Celery分布式任务队列
文章目录
- Celery
- 核心组件
- 工作原理
- 处理异步任务
- Docker部署运行Kafka
- 处理定时任务
Celery
Celery 是一个分布式任务队列,主要用于处理异步任务、定时任务和大规模并发任务。它可以将耗时操作(如数据处理、邮件发送、文件转换等)从主程序中剥离,通过异步执行提高系统响应速度和资源利用率。
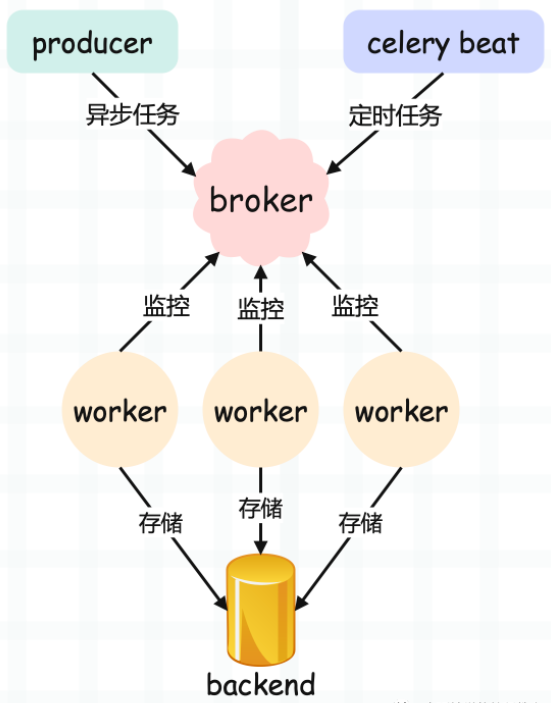
核心组件
消息中间件(Broker):作为任务的调度中心,接收生产者发送的任务消息,再将消息分发给消费者(Worker)。
执行单元(Worker):实际执行任务的进程 / 线程,负责从 Broker 中获取任务、执行任务,并将结果发送给Backend, 通过命令: celery -A 项目名 worker --loglevel=info 启动。
结果存储(Backend):存储 Worker 执行任务后的结果,供生产者查询。
Celery Beat:定时任务调度器,用于周期性生成任务,其原理是定期向 Broker 发送任务消息。启动命令:celery -A 项目名 beat --loglevel=info。
工作原理
-
生产者调用 Celery 任务,任务被序列化后发送到 Broker。
-
Worker 从 Broker 中获取任务并执行。
-
任务执行完成后,Worker 将执行结果存入 Backend。
-
生产者通过 Backend 查询任务结果。
如果是定时任务,则由 Celery Beat 定期向 Broker 发送任务,后续流程一样。
处理异步任务
异步处理订单信息,Broker采用Kafka,Backend采用Redis。
Docker部署运行Kafka
创建目录配置文件
mkdir -p ~/kafka-docker && cd ~/kafka-docker
创建docker-compose.yml文件
vim docker-compose.yml
services:zookeeper:image: confluentinc/cp-zookeeper:latestcontainer_name: zookeeperenvironment:ZOOKEEPER_CLIENT_PORT: 2181ZOOKEEPER_TICK_TIME: 2000ports:- "2181:2181"volumes:- zookeeper-data:/var/lib/zookeeper/datanetworks:- kafka-networkhealthcheck:test: ["CMD", "echo", "ruok", "|", "nc", "localhost", "2181"]interval: 5stimeout: 5sretries: 5kafka:image: confluentinc/cp-kafka:latestcontainer_name: kafkadepends_on:zookeeper:condition: service_healthyports:- "9092:9092"- "9093:9093"environment:KAFKA_PROCESS_ROLES: broker,controllerKAFKA_BROKER_ID: 1KAFKA_CONTROLLER_QUORUM_VOTERS: 1@kafka:9093KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT,CONTROLLER:PLAINTEXTKAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka:29092,PLAINTEXT_HOST://xxxxxxxx:9092KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1KAFKA_AUTO_CREATE_TOPICS_ENABLE: "true"CLUSTER_ID: "MkU3OEVBNTcwNTJENDM2Qk"KAFKA_CONTROLLER_LISTENER_NAMES: CONTROLLERKAFKA_LISTENERS: PLAINTEXT://kafka:29092,PLAINTEXT_HOST://0.0.0.0:9092,CONTROLLER://0.0.0.0:9093volumes:- kafka-data:/var/lib/kafka/datanetworks:- kafka-networknetworks:kafka-network:driver: bridgevolumes:zookeeper-data:kafka-data:运行kafka
docker compose up -d
查看是否运行正常
docker ps

celery_app.py配置信息及定义任务
from celery import Celery
import timeapp = Celery('kafka_redis_demo', broker='confluentkafka://xxxxxxxx:9092', broker_transport='confluentkafka', broker_transport_options={'queue_name_prefix': 'demo-', 'bootstrap_servers': ['xxxxxxxx:9092'], 'socket_timeout_ms': 30000, },backend='redis://localhost:6379/0',task_serializer='json',result_serializer='json',accept_content=['json'],timezone='Asia/Shanghai',enable_utc=True,task_routes={'celery_app.process_order': {'queue': 'demo-celery'}}
)# 定义任务
@app.task(bind=True,max_retries=3,retry_delay=2,queue='demo-celery'
)
def process_order(self, order_id: str, amount: float, user_id: str):try:print(f"开始处理订单 {order_id}(用户 {user_id},金额 {amount} 元)")time.sleep(2) return {"order_id": order_id,"status": "success","amount": amount,"user_id": user_id,"processed_at": time.strftime("%Y-%m-%d %H:%M:%S")}except Exception as e:print(f"订单 {order_id} 处理失败,重试中...")self.retry(exc=e)启动worker
需要在celery当前目录执行
celery -A celery_app worker --loglevel=info --queues=demo-celery --pool=solo
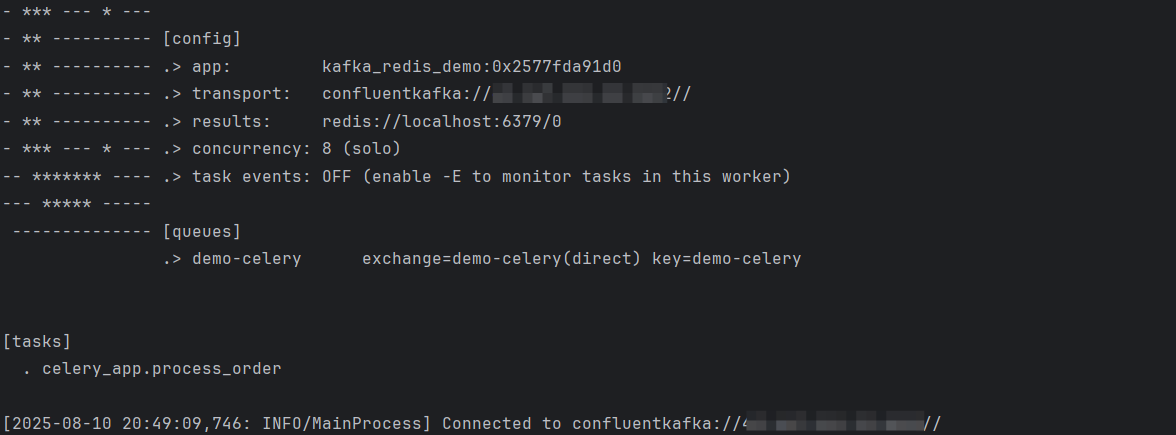
producer.py生产者发送消息
from celery_app import process_orderdef submit_tasks():task_ids = []for i in range(1, 4):order_id = f"ORD{202408:06d}" task = process_order.delay(order_id=order_id,amount=99.9 * i,user_id=f"USER{i:03d}")task_ids.append({"order_id": order_id, "task_id": task.id})print(f"提交订单 {order_id},任务ID:{task.id}")return task_idsif __name__ == "__main__":submitted_tasks = submit_tasks()with open("task_ids.txt", "w") as f:import jsonjson.dump(submitted_tasks, f)
查看kafka队列已经收到消息
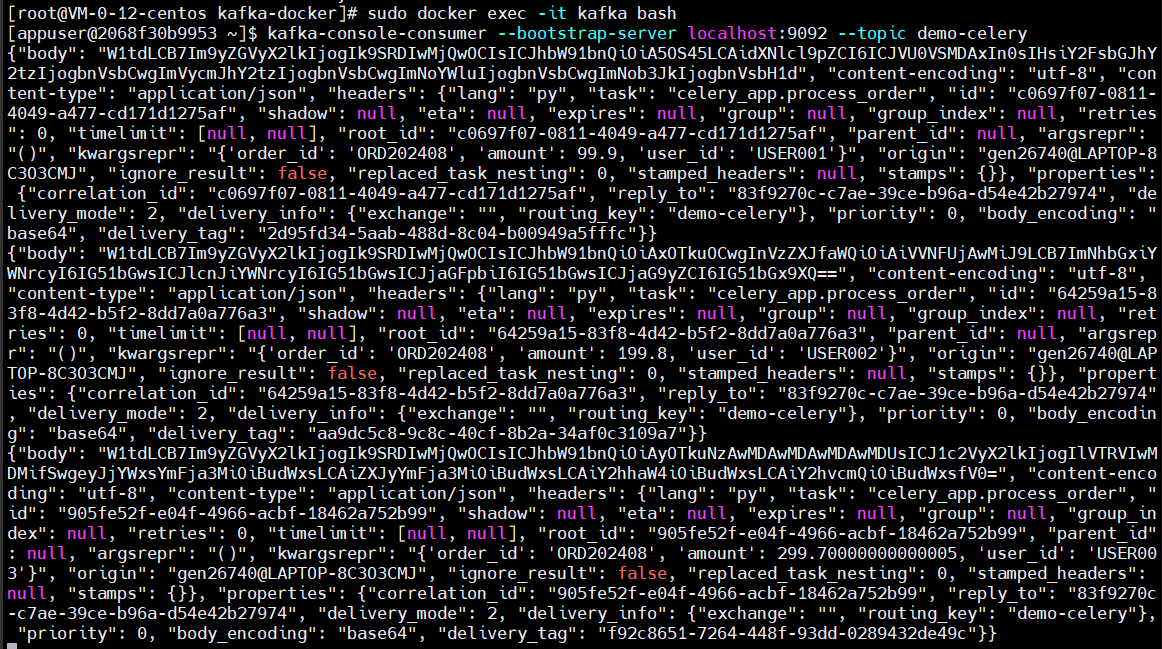
worker执行任务
result_checker.py查询结果
from celery_app import app
import jsondef check_results():with open("task_ids.txt", "r") as f:tasks = json.load(f)for task in tasks:task_id = task["task_id"]order_id = task["order_id"]result = app.AsyncResult(task_id)print(f"\n订单 {order_id}(任务ID:{task_id})")print(f"状态:{result.status}") print(f"任务信息:{result.info}") if result.ready():if result.successful():print("结果:", result.get()) else:print("错误:", str(result.result)) else:print("任务尚未完成")if __name__ == "__main__":check_results()查询结果
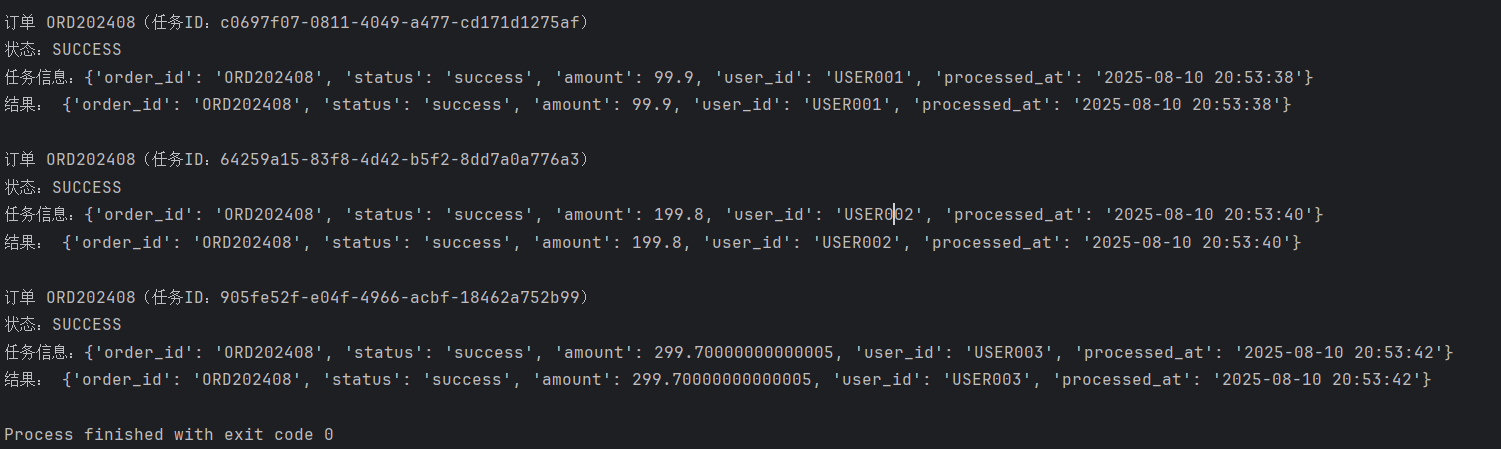
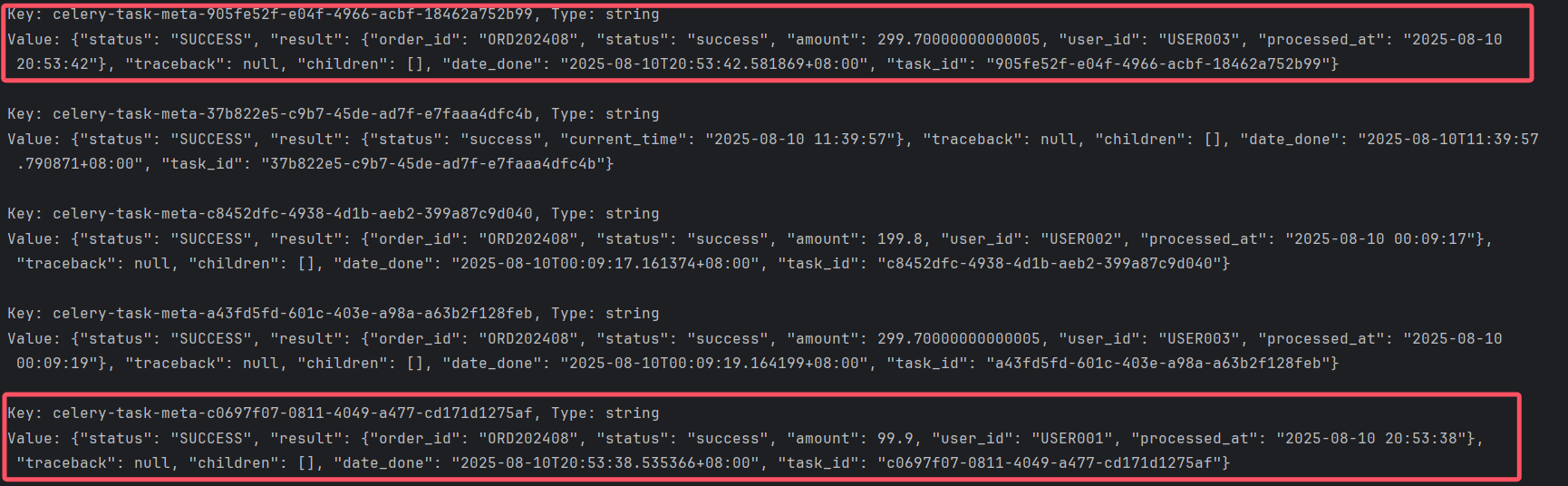
redis中的最终存储结果
处理定时任务
celery_config.py
from celery import Celery
from celery.schedules import crontab
import time
import os
import logging
app = Celery('kafka_redis_schedule_demo',broker='confluentkafka://xxxxxxxx:9092',broker_transport='confluentkafka',broker_transport_options={'bootstrap_servers': ['xxxxxxxx:9092'],'socket_timeout_ms': 30000,'api_version': (2, 8, 1),'queue_name_prefix': 'schedule-'},backend='redis://localhost:6379/0',task_serializer='json',result_serializer='json',accept_content=['json'],timezone='Asia/Shanghai',enable_utc=False,task_routes={'celery_config.print_current_time': {'queue': 'schedule-tasks2'}}
)app.conf.beat_schedule = {# 任务1:每30秒执行一次'every-30-seconds-print-time': {'task': 'celery_config.print_current_time','schedule': 30.0,'args': (),},# 任务2:每天凌晨3点执行'daily-2am-cleanup-logs': {'task': 'celery_config.cleanup_logs','schedule': crontab(hour=3, minute=0),'args': ('./var/log/app',),},# 任务3:每周一上午8点执行'weekly-monday-10am-statistics': {'task': 'celery_config.generate_weekly_report','schedule': crontab(hour=8, minute=0, day_of_week=1),'args': ('weekly_report.csv',),}
}logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)# 任务1:打印当前时间
@app.task(queue='schedule-tasks2')
def print_current_time():current_time = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())print(f"当前时间: {current_time}")return {"status": "success", "current_time": current_time}# 任务2:清理日志文件
@app.task(queue='schedule-tasks2')
def cleanup_logs(log_dir):try:if not os.path.exists(log_dir):return {"status": "failed", "message": f"日志目录不存在: {log_dir}"}print(f"开始清理日志目录: {log_dir}")time.sleep(2)print(f"日志清理完成: {log_dir}")return {"status": "success", "cleaned_dir": log_dir}except Exception as e:print(f"日志清理失败: {str(e)}")return {"status": "failed", "error": str(e)}# 任务3:生成每周报告
@app.task(queue='schedule-tasks2')
def generate_weekly_report(output_file):try:print(f"开始生成每周报告: {output_file}")time.sleep(3) print(f"每周报告生成完成: {output_file}")return {"status": "success","report_file": output_file,"period": "2025-08-11至2025-08-17"}except Exception as e:return {"status": "failed", "error": str(e)}
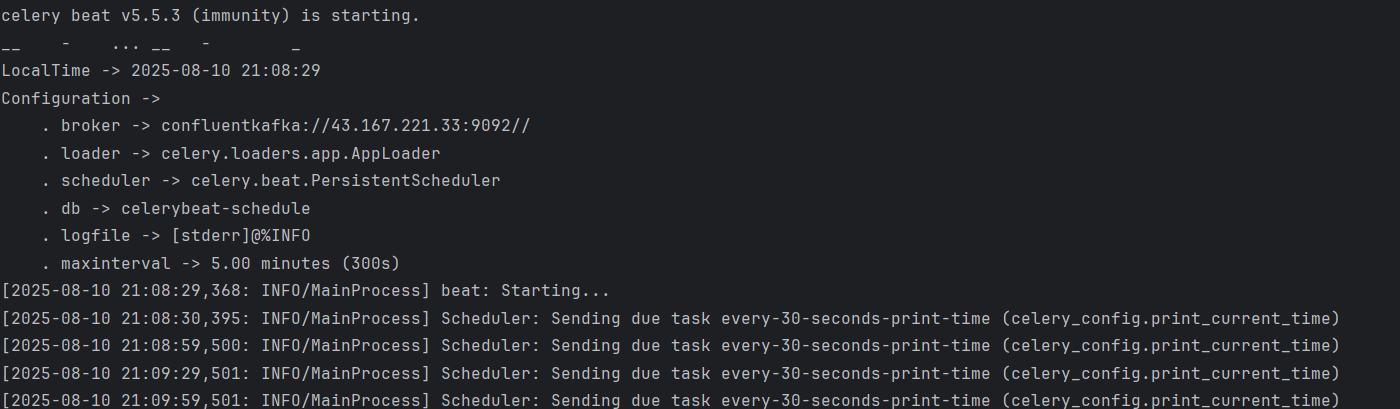
启动任务调度器,Celery Beat每隔30s往Broker发送消息
celery -A celery_config beat --loglevel=info
启动worker执行任务
celery -A celery_config worker --loglevel=info --pool=solo --queues=schedule-tasks2
