蓝桥杯算法之搜索章 - 4
亲爱的读者朋友们,大家好啊!不同的时间,相同的地点,今天又带来了关于搜索部分的讲解。接下来我将接着我前面文章的内容,开始讲解以下记忆化搜索的部分了。
let's go!
文章目录
- 前言
- 一、pandas是什么?
- 二、使用步骤
- 1.引入库
- 2.读入数据
- 总结
前言
前面我们讲解了剪枝的内容,我们接着它,继续剪枝。
记忆化搜索就是我们剪枝的一大部分,我们接下来就学习我们的记忆化搜索吧!
一、记忆化搜索
记忆化搜索也是一种剪枝的策略
通过⼀个"备忘录",记录第⼀次搜索到的结果,当下⼀次搜索到这个状态时,直接在"备忘录"⾥⾯找结果。
我们接下来就看看这部分的题目,在题目中来理解记忆化搜索吧
二、题目概略
509. 斐波那契数 - 力扣(LeetCode)
P1464 Function - 洛谷
P5635 【CSGRound1】天下第一 - 洛谷
P1434 [SHOI2002] 滑雪 - 洛谷
三、斐波拉契数


我们看完题目后,会发现很简单,一个简单的递归就可以解决了,所以我们很快就可以写出这道题:
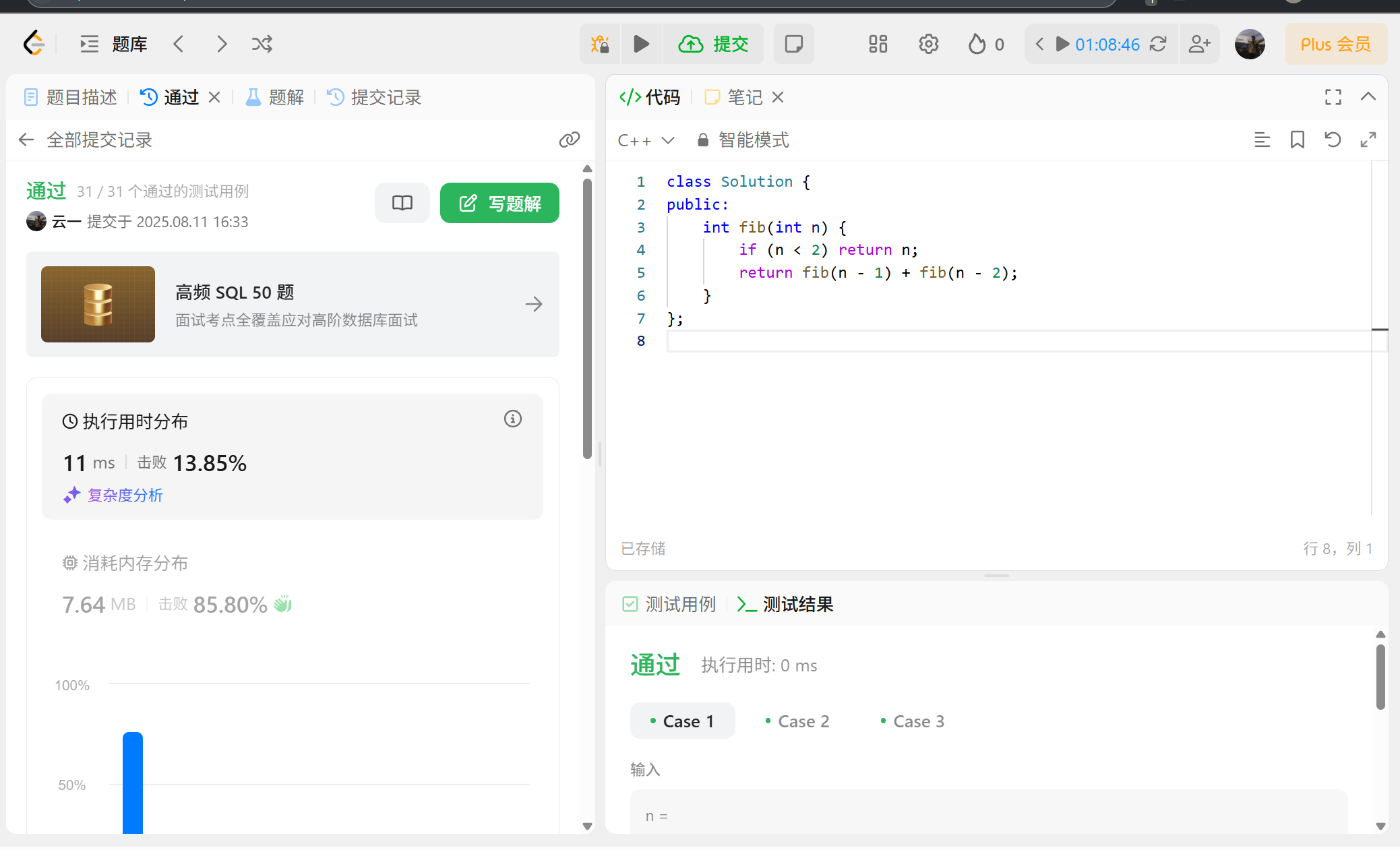
但是?我们执行时间怎么这么多?
如果卡时间我们不就过不了了吗,所以该怎么办?
我们画一下对应的决策树:
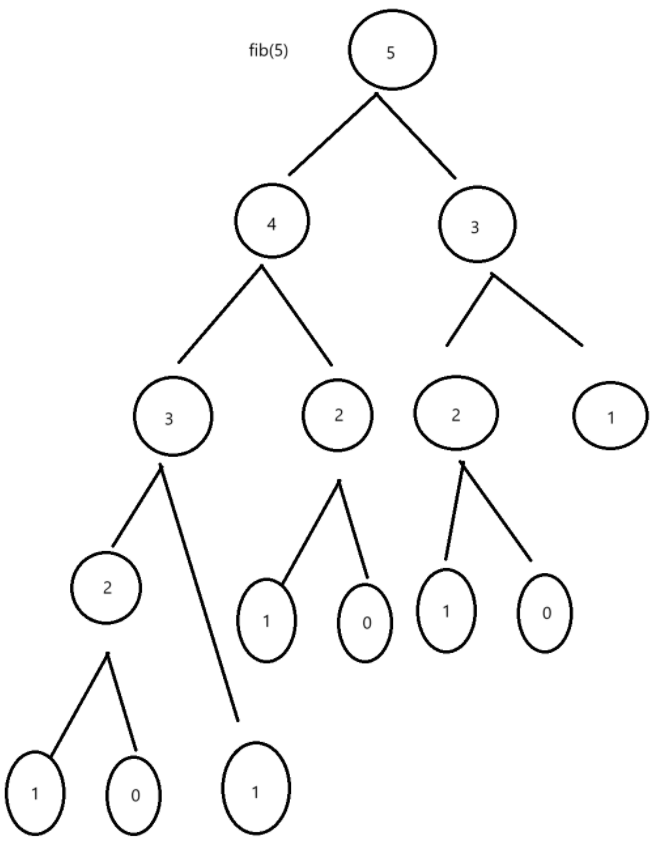
我们发现在递归的过程中,会出现很多重复的展开,我们就需要去将这些重复的内容全部去掉才对。这时候我们记忆化搜索就可以来帮助我们了
我们可以将对应的递归结果存下来,如果再次需要去递归这个数,那么我们判断一下,直接拿对应的值即可
可以看一下它的数据范围是小于等于30,所以我们创建一个35大小的数组即可:
int f[35];//备忘录,存放对应下标i的斐波拉契值

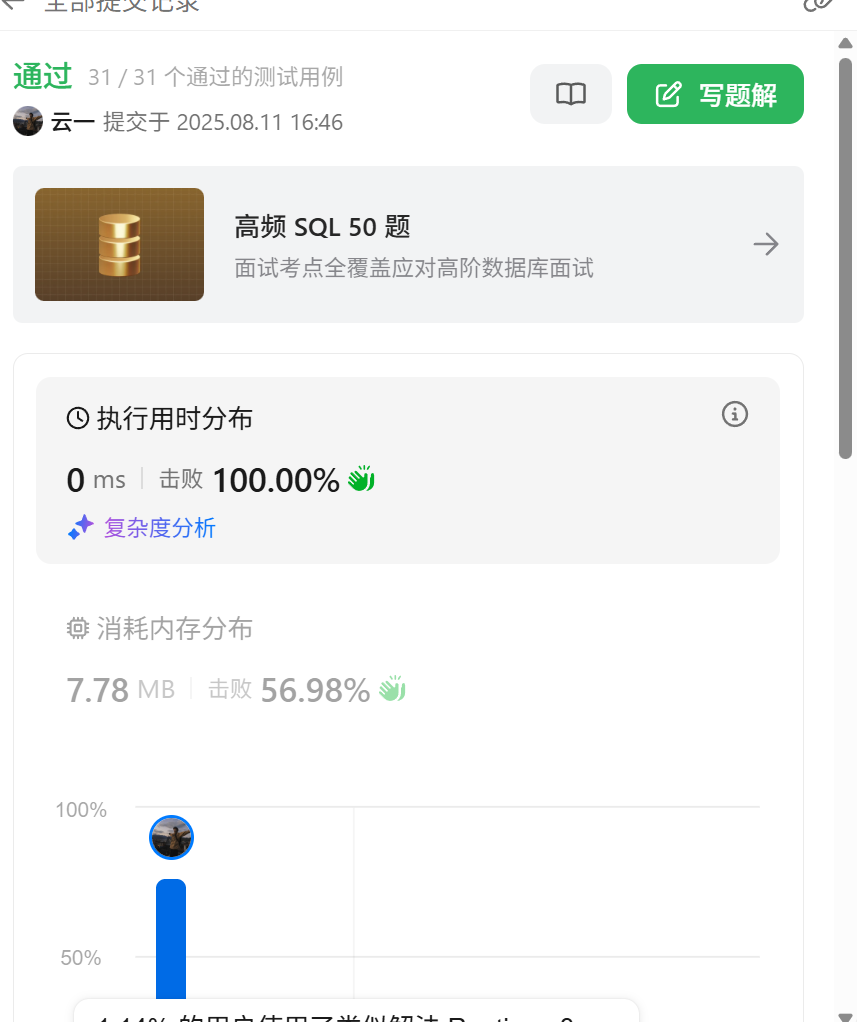
这样,我们就大幅度的降低了我们的时间消耗。记忆化搜索就帮我们剪掉对应的那些重复枝丫。
四、Function

首先,先理解一下这个题目:
我们无非就是要设计一个递归函数,从之前的学习后,写一个递归函数难度肯定不大。
但是题目后面又说,如果出现如w(15, 15, 15)的时候会出现很多的调用,这个时候我们就得需要记忆化搜索来记录它的结果,剪掉多余的枝丫。
我们来实现一下最简单的版本:
#include <iostream>
using namespace std;
typedef long long LL;
LL a, b, c;
LL dfs(LL a, LL b, LL c)
{if (a <= 0 || b <= 0 || c <= 0) return 1;if (a > 20 || b > 20 || c > 20) return dfs(20, 20, 20);if (a < b && b < c){return dfs(a, b, c - 1) + dfs(a, b - 1, c - 1) - dfs(a, b - 1, c);}else {return dfs(a - 1, b, c) + dfs(a - 1, b - 1, c) + dfs(a - 1, b, c - 1) - dfs(a - 1, b - 1, c - 1);}
}
int main()
{while(cin >> a >> b >> c){if (a == -1 && b == - 1 && c == -1) break;printf("w(%lld, %lld, %lld) = %lld\n", a, b, c, dfs(a, b, c));}return 0;
}这是没有记忆化搜索的版本,我们看看能不能通过呢?
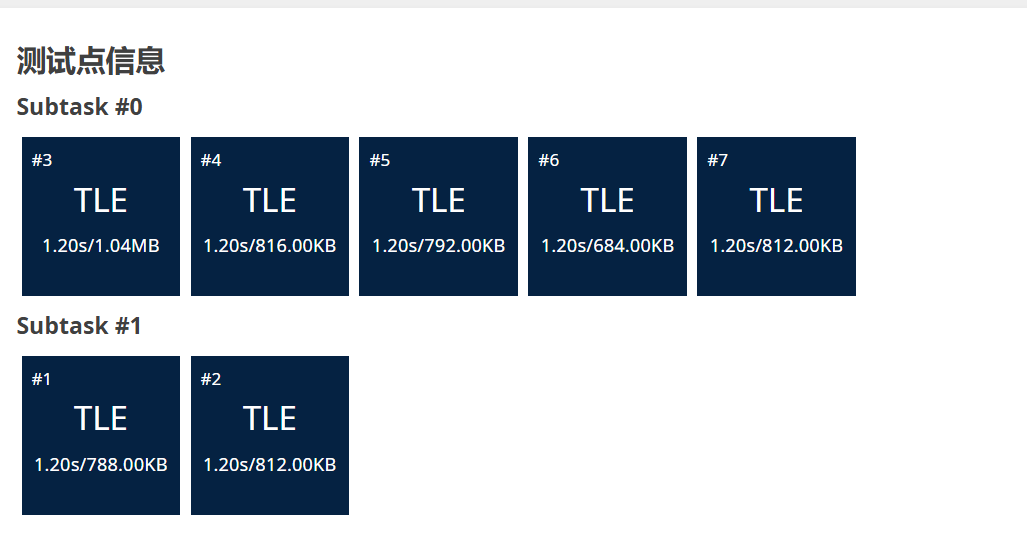
会发现全部都超时了,所以我们的记忆化搜索是必须要增加上去的:
由于这里有三个数,我们要通过三个数来映射对应的值,所以我们要使用一个三维数组去映射:
#include <iostream>
using namespace std;
typedef long long LL;
const int N = 25;
LL f[N][N][N];
LL a, b, c;
LL dfs(LL a, LL b, LL c)
{if (a <= 0 || b <= 0 || c <= 0) return 1;if (a > 20 || b > 20 || c > 20) return dfs(20, 20, 20);if (f[a][b][c]) return f[a][b][c];//查找备忘录 if (a < b && b < c){return f[a][b][c] = dfs(a, b, c - 1) + dfs(a, b - 1, c - 1) - dfs(a, b - 1, c);}else {return f[a][b][c] = dfs(a - 1, b, c) + dfs(a - 1, b - 1, c) + dfs(a - 1, b, c - 1) - dfs(a - 1, b - 1, c - 1);}
}
int main()
{while(cin >> a >> b >> c){if (a == -1 && b == - 1 && c == -1) break;printf("w(%lld, %lld, %lld) = %lld\n", a, b, c, dfs(a, b, c));}return 0;
}
我们这样就通过了!
可能会有读者问,为什么多组测试数据不清理数组呢?
那是因为我们后面也会用到这个备忘录,并不需要清理
五、天下第一

讲这道题的时候我需要先讲一下取模运算的一些内容
对于取模的加法和乘法的性质:
(a + b + c) % p = (a % p + b % p + c % p) % p
(a * b * c) % p = (a % p * b % p * c % p) % p
在加法和乘法中,括号里面那一坨可以随便加%p,并不会影响结果
那么现在再来理解一下这道题吧:
我们会有一个x和一个y进行不停的执行取模,谁先到0,谁就赢
都不能到0,就平局
题目很简单,只需要通过递归去解决这个相同子问题即可:
还有就是每次x和y都会更新x = (x + y) % p, y = ((x + y) % p + y) % p = (x + y + y) % p
在不停的模中,就会出现重复的情况,我们就需要记录下对应的结果
#include <iostream>
using namespace std;
const int N = 1e4 + 10;
char f[N][N];
int T, p;
char dfs(int x, int y)
{if (f[x][y]) return f[x][y];f[x][y] = '3';if (x == 0) return f[x][y] = '1';else if (y == 0) return f[x][y] = '2';return f[x][y] = dfs((x + y) % p, (x + y + y) % p);
}
int main()
{cin >> T >> p;while(T--){int x, y;cin >> x >> y;char ret = dfs(x, y);if (ret == '1') cout << 1 << endl;else if (ret == '2') cout << 2 << endl;else cout << "error" << endl;}return 0;
}我们由于有x和y,就采用一个二维数组来映射即可
因为有三种结果,我们就不能直接使用bool数组来标记了,我们可以使用int或者char去记录
但是int没必要,有些浪费空间了,我们直接使用char数组去记录即可。
我们一旦进入函数就要给它先打上平局的'3'才行,如果x或者y成了0,就修改为对应的1或者2
如果没有最后返回的便是平局
六、滑雪

这道题跟前面几道题的难度就不一样了
我们最简单的方法就是枚举i,j
从(i, j)位置向四个方向去走,将最长的路径找出来
dfs(i, j)返回这个点能滑的最远距离
那么怎么让这个往四个方向去走呢,看过前面章节内容的读者就知道这时候我们就需要方向数组:dx[]和dy[]去更新我们的x和y了
我们先将最简单代码来写一下:
#include <iostream>
using namespace std;
const int N = 110;
int a[N][N];
int r, c;
int dx[] = {1, -1, 0, 0};
int dy[] = {0, 0, 1, -1};
int dfs(int i, int j)
{int len = 1;for (int k = 0; k < 4; k++){int x = i + dx[k];int y = j + dy[k];if (x >= 1 && x <= r && y >= 1 && y <= c&& a[x][y] < a[i][j]){len = max(len, dfs(x, y) + 1);}}return len;
}int main()
{cin >> r >> c;for (int i = 1; i <= r; i++){for (int j = 1; j <= c; j++){cin >> a[i][j];}}int ret = 1;for (int i = 1; i <= r; i++){for (int j = 1; j <= c; j++){ret = max(ret, dfs(i, j));}}cout << ret << endl;return 0;
}
我们会发现还是有个例子超时了,我们不加记忆化搜索还是过不了。
由于每次去遍历的时候都会遍历到很多之前走过的节点,我们去遍历的话就会浪费很多时间
我们就得想办法将每个访问过的点记忆下来,这样再访问这个点就可以直接拿到对应的值了。
#include <iostream>
using namespace std;
const int N = 110;
int a[N][N];
int r, c;
int dx[] = {1, -1, 0, 0};
int dy[] = {0, 0, 1, -1};
int f[N][N];
int dfs(int i, int j)
{if(f[i][j]) return f[i][j];int len = 1;for (int k = 0; k < 4; k++){int x = i + dx[k];int y = j + dy[k];if (x >= 1 && x <= r && y >= 1 && y <= c&& a[x][y] < a[i][j]){len = max(len, dfs(x, y) + 1);}}return f[i][j] = len;
}int main()
{cin >> r >> c;for (int i = 1; i <= r; i++){for (int j = 1; j <= c; j++){cin >> a[i][j];}}int ret = 1;for (int i = 1; i <= r; i++){for (int j = 1; j <= c; j++){ret = max(ret, dfs(i, j));}}cout << ret << endl;return 0;
}

我们发现这道题难度不大,只要通过深度搜索我们就可以很简单的将对应的代码写出来。
通过添加映射的备忘录将值记录即可。
但是要注意的是,一定是要出现大量的相同的情况,我们才去使用备忘录,记忆化搜索。
如上这样会访问到很多相同节点一般。
我们就要去使用记忆化搜索剪枝
总结
亲爱的读者朋友们,这篇文章希望大家能够看完前面的文章再来读,这样的话会更加得心应手。
希望大家多多点赞 + 收藏 + 关注!