第2节 PyTorch加载数据
目录
2.1 PyTorch读取数据的两个类Dataset&Dataloader
2.2 数据集的几种组织形式
2.3 Dataset类实战
2.3.1 使用PIL中的Image类读取图片
2.3.2 控制台读取与可视化图片
2.4 昆虫图像数据集构建工具
2.1 PyTorch读取数据的两个类Dataset&Dataloader
Dataset:提供一种方式,获取其中需要的数据及其对应的真实的label值,并完成编号,主要实现两个功能:1、如何获取每一个数据及其标签。2、告诉我们一共有多少数据。
Dataloader:打包(batch_size),为后面的神经网络提供不同的数据形式。
2.2 数据集的几种组织形式
练手数据集中包含训练集和验证集。
- train里面有ants和bees数据集图片。
- train_images是一个装照片的文件夹,trains_labels是数据集标签的文件夹。
- label直接为图片的名称。
2.3 Dataset类实战
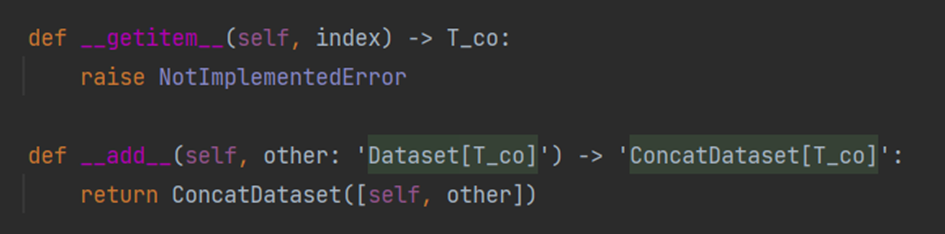
Dataset是一个抽象类,所有的数据集都需要继承这个类,所有子类都需要重写
__getitem__的方法,这个方法是获取每一个数据集及其对应的label。还可以重写
__len__方法,来获取数据集的数量。
2.3.1 使用PIL中的Image类读取图片

注:
绝对路径:绝对路径是指目录下的绝对位置,直接到达目标位置,通常是从盘符开始的路径。
例子:D:\PyTorch\Pytorch\Learn_torch\dataset\train\ants
相对路径:相对路径是指以当前文件资源所在的目录为参照基础,链接到目标文件资源(或文件夹)的路径。
例子:dataset/train/ants
(注意,路径引号前加 r 可以防止转义,或使用双斜杠)
2.3.2 控制台读取与可视化图片
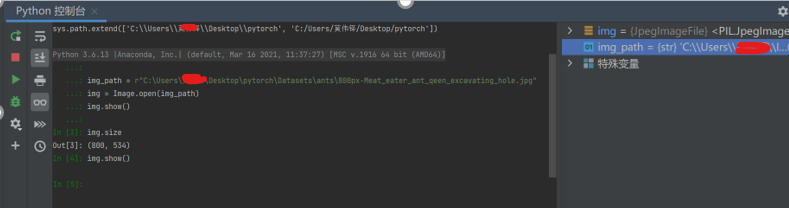
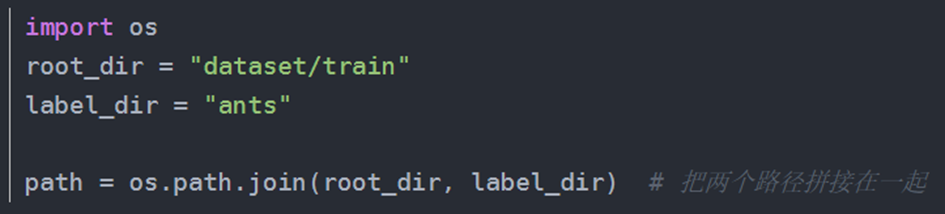
(1)、获取数据文件夹的所有图片地址
想要获取图片地址(通过索引),需要os库。
函数 os.listdir() :让文件夹下图片变成一个列表。要用idx获取图片时要先获取图片的列表。

右边属性栏显示:
(2)、拼接路径:
 2.4 昆虫图像数据集构建工具
2.4 昆虫图像数据集构建工具
该代码用于构建一个自定义的昆虫图像数据集,主要功能如下:
- 定义了一个继承自 PyTorch 的
Dataset类的MyData类,实现了从指定文件夹读取图像数据及对应标签的功能。 - 通过指定根目录和标签文件夹(分别对应蚂蚁和蜜蜂的图像),创建了蚂蚁数据集和蜜蜂数据集两个实例。
- 支持单独查看数据集中的图像(如示例中显示蚂蚁数据集的第一张图像)。
- 将蚂蚁数据集和蜜蜂数据集合并,形成完整的训练数据集,方便后续用于昆虫图像分类等深度学习任务。
# 从PyTorch的工具模块中导入Dataset类,用于创建自定义数据集
from torch.utils.data import Dataset
# 从PIL库中导入Image类,用于图像处理
from PIL import Image
# 导入os模块,用于文件路径操作
import os# 定义一个自定义数据集类MyData,继承自Dataset
class MyData(Dataset):# 类的初始化方法,用于设置数据集的基本参数def __init__(self, root_dir, label_dir):# 保存根目录路径(包含所有类别的图像文件夹)self.root_dir = root_dir# 保存当前类别的标签文件夹名称self.label_dir = label_dir# 拼接根目录和标签文件夹路径,得到当前类别图像的完整路径self.path = os.path.join(self.root_dir, self.label_dir)# 获取该路径下所有图像文件的名称列表self.img_path = os.listdir(self.path)# 重写__getitem__方法,用于根据索引获取数据集中的样本def __getitem__(self, index):# 根据索引获取图像文件的名称img_name = self.img_path[index]# 拼接得到该图像的完整路径img_item_path = os.path.join(self.root_dir, self.label_dir, img_name)# 使用PIL的Image.open方法打开图像img = Image.open(img_item_path)# 标签即为当前的标签文件夹名称label = self.label_dir# 返回图像和对应的标签return img, label# 重写__len__方法,返回数据集的样本数量def __len__(self):# 样本数量就是图像文件的数量return len(self.img_path)# 设置训练数据集的根目录
root_dir = "Datasets/train"
# 蚂蚁图像的标签文件夹名称
ants_label_dir = "ants_image"
# 蜜蜂图像的标签文件夹名称
bees_label_dir = "bees_image"# 创建蚂蚁数据集实例
ants_dataset = MyData(root_dir, ants_label_dir)
# 创建蜜蜂数据集实例
bees_dataset = MyData(root_dir, bees_label_dir)# 获取蚂蚁数据集中的第一个样本(图像和标签)
img, label = ants_dataset[0]
# 显示该图像
img.show()# 将蚂蚁数据集和蜜蜂数据集合并,形成完整的训练数据集
train_dataset = ants_dataset + bees_dataset