爬虫和数据分析相结合的案例
爬虫主要作用是爬取网站,可是当我们要数据分析时,爬取的网站有空值和异常值时怎么办呢?我们就需要用matplotlib库和seaborn库来分析,用pandas 和 numpy 将爬取的网站转换成数组或者字典的格式来输出图像,方便我们分析。
一.回顾爬取
这里以中国好大学为例:
爬取:
import requests
from bs4 import BeautifulSoup
import csvdef get_html(url, time=3): try:r = requests.get(url, timeout=time) r.encoding = r.apparent_encoding r.raise_for_status() return r.text except Exception as error:print(error)def parser(html): soup = BeautifulSoup(html, "lxml") out_list = [] for row in soup.select("table>tbody>tr"): td_html = row.select("td") row_data = [td_html[1].text.strip(), td_html[2].text.strip(), td_html[3].text.strip(), td_html[4].text.strip(), td_html[5].text.strip(), ]out_list.append(row_data) return out_listdef save_csv(item, path): with open(path, "w+", newline='', encoding="utf-8") as f: csv_write = csv.writer(f) csv_write.writerows(item) if __name__ == "__main__":url = "http://www.bspider.top/gaosan/" html = get_html(url) out_list = parser(html) save_csv(out_list, "school.csv") 运行结果:
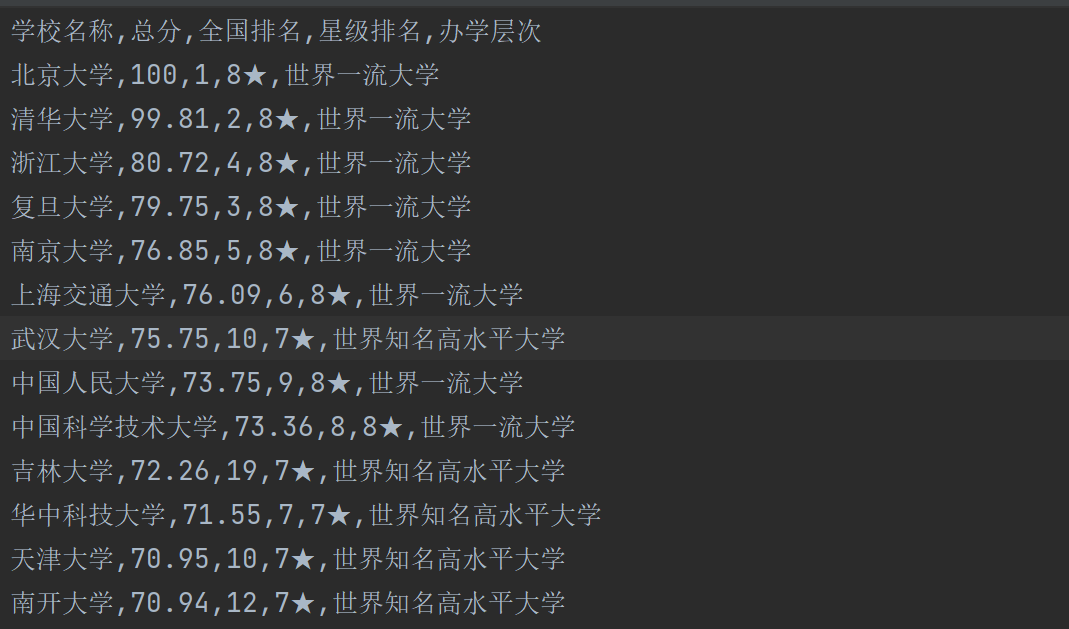
这里的结果不全,我们可以自己去运行一下这个代码,然后查看一下结果,在这里,我们也是只提取部分结果来展示!!!!
二.数据分析
以下图为例:
这里我们发现有些成绩是空值,在pandas中,我们处理空值的方法有删除行,填充和忽略。在这些的前提下我们要分辨是否有足够的理由去做这些。
1.删除
import pandas as pd# 读取 CSV 文件
df = pd.read_csv("school.csv")
# 删除含缺失值的行
new_df = df.dropna()
# 打印处理后 DataFrame 的字符串形式
print(new_df.to_string()) 导入pandas库之后,我们要读取这个csv文件,用删除函数df = pd.read_csv("school.csv") 来删除有空值的行,接下来输出。
2.填充
1.用指定内容替换空字段
import pandas as pd# 读取 CSV 文件
df = pd.read_csv("school.csv")
# 将 DataFrame 中的缺失值填充为“暂无分数信息”,inplace=True 表示直接在原 DataFrame 上修改
df.fillna("暂无分数信息", inplace=True)
# 以字符串形式打印整个 DataFrame,避免默认打印时的省略
print(df.to_string()) 同样,导入pandas库之后,读取这个csv文件,用“暂无分数信息”来填充空值,inplace=true意思为在原对象上修改,而不是创建一个新的副本。
2.用均值填充空字段
import pandas as pd# 读取 CSV 文件
df = pd.read_csv("school.csv") # 计算“总分”列的均值
x = df["总分"].mean() # 打印提示文本
print("总分的均值为")
# 打印均值
print(x) # 用均值填充“总分”列的缺失值,inplace=True 表示直接在原 DataFrame 上修改
df["总分"].fillna(x, inplace=True) # 打印处理后 DataFrame 的字符串形式,完整展示表格内容
print(df.to_string()) 基本思路与上边一致,导包,读取文件,这里的变动时我们要先求出均值,然后用均值去填充缺失值。
3.用列的中位数去填充空值
import pandas as pd# 读取 CSV 文件,构建 DataFrame
df = pd.read_csv("school.csv") # 计算“总分”列的中位数
x = df["总分"].median() # 打印中位数相关提示与结果
print("总分的中位数为")
print(x) # 用中位数填充“总分”列的缺失值,直接在原 DataFrame 上修改
df["总分"].fillna(x, inplace=True) # 打印处理后 DataFrame 的完整内容(转为字符串格式展示)
print(df.to_string()) 3.分析数据
1.柱形图用法
假设该网站一共有820所学校,其中,按照星级排名分,8星学校有8所,7星学校有16所,6星学校有36所,5星学校有59所,4星学校有103所,3星学校有190所,2星学校有148所,1星学校有260所。
这里我们可以用柱形图来表示,这样我们可以更简洁明了的图形来方便我们的分析
代码:
import matplotlib.pyplot as plt
import numpy as np# 定义 x 轴数据(星级类别)
x = np.array(["8星", "7星", "6星", "5星", "4星", "3星", "2星", "1星"])
# 定义 y 轴数据(对应星级的学校数量)
y = np.array([8, 16, 36, 59, 103, 190, 148, 260]) # 设置图表标题
plt.title("不同星级的学校个数")
# 配置字体为 SimHei,解决中文显示为方块的问题
plt.rcParams["font.sans-serif"] = ["SimHei"] # 绘制柱状图
plt.bar(x, y)
# 显示图表
plt.show() 运行结果为:
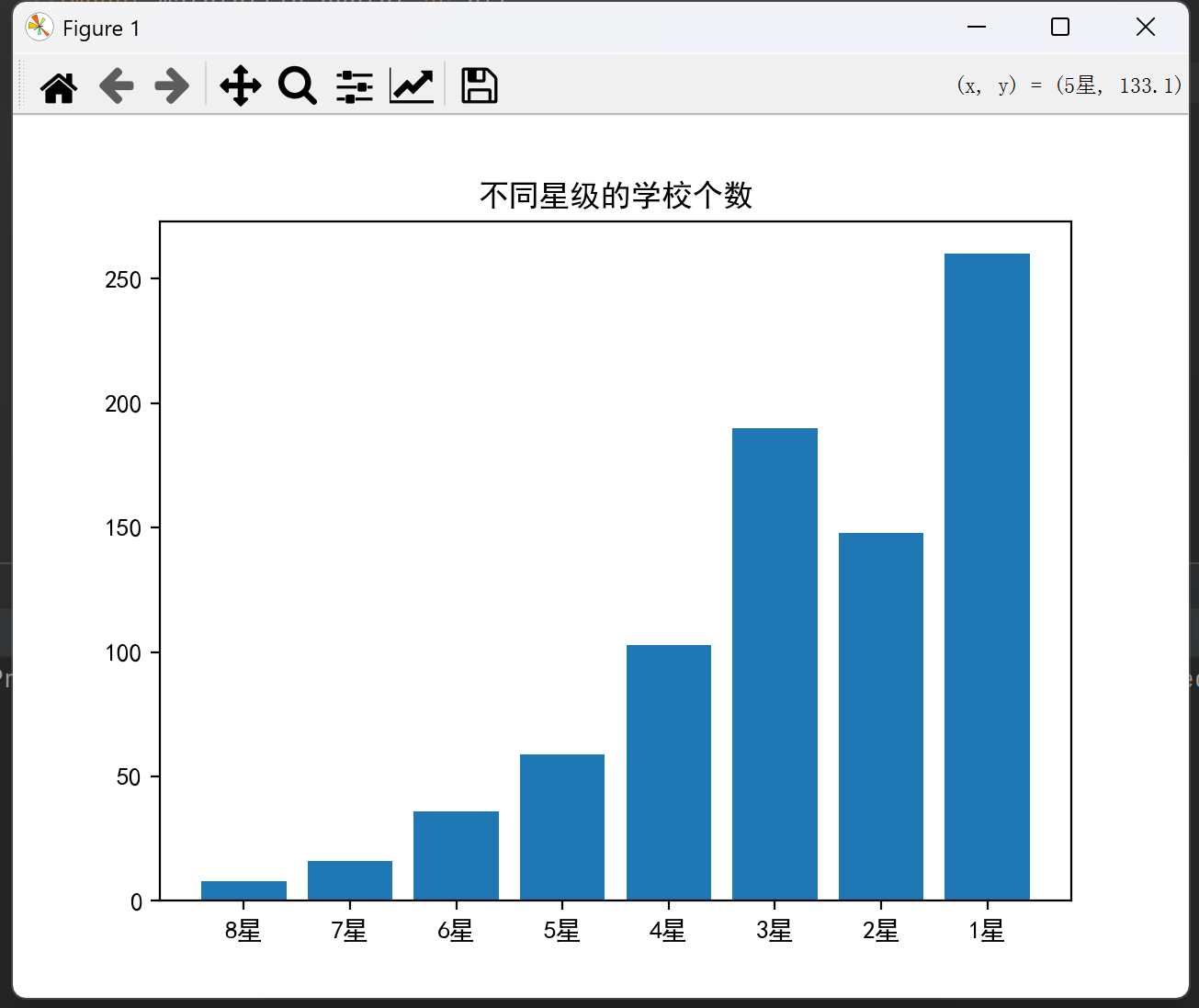
在这里我们也可以制作横向的图,制作方法就是将plt.bar(x, y) 改成plt.barh(x, y)。这样图就变成了横向的图了。
2.大饼图用法
该网站一共有820所学校,其中,按照星级排名分,8星学校约占1%,7星学校约占2%,6星学校约占4.5%,5星学校约占7.2%,4星学校约占12.5%,3星学校约占23.1%,2星学校约占18%,1星学校约占31.7%。
这里我们用饼图能更好地展示占比,所以我们选择饼图来显示这个题
代码为:
import matplotlib.pyplot as plt
import numpy as npy = np.array([1,2,4.5,7.2,12.5,23.1,18,31.7])
plt.pie(y,labels=["8星","7星","6星","5星","4星","3星","2星","1星"])
plt.title("不同星级的学校个数")
plt.rcParams["font.sans-serif"]=["SimHei"]
plt.show()运行结果为:
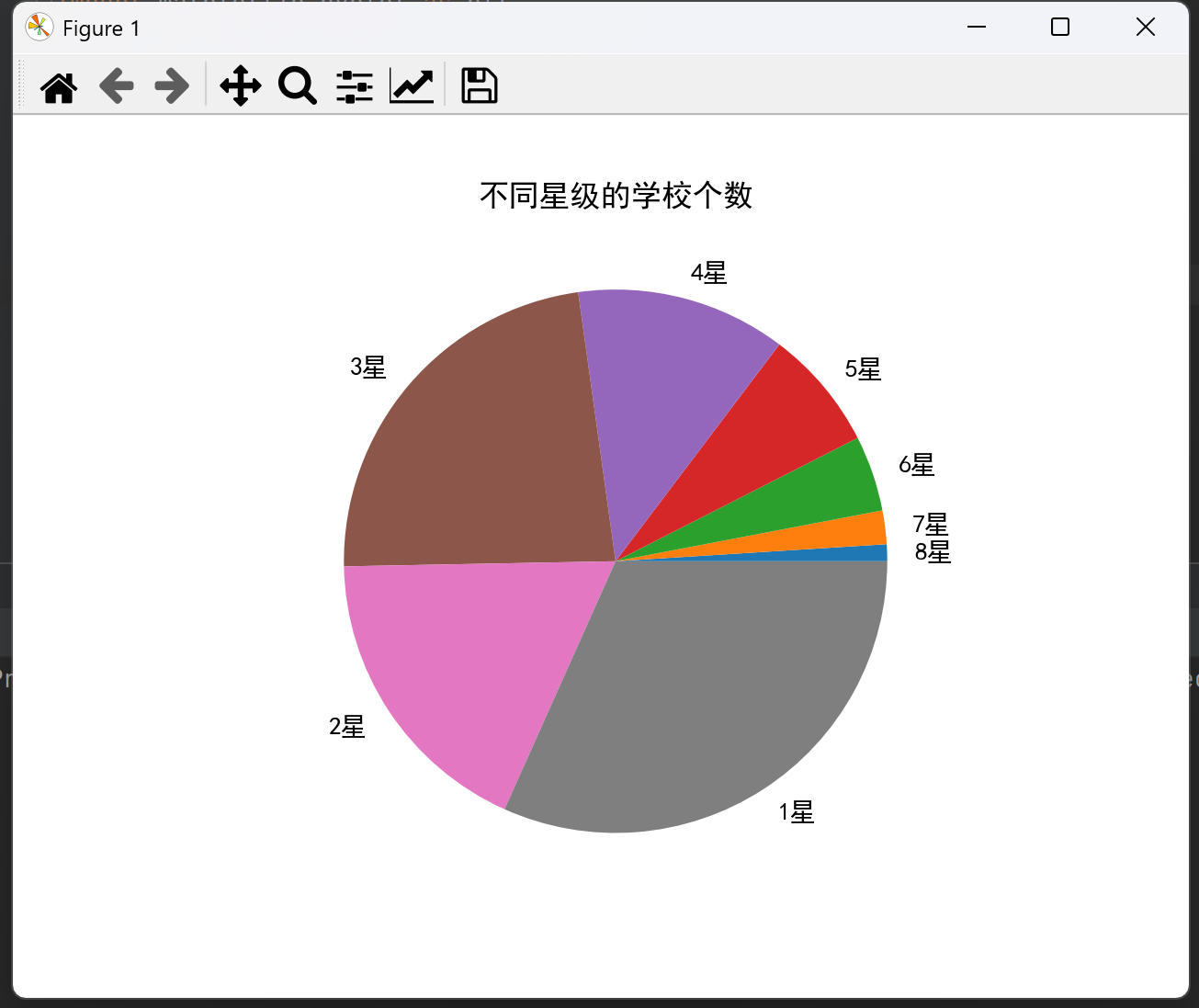
三.总结:
本案例从网页数据爬取入手,运用requests和beautifulsoup库获取并解析数据,接着使用pandas库处理缺失值,最后借助matplotlib和numpy库实现数据可视化。完整展示了数据处理流程,涵盖数据获取、清洗、分析及呈现,为数据科学相关实践提供了清晰范例,在实际应用中,可根据具体需求对代码进行优化扩展,如处理更多数据、改进可视化效果等 。