HyDE 在 RAG 知识问答助手中的应用解析
在大模型驱动的知识问答系统中,RAG(Retrieval-Augmented Generation)已经成为一种主流架构。它结合了“检索”(Retrieval)与“生成”(Generation),能够让模型在回答问题时引用外部知识库,从而提高准确性和可解释性。
然而,在实际使用中,RAG 也面临一个常见难题:用户的查询语句可能与知识库内容的表达方式差异很大,导致检索效果不佳。
这时,HyDE(Hypothetical Document Embeddings) 技术就派上用场了。
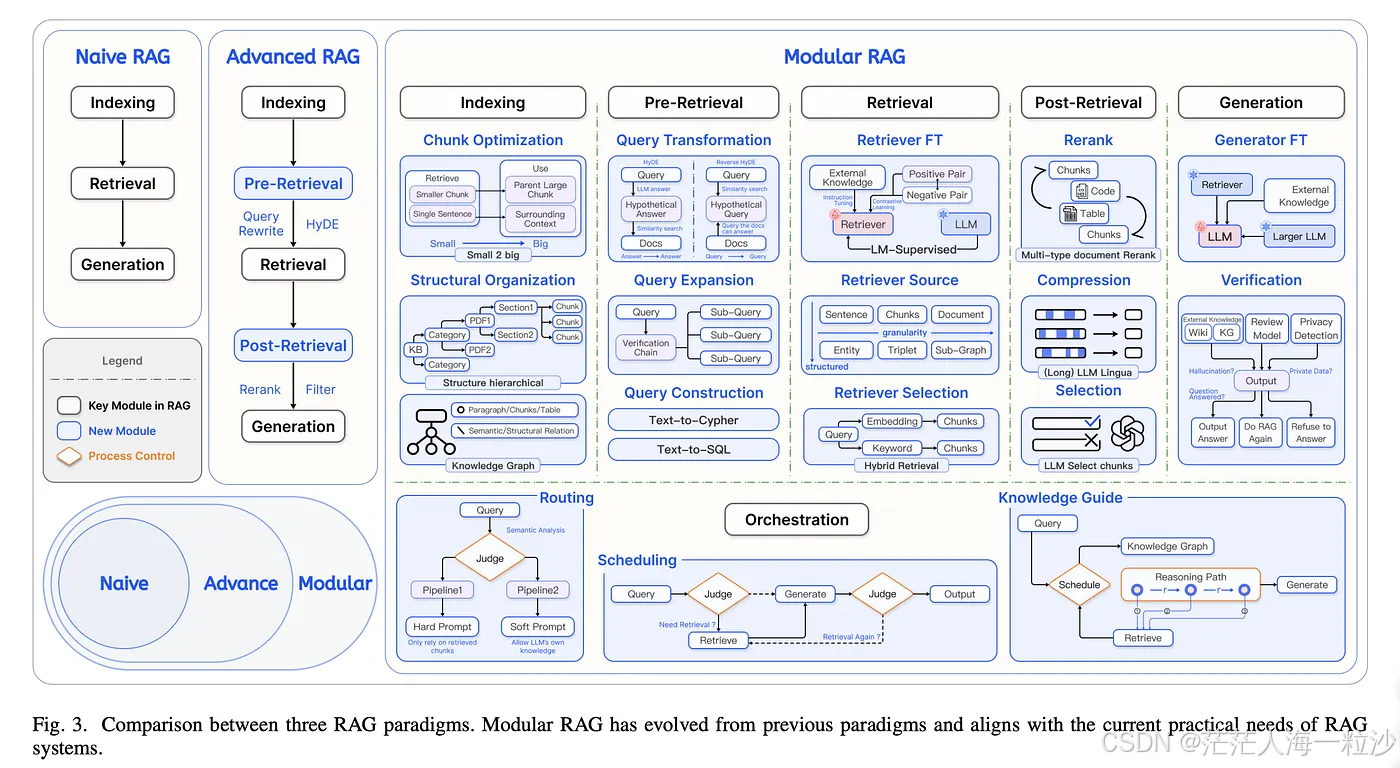
1. 什么是 HyDE?
HyDE 的全称是 Hypothetical Document Embeddings,直译为“假设文档嵌入”。它的核心思想是:
在检索之前,先用大模型根据用户的提问生成一段假设答案(即便不完全正确也没关系),再将这段假设答案向量化用于检索,而不是直接用原始问题去查。
这样做的好处是:
-
语义更丰富:假设答案往往包含了问题的核心概念、关键词和相关背景信息。
-
缩小表达差距:解决用户问题表述和知识库原文差异过大的问题。
-
提升召回率:检索到的候选文档更相关,从而提高生成回答的质量。
2. HyDE 在 RAG 中的流程
假设我们在做一个企业内部知识问答助手,流程可能是这样的:
-
用户提问
例:"我们公司的年度绩效考核流程是什么?" -
HyDE 生成假设答案
LLM 根据问题生成一个可能的答案(哪怕只是猜测):“公司的年度绩效考核流程包括:目标设定、季度评估、年终总结、绩效评级以及奖金发放。”
-
嵌入生成与检索
-
对这段假设答案进行向量化(embedding)
-
用它去向量数据库(如 Milvus、Pinecone、Weaviate)中检索最相关的文档片段
-
-
取回相关内容并生成最终答案
将检索到的真实文档作为上下文交给 LLM,由模型综合这些信息生成准确、可引用的回答。
3. 为什么 HyDE 有用?
普通 RAG 流程里,检索是基于问题本身的向量表示。如果问题短且含糊,比如“绩效考核流程”,向量化后可能缺乏足够的上下文,导致检索不准确。
HyDE 通过先“脑补”出一个假设答案,让检索向量更加信息密集。例如:
-
原始问题向量可能只含有 “绩效”、“考核”、“流程” 这样的关键词
-
HyDE 生成的假设答案向量则可能包含“目标设定”、“季度评估”、“年终总结”等额外信息,更容易匹配知识库中的实际文档
4. 适用场景
HyDE 特别适合:
-
企业内部知识库问答:文档内容专业化,用户提问方式多样
-
医疗、法律等专业领域:术语表达差异大
-
多语言检索:HyDE 可以在生成假设答案时自动翻译或补全相关词汇
-
用户问题含糊或缺少上下文:HyDE 的“补全”特性可以有效弥补
5. 注意事项
-
假设答案不需要绝对正确,它的作用是丰富语义,而不是直接呈现给用户
-
HyDE 会增加一次 LLM 调用,意味着成本和延迟略有上升
-
检索效果依赖于向量数据库的质量和嵌入模型的表现
-
在高实时性需求场景(如客服即时对话)要权衡性能与精度
6. 总结
HyDE 给 RAG 知识问答助手带来的核心价值在于:
先让模型“假装知道”,再用这个假设去找真正的答案
这种“先假设、再验证”的策略,使得检索阶段更精准,生成阶段更可靠,特别适合那些知识库复杂、用户提问多变的应用场景。
如果你正在构建一个基于 RAG 的问答系统,不妨尝试引入 HyDE,相信它会让你的助手“更聪明、更靠谱”。
参考
Modular RAG: Transforming RAG Systems into LEGO-like Reconfigurable Frameworks
HyDE Query Transform - LlamaIndex