深度学习-卷积神经网络-VGG
卷积神经网络(CNN)在计算机视觉领域取得了显著的成果,而 VGG(Visual Geometry Group)网络作为其中的经典模型之一,凭借其简洁而优雅的结构,对深度学习的发展产生了深远的影响。
虽然AlexNet证明深层神经网络卓有成效,但它没有提供一个通用的模板来指导后续的研究人员设计新的网络。与芯片设计中工程师从放置晶体管到逻辑元件再到逻辑块的过程类似,神经网络架构的设计也逐渐变得更加抽象。研究人员开始从单个神经元的角度思考问题,发展到整个层,现在又转向块,重复层的模式。
VGG 网络由 Simonyan 和 Zisserman 在 2014 年提出,旨在探讨卷积神经网络的深度与模型性能之间的关系。它在 ImageNet 等大型数据集上取得了优异的性能,证明了增加网络深度对于提高模型准确性的重要性,推动了深度学习模型向更深、更复杂的方向发展。

1. 网络结构组成
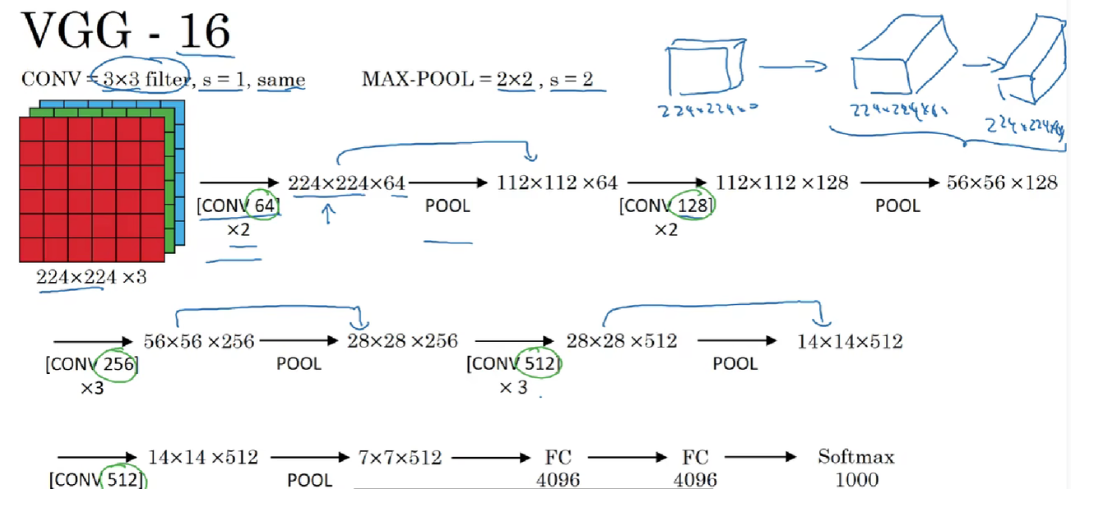
输入层 :接收 224×224×3 的彩色图像数据,与 ImageNet 数据集中常用图像的尺寸和颜色通道相匹配。
卷积层 :
VGG 网络包含多个卷积层,通常有 16 层(VGG16)或 19 层(VGG19)两种主要结构。这些卷积层使用较小的卷积核(3×3),并且在每层卷积后都使用 ReLU 激活函数。较小的卷积核可以更精细地提取特征,同时通过多层卷积的叠加能够扩大网络的感受野,捕获图像中的更大范围的特征组合。例如,在 VGG16 中,前几层卷积用于提取图像的边缘、纹理等低级特征,后续的卷积层则逐渐提取更高级的特征,如形状、物体部件等特征。
卷积层的通道数逐渐增加,例如从最初的 64 通道开始,经过多次卷积和池化操作后,通道数逐渐增加到 512 通道。通道数的增加使得模型能够提取更多的特征维度,捕捉图像中的丰富信息。
池化层 :
在卷积层之间插入池化层,通常采用最大池化,池化窗口大小为 2×2,步长为 2。池化操作的作用是降低特征图的空间分辨率,减少计算量和参数数量,同时具有一定的平移不变性,使模型对图像的微小位移具有鲁棒性。通过池化层,特征图的尺寸逐渐缩小,模型能够逐步提取更具有语义信息的特征。
全连接层 :
VGG 网络通常包含多个全连接层,例如 VGG16 包含 3 个全连接层。前两个全连接层通常包含 4096 个神经元,最后一个全连接层的神经元数量与数据集的类别数相同(如 ImageNet 的 1000 个类别)。全连接层的作用是将卷积层提取到的高级特征进行全局的组合和抽象,提取更具语义意义的特征表示,用于最终的分类任务。在最后的全连接层,使用 softmax 激活函数计算每个类别的概率分布,输出图像属于各个类别的预测概率。
2. 激活函数与训练
VGG 网络中采用了 ReLU 激活函数,它解决了传统激活函数(如 sigmoid、tanh)在深层网络训练中出现的梯度消失问题,加速了网络的训练过程。ReLU 激活函数在正区间具有恒等映射的特性,使得梯度能够更有效地反向传播,提高了模型的收敛速度。
在训练过程中,使用了随机梯度下降(SGD)优化算法,并引入了 dropout 技术来防止过拟合。Dropout 在训练时随机丢弃一部分神经元的输出,使得模型在每次迭代时只能依赖部分神经元进行学习,从而增强了模型的泛化能力。
3. 代码实现
代码改编自《动手学深度学习》
先定义VGG块:
import torch
from torch import nn
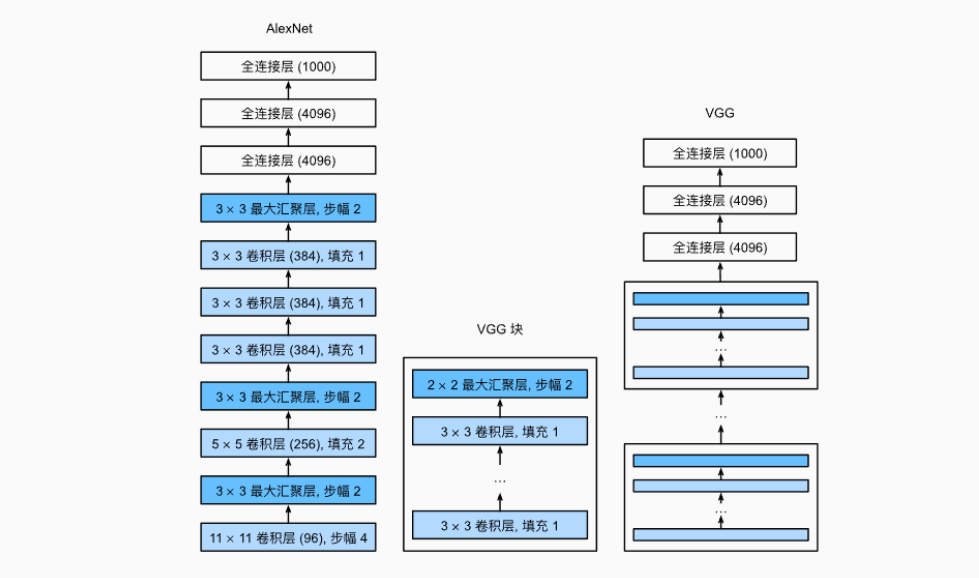
from d2l import torch as d2ldef vgg_block(num_convs, in_channels, out_channels):layers = []for _ in range(num_convs):layers.append(nn.Conv2d(in_channels, out_channels,kernel_size=3, padding=1))layers.append(nn.ReLU())in_channels = out_channelslayers.append(nn.MaxPool2d(kernel_size=2,stride=2))return nn.Sequential(*layers)原始VGG网络有5个卷积块,其中前两个块各有一个卷积层,后三个块各包含两个卷积层。
第一个模块有64个输出通道,每个后续模块将输出通道数量翻倍,直到该数字达到512。
由于该网络使用8个卷积层和3个全连接层,因此它通常被称为VGG-11。
conv_arch = ((1, 64), (1, 128), (2, 256), (2, 512), (2, 512))下面的代码实现了VGG-11。可以通过在conv_arch上执行for循环来简单实现。
def vgg(conv_arch):conv_blks = []in_channels = 1# 卷积层部分for (num_convs, out_channels) in conv_arch:conv_blks.append(vgg_block(num_convs, in_channels, out_channels))in_channels = out_channelsreturn nn.Sequential(*conv_blks, nn.Flatten(),# 全连接层部分nn.Linear(out_channels * 7 * 7, 4096), nn.ReLU(), nn.Dropout(0.5),nn.Linear(4096, 4096), nn.ReLU(), nn.Dropout(0.5),nn.Linear(4096, 10))net = vgg(conv_arch)接下来,我们将构建一个高度和宽度为224的单通道数据样本,以观察每个层输出的形状。
X = torch.randn(size=(1, 1, 224, 224))
for blk in net:X = blk(X)print(blk.__class__.__name__,'output shape:\t',X.shape)输出:
Sequential output shape: torch.Size([1, 64, 112, 112])
Sequential output shape: torch.Size([1, 128, 56, 56])
Sequential output shape: torch.Size([1, 256, 28, 28])
Sequential output shape: torch.Size([1, 512, 14, 14])
Sequential output shape: torch.Size([1, 512, 7, 7])Flatten output shape: torch.Size([1, 25088])
Linear output shape: torch.Size([1, 4096])
ReLU output shape: torch.Size([1, 4096])
Dropout output shape: torch.Size([1, 4096])Linear output shape: torch.Size([1, 4096])
ReLU output shape: torch.Size([1, 4096])
Dropout output shape: torch.Size([1, 4096])Linear output shape: torch.Size([1, 10])训练模型:
由于VGG-11比AlexNet计算量更大,因此构建了一个通道数较少的网络,足够用于训练Fashion-MNIST数据集。
ratio = 4
small_conv_arch = [(pair[0], pair[1] // ratio) for pair in conv_arch]
net = vgg(small_conv_arch)lr, num_epochs, batch_size = 0.05, 10, 128
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=224)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())输出:
loss 0.178, train acc 0.935, test acc 0.920
2463.7 examples/sec on cuda:0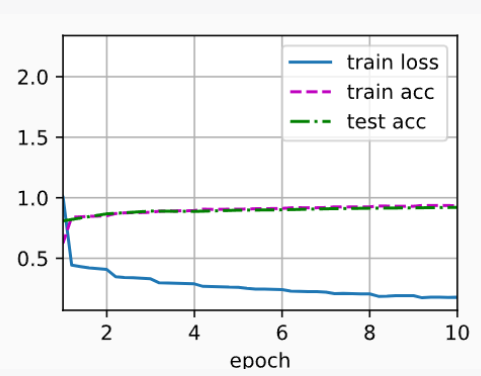
4. VGG的影响
VGG以其简单而规则的结构、对深度的探索以及强大的特征提取能力,推动了卷积神经网络在计算机视觉领域的广泛应用和发展。尽管 VGG 网络存在一些局限性,如计算量大、参数多、收敛速度较慢等问题,但它的基本思想和设计理念仍然具有重要的参考价值,为后续更先进的深度学习模型的提出和发展提供了坚实的基础和宝贵的经验。
VGG-11使用可复用的卷积块构造网络。
不同的VGG模型可通过每个块中卷积层数量和输出通道数量的差异来定义。
块的使用导致网络定义的非常简洁。使用块可以有效地设计复杂的网络。
在VGG论文中尝试了各种架构。特别是他们发现深层且窄的卷积比较浅层且宽的卷积更有效。所以选的是3×3。
在实际应用中,我们应根据具体的需求和场景,权衡 VGG 网络的优势和局限性,合理选择和优化模型,充分发挥其在图像处理等任务中的潜力,同时也不断探索和研究新的模型架构和技术,以应对不断出现的挑战和需求。