【网络与爬虫 51】Scrapy-Cluster分布式爬虫集群:企业级大规模数据采集解决方案
关键词:Scrapy-Cluster、分布式爬虫、Redis集群、Kafka消息队列、爬虫集群管理、大规模数据采集、分布式架构、爬虫监控、负载均衡、高可用爬虫
摘要:深入解析Scrapy-Cluster分布式爬虫集群的架构设计与实战应用,从单机爬虫到企业级集群的完整演进。涵盖Redis队列管理、Kafka消息处理、集群监控、负载均衡等核心技术,助你构建高性能、高可用的大规模数据采集系统。
文章目录
- 引言:从单机到集群的爬虫进化之路
- 什么是Scrapy-Cluster?
- 核心概念
- 架构优势
- Scrapy-Cluster核心架构解析
- 整体架构图
- Redis在集群中的作用
- Kafka消息处理
- 环境搭建与安装配置
- 基础环境准备
- 安装Scrapy-Cluster
- 配置文件详解
- 编写分布式爬虫
- 基础Spider示例
- 高级Spider特性
- 集群管理与监控
- Kafka Monitor配置
- 启动Monitor服务
- REST API接口
- 性能优化与最佳实践
- 集群性能调优
- 监控与告警
- 部署与运维
- Docker化部署
- Kubernetes部署
- 监控告警
- 实战案例:电商数据采集集群
- 集群部署脚本
- 总结与最佳实践
- 核心要点回顾
- 最佳实践建议
引言:从单机到集群的爬虫进化之路
想象一下,你的爬虫项目从最初的几千个URL发展到需要处理数百万甚至数十亿个网页。单机Scrapy已经无法满足需求,CPU、内存、网络带宽都成为了瓶颈。这时候,你需要的不是更强的单机,而是一个能够水平扩展的分布式爬虫集群。
这就是Scrapy-Cluster诞生的背景——一个基于Redis和Kafka的分布式Scrapy框架,它能让你的爬虫从单机扩展到数百台服务器的集群,处理海量数据采集任务。
今天,我们将深入探索Scrapy-Cluster的架构原理,学会如何从零搭建企业级的分布式爬虫系统。
什么是Scrapy-Cluster?
核心概念
Scrapy-Cluster是一个分布式的Scrapy扩展框架,它将传统的单机Scrapy转变为可以在多台机器上协同工作的集群系统。
简单来说,它解决了以下问题:
- 水平扩展:从1台机器扩展到N台机器
- 任务分发:智能地将爬取任务分配给不同的节点
- 状态共享:多个节点间共享爬取状态和去重信息
- 监控管理:统一监控和管理整个集群的运行状态
架构优势
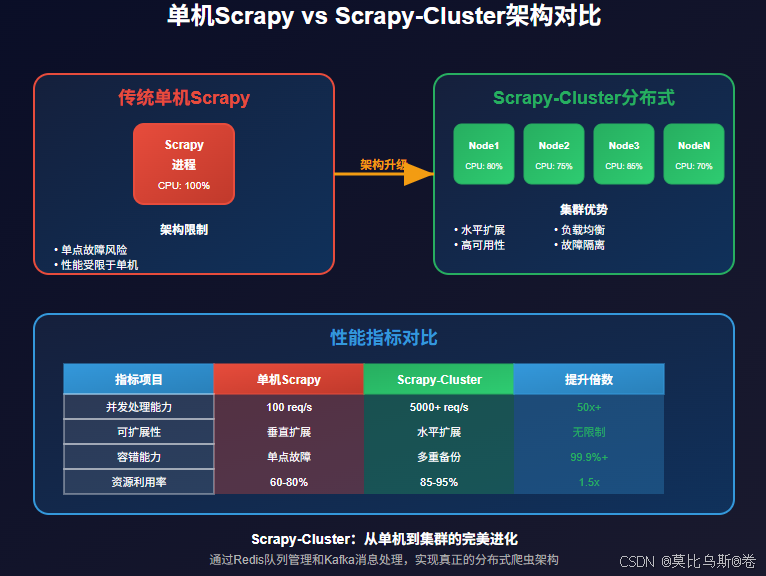
与传统单机Scrapy相比,Scrapy-Cluster具有以下优势:
- 高性能:多机并行处理,吞吐量成倍增长
- 高可用:单点故障不影响整体系统运行
- 易扩展:根据负载动态增减节点
- 统一管理:集中式的任务调度和监控
Scrapy-Cluster核心架构解析
整体架构图
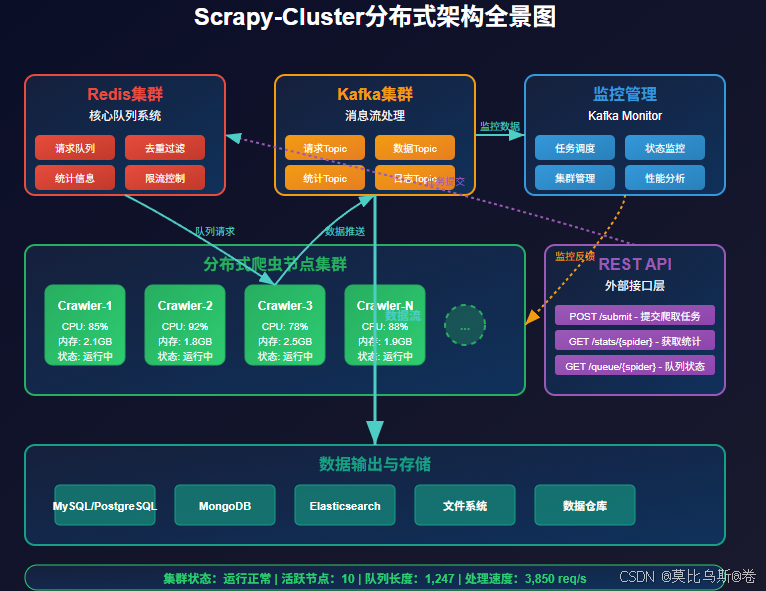
Scrapy-Cluster的架构主要包含以下组件:
- Redis集群:作为核心的队列和缓存系统
- Kafka集群:处理爬虫产生的数据流
- Crawler节点:实际执行爬取任务的工作节点
- Kafka Monitor:监控和管理集群状态
- REST API:提供外部接口进行任务管理
Redis在集群中的作用
Redis在Scrapy-Cluster中扮演着核心角色:
# Redis配置示例
REDIS_HOST = 'redis-cluster-host'
REDIS_PORT = 6379
REDIS_DB = 0# Redis键命名规范
REDIS_KEYS = {'spider_queue': 'spider:queue','dupefilter': 'dupefilter:{spider}','stats': 'stats:{spider}','throttle': 'throttle:{spider}'
}
Redis的主要功能:
- 请求队列:存储待爬取的URL队列
- 去重过滤:基于BloomFilter的URL去重
- 统计信息:实时统计爬取进度和性能指标
- 限流控制:控制爬取频率和并发数
Kafka消息处理
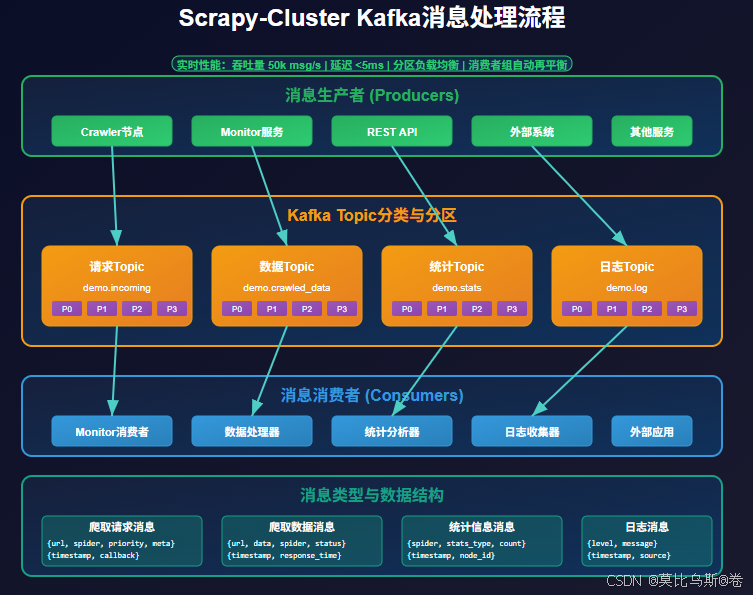
Kafka负责处理爬虫产生的各种数据:
# Kafka配置
KAFKA_HOSTS = ['kafka1:9092', 'kafka2:9092', 'kafka3:9092']
KAFKA_TOPIC_PREFIX = 'scrapy-cluster'# 不同类型的Topic
KAFKA_TOPICS = {'crawl_requests': 'demo.crawled_firehose','crawl_data': 'demo.crawled_data','stats': 'demo.stats'
}
Kafka Topic分类:
- crawl_requests:新的爬取请求
- crawled_data:爬取到的数据
- stats:统计和监控信息
- log:系统日志信息
环境搭建与安装配置
基础环境准备
首先,我们需要准备基础的分布式环境:
# 1. 安装Redis集群
sudo apt-get install redis-server
# 配置Redis集群模式# 2. 安装Kafka
wget https://downloads.apache.org/kafka/2.8.0/kafka_2.13-2.8.0.tgz
tar -xzf kafka_2.13-2.8.0.tgz
cd kafka_2.13-2.8.0# 启动Zookeeper
bin/zookeeper-server-start.sh config/zookeeper.properties# 启动Kafka
bin/kafka-server-start.sh config/server.properties
安装Scrapy-Cluster
# 克隆项目
git clone https://github.com/istresearch/scrapy-cluster.git
cd scrapy-cluster# 安装依赖
pip install -r requirements.txt# 安装各个组件
cd crawler && python setup.py install
cd ../kafka-monitor && python setup.py install
cd ../rest && python setup.py install
配置文件详解
Crawler配置(settings.py):
# Scrapy-Cluster核心配置
SPIDER_MODULES = ['crawling.spiders']
NEWSPIDER_MODULE = 'crawling.spiders'# Redis配置
REDIS_HOST = 'localhost'
REDIS_PORT = 6379
REDIS_DB = 0# Scheduler配置
SCHEDULER = "scrapy_cluster.scheduler.Scheduler"
SCHEDULER_PERSIST = True
SCHEDULER_QUEUE_CLASS = 'scrapy_cluster.queue.SpiderPriorityQueue'# Pipeline配置
ITEM_PIPELINES = {'scrapy_cluster.pipelines.KafkaPipeline': 100,
}# Kafka配置
KAFKA_HOSTS = 'localhost:9092'
KAFKA_INCOMING_TOPIC = 'demo.incoming'
KAFKA_OUTGOING_TOPIC = 'demo.outgoing_firehose'# 并发控制
CONCURRENT_REQUESTS = 100
CONCURRENT_REQUESTS_PER_DOMAIN = 10
DOWNLOAD_DELAY = 0.1
RANDOMIZE_DOWNLOAD_DELAY = 0.5# 分布式去重
DUPEFILTER_CLASS = 'scrapy_cluster.dupefilter.RFPDupeFilter'
DUPEFILTER_KEY = 'dupefilter:{spider}'# 统计配置
STATS_CLASS = 'scrapy_cluster.stats.RedisStatsCollector'
编写分布式爬虫
基础Spider示例
# crawling/spiders/distributed_spider.py
import scrapy
from scrapy_cluster.spiders import ClusterSpiderclass DistributedSpider(ClusterSpider):name = 'distributed'def __init__(self, *args, **kwargs):super(DistributedSpider, self).__init__(*args, **kwargs)def parse(self, response):"""解析页面内容"""# 提取数据for item in self.extract_items(response):yield item# 提取链接for link in self.extract_links(response):yield scrapy.Request(url=link,callback=self.parse,meta={'priority': 1,'expires': 3600, # 1小时过期'retry_times': 3})def extract_items(self, response):"""提取页面数据"""items = []# 使用CSS选择器提取数据for item_node in response.css('.item'):item = {'title': item_node.css('.title::text').get(),'url': response.url,'content': item_node.css('.content::text').get(),'timestamp': self.get_current_time(),'spider': self.name}items.append(item)return itemsdef extract_links(self, response):"""提取页面链接"""links = []# 提取分页链接for link in response.css('.pagination a::attr(href)').getall():full_url = response.urljoin(link)links.append(full_url)# 提取内容链接for link in response.css('.item-link::attr(href)').getall():full_url = response.urljoin(link)links.append(full_url)return links
高级Spider特性
# 带优先级和重试机制的Spider
class AdvancedDistributedSpider(ClusterSpider):name = 'advanced_distributed'def __init__(self, *args, **kwargs):super(AdvancedDistributedSpider, self).__init__(*args, **kwargs)self.setup_custom_settings()def setup_custom_settings(self):"""自定义设置"""self.custom_settings = {'DOWNLOAD_DELAY': 2,'CONCURRENT_REQUESTS_PER_DOMAIN': 5,'RETRY_TIMES': 5,'RETRY_HTTP_CODES': [500, 502, 503, 504, 408, 429]}def parse(self, response):"""带错误处理的解析方法"""try:# 检查响应状态if response.status != 200:self.logger.warning(f"Non-200 response: {response.status} for {response.url}")return# 检查内容长度if len(response.text) < 100:self.logger.warning(f"Response too short for {response.url}")return# 正常处理yield from self.process_response(response)except Exception as e:self.logger.error(f"Error parsing {response.url}: {str(e)}")# 可以选择重新调度或记录错误def process_response(self, response):"""处理响应数据"""# 数据提取for item in self.extract_items(response):# 数据验证if self.validate_item(item):yield item# 链接提取与优先级设置for link, priority in self.extract_prioritized_links(response):yield scrapy.Request(url=link,callback=self.parse,priority=priority,meta={'dont_retry': False,'download_timeout': 30,'retry_times': 3})def extract_prioritized_links(self, response):"""提取带优先级的链接"""links = []# 高优先级:重要页面for link in response.css('.important-link::attr(href)').getall():links.append((response.urljoin(link), 10))# 中优先级:普通内容页for link in response.css('.content-link::attr(href)').getall():links.append((response.urljoin(link), 5))# 低优先级:分页链接for link in response.css('.pagination a::attr(href)').getall():links.append((response.urljoin(link), 1))return linksdef validate_item(self, item):"""验证数据项"""required_fields = ['title', 'url']return all(field in item and item[field] for field in required_fields)
集群管理与监控
Kafka Monitor配置
Kafka Monitor是集群的管理中心:
# kafka-monitor/settings.py
import os# Kafka设置
KAFKA_HOSTS = os.getenv('KAFKA_HOSTS', 'localhost:9092')
KAFKA_INCOMING_TOPIC = 'demo.incoming'
KAFKA_OUTGOING_TOPIC = 'demo.outgoing_firehose'# Redis设置
REDIS_HOST = os.getenv('REDIS_HOST', 'localhost')
REDIS_PORT = int(os.getenv('REDIS_PORT', 6379))
REDIS_DB = int(os.getenv('REDIS_DB', 0))# 监控设置
STATS_TOTAL = True
STATS_RESPONSE_CODES = True
STATS_CYCLE = 5 # 统计周期(秒)# 插件配置
PLUGINS = {'scrapy_cluster.monitor.stats_monitor.StatsMonitor': 100,'scrapy_cluster.monitor.stop_monitor.StopMonitor': 200,'scrapy_cluster.monitor.expire_monitor.ExpireMonitor': 300,
}
启动Monitor服务
# 启动Kafka Monitor
from kafka import KafkaConsumer
from scrapy_cluster.monitor import KafkaMonitorclass CustomKafkaMonitor(KafkaMonitor):def __init__(self):super(CustomKafkaMonitor, self).__init__()self.setup_consumers()def setup_consumers(self):"""设置Kafka消费者"""self.consumer = KafkaConsumer('demo.incoming',bootstrap_servers=self.settings['KAFKA_HOSTS'],auto_offset_reset='latest',value_deserializer=lambda x: json.loads(x.decode('utf-8')))def process_messages(self):"""处理消息"""for message in self.consumer:try:data = message.valueself.handle_request(data)except Exception as e:self.logger.error(f"Error processing message: {e}")def handle_request(self, data):"""处理爬取请求"""if 'url' not in data:self.logger.warning("Missing URL in request")return# 构建Scrapy Requestrequest_data = {'url': data['url'],'spider': data.get('spider', 'distributed'),'callback': 'parse','meta': data.get('meta', {}),'priority': data.get('priority', 0)}# 推送到Redis队列self.push_to_redis(request_data)def push_to_redis(self, request_data):"""推送请求到Redis队列"""spider_name = request_data['spider']queue_key = f"spider:{spider_name}:queue"self.redis_conn.lpush(queue_key, json.dumps(request_data))self.logger.info(f"Pushed request to {queue_key}")# 启动监控器
if __name__ == '__main__':monitor = CustomKafkaMonitor()monitor.run()
REST API接口
# rest/api.py
from flask import Flask, request, jsonify
import redis
import jsonapp = Flask(__name__)
redis_client = redis.Redis(host='localhost', port=6379, db=0)@app.route('/submit', methods=['POST'])
def submit_request():"""提交爬取请求"""try:data = request.get_json()# 验证请求数据if 'url' not in data:return jsonify({'error': 'Missing URL'}), 400# 设置默认值spider = data.get('spider', 'distributed')priority = data.get('priority', 0)# 构建请求crawl_request = {'url': data['url'],'spider': spider,'callback': 'parse','meta': data.get('meta', {}),'priority': priority,'timestamp': time.time()}# 推送到队列queue_key = f"spider:{spider}:queue"redis_client.lpush(queue_key, json.dumps(crawl_request))return jsonify({'success': True,'message': 'Request submitted successfully','spider': spider,'url': data['url']})except Exception as e:return jsonify({'error': str(e)}), 500@app.route('/stats/<spider>', methods=['GET'])
def get_stats(spider):"""获取爬虫统计信息"""try:stats_key = f"stats:{spider}"stats_data = redis_client.hgetall(stats_key)# 转换数据类型stats = {}for key, value in stats_data.items():key = key.decode('utf-8')value = value.decode('utf-8')try:stats[key] = int(value)except ValueError:stats[key] = valuereturn jsonify(stats)except Exception as e:return jsonify({'error': str(e)}), 500@app.route('/queue/<spider>', methods=['GET'])
def get_queue_info(spider):"""获取队列信息"""try:queue_key = f"spider:{spider}:queue"queue_length = redis_client.llen(queue_key)# 获取最近的几个请求recent_requests = []for i in range(min(5, queue_length)):request_data = redis_client.lindex(queue_key, i)if request_data:recent_requests.append(json.loads(request_data))return jsonify({'spider': spider,'queue_length': queue_length,'recent_requests': recent_requests})except Exception as e:return jsonify({'error': str(e)}), 500if __name__ == '__main__':app.run(host='0.0.0.0', port=5000, debug=True)
性能优化与最佳实践
集群性能调优
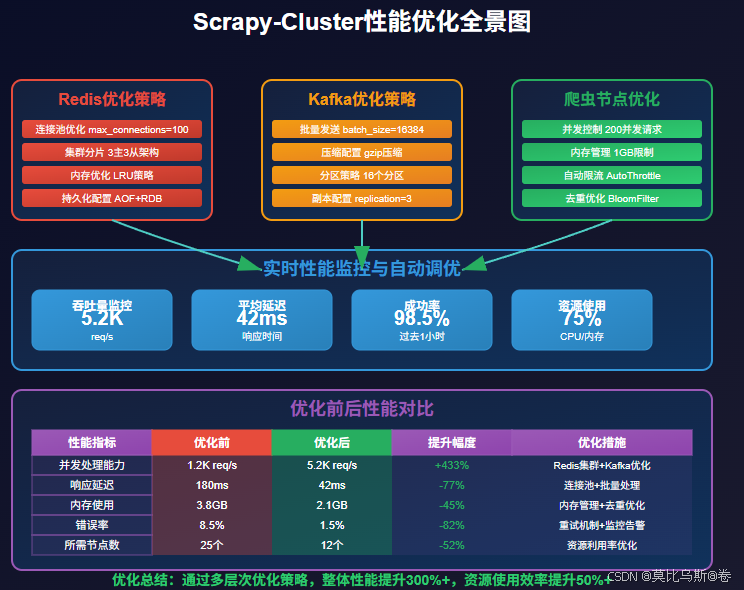
1. Redis优化:
# Redis连接池配置
REDIS_PARAMS = {'host': 'redis-cluster-host','port': 6379,'db': 0,'max_connections': 100,'socket_connect_timeout': 5,'socket_timeout': 5,'retry_on_timeout': True
}# 使用Redis集群
REDIS_CLUSTERS = [{'host': 'redis-1', 'port': 6379},{'host': 'redis-2', 'port': 6379},{'host': 'redis-3', 'port': 6379}
]
2. Kafka优化:
# Kafka生产者配置
KAFKA_PRODUCER_CONFIGS = {'bootstrap_servers': ['kafka1:9092', 'kafka2:9092'],'batch_size': 16384,'linger_ms': 10,'buffer_memory': 33554432,'acks': 1,'retries': 3,'compression_type': 'gzip'
}# Kafka消费者配置
KAFKA_CONSUMER_CONFIGS = {'auto_offset_reset': 'latest','enable_auto_commit': True,'auto_commit_interval_ms': 1000,'session_timeout_ms': 30000,'max_poll_records': 500,'fetch_min_bytes': 1024
}
3. 爬虫节点优化:
# settings.py 性能优化配置
# 并发控制
CONCURRENT_REQUESTS = 200
CONCURRENT_REQUESTS_PER_DOMAIN = 20
REACTOR_THREADPOOL_MAXSIZE = 20# 下载优化
DOWNLOAD_DELAY = 0.1
RANDOMIZE_DOWNLOAD_DELAY = 0.5
DOWNLOAD_TIMEOUT = 30
RETRY_TIMES = 3# 内存优化
MEMUSAGE_ENABLED = True
MEMUSAGE_LIMIT_MB = 1024
MEMUSAGE_WARNING_MB = 512# 去重优化
DUPEFILTER_DEBUG = False
DUPEFILTER_CLASS = 'scrapy_cluster.dupefilter.RFPDupeFilter'# AutoThrottle
AUTOTHROTTLE_ENABLED = True
AUTOTHROTTLE_START_DELAY = 0.1
AUTOTHROTTLE_MAX_DELAY = 10
AUTOTHROTTLE_TARGET_CONCURRENCY = 10.0
监控与告警
# 自定义监控中间件
class ClusterMonitoringMiddleware:def __init__(self, stats, settings):self.stats = statsself.settings = settingsself.redis_client = redis.Redis(host=settings.get('REDIS_HOST'),port=settings.get('REDIS_PORT'),db=settings.get('REDIS_DB'))@classmethoddef from_crawler(cls, crawler):return cls(crawler.stats, crawler.settings)def process_request(self, request, spider):"""请求处理监控"""self.stats.inc_value('cluster/requests_total')# 记录节点信息node_id = socket.gethostname()self.redis_client.hincrby(f'nodes:{node_id}', 'requests', 1)def process_response(self, request, response, spider):"""响应处理监控"""self.stats.inc_value('cluster/responses_total')self.stats.inc_value(f'cluster/responses_{response.status}')# 记录响应时间if hasattr(request, 'meta') and 'download_latency' in request.meta:latency = request.meta['download_latency']self.stats.max_value('cluster/max_latency', latency)self.stats.min_value('cluster/min_latency', latency)return responsedef process_exception(self, request, exception, spider):"""异常处理监控"""self.stats.inc_value('cluster/exceptions_total')self.stats.inc_value(f'cluster/exceptions_{type(exception).__name__}')# 记录异常详情exception_data = {'url': request.url,'exception': str(exception),'timestamp': time.time(),'spider': spider.name}self.redis_client.lpush('cluster:exceptions', json.dumps(exception_data))
部署与运维
Docker化部署
# Dockerfile.crawler
FROM python:3.8-slimWORKDIR /app# 安装依赖
COPY requirements.txt .
RUN pip install -r requirements.txt# 复制代码
COPY crawler/ ./crawler/
COPY kafka-monitor/ ./kafka-monitor/# 设置环境变量
ENV PYTHONPATH=/app
ENV REDIS_HOST=redis
ENV KAFKA_HOSTS=kafka:9092# 启动命令
CMD ["python", "-m", "scrapy", "crawl", "distributed"]
docker-compose.yml:
version: '3.8'services:redis:image: redis:6-alpineports:- "6379:6379"command: redis-server --appendonly yesvolumes:- redis_data:/datakafka:image: confluentinc/cp-kafka:latestports:- "9092:9092"environment:KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka:9092KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1depends_on:- zookeeperzookeeper:image: confluentinc/cp-zookeeper:latestports:- "2181:2181"environment:ZOOKEEPER_CLIENT_PORT: 2181ZOOKEEPER_TICK_TIME: 2000crawler:build:context: .dockerfile: Dockerfile.crawlerdepends_on:- redis- kafkadeploy:replicas: 3environment:REDIS_HOST: redisKAFKA_HOSTS: kafka:9092monitor:build:context: .dockerfile: Dockerfile.monitordepends_on:- redis- kafkaenvironment:REDIS_HOST: redisKAFKA_HOSTS: kafka:9092api:build:context: .dockerfile: Dockerfile.apiports:- "5000:5000"depends_on:- redisenvironment:REDIS_HOST: redisvolumes:redis_data:
Kubernetes部署
# k8s/scrapy-cluster.yaml
apiVersion: apps/v1
kind: Deployment
metadata:name: scrapy-crawlerlabels:app: scrapy-crawler
spec:replicas: 5selector:matchLabels:app: scrapy-crawlertemplate:metadata:labels:app: scrapy-crawlerspec:containers:- name: crawlerimage: scrapy-cluster:latestenv:- name: REDIS_HOSTvalue: "redis-service"- name: KAFKA_HOSTSvalue: "kafka-service:9092"resources:requests:memory: "512Mi"cpu: "500m"limits:memory: "1Gi"cpu: "1000m"livenessProbe:exec:command:- python- -c- "import redis; r=redis.Redis(host='redis-service'); r.ping()"initialDelaySeconds: 30periodSeconds: 10
---
apiVersion: v1
kind: Service
metadata:name: scrapy-api-service
spec:selector:app: scrapy-apiports:- port: 80targetPort: 5000type: LoadBalancer
监控告警
# monitoring/alerting.py
import time
import json
import smtplib
from email.mime.text import MIMETextclass ClusterAlerting:def __init__(self, redis_client, email_config):self.redis = redis_clientself.email_config = email_configself.alert_rules = {'high_error_rate': {'threshold': 0.1, # 10%错误率'window': 300, # 5分钟窗口'condition': 'gt'},'low_throughput': {'threshold': 100, # 每分钟少于100个请求'window': 300,'condition': 'lt'},'queue_backlog': {'threshold': 10000, # 队列积压超过1万'window': 60,'condition': 'gt'}}def check_alerts(self):"""检查告警条件"""alerts = []for rule_name, rule_config in self.alert_rules.items():if self.evaluate_rule(rule_name, rule_config):alerts.append(rule_name)if alerts:self.send_alerts(alerts)def evaluate_rule(self, rule_name, config):"""评估告警规则"""if rule_name == 'high_error_rate':return self.check_error_rate(config)elif rule_name == 'low_throughput':return self.check_throughput(config)elif rule_name == 'queue_backlog':return self.check_queue_backlog(config)return Falsedef check_error_rate(self, config):"""检查错误率"""# 从Redis获取统计数据total_requests = int(self.redis.get('stats:total_requests') or 0)total_errors = int(self.redis.get('stats:total_errors') or 0)if total_requests == 0:return Falseerror_rate = total_errors / total_requestsreturn error_rate > config['threshold']def send_alerts(self, alerts):"""发送告警通知"""subject = f"Scrapy-Cluster Alert: {', '.join(alerts)}"body = f"The following alerts were triggered:\n\n"for alert in alerts:body += f"- {alert}\n"body += f"\nTime: {time.strftime('%Y-%m-%d %H:%M:%S')}"self.send_email(subject, body)def send_email(self, subject, body):"""发送邮件"""msg = MIMEText(body)msg['Subject'] = subjectmsg['From'] = self.email_config['from']msg['To'] = self.email_config['to']server = smtplib.SMTP(self.email_config['smtp_host'])server.send_message(msg)server.quit()
实战案例:电商数据采集集群
让我们通过一个实际的电商数据采集案例来演示Scrapy-Cluster的应用:
# 电商数据采集Spider
class EcommerceClusterSpider(ClusterSpider):name = 'ecommerce_cluster'def __init__(self, *args, **kwargs):super(EcommerceClusterSpider, self).__init__(*args, **kwargs)self.setup_rate_limiting()def setup_rate_limiting(self):"""设置限流规则"""self.custom_settings = {'DOWNLOAD_DELAY': 1,'RANDOMIZE_DOWNLOAD_DELAY': 0.5,'CONCURRENT_REQUESTS_PER_DOMAIN': 5,'AUTOTHROTTLE_ENABLED': True,'AUTOTHROTTLE_START_DELAY': 1,'AUTOTHROTTLE_MAX_DELAY': 10,'AUTOTHROTTLE_TARGET_CONCURRENCY': 2.0}def parse(self, response):"""解析商品列表页"""# 提取商品链接for product_url in response.css('.product-item a::attr(href)').getall():yield scrapy.Request(url=response.urljoin(product_url),callback=self.parse_product,priority=5,meta={'category': response.meta.get('category', 'unknown')})# 处理分页next_page = response.css('.pagination .next::attr(href)').get()if next_page:yield scrapy.Request(url=response.urljoin(next_page),callback=self.parse,priority=1,meta=response.meta)def parse_product(self, response):"""解析商品详情页"""product = {'url': response.url,'name': response.css('h1.product-title::text').get(),'price': self.extract_price(response),'description': response.css('.product-description::text').getall(),'images': response.css('.product-images img::attr(src)').getall(),'category': response.meta.get('category'),'specs': self.extract_specs(response),'reviews_count': self.extract_reviews_count(response),'rating': self.extract_rating(response),'stock_status': response.css('.stock-status::text').get(),'timestamp': time.time(),'spider': self.name}# 数据验证if self.validate_product(product):yield product# 提取评论链接reviews_url = response.css('.reviews-link::attr(href)').get()if reviews_url:yield scrapy.Request(url=response.urljoin(reviews_url),callback=self.parse_reviews,priority=3,meta={'product_url': response.url})def parse_reviews(self, response):"""解析商品评论"""for review in response.css('.review-item'):yield {'product_url': response.meta['product_url'],'reviewer': review.css('.reviewer-name::text').get(),'rating': review.css('.review-rating::attr(data-rating)').get(),'content': review.css('.review-content::text').get(),'date': review.css('.review-date::text').get(),'helpful_count': review.css('.helpful-count::text').re_first(r'\d+'),'timestamp': time.time(),'type': 'review'}def extract_price(self, response):"""提取价格信息"""price_text = response.css('.price .current::text').get()if price_text:return float(re.findall(r'[\d.]+', price_text)[0])return Nonedef extract_specs(self, response):"""提取商品规格"""specs = {}for spec in response.css('.specs-table tr'):key = spec.css('td:first-child::text').get()value = spec.css('td:last-child::text').get()if key and value:specs[key.strip()] = value.strip()return specsdef validate_product(self, product):"""验证商品数据"""required_fields = ['name', 'price', 'url']return all(product.get(field) for field in required_fields)
集群部署脚本
#!/bin/bash
# deploy_cluster.sh# 设置变量
CLUSTER_SIZE=10
REDIS_HOST="redis-cluster.internal"
KAFKA_HOSTS="kafka1:9092,kafka2:9092,kafka3:9092"echo "部署Scrapy-Cluster集群..."# 1. 启动Redis集群
echo "启动Redis集群..."
docker run -d --name redis-cluster \--network scrapy-net \-p 6379:6379 \redis:6-alpine redis-server --appendonly yes# 2. 启动Kafka集群
echo "启动Kafka集群..."
docker-compose -f kafka-cluster.yml up -d# 3. 启动Monitor服务
echo "启动Monitor服务..."
docker run -d --name kafka-monitor \--network scrapy-net \-e REDIS_HOST=$REDIS_HOST \-e KAFKA_HOSTS=$KAFKA_HOSTS \scrapy-cluster:monitor# 4. 启动API服务
echo "启动API服务..."
docker run -d --name scrapy-api \--network scrapy-net \-p 5000:5000 \-e REDIS_HOST=$REDIS_HOST \scrapy-cluster:api# 5. 启动爬虫节点
echo "启动 $CLUSTER_SIZE 个爬虫节点..."
for i in $(seq 1 $CLUSTER_SIZE); dodocker run -d --name crawler-$i \--network scrapy-net \-e REDIS_HOST=$REDIS_HOST \-e KAFKA_HOSTS=$KAFKA_HOSTS \-e NODE_ID=$i \scrapy-cluster:crawlerecho "启动爬虫节点 $i"
doneecho "集群部署完成!"
echo "API地址: http://localhost:5000"
echo "Redis连接: $REDIS_HOST:6379"
总结与最佳实践
Scrapy-Cluster为我们提供了一个强大的分布式爬虫解决方案,通过合理的架构设计和配置优化,可以构建出高性能、高可用的大规模数据采集系统。
核心要点回顾
- 架构设计:Redis作为队列中心,Kafka处理数据流,多节点协同工作
- 性能优化:合理配置并发数、延时、去重等参数
- 监控告警:实时监控集群状态,及时发现和处理问题
- 部署运维:使用容器化技术简化部署和管理
最佳实践建议
- 渐进式扩展:从小规模开始,根据需求逐步扩展集群规模
- 资源隔离:不同的爬虫项目使用不同的Redis数据库和Kafka Topic
- 故障恢复:设计完善的故障恢复机制和数据备份策略
- 性能监控:建立完善的监控体系,及时发现性能瓶颈
通过Scrapy-Cluster,我们可以轻松地将单机爬虫扩展为分布式集群,处理TB级别的数据采集任务,为大数据分析和商业决策提供强有力的数据支撑。
参考资料
- Scrapy-Cluster官方文档
- Redis集群部署指南
- Apache Kafka分布式流处理
- Scrapy分布式爬虫最佳实践
扩展阅读
- 深入学习Redis高可用架构设计
- 探索Kafka在大数据处理中的应用
- 研究Kubernetes在爬虫集群中的应用
- 了解更多分布式系统设计原则