AAAI-2025 | 北理工具身导航新范式!FloNa:基于平面图引导的具身视觉导航
- 作者:Jiaxin Li1^{1}1, Weiqi Huang1^{1}1, Zan Wang1^{1}1, Wei Liang1,2^{1,2}1,2, Huijun Di1^{1}1, Feng Liu3^{3}3
- 单位:1^{1}1北京理工大学,2^{2}2北京理工大学长三角研究院,3^{3}3北京瑞科比特电子信息科技有限公司
- 论文标题:FloNa: Floor Plan Guided Embodied Visual Navigation
- 论文链接:https://ojs.aaai.org/index.php/AAAI/article/download/33601/35756
主要贡献
- 引入了Floor Plan Visual Navigation(FloNa)任务,即利用RGB图像和建筑平面图导航到目标位置,丰富了具身视觉导航的应用场景。
- 提出了FloDiff框架,这是一个基于扩散策略的端到端框架,通过显式地对智能体进行定位,高效且有效地解决了FloNa任务。
- 收集了一个包含20k导航剧集、覆盖117个场景的大规模数据集,用于训练和评估模型,并对FloDiff在不同维度的能力进行了全面分析,证明了其优越性。
研究背景
- 具身视觉导航的重要性:具身AI中的一个重要任务是使智能体能够在多种环境中朝着目标导航,目标可以是点、图像、物体或语言指令等。近年来,研究者们开始利用易于获取的先验知识来提高导航效率和准确性,建筑平面图作为一种稳定且广泛可用的先验知识,能够提供高层语义和几何信息,帮助智能体在不熟悉的环境中定位和导航。
- 现有研究的局限性:以往的研究虽然探索了将平面图用于定位和导航,但往往依赖于多传感器融合或对平面图结构施加约束,限制了其实际应用性。而本文旨在减少对传感器的依赖和对平面图结构的约束,使智能体能够仅使用RGB图像和平面图进行导航。
任务设置
- 任务定义:
- Floor Plan Visual Navigation(FloNa)任务要求智能体在3D环境中从起始位置导航到特定目标位置。智能体在导航过程中只能接收以自身为中心的RGB图像、环境的平面图图像以及目标位置(在平面图上以红点表示)。
- 智能体在每个时间步t接收观察图像ot,并产生动作at以到达目标g。如果智能体的最终位置与目标位置的距离在指定阈值τd内,且与场景碰撞的次数不超过给定阈值τc,则认为导航成功。
- 模拟器设置:
- 基于iGibson模拟器构建模拟环境,使用Locobot作为智能体。智能体的高度为0.85米,底座半径为0.18米,配备一个分辨率为512×512像素的RGB相机。
- 动作定义为ata_tat := ptp_tpt − pt−1p_{t−1}pt−1,ata_tat ∈ R2R^2R2,表示在2D平面上的连续运动。
数据集设计
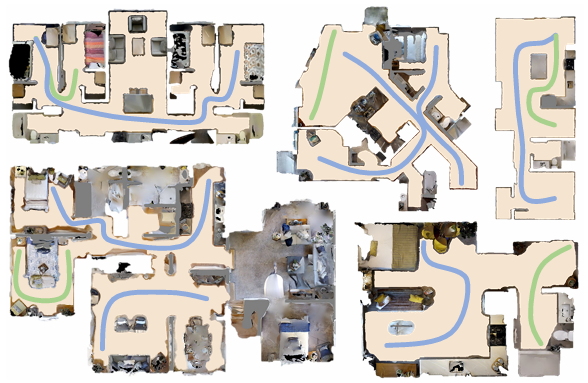
- 数据集规模:收集了20,214个导航剧集,涵盖117个静态室内场景,总共生成了3,312,480张图像,这些图像的视野角度为45度。
- 场景来源:这些Gibson场景是从家庭和办公室中重建而来的,使用Matterport设备进行扫描,保留了传感器观察到的纹理,从而最小化了从模拟到现实的差距。
- 数据集划分:将数据集划分为训练集和测试集,其中训练集包含67个场景,测试集包含50个场景。
- 平面图与可导航地图:每个场景都提供了一个平面图和一个可导航地图。平面图直接采用了Chen等人(2024年)手动标注的平面图。可导航地图是通过粗到细的方法获得的,首先从场景的网格生成一个粗糙的可导航地图,然后手动对其进行细化,以解决扫描伪影问题。
- 剧集生成:根据场景大小,在小场景中收集150个剧集,在中等场景中收集180个剧集,在大场景中收集200个剧集。在收集每个剧集之前,随机采样两个至少相隔3米的点作为起始点和目标点。然后使用A*算法搜索从起始点到目标点的无碰撞轨迹,并记录轨迹位置以及在搜索过程中渲染的观察图像。剧集轨迹长度范围从4.53米到42.03米。
预备知识
扩散模型
扩散模型是一种用于生成任务的概率框架,通过迭代去噪过程,从采样的高斯噪声中逐渐生成所需数据。从采样的噪声xK开始,模型执行K次去噪迭代,生成一系列中间姿态xK−1,...,x0x^{K−1}, ..., x^0xK−1,...,x0。去噪过程可以表示为:
xk−1=α(xk−γϵθ(xk,k)+σz),
x^{k-1}=\alpha\big(x^{k}-\gamma\epsilon_{\theta}(x^{k},k)+\sigma z\big),
xk−1=α(xk−γϵθ(xk,k)+σz),
其中α、γ、σ是噪声调度函数,ϵθ\epsilon_{\theta}ϵθ是具有参数θ\thetaθ的噪声预测网络,z服从标准正态分布。
扩散策略
扩散策略将扩散模型的概念扩展到策略学习中,允许智能体基于学习到的概率分布做出决策。策略通常包含一个编码器,用于将观察结果转换为低维特征,作为去噪过程的条件。公式可以改写为:
Atk−1=α(Atk−γεθ(Atk,Ot,k)+σz),
\mathcal{A}_{t}^{k-1}=\alpha(\mathcal{A}_{t}^{k}-\gamma\varepsilon_{\theta}(\mathcal{A}_{t}^{k},\mathcal{O}_{t},k)+\sigma z),
Atk−1=α(Atk−γεθ(Atk,Ot,k)+σz),
其中At\mathcal{A}_{t}At和Ot\mathcal{O}_{t}Ot分别表示每个时间步t的动作和观察结果。
方法
框架概述
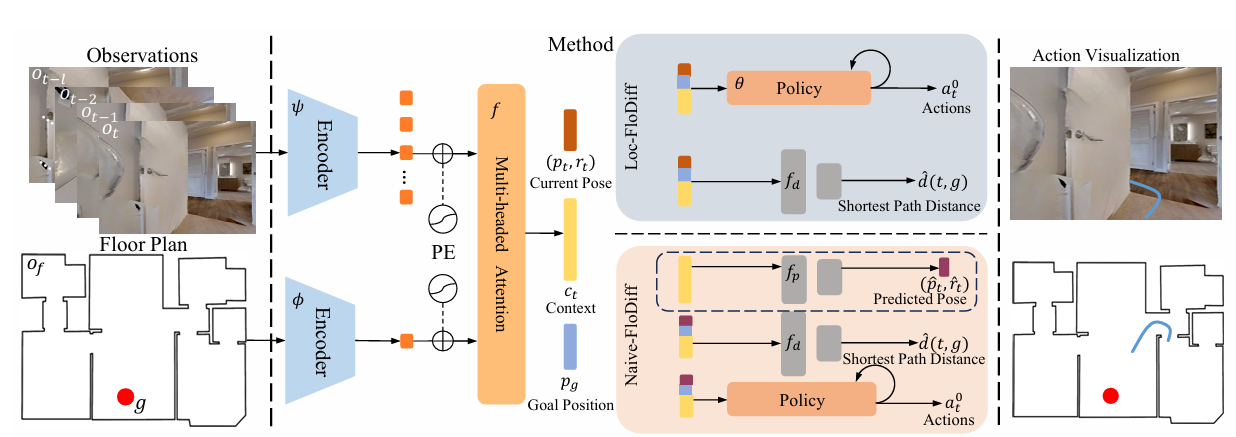
FloDiff框架包括一个基于Transformer的骨干网络,用于融合视觉观察和平面图,以及一个策略网络,用于在场景内导航。理想智能体需要具备两个能力:
- 在不与场景碰撞的情况下导航到目标;
- 将视觉观察与平面图对齐。
为了应对第一个挑战,采用强大的扩散策略从大量演示中学习在拥挤场景中的导航。
对于第二个挑战,显式地从观察中预测智能体姿态,或者使用预训练模型进行姿态预测。
观察上下文
视觉观察OtO_tOt包含观察到的图像{ot−l,ot−l+1,...,ot}\{o_{t−l}, o_{t−l+1}, ..., o_t\}{ot−l,ot−l+1,...,ot},其中l表示上下文长度,以及平面图图像。使用Transformer骨干网络处理观察上下文。
- 对于每个观察图像oio_ioi,使用共享的EfficientNet-B0作为编码器ψ,独立地产生视觉潜在特征。
- 然后使用另一个EfficientNet-B0作为编码器φ处理平面图图像。通过多头注意力层f(·)融合两个分支的特征,最终输出特征作为观察上下文向量ctc_tct。
目标位置
根据平面图上标记的目标点g,在世界坐标中计算目标位置pgp_gpg。首先确定目标在平面图图像上的像素坐标ugu_gug,然后使用平面图分辨率μ(定义为每像素的距离)和偏移量δ(由Chen等人(2024年)提供),通过pg=μ⋅ug+δp_{g}=\mu\cdot u_{g}+\deltapg=μ⋅ug+δ将其转换为世界坐标。
策略
根据获取当前智能体姿态的不同方式,提出了FloDiff的两个变体。
- 第一个变体是Naive-FloDiff,它从观察上下文向量ct中学习预测智能体姿态x^t=(p^t,r^t)\hat{x}_{t}=(\hat{p}_{t},\hat{r}_{t})x^t=(p^t,r^t)。
- 第二个变体是Loc-FloDiff,它直接使用真实姿态或预训练模型(如F3F^3F3Loc)的预测姿态。
对于所有FloDiff变体,将时间步t的预测动作序列A0t建模为具有Hp范围的未来动作序列,智能体执行前Ha步。
训练
使用包含67个室内场景的训练集训练FloDiff,这些场景包含11,575个剧集,大约26小时的轨迹数据。
-
在训练过程中,从剧集中随机采样具有固定范围的轨迹片段作为训练样本。
-
为了增加目标的多样性,还会随机选择轨迹后面的点作为目标位置,而不是使用剧集的终点作为目标。使用以下损失函数训练Naive-FloDiff:
L(ϕ,ψ,f,θ,fd,fp)=MSE(ϵk,ϵθ(ct,At0+ϵk,k))+λ1⋅MSE(d(t,g),fd(ct,x^t,pg))+λ2⋅MSE(xt,fp(ct)). \begin{aligned} \mathcal{L}(\phi,\psi,f,\theta,f_{d},f_{p})=\mathtt{MSE}(\epsilon^{k},\epsilon_{\theta}(c_{t},\mathcal{A}_{t}^{0}+\epsilon^{k},k))\\ +\lambda_{1}\cdot\mathtt{MSE}(d(t,g),f_{d}(c_{t},\hat{x}_{t},p_{g}))\\ +\lambda_{2}\cdot\mathtt{MSE}(x_{t},f_{p}(c_{t})). \end{aligned} L(ϕ,ψ,f,θ,fd,fp)=MSE(ϵk,ϵθ(ct,At0+ϵk,k))+λ1⋅MSE(d(t,g),fd(ct,x^t,pg))+λ2⋅MSE(xt,fp(ct)).
类似地,使用以下损失函数训练Loc-FloDiff:
L(ϕ,ψ,f,θ,fd)=MSE(ϵk,ϵθ(ct,At0+ϵk,k))+λ3⋅MSE(d(t,g),fd(ct,x^t,pg)). \begin{aligned} \mathcal{L}(\phi,\psi,f,\theta,f_{d})=\mathtt{MSE}(\epsilon^{k},\epsilon_{\theta}(c_{t},\mathcal{A}_{t}^{0}+\epsilon^{k},k))\\ +\lambda_{3}\cdot\mathtt{MSE}(d(t,g),f_{d}(c_{t},\hat{x}_{t},p_{g})). \end{aligned} L(ϕ,ψ,f,θ,fd)=MSE(ϵk,ϵθ(ct,At0+ϵk,k))+λ3⋅MSE(d(t,g),fd(ct,x^t,pg)).
其中,λ1、λ2和λ3是用于加权不同损失项的超参数,MSE(⋅)\mathtt{MSE}(\cdot)MSE(⋅)计算均方误差。 -
在实现中,使用AdamW优化器训练FloDiff,固定学习率为0.0001,训练5个epoch。
-
实验中设置λ1=λ3=0.001\lambda_{1}=\lambda_{3}=0.001λ1=λ3=0.001和λ2=0.05\lambda_{2}=0.05λ2=0.05。
-
注意力层使用PyTorch的原生实现,多头注意力层和头的数量均为4。
-
观察上下文向量ctc_tct的维度设置为256。扩散策略使用Square Cosine Noise Scheduler进行训练,K=10步去噪。
-
噪声预测网络ϵθ\epsilon_{\theta}ϵθ采用条件U-Net架构,包含15层卷积。扩散范围设置为Hp=32H_{p}=32Hp=32,并在每次迭代中执行前Ha=16H_{a}=16Ha=16步。
-
在一台配备NVIDIA RTX 3090 GPU的机器上训练FloDiff,批量大小为256。
实验
实验设置
- 测试场景:在50个测试室内场景中评估所提出的方法,每个场景随机选择10对起始点和终点,总共500个测试对。
- 碰撞处理策略:由于平面图没有考虑家具障碍,可能会发生碰撞。当发生碰撞时,智能体会顺时针旋转45度并重新预测未来的动作。
- 基线方法:
- Loc-A*(F3)(F^3)(F3):使用预训练的F3F^3F3Loc进行定位,然后使用A*算法在平面图上规划轨迹并执行动作。
- **Loc-A*$∗∗(GT):与Loc−A∗**(GT):与Loc-A*∗∗(GT):与Loc−A∗F^3$类似,但使用真实姿态代替预测姿态。
- Naive-FloDiff:直接在策略训练过程中学习预测智能体姿态。
- Loc-FloDiffF3F^3F3:基于Loc-FloDiff模型,使用与Loc-A*F3F^3F3相同的定位模块。
- Loc-FloDiff(GT)(GT)(GT):与Loc-FloDiff F3F^3F3类似,但使用真实姿态代替预测姿态。
- 评估指标:
- Success Rate (SR):成功完成任务的测试集比例。
- Success Weighted by Path Length (SPL):考虑路径长度的效率指标,计算公式为:
SPL=1N∑i=1NSi⋅limax(pi,li) \text{SPL} = \frac{1}{N} \sum_{i=1}^{N} S_i \cdot \frac{l_i}{\max(p_i, l_i)} SPL=N1i=1∑NSi⋅max(pi,li)li
其中,pip_ipi是智能体的路径长度,lil_ili是最短路径长度。
结果与讨论
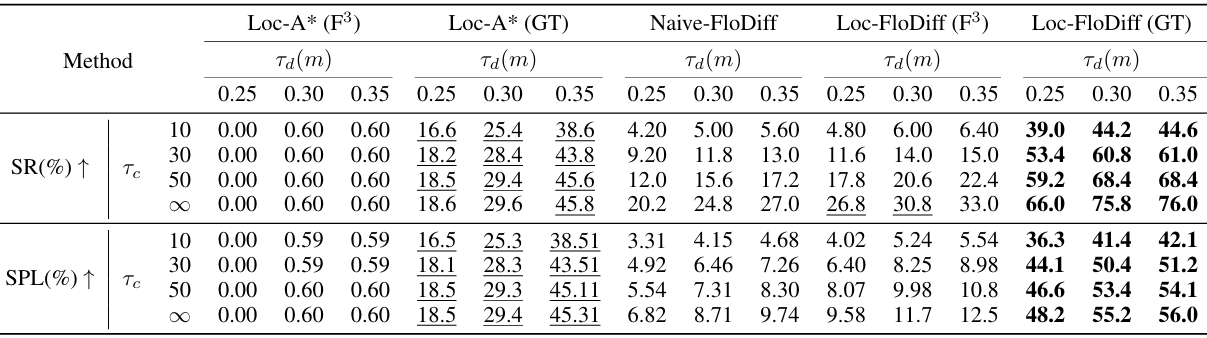
- 主要结果:
- Loc-FloDiff(GT)(GT)(GT) 在所有条件下均优于其他方法,表明所提出的扩散策略框架能够有效解决FloNa任务。
- Loc-FloDiffF3F^3F3 在定位不准确的情况下,仍然表现出一定的鲁棒性,优于Loc-A*F3F^3F3。
- Naive-FloDiff 在端到端学习中表现不如模块化方法(如Loc-FloDiff),这表明同时处理定位和规划的编码器面临挑战。
- 定位分析:
- Loc-A*F3F^3F3和Loc-FloDiff F3F^3F3的性能低于其真实姿态版本,主要是由于F3F^3F3Loc的定位不准确导致路径规划不合理。
- 即使在定位不准确的情况下,Loc-FloDiff F3F^3F3的性能下降幅度小于Loc-A*F3F^3F3,表明Loc-FloDiff对噪声输入具有一定的鲁棒性。
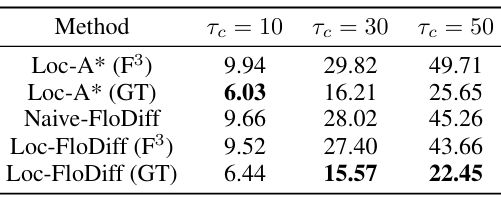
- 碰撞避免:
- Loc-FloDiff (GT)(GT)(GT)和Loc-FloDiff F3F^3F3的碰撞次数均少于Loc-A*(GT)(GT)(GT)和Loc-A*F3F^3F3,表明Loc-FloDiff在导航过程中具有更好的碰撞避免能力。
- 在带有噪声的定位输入下,Loc-FloDiff能够生成无碰撞路径,而Loc-A*则经常预测出碰撞路径。
- 规划能力:
- Loc-FloDiff (GT)(GT)(GT)在不同目标位置下能够成功规划出不同的路径,表明其规划能力的有效性。

- 鲁棒性:
- 即使在输入姿态带有噪声的情况下,Loc-FloDiff (GT)(GT)(GT)的性能也不会随着噪声方差的增加而持续下降,表明其对定位不确定性具有较强的鲁棒性。
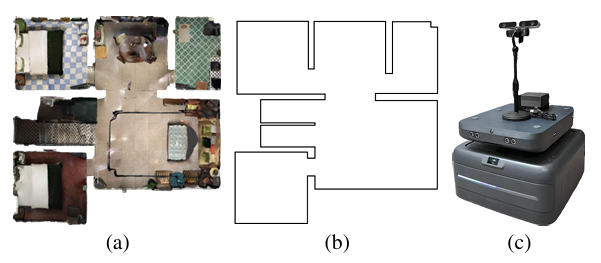
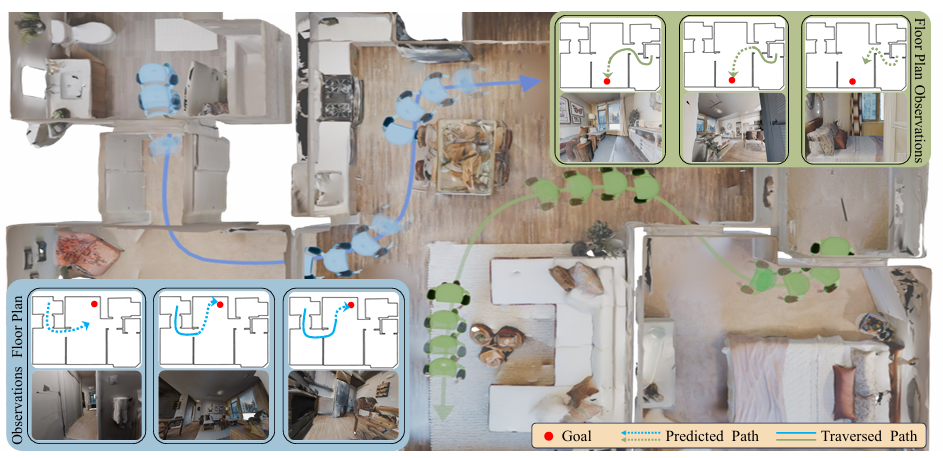
- 真实世界部署:
- 在一个未见过的真实世界公寓中部署Loc-FloDiff (GT)(GT)(GT),即使没有进行微调,智能体也能成功完成导航任务,证明了模型的鲁棒性和泛化能力。
结论与未来工作
- 结论:
- 本文首次将建筑平面图引入具身视觉导航,开发了FloDiff框架,并构建了相应的数据集。
- FloDiff在性能上优于基线方法,展示了该方法在处理FloNa任务时的潜力。通过提出这一实用的设置和解决方案,旨在激发视觉导航领域的进一步研究。
- 未来工作:
- 未来可以探索如何进一步提高模型在真实世界环境中的性能,例如通过改进定位模块或增加对动态障碍物的处理能力。
- 此外,还可以研究如何将其他模态的信息(如声音)与平面图和视觉信息相结合,以进一步提高导航的效率和准确性。
