data: 要发送的表单数据(会以 application/x-www-form-urlencoded 格式编码)
# - timeout=5: 设置请求超时时间为 5 秒,防止程序无限等待
# 返回一个 Response 对象,包含服务器响应信息
response = requests.post(url=url, data=data, timeout=5)# 打印服务器返回的 HTTP 状态码
# 常见状态码:
# - 200: 请求成功
# - 400: 请求错误(如参数不合法)
# - 404: 页面未找到
# - 500: 服务器内部错误
# 这里预期输出为 200,表示请求成功被接收和处理
print("状态码:", response.status_code)
打印结果如下所示:
状态码: 200
四、处理响应
当使用 requests.get() 或 requests.post() 等方法发送请求后,Requests 库会返回一个 Response 对象。该对象封装了服务器响应的所有信息,开发者可以通过它获取状态码、响应体、请求头等关键数据,从而完成对请求结果的处理。
1. 响应类 Response 介绍
Response 是 Requests 库中用于表示服务器响应的核心类,它包含了一次 HTTP 请求的全部响应信息。无论是成功的请求(如 200 状态码)还是失败的请求(如 404 状态码),都会返回该类的实例。
Response 类的主要作用是:
- 提供对响应状态的判断(如是否成功、是否重定向);
- 解析并返回响应体数据(如文本、JSON、二进制内容);
- 暴露请求和响应的元数据(如请求 URL、响应头、Cookie 等);
- 提供便捷的方法处理响应内容(如自动解码、JSON 解析)。
2. Response 类的属性介绍
Response 类提供了丰富的属性,用于获取响应的各类信息。以下是常用属性的详细说明(按使用频率排序):
| 属性名 | 类型 | 说明 | 示例(基于成功请求) |
|---|---|---|---|
status_code | int | 服务器返回的 HTTP 状态码,用于判断请求是否成功(200 表示成功,4xx 表示客户端错误,5xx 表示服务器错误)。 | print(response.status_code) → 200 |
text | str | 响应体的文本内容,自动根据响应头的 Content-Type 猜测编码并解码(如 UTF-8)。 | print(response.text) → 输出网页 HTML 或 JSON 字符串 |
json() | 方法(返回 dict/list) | 将响应体的 JSON 字符串解析为 Python 字典或列表(仅适用于 Content-Type: application/json 的响应)。 | data = response.json() → print(data["args"]) 访问 JSON 中的字段 |
content | bytes | 响应体的二进制原始数据,适用于处理图片、文件等非文本内容。 | with open("image.jpg", "wb") as f: f.write(response.content) 保存图片 |
headers | CaseInsensitiveDict | 服务器返回的响应头,是一个不区分大小写的字典(如 headers["Content-Type"] 与 headers["content-type"] 等价)。 | print(response.headers["Content-Type"]) → application/json |
url | str | 实际请求的 URL(可能因重定向与原始 URL 不同)。 | print(response.url) → https://httpbin.org/get(若发生重定向则显示最终 URL) |
encoding | str | 响应内容的编码方式(如 utf-8),可手动修改以纠正解码错误。 | response.encoding = "utf-8" 强制设置编码 |
cookies | RequestsCookieJar | 服务器返回的 Cookie 信息,可像字典一样访问。 | print(response.cookies["session_id"]) → 获取名为 session_id 的 Cookie 值 |
elapsed | timedelta | 请求发送到接收响应的耗时(时间差),用于分析请求性能。 | print(response.elapsed.total_seconds()) → 0.23(表示耗时 0.23 秒) |
history | list | 包含请求重定向历史的 Response 对象列表(按重定向顺序排列),无重定向时为空。 | print([h.status_code for h in response.history]) → [301](表示一次 301 重定向) |
ok | bool | 快捷判断请求是否成功(status_code 在 200~400 之间时为 True,否则为 False)。 | if response.ok: print("请求成功") |
reason | str | 状态码对应的原因短语(如 200 对应 “OK”,404 对应 “Not Found”)。 | print(response.reason) → OK |
3. 示例:处理响应
# 导入 requests 库,用于发送 HTTP 请求
import requests# 定义目标网站的基础 URL(豆瓣图书中“小说”标签的页面)
base_url = 'https://book.douban.com/tag/小说'# 设置请求头(headers),模拟浏览器访问,避免被服务器识别为爬虫而拒绝请求
# User-Agent 表示客户端信息,这里模拟的是 Chrome 浏览器在 Windows 10 系统上的访问
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.0.0 Safari/537.36'
}# 定义 URL 的查询参数(query parameters)
# 这些参数会自动拼接到 URL 后面,形成完整的请求地址
params = {'start': 20, 'type': 'T'}# 发送 GET 请求到目标 URL
# 请求会自动将 base_url 与 params 拼接成完整地址:https://book.douban.com/tag/小说?start=20&type=T
# 同时携带 headers 中的请求头信息
response = requests.get(base_url, headers=headers, params=params)# 获取服务器返回的 HTTP 状态码(整数类型)
# 常见状态码:200(成功)、404(未找到)、403(禁止访问)、500(服务器错误)等
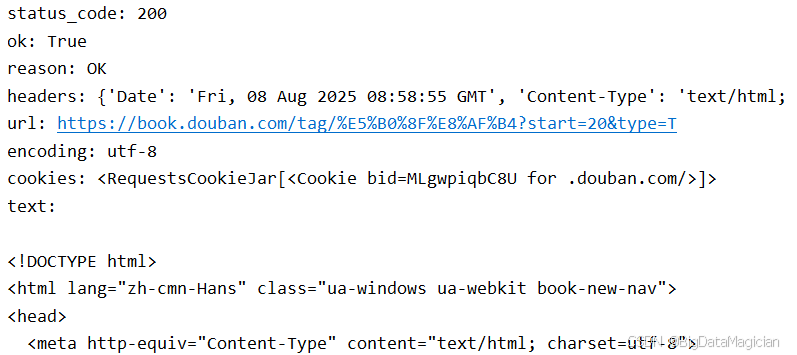
status_code = response.status_code
print('status_code:', status_code) # 输出如:status_code: 200# 判断请求是否成功(布尔值)
# 当 status_code < 400 时返回 True(即 200-399 范围内都算“成功”)
ok = response.ok
print('ok:', ok) # 成功时输出 True,失败时输出 False# 获取状态码对应的原因短语(Reason Phrase)
# 例如 200 -> 'OK',404 -> 'Not Found',500 -> 'Internal Server Error'
reason = response.reason
print('reason:', reason) # 输出如:OK# 获取响应头信息,返回一个字典(dict)
# 包含服务器类型、内容类型、内容长度、编码方式、Set-Cookie、缓存策略等元数据
headers = response.headers
print('headers:', headers) # 输出如:{'Content-Type': 'application/json', 'Server': 'nginx', ...}# 获取实际请求的完整 URL
# 如果发生了重定向,url 返回的是最终到达的页面地址(而非原始请求地址)
url = response.url
print('url:', url) # 输出如:https://httpbin.org/get?name=test# 获取或设置当前使用的字符编码
# requests 会自动猜测编码,但有时不准确(如中文网页为 GBK),可手动设置 response.encoding = 'gbk'
encoding = response.encoding
print('encoding:', encoding) # 输出如:utf-8# 获取服务器返回的 Cookies
# 返回一个 RequestsCookieJar 对象,可用于会话保持(如登录后访问其他页面)
cookies = response.cookies
print('cookies:', cookies) # 输出如:<RequestsCookieJar[<Cookie sessionid=abc123 for .example.com/>]># 获取响应内容的字符串形式(自动解码后的文本)
# requests 会根据响应头中的 charset 自动推断编码(如 UTF-8),也可手动设置 encoding
text = response.text
print('text:', text) # 通常用于查看网页 HTML 或 API 返回的文本内容# 获取响应内容的原始字节数据(bytes 类型)
# 适用于处理非文本数据,如图片、PDF、音频、视频等二进制文件
content = response.content
print('content:', content) # 输出为字节串,例如:b'{"key": "value"}'
运行部分结果如下图所示:
五、处理复杂 GET 请求
在实际开发中,简单的 GET 请求往往无法满足需求。例如,部分网站会验证请求的合法性(如检查浏览器标识、登录状态等),此时需要通过定制请求头、携带 Cookie 等方式模拟真实的浏览器行为。以下介绍如何处理这类复杂的 GET 请求。
1. 定制请求头
请求头(Headers)是 HTTP 请求中包含的元数据,用于向服务器传递附加信息(如浏览器类型、支持的数据格式、认证信息等)。通过定制请求头,开发者可以模拟不同的客户端环境,绕过部分服务器限制(如反爬虫机制)。
1.1 User-Agent 介绍
User-Agent 是请求头中最常用的字段之一,用于标识发送请求的客户端(如浏览器、爬虫程序等)。服务器通过该字段判断请求来源,部分网站会拒绝非浏览器的请求(如直接使用 Requests 库默认的 User-Agent)。
特点与作用:
- 格式:通常包含客户端类型、版本、操作系统等信息,例如浏览器的
User-Agent格式为:
Mozilla/5.0 (操作系统) 浏览器引擎/版本 浏览器/版本 - 作用:服务器可根据
User-Agent返回适配客户端的内容(如移动端和 PC 端页面),或限制非浏览器请求(反爬虫)。 - 默认问题:
Requests库的默认User-Agent为python-requests/版本号,容易被服务器识别为爬虫并拦截。
1.2 Cookie 介绍
Cookie 是服务器存储在客户端的小型数据片段,主要用于维持会话状态(如登录状态、用户偏好等)。当客户端再次向同一服务器发送请求时,会自动携带对应的 Cookie,使服务器识别用户身份。
特点与作用:
- 数据格式:由键值对组成(如
session_id=abc123; user_id=100),通常包含过期时间、域名等属性。 - 作用:实现跨请求的状态保持,例如:
- 登录后服务器返回
session_idCookie,后续请求携带该 Cookie 即可保持登录状态; - 记录用户的浏览历史、购物车等信息。
- 登录后服务器返回
- 获取方式:Cookie 通常由服务器通过响应头的
Set-Cookie字段返回,客户端(如浏览器)自动保存。
1.3 示例:访问登录后的网易云阅读
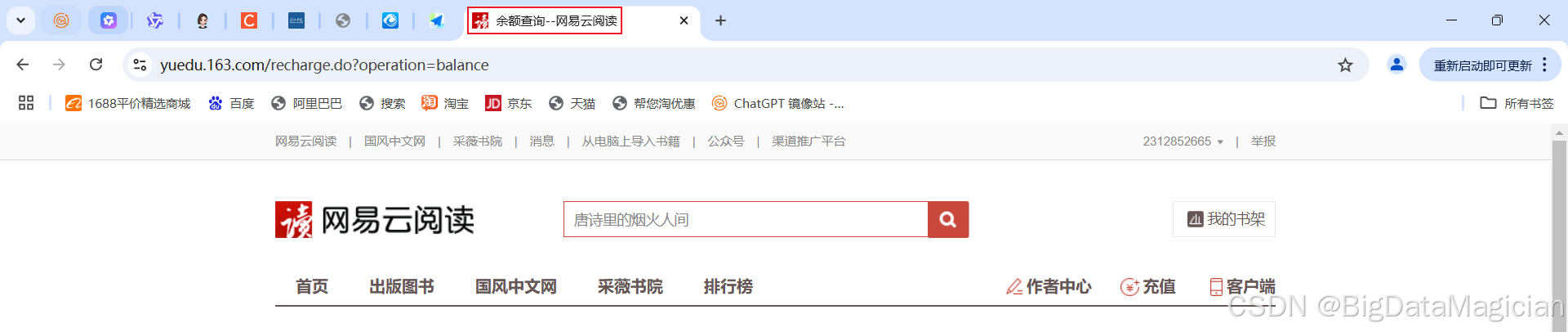
目的:使用代码访问登录后的网易云阅读的余额查询页面并保存。
登录后的网易云阅读个人信息页面如下图所示,可以看到网页标题是余额查询–网易云阅读,网址是https://yuedu.163.com/recharge.do?operation=balance。
接下退出登录,然后直接访问https://yuedu.163.com/recharge.do?operation=balance,会跳转到登录页面,需要先登录才能访问,此时的标题是登录–网易云阅读,如下图所示。

查看登录后的Cookie,如下图所示。
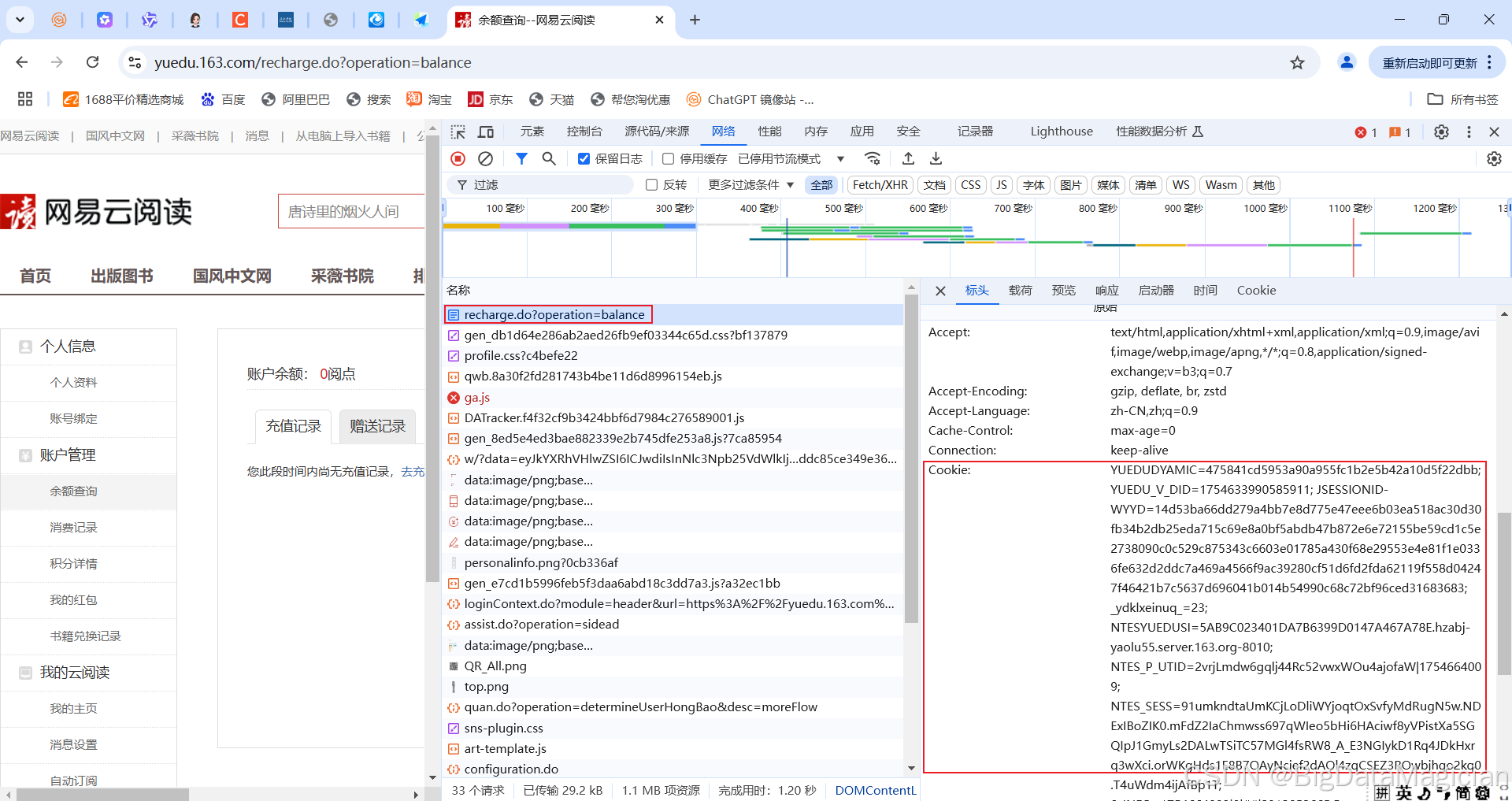
代码实现如下:
# 导入 pathlib 中的 Path 类,用于跨平台安全地处理文件和目录路径
from pathlib import Path# 导入 requests 库,用于发送 HTTP 请求
import requests# 定义目标 URL:网易阅读(yuedu.163.com)的余额查询接口
# 该接口通常用于获取用户的账户余额信息
base_url = 'https://yuedu.163.com/recharge.do?operation=balance'# 设置请求头(headers),模拟浏览器行为,避免被服务器识别为爬虫
headers = {# User-Agent:标识客户端浏览器和操作系统信息'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.0.0 Safari/537.36',# Cookie:携带登录状态信息# 注意:这里的 '登录后的Cookie' 是占位符,实际使用时需替换为真实登录后的 Cookie 字符串# 否则服务器会认为你未登录,返回登录页或错误信息'Cookie': '登录后的Cookie'
}# 向目标 URL 发送 GET 请求
# 请求携带指定的 headers(包含 User-Agent 和 Cookie)
# 由于 URL 中已包含参数 ?operation=balance,无需额外传入 params
response = requests.get(base_url, headers=headers)# 获取服务器返回的 HTTP 状态码,用于判断请求是否成功
status_code = response.status_code# 判断状态码是否为 200(表示请求成功)
if status_code == 200:# 如果请求成功,获取响应的文本内容(HTML 或 JSON 等)text = response.text# 定义本地保存文件的目录路径dir_path = Path('./html')# 定义保存的文件名file_name = 'wagnyi.html'# 创建目录(如果不存在)# parents=True:支持创建多级目录(如 ./html/a/b)# exist_ok=True:如果目录已存在,不会报错dir_path.mkdir(parents=True, exist_ok=True)# 打开文件并写入响应内容# 使用 with 语句确保文件在写入后自动关闭,避免资源泄漏# 'w' 模式:写入文本# encoding='utf-8':指定编码为 UTF-8,支持中文等多语言字符with open(dir_path / file_name, 'w', encoding='utf-8') as fp:fp.write(str(text)) # 将响应内容(text)转换为字符串并写入文件# 提示:网页内容已成功保存print(f"✅ 成功将响应内容保存到: {dir_path / file_name}")
else:# 如果请求失败,输出错误状态码print(f"❌ 请求失败,状态码: {status_code}")
2. 保持会话
在实际网络交互中,许多操作需要多步请求协同完成,且后续请求依赖于前期请求的状态(例如:登录后才能访问个人中心,购物车操作依赖登录状态等)。此时,单纯通过手动传递 Cookie 维持状态会非常繁琐,而 Requests 库提供的 Session 类可以完美解决这一问题。
2.1 Session 介绍
Session 是 Requests 库中用于创建持久会话的类,它能够在多个请求之间保持状态信息(如 Cookie、请求头),模拟浏览器的“会话”机制。简单来说,Session 就像一个“持续打开的浏览器”,在其生命周期内发送的所有请求会自动共享 Cookie 和部分配置,无需手动传递。
核心特点:
-
状态持久性
- 会话内的所有请求会自动携带服务器返回的 Cookie(如登录后的
session_id),无需手动设置cookies参数。 - 例如:用
Session发送登录请求后,后续请求会自动携带登录状态的 Cookie,直接访问需要登录的资源。
- 会话内的所有请求会自动携带服务器返回的 Cookie(如登录后的
-
请求头共享
- 可以为
Session设置全局请求头(如User-Agent),会话内的所有请求会自动继承这些头信息,减少重复代码。
- 可以为
-
连接复用
- 会话会复用与服务器的 TCP 连接,减少重复建立连接的开销,提升多请求场景的效率。
与普通请求的区别:
| 场景 | 普通请求(requests.get()) | Session 请求(session.get()) |
|---|---|---|
| Cookie 处理 | 需手动提取和传递 Cookie | 自动保存和携带 Cookie |
| 请求头复用 | 每次请求需单独设置 headers | 可设置全局 headers,所有请求自动继承 |
| 状态维持 | 无状态,每次请求独立 | 有状态,多个请求共享会话信息 |
2.2 示例:使用 Session 保持会话
2.2.1 基本用法示例
import requests# 创建一个 Session 对象
# Session 类似于一个浏览器会话,可以跨请求保持某些参数(如 Cookies、HTTP 认证等)
# 在这里,Session 会自动管理登录后返回的 Cookie,后续请求会自动带上这些 Cookie
session = requests.Session()# 设置测试用的Cookie
session.get('http://httpbin.org/cookies/set/test_cookie/cookie_value')# 第一步:发送登录请求,模拟用户登录操作
# 登录接口地址(此处使用 httpbin.org 的 /post 接口用于测试和演示)
login_url = "https://httpbin.org/post"# 登录所需的表单数据(用户名和密码)
login_data = {"username": "username","password": "password"
}# 使用 session 发送 POST 请求到登录接口
# 由于使用了 Session,服务器返回的 Cookie 会被自动保存和管理
login_response = session.post(login_url, data=login_data)# 打印登录请求的响应状态码,用于判断请求是否成功(如 200 表示成功)
print("登录响应状态码:", login_response.status_code)# 第二步:访问需要登录后才能访问的页面
# 此处使用 httpbin.org 的 /get 接口来验证请求头信息
profile_url = "https://httpbin.org/get"# 使用同一个 session 发起 GET 请求
# Session 会自动携带之前登录时获取的 Cookie,实现“保持登录状态”的效果
profile_response = session.get(profile_url)# 查看本次请求的请求头中是否包含 Cookie
# 这是为了验证 Session 是否自动将登录时获得的 Cookie 添加到了请求头中
print("请求携带的 Cookie:", profile_response.request.headers.get("Cookie"))# 第三步:关闭 Session(可选操作)
# 关闭 Session 可以释放底层连接资源,特别是在长时间运行的程序中建议显式关闭
# Python 的垃圾回收机制通常也会自动处理,但显式关闭是良好的编程习惯
session.close()
打印结果如下图所示:

2.2.2 进阶:设置全局请求头
使用Cookie登录网易云阅读后,保存个人信息页面和余额查询页面;通过 Session 的 headers 属性设置全局请求头,会话内的所有请求会自动携带这些头信息。
# 导入 requests 库,用于发送 HTTP 请求
import requests# 创建一个持久会话对象(Session)
# Session 的作用是:在多个请求之间自动保持状态(如 Cookies、Headers、认证信息等)
# 类似于浏览器打开一个标签页,所有请求共享同一个上下文
session = requests.Session()# 设置全局请求头(headers)
# 使用 update() 方法为该 Session 设置默认请求头
# 后续通过此 session 发出的所有请求都会自动携带这些 headers
session.headers.update({# User-Agent:标识客户端浏览器和操作系统,防止被服务器识别为爬虫而拒绝"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) Chrome/114.0.0.0 Safari/537.36",# Cookie:携带用户的登录凭证# 注意:'登录后的Cookie' 是占位符,实际使用时需替换为真实登录后获取的 Cookie 字符串# 否则服务器会认为你未登录,返回登录页或权限错误"Cookie": '登录后的Cookie'
})# 发送第一个 GET 请求:访问“充值页面”,查询账户余额
# 由于使用了 session,请求会自动携带上面设置的 User-Agent 和 Cookie
# URL 中的 operation=balance 表示执行“查询余额”操作
response1 = session.get("https://yuedu.163.com/recharge.do?operation=balance")# 发送第二个 GET 请求:访问“我的信息”页面
# 同样自动携带 headers 和登录状态(Cookie)
# 可用于获取用户个人信息、阅读记录等
response2 = session.get("https://yuedu.163.com/myinfor")# 将第一个请求的响应内容(HTML)保存到本地文件
# './html/recharge.html' 是保存路径
# 'w' 模式表示写入文本
# encoding='utf-8' 确保中文等字符正确保存,避免乱码
with open('./html/recharge.html', 'w', encoding='utf-8') as fp:fp.write(str(response1.text)) # 将响应文本写入文件# 将第二个请求的响应内容(HTML)保存到本地文件
with open('./html/myinfor.html', 'w', encoding='utf-8') as fp:fp.write(str(response2.text)) # 将响应文本写入文件# 提示:两个页面内容已成功保存
print("页面数据已成功保存:")
print(" - recharge.html")
print(" - myinfor.html")
3. SSL证书验证
3.1 SSL证书介绍
SSL(Secure Sockets Layer,安全套接层)证书是一种数字证书,用于在客户端(如浏览器)和服务器之间建立加密连接,确保数据传输的安全性和完整性。
在Python爬虫中,requests库默认会验证SSL证书的有效性。如果目标网站的SSL证书无效(如自签名证书、过期证书等),会抛出SSLError异常。
3.2 关闭SSL证书验证
在某些特殊场景(如测试环境、内部系统)中,可能需要临时关闭SSL证书验证。使用requests库时,可以通过设置get()方法中的参数verify=False来关闭SSL证书验证。
3.2.1 全局关闭
import requests# 关闭全局SSL验证警告(可选,仅消除警告信息)
# requests.packages.urllib3.disable_warnings()# 发送请求时关闭SSL验证
response = requests.get(url="http://httpbin.org/get", verify=False)print(response.status_code)
3.2.2 在Session中关闭
import requests# 创建会话对象
session = requests.Session()# 关闭会话级别的SSL验证
session.verify = False# 发送请求(自动应用会话设置)
response = session.get("http://httpbin.org/get")# 打印响应状态码
print(response.status_code)
4. 代理服务器
4.1 代理服务器介绍
代理服务器(Proxy Server)是网络信息的中转站,是介于浏览器和Web服务器之间的一台服务器,其功能是代理网络用户去取得网络信息。
代理服务器作为连接Internet与Intranet的桥梁,工作主要在开放系统互联(OSI)模型的对话层。浏览器向代理服务器发出请求,由代理服务器来取回浏览器所需要的信息并传送给浏览器。并且,大部分代理服务器都具有缓冲功能,可将新取得数据包存到本机存储器上,若浏览器请求的数据已存在且为最新,就直接从存储器传输数据给浏览器,能提高浏览速度和效率。
此外,代理服务器还可实现网络的安全过滤、流量控制、用户管理等功能,能解决许多单位连接Internet引起的IP地址不足问题,也可作为一种网络防火墙技术。
4.2 代理服务器的作用
- 突破访问限制:在一些国家或地区,政府或互联网服务提供商可能会限制或封锁某些网站或服务,使用代理可以绕过这些限制,使用户能够访问被封锁的网站或服务。例如,教育网用户可通过代理访问一些外部资源。
- 提高访问速度:代理服务器通常在全球范围内分布有多个节点,用户可以选择就近的代理节点来提高访问速度。同时,其缓存机制也可以让用户在访问相同内容时,直接从代理服务器获取数据,减少数据传输的时间和延迟。
- 隐藏真实IP地址:代理可以帮助用户隐藏其真实的IP地址,让用户的上网行为更加难以追踪,从而减少个人信息泄露的风险,增强隐私保护。
- 增强网络安全:代理服务器可以充当防火墙的角色,阻止恶意内容的访问,过滤掉一些潜在的安全威胁,保护用户数据和隐私。此外,通过代理服务器,内部网络对外部呈现为一个IP地址,外界不能直接访问到内部网,提高了内部网络的安全性。
- 内容过滤与管理:对于企业或学校等组织来说,代理服务器可以用于过滤不需要的内容,例如广告,或者阻止访问某些特定网站,有效地控制内部网络的内容访问。
- 节省IP地址开销:对于局域网内的多个用户,只需代理服务器上有一个合法的IP地址,其他用户可以使用私有IP地址,这样可以节约大量的IP资源,降低网络的维护成本。
4.3 设置代理服务器
4.3.1 常见的代理网站介绍
- 高可用全球免费代理IP库:网址为http://ip.jiangxianli.com,提供了大量的免费代理IP资源,可获取不同地区、类型的代理IP,适合对代理IP需求不太苛刻的临时性使用。
- 西拉代理:网址是http://www.xiladaili.com/,有免费的代理IP可供使用,同时也提供一些付费代理服务,其免费代理IP会定期更新,有一定的可用性。
- 快代理:网址为https://www.kuaidaili.com,提供免费和付费代理服务。免费代理IP部分更新速度较快,可在网站上直接查看可用的代理IP列表,也能按地区等条件进行筛选,但免费代理的稳定性可能稍差。
- ProxyList:提供了大量的免费和付费代理IP,分类清晰,包括HTTP、HTTPS、SOCKS5等多种类型。还提供了IP筛选功能,可以按国家、城市、运营商等条件筛选代理IP,方便用户根据需求查找。
- FreeProxyList:该网站提供的是免费的代理IP,数量和质量都相对较高,支持HTTP、HTTPS、SOCKS4、SOCKS5等多种协议。使用时,只需在搜索框中输入目标网站地址,就可以看到可用的代理IP列表。
4.3.2 检测免费代理IP的有效性
此处以快代理中的免费IP为示例,来检测免费代理IP的有效性。打开快代理,选用的免费代理IP如下图所示。
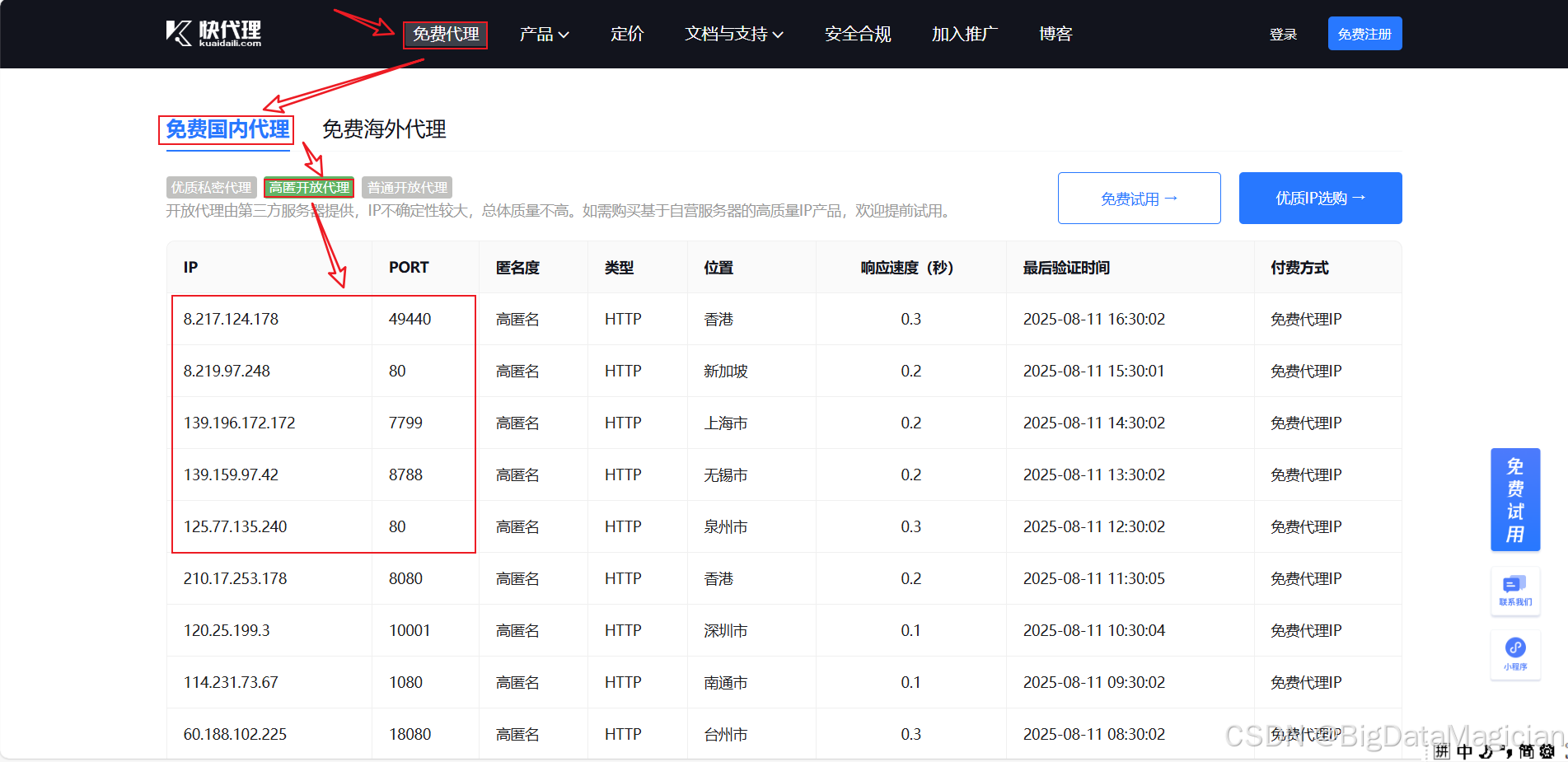
检测代理IP有效性的代码如下所示:
import requests# 定义一个代理 IP 地址列表,每个代理以字典形式存储
# 格式为 {"http": "http://IP:端口"},用于通过 HTTP 代理发送请求
# 这些代理可用于隐藏真实 IP、绕过访问限制或测试网络连通性
proxy_list = [{"http": "http://8.217.124.178:49440"},{"http": "http://8.219.97.248:80"},{"http": "http://139.196.172.172:7799"},{"http": "http://139.159.97.42:8788"},{"http": "http://125.77.135.240:80"}
]# 目标网站的基础 URL
# 此处为一个前端学习网站的首页(示例用途),用于测试代理是否能正常访问
base_url = 'http://erabbit.itheima.net/#/'# 设置请求头(Headers),模拟浏览器行为,避免被服务器识别为爬虫而拒绝访问
# User-Agent 字段表示客户端浏览器信息
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36'
}# 遍历代理列表的副本(使用 copy() 是为了避免在遍历时修改原列表导致异常)
for proxy_ip in proxy_list.copy():try:# 发送 GET 请求,使用当前代理 IP 和自定义请求头# timeout=3 表示最多等待 3 秒,超时则抛出异常response = requests.get(base_url, headers=header, proxies=proxy_ip, timeout=3)# 如果请求成功(未抛出异常),说明代理可用print(f'IP地址:{proxy_ip.get("http")}有效')except Exception as e: # 捕获所有网络相关异常(如连接超时、拒绝连接等)# 如果请求失败(如超时、无法连接等),说明该代理不可用print(f'IP地址:{proxy_ip.get("http")}无效')# 将无效的代理从原始列表中移除,确保后续不再使用proxy_list.remove(proxy_ip)
运行结果如下图所示,可以看到在这几个IP地址中,只有一个是有效的。

4.3.3 设置代理服务器
以下代码演示了如何在 Python 爬虫中使用代理服务器发送请求,通过随机选择代理 IP 的方式隐藏真实网络地址,适用于绕过访问限制、避免 IP 被封禁等场景。
import randomimport requests# 定义一个代理 IP 地址列表,每个代理以字典形式存储
# 格式为 {"http": "http://IP:端口"},用于通过 HTTP 代理发送请求
# 这些代理可用于隐藏真实 IP、绕过访问限制或测试网络连通性
proxy_list = [{"http": "http://114.231.73.67:1080", "https": "https://114.231.73.67:1080"},{"http": "http://125.77.135.240:80", "https": "https://125.77.135.240:80"},{"http": "http://171.105.22.54:9909", "https": "https://171.105.22.54:9909"},
]# 随机选择一个代理 IP
proxies = random.choice(proxy_list)# 定义目标网站的基础 URL(豆瓣图书中“小说”标签的页面)
base_url = 'https://book.douban.com/tag/小说'# 设置请求头(headers),模拟浏览器访问,避免被服务器识别为爬虫而拒绝请求
# User-Agent 表示客户端信息,这里模拟的是 Chrome 浏览器在 Windows 10 系统上的访问
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.0.0 Safari/537.36'
}# 定义 URL 的查询参数(query parameters)
# 这些参数会自动拼接到 URL 后面,形成完整的请求地址
params = {'start': 20, 'type': 'T'}# 发送 GET 请求到目标 URL
# 请求会自动将 base_url 与 params 拼接成完整地址:https://book.douban.com/tag/小说?start=20&type=T
# 同时携带 headers 中的请求头信息
response = requests.get(base_url, headers=headers, params=params, proxies=proxies)# 输出响应的状态码
# 200 表示请求成功,404 表示页面未找到,403 表示禁止访问等
print(response.status_code)# 输出最终请求的完整 URL(包含查询参数)
# 用于确认实际请求的地址是否正确
print(response.url)
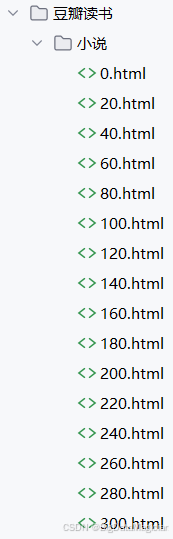
六、实战:爬取豆瓣读书中小说的网页
代码如下所示:
import random
import time
from pathlib import Pathimport requests# 基础配置
BASE_URL = 'https://book.douban.com/tag/小说' # 目标页面URL
SAVE_DIR = Path('./豆瓣读书/小说') # 保存目录
MAX_PAGES = 50 # 最大爬取页数
PAGE_SIZE = 20 # 每页条目数# 创建保存目录(如果不存在)
SAVE_DIR.mkdir(parents=True, exist_ok=True)# 请求头,模拟浏览器访问
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.0.0 Safari/537.36',
}# 循环爬取页面
for page in range(MAX_PAGES + 1):start = page * PAGE_SIZEfile_name = f'{start}.html'file_path = SAVE_DIR / file_name# 如果文件已存在,跳过当前页if file_path.exists():print(f"文件 {file_name} 已存在,跳过")continue# 构建请求参数params = {"start": start, "type": "T"}# 发送GET请求,设置10秒超时response = requests.get(url=BASE_URL, headers=headers, params=params, timeout=10)# 检查请求是否成功status_code = response.status_codeif status_code == 200:# 保存页面内容with open(file_path, 'w', encoding='utf-8') as fp:fp.write(response.text)print(f"成功保存: {file_path}")else:print(f"请求失败,状态码: {status_code}")continue# 随机延迟,避免请求过于频繁delay = random.uniform(0.1, 0.5)print(f"等待 {delay:.2f} 秒后继续...")time.sleep(delay)print("爬取任务完成")
部分打印结果如下图所示:

保存后的部分html文件如下图所示: