问津集 #4:The Five-Minute Rule for the Cloud: Caching in Analytics Systems
引言
CIDR2025的这篇文章对云环境中使用缓存的成本效益进行了建模,主要是为了找到对象缓存和对象存储之间break-even point。
近40年来,Gray和Putzolu的The Five-Minute Rule指引开发人员找到了内存缓存与直接本地存储访问之间的break-even point,这篇文章认为分离式云数据库系统设计中,对象缓存和存储也需要类似的经验法则。
本来想详细的看下前面几年的文章,但是发现熟悉的大佬[1]已经完成了类似的工作了,那我只需要聚焦在这篇文章就好。
Motivation
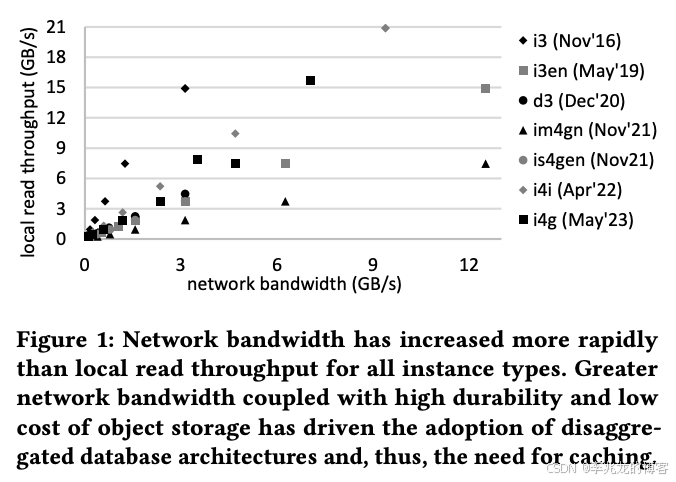
可以说,通过网络访问对象存储比直接连接存储设备会产生更高的延迟和更低的带宽,因此对象存储在存储层级中处于较低位置。
但是云存储和网络技术的进步显著影响了cost-effectiveness, latency variability 和 dynamic workload optimization,,对这些传统假设提出了挑战。
上图比较了AWS上“存储优化型”EC2实例的本地存储读取带宽(Y轴)和S3读取带宽(X轴)。
- im4gn实例的S3读取带宽高于本地读取带宽。
- 其他实例类型,如i3en和is4gen,提供的本地读取带宽略高于S3带宽,但差距很小,并且随着时间推移在缩小。
- 在非存储优化型实例中,网络带宽通常超过本地存储读取带宽,写入本地存储设备的速度往往是读取速度的一半,而写入S3的速度可以达到网络带宽。
这些观察结果表明,在本地连接存储上进行缓存并不可取,但这些设备具有一些特性:
- 更低的延迟:本地连接存储避免了网络往返,并且通常比对象存储具有更可预测的尾部延迟。对延迟敏感的工作负载使用本地连接存储往往能实现更稳定的性能。
- 成本:对象存储根据请求数量收费,而配备本地连接存储的计算实例则按固定的每小时费率收费,无论读取或写入多少数据。
这其实就已经奠定了一定有一个点是把数据存储在SSD上是更有成本效益的。但是显而易见这个公式不会具有普适性,因为会受非常多的因素影响,机型,性能要求,命中率等等。
还有一点对于本地存储带宽不及S3带宽这一点我持怀疑态度,我们内部可以拿到物理机,盘的性能是很高的,而且高密机型可以挂很多盘,本地带宽不及网络带宽这点也很看机型。
Cache Architectures
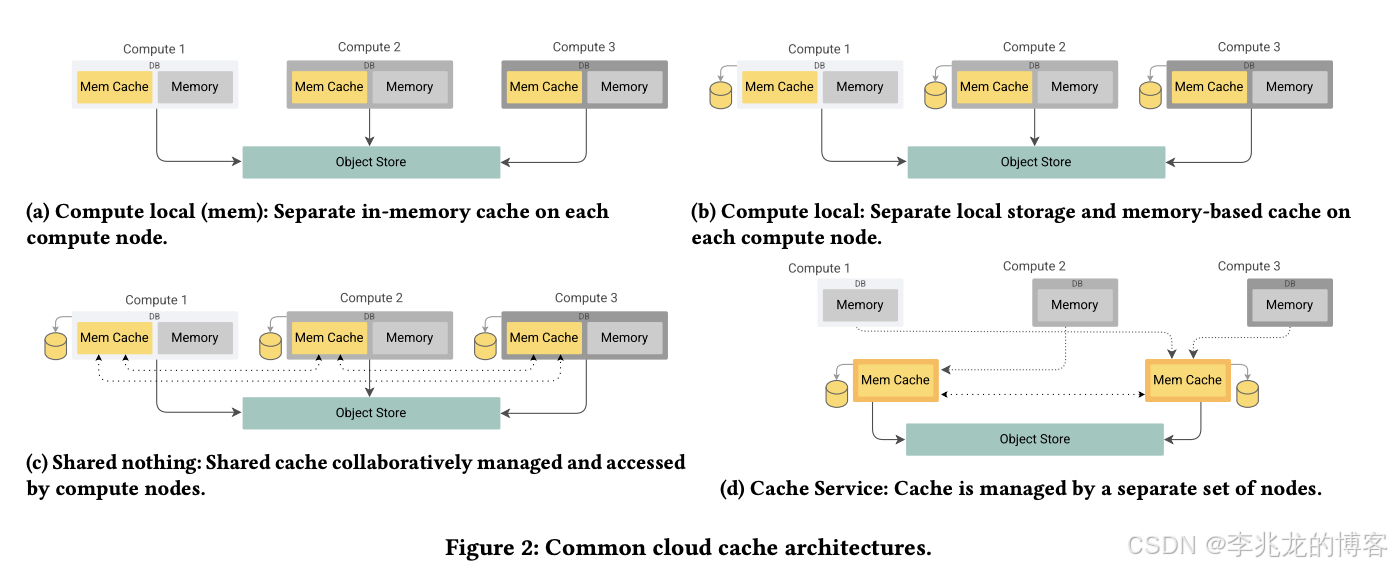
为了引出公式先阐述业界目前的缓存形态,其实挺有意思的,看着篇文章之前我们也在做缓存设计,有一些我们自己的考量选择了一种我们认为最优的场景,其中一些考量论文中有提到,论文中提到的点有:
- 重启或宕机后缓存状态无法保留,导致变版本,故障期间查询尾延高。
- 第三种形态本地存储会导致缓存是热点,还需要增加热点识别在存在热点时把任务分布到其他机器。
- 第二种,第三种从设计的角度来讲最简单,甚至于部分计算引擎本来就携带了类似的机制,比如Velox的AsyncCache
FIVE-MINUTE RULE FOR THE CLOUD
公式中只包含请求成本,不包含托管应用程序,对象存储存储量。

这里统一认为缓存成本就是硬件成本,事实上在使用第四种架构的情况下也可以是serverless的。
对象存储就是用请求数建模,但是实际上以腾讯云对象存储为例[3],其实数据取回费用也是很贵的,但是S3就没有这部分的费用,如果是自建的对象存储(私有云,开源产品自建)这里收的就是设备的费用,所以这里的建模也不是普适性的,需要看实际使用的对象存储的定价策略。

缓存的成本是是: ( 存储成本+实例成本) x 缓存大小(GB) x 缓存的生命周期(小时)+ 缓存未命中的成本(未命中都需要为从对象存储获取新对象的请求付费)

如果缓存和应用程序共享同一节点,可以减去实例成本:

对象存储的成本就是请求数,但是加上了一个所谓的𝑅𝑒𝑝𝑒𝑎𝑡𝑠𝑇𝑜𝐺𝑢𝑎𝑟𝑎𝑛𝑡𝑒𝑒𝐿𝑎𝑡𝑒𝑛𝑐𝑦,即Racing Reads :
在没有缓存的系统中,一种常用的降低延迟变化的技术是Racing Reads 。使用此技术的系统会针对同一对象发出多个请求,并采用最先到达的响应,忽略其他任何响应。

如上图所示,从1个并发请求增加到2个并发请求时,第99百分位延迟(99% 的请求在给定时间内完成)显著改善,从约180毫秒降至145毫秒。额外的并发请求进一步改善了预期延迟,但回报递减。

利用延迟分布,可以计算从对象存储中在目标延迟预算内读取对象的概率 P 。如果对该对象有 n 个独立请求,那么所有请求都超过目标延迟的概率为(1−P)n(1 - P)^n(1−P)n。因此n 个请求中至少有一个达到目标的概率1−(1−P)n1-(1 - P)^n1−(1−P)n,求解可得上述公式。
基于AWS服务填充上述公式:
非延迟敏感工作负载和延迟工作负载的对象存储成本差别由Racing Reads导致,缓存成本不变,所以会导致不同的结果。

- 节点上缓存(EBS):每小时25,000次请求,大致相当于每分钟420次请求或每秒7次请求。
- 节点缓存(NVMe):每小时50,000次请求,每分钟840次请求,即每秒14次请求。
- 专用缓存(EBS):每小时125,000次请求,每分钟2,000次请求,每秒35次请求。
- 专用缓存(NVMe)每小时225,000次请求,每分钟3,700次请求,每秒62次请求。
途中交叠点就是break-even point,在这些个苛刻和建模下得到了非延迟敏感工作负载中七个请求是关键点的结论。

上图为使用1MiB请求重复读取1GiB数据的成本,其中每次请求延迟有99%的概率为100毫秒或1秒(Racing Reads会导致对象存储成本不一致),无缓存(S3)与命中率为95%的1GiB块存储(EBS)或固态硬盘(NVMe)缓存的对比。
结束语
这种文章其实没有太多的工程实践价值,更多的是大佬们给出一个大的指导方向。
计算机领域中对于很多问题的建模都比较苛刻,实际的工程系统是非常复杂的,影响因素非常之多,比如命中率这种现网很难给一个完美的值,都是动态变化的,而且不同系统的建模方式都存在差异,比如提到的对象存储计费。
这篇文章中其实最终的结论太依赖于Racing Reads,但是现实中很少见到用这个的,因为很容易跑满带宽导致失败,现实就是理论带宽是100G,但是实际可能还没有跑到这里就存在失败,而且有时候也会出现QPS限制的失败。
参考:
- https://zhuanlan.zhihu.com/p/1932613410174014236
- 腾讯云对象存储定价
- 从一到无穷大 #22 基于对象存储执行OLAP分析的学术or工程经验,我们可以从中学习到什么?