面向高级负载的 Kubernetes 调度框架对比分析:Volcano、YuniKorn、Kueue 与 Koordinator
前言
随着 Kubernetes 成为容器编排的事实标准,其应用场景已从无状态服务扩展到人工智能(AI)、机器学习(ML)、高性能计算(HPC)和大数据分析等复杂且资源密集型的领域。然而,Kubernetes 的默认调度器 kube-scheduler 在设计上主要面向长时运行的服务,其逐个 Pod 的调度模式在处理需要协同调度、精细化资源管理和高吞吐量的批处理及弹性工作负载时,暴露出诸多局限性。为弥补这些不足,云原生社区涌现出多个高级调度框架,其中 Volcano、YuniKorn、Kueue 和 Koordinator 是四个最具代表性的解决方案。
本报告旨在对这四个调度框架进行全面、深入的比较分析,从架构范式、核心功能、高级特性、生态系统及运营等多个维度,揭示其设计哲学、技术实现与适用场景的差异。

-
Volcano:作为一个全面的云原生批处理系统,Volcano 源自
kube-batch,是 CNCF 的孵化项目。它提供了一整套丰富的功能,包括强大的 Gang Scheduling(成组调度)、层级队列管理、多种公平性策略以及先进的网络拓扑感知能力。值得注意的是,Volcano 也提供了一套完整的在离线混合部署解决方案,通过节点代理(SLO Agent)和内核级 QoS 保障机制,旨在提升集群资源利用率,是专为满足 HPC 和大规模 AI 训练等高性能计算需求而设计的“重武器”。 -
YuniKorn:源于大数据生态(特别是 Apache Hadoop YARN)的通用资源调度器,是 Apache 基金会的顶级项目。YuniKorn 的核心优势在于其强大的多租户管理能力,通过精细的层级队列、资源配额和公平性策略,为在 Kubernetes 上运行 Spark、Flink 等大数据作业提供了媲美 YARN 的调度体验。
-
Kueue:作为 Kubernetes SIG-Scheduling 的子项目,Kueue 采取了一种独特的“元调度器”或“作业排队系统”的架构。它并不替换默认调度器,而是通过准入控制(Admission Control)对作业进行排队、挂起和准入,将实际的 Pod 到节点的绑定工作委托给
kube-scheduler。这种轻量级、非侵入式的设计使其极易被采用,尤其适用于需要为通用批处理作业添加队列和配额管理的弹性云环境。 -
Koordinator:源自阿里巴巴大规模生产实践的 CNCF 沙箱项目,其独特价值主张在于通过服务质量(QoS)驱动的混合部署(Co-location)能力,极致地提升集群资源利用率。Koordinator 不仅仅是一个调度器,而是一套完整的系统,包含调度插件、节点代理(
koordlet)和管理器,能够安全地将在线服务和离线批处理作业部署在同一批节点上,并通过精密的实时负载感知和运行时干预来保障在线服务的 SLO。
本报告的分析表明,选择最合适的调度器并非取决于功能的多少,而在于其设计哲学是否与组织的核心需求、工作负载特性及运维能力相匹配。对于追求极致性能的大规模 AI/HPC 场景,Volcano 的功能集最为全面;对于需要精细化多租户管理的大数据平台,YuniKorn 提供了最熟悉的范式;对于寻求简单、云原生方式管理通用批处理作业的团队,Kueue 是理想的切入点;而对于致力于通过混合部署来大幅降低 TCO 的大型企业,Volcano 和 Koordinator 均提供了强大的解决方案,其中 Koordinator 在实时干扰检测和动态 SLO 保障方面提供了业界领先的精细化控制能力。本报告将为平台架构师、技术负责人和高级运维工程师在进行技术选型时提供一份详尽、可靠的决策依据。
第一章:架构范式与集成模型
在深入比较四个高级调度框架之前,必须首先理解它们各自的架构设计以及与 Kubernetes 原生调度生态的集成方式。每个框架的架构选择不仅反映了其设计哲学,也直接决定了其功能边界、运维复杂度和长期演进路径。本章将首先剖析默认调度器的局限性,然后逐一解析 Volcano、YuniKorn、Kueue 和 Koordinator 的架构范式,并最终综合对比其设计上的权衡。
1.1 基准:默认 Kubernetes 调度器的局限性
Kubernetes 的默认调度器 kube-scheduler 是一个健壮且高效的控制平面组件,其核心任务是为处于 Pending 状态的 Pod 寻找到一个合适的节点进行绑定。其工作流程主要分为两个阶段:调度周期(Scheduling Cycle)和绑定周期(Binding Cycle)。在调度周期中,调度器通过一系列“断言(Predicates)”或“过滤(Filtering)”插件(如检查资源是否满足、端口是否冲突、节点亲和性是否匹配等)筛选出所有可以运行该 Pod 的候选节点,然后通过一系列“优先级(Priorities)”或“打分(Scoring)”插件(如均衡资源分配、优先选择已存在所需镜像的节点等)为每个候选节点打分,最终选择得分最高的节点。
尽管这套机制对于长时运行的微服务非常有效,但在面对新兴的专业化工作负载时,其固有的、逐个 Pod 调度的本质暴露了显著的局限性:
-
缺乏成组调度(Gang Scheduling)能力:分布式 AI 训练或大数据作业(如 MPI、Spark)通常包含多个需要同时启动的 Pod。
kube-scheduler逐个调度这些 Pod,可能导致部分 Pod 成功调度并占用资源,而另一部分因资源不足而持续等待。这种“部分启动”的状态会造成已分配资源的空转和浪费,甚至引发整个作业的死锁。 -
队列机制过于简单:Kubernetes 的资源管理主要依赖于
Namespace级别的ResourceQuota。这是一种硬性约束,在 Pod 创建的准入阶段(Admission Phase)进行校验。如果资源不足,Pod 创建请求会直接失败,集群层面没有内置的排队机制让作业等待资源释放。这迫使客户端或上层应用控制器需要实现复杂的重试和排队逻辑。 -
公平性策略基础:默认的调度队列主要基于 Pod 的优先级进行排序,对于同一优先级的 Pod 则遵循先进
出(FIFO)的原则。在多租户环境中,一个用户提交的大量或长时间运行的低优先级作业,可能会因为先到而持续占用资源,导致其他用户的高优先级作业被阻塞或“饿死”,缺乏跨用户、跨租户的公平共享机制。
-
拓扑无感知:
kube-scheduler对节点的物理拓扑结构(如服务器所在的机架、连接的网络交换机、CPU 的 NUMA 架构或 GPU 间的 NVLink 连接)知之甚少。虽然可以通过节点标签和亲和性/反亲和性进行粗粒度的控制,但无法进行精细的拓扑感知调度,这对于通信密集型的 HPC 和 AI 应用至关重要,因为不佳的 Pod 布局会显著增加网络延迟,影响整体性能。 -
基于“请求”而非“负载”:调度决策的核心依据是 Pod 定义中的资源
requests,这是一个静态的声明值。调度器并不关心节点上实际的资源使用率(即负载)。这种模式在混合部署场景下效率低下,因为在线服务为了应对流量高峰,其requests通常远高于平均使用量,导致大量资源被“预留”但未被使用,而调度器无法安全地将这些“闲置”资源分配给其他工作负载。
正是这些局限性催生了对更高级调度解决方案的需求,Volcano、YuniKorn、Kueue 和 Koordinator 应运而生,它们通过不同的架构路径来解决上述一个或多个问题。
1.2 Volcano:一个全面的批处理调度系统
Volcano 的定位是一个为高性能、高吞吐量计算而生的云原生批处理系统。它的架构设计旨在提供一个功能完备、一站式的解决方案,以替代或增强 kube-scheduler。
-
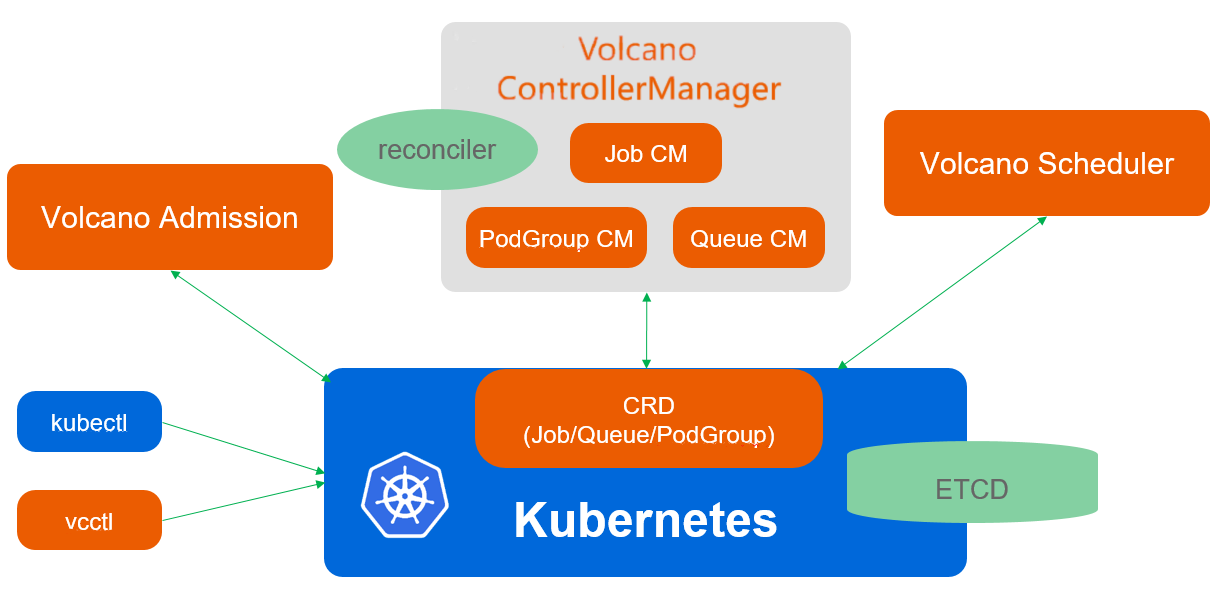
架构:Volcano 作为一个独立的调度器运行,用户通过在 Pod 或工作负载的规约中指定
schedulerName: volcano来使用它。它并非单一组件,而是一个系统,主要包括:-
volcano-scheduler:核心调度器,负责执行调度逻辑。 -
volcano-controller:负责管理 Volcano 相关的自定义资源(CRD)并与调度器协同工作。 -
volcano-admission:一个 Webhook 服务,用于校验和修改 Pod、Job 等资源,注入调度所需的信息。 -
volcano-agent(SLO Agent):作为 DaemonSet 部署在每个节点上,负责动态计算节点可超卖的资源、保障节点 QoS(例如,在检测到 CPU/内存压力时驱逐低优先级作业)以及实现 CPU Burst 等高级功能2。 -
可选组件:如
resource-exporter(用于上报 NUMA 拓扑信息)等,进一步增强其功能。
-
-
核心概念:Volcano 的设计哲学是以“作业”为中心,而非“Pod”。它引入了
VolcanoJob和PodGroup等 CRD,将一组关联的 Pod 作为一个逻辑单元进行管理和调度。这一设计直接解决了默认调度器缺乏作业抽象的问题。Volcano 项目源于早期的kube-batch项目,其初衷就是为了解决 Kubernetes 中的成组调度问题,后来随着 AI 和大数据场景需求的增长,演变为功能更强大的 Volcano。 -
治理:Volcano 是云原生计算基金会(CNCF)的孵化(Incubating)项目,也是 CNCF 在批处理调度领域的第一个官方项目。这表明它拥有强大的社区支持、中立的厂商治理和明确的演进路线,为企业用户提供了采用的信心。
1.3 YuniKorn:一个面向大数据和批处理的通用调度器
YuniKorn 的设计深受其在 Apache Hadoop 生态中的渊源影响,旨在为 Kubernetes 带来一个通用、高性能、支持大规模多租户的资源调度器。
-
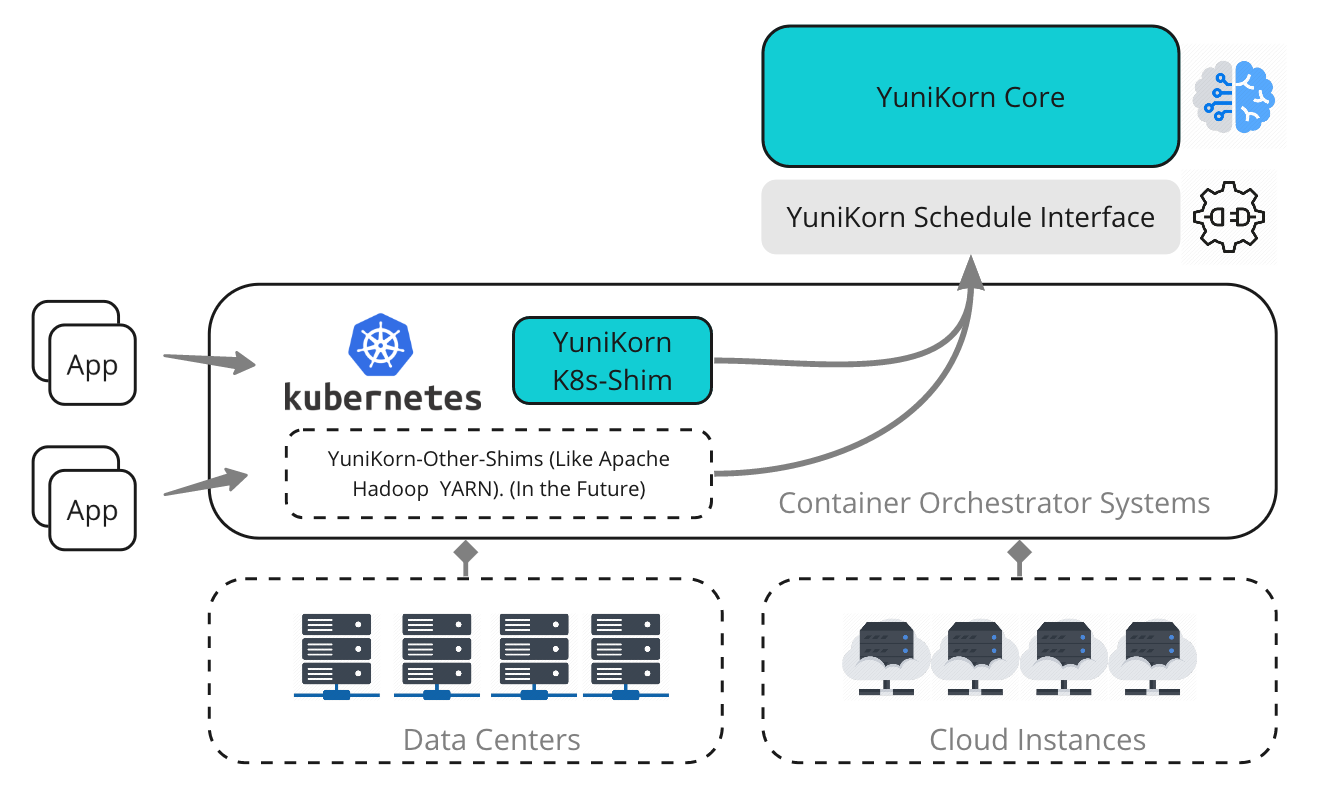
架构:YuniKorn 的架构经历了重要的演进。
-
传统模式:最初,YuniKorn 是一个完全从头实现的
kube-scheduler替代品。这种方式使其能够快速创新,但也带来了与 Kubernetes 版本升级的兼容性阵痛,因为它需要调用一些非公开的 K8s 内部 API,导致维护成本高昂。 -
插件模式:为了解决兼容性问题并更好地融入 Kubernetes 生态,YuniKorn 正在积极转向基于 Kubernetes 调度框架(Scheduling Framework)的插件模型。在这种新模式下,YuniKorn 的核心调度逻辑可以作为插件运行在标准的 kube-scheduler 二进制文件中,既能利用 YuniKorn 的高级功能,又能享受与上游 Kubernetes 的无缝兼容性。项目为此提供了两种不同的 Docker 镜像:scheduler-{version}(传统版)和 scheduler-plugin-{version}(插件版)。
其核心架构由两部分组成:yunikorn-core(包含所有调度算法的“大脑”)和 yunikorn-k8shim(与 Kubernetes API Server 通信的“适配器”)。
-
-
核心概念:YuniKorn 的核心理念是“应用感知调度”(App-aware scheduling)。它识别用户、应用和队列,并基于这些上下文进行决策,这与
kube-scheduler的 Pod 视角形成鲜明对比。其强大的层级队列和公平性策略深受 YARN Capacity Scheduler 的影响,使其特别适合需要复制传统大数据集群管理模式的场景。 -
治理:YuniKorn 是 Apache 软件基金会(ASF)的顶级项目。这一背景不仅体现了其在大数据领域的深厚根基,也意味着它遵循 ASF 成熟的社区治理和开发流程。