卷积神经网络学习
- 卷积神经网络中知识点
- 感受野 源数据或图片中单次取出-转换(卷积)的其中一小片区域
- 步长 感受野每次移动的距离,卷积核通过感受野提取当前小区域的特征后,移动到下一个小区域上继续提取特征,每次移动的距离叫做感受野。
- 卷积核 与从感受野取出的数据进行乘积的一个固定参数,类似MLP中的权重参数
- 通道数 卷积核的个数,有时候源数据是有多组数据组成,例如图片根据RGB颜色一般3个图层分开进行分析,这时如果卷积核可以只有一个,用相同的权重去处理数据,一个卷积核也称为单通道卷积,但为了提取的特征更加精准,一般至少会有3个卷积核,分别处理不同的图层,多个卷积核也称为多通道卷积,通道数不一定与源数据组数一致,也经常会有远大于源数据组数的情况,例如每组数据分别经过8、16、128等数次的卷积,得到8、16、128组特征数据,这里8、16、128数量随意,看自己需要提取多少维度的特征数据,3、5层都行
- 下采样 一是为了减少计算量,避免过拟合,二是增大感受野,是后续的卷积核能感受、学习到更全局的信息,可以通过池化操作或者增大步长来实现,22的池化操作就是22的方格内只保留一个特征数据,取最大称为Max-Pooling,取平均称为Average-Pooling;增大步长就是由一般的步长为1,增大为2、3…之类
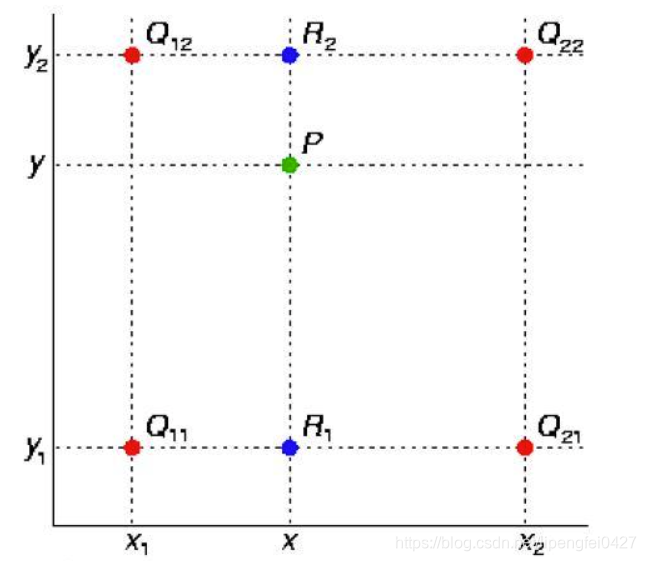
- 上采样 图像经过特征提取后,输出尺寸往往会越来越小,而有时需要将图片恢复到原尺寸进行进一步计算,这个将图像由小分辨率放大到打分辨率的操作称为上采样,一般有插值、转置卷积、Max-Unpooling三种方式,插值有最邻近插值(目标坐标x除以缩放比例,目标坐标y除以缩放比例,根据计算后的x,y去原图中找最近的像素坐标点),单线性插值(图片放大后,需要插入的像素点根据最近的,已知的同行或同列的两个像素点,同行的根据列数与RGB值,同列的根据行数与RGB值带入二元函数RGB =ax+b,求得ab值,带入未知像素点的行数或列数,求得rgb),双线性插值(如下图,先找打原图最近的4个像素点,根据已知的Q12、Q22求出R2,Q11、Q21求出R1,根据R1、R2求出P点的像素值)
现有原图像素为ab,需要经过缩放后变成mn,在寻找原图最近像素点中,X方向的缩放比例Xr = m/a 目标坐标xt,计算出Xs = Xt * Xr;同理 Ys = Yt * Yr,但是仔细一想有问题,例如33的源图片缩放为3030目标图片,根据该等式目标图片的(1,20)像素点对应原图的(1,2),他俩RGB一样,但其实源图的(1,2)映射到目标图的(1,15)或(1,16)才是等比缩放,根据网上的信息目前matlab和openCV的坐标计算公式为:
int Xt =(Xs+0.5)*m/a - 0.5
int Yt=(Ys+0.5)*n/b - 0.5
我自己琢磨的时候发现,想要各个像素点等比缩放,其实就是间距一定的等比数列。1,2,3放大十倍就是1,15,30;1,2,3,4放大十倍就是1,13,26,40,宗旨就是间距尽量保持一样,各像素点均匀填充到缩放后的图片中,要想间距一样,只需要用间距总数(m-1)/间距个数(a-1),可得公式:
int Xt=(Xs - 1) * (m-1)/(a-1) + 1
int Yt=(Ys - 1) * (n-1)/(b-1) + 1
这里都是从源图坐标得到目标图像素坐标的公式,要从目标图坐标计算原图坐标,只要将等式变换一下就行,这里减1我自己感觉比减0.5效果更好,也更清晰,不知道为啥都用减0.5。
双线性插值比较重要,平时的缩放图片也会用,剩下了转置卷积顾名思义与卷积相反,卷积是通过较大的感受野提取较小的特征,转置卷积就是通过较小的特征映射出较大的数据来,例如一格映射为3*3,对于输入的特征间隔之间填充0;Max-Unpooling也与池化基本相反,在pooling操作时记录下取值的位置,unpooling将值提填到之前位置,剩下的补零
- Batch-Normalization(批量归一化) 神经网络模型一般分为多层,当模型学习数据时,数据通过上层一步步传到下层,然后输出预测结果,这是就是正向传播-forward;将预测结果与真实结果做对比,根据对比结果修改各隐藏层的损失函数,权重参数等,这就是反向传播-backward,在反向传播过程中,一般由输出层->较下层->较上层->输入的方向开始修改、优化各个参数,一般较上层的梯度较大、参数也较大,较下层参数一变,较上层也得跟着变,而且上层数值变化更大,导致需要重新学习很多次,收敛变慢,BN就是为了优化这个现象而设计的,通过随机抽取样本中小批量的样本,小批量样本中,每个样本有多个参数,合起来就是一个矩阵(或者说二维数组),将数组的每一列求出方差和均值,在训练第二个batch的时候,将上一batch计算出的方差和均值乘上系数,加上本批次的均值*权重得到本批次的均值新标准(这里计算公式有多种,思路是这样),根据新均值对数据进行处理,每批次对权重和系数进行学习和修改,这就是批量归一化。
乍一想,这里的批量归一化类似于正则化,对数据做出些约束,最初的论文也是想的通过它来减少内部协变量的转移,但我自己都会感觉别扭,比如数值正常波动较大的特征,取小批量的均值对数值做约束,可能就导致数据被预期之外的改动,这导致数据不准确,如果数值正常波动较小的特征,可能均值差不多,批量归一化对数据基本没改动,对模型影响不大,可能只适用于特征数值正常情况下波动不大,然后有小部分样本异常的多大或过小的场景才适用,这种异常样本多了也不行,多了估计也会导致归一化的值偏离正常值,那这个额外的为每个特征,再每层网络添加两个参数的做法就没意义,还不如提前清洗掉异常数据,后面有论文指出BN可能通过向每个小批量里加入噪声来控制模型复杂度,我也感觉后面提出的观点是对的,可以理解为BN不是规范数据让模型更快收敛,而是人工的打乱一些数据值,加入数据噪声,反而意外的导致模型收敛更快!!!BN在数据值正常分布的情况下,对数值进行归一化处理,就相当于直接向最标准的值做出靠近,可以加速收敛速度,但这样不会提升模型精度。可能在可接受的范围内,损失部分精度,从而提高速度。
- 卷积神经网络是以卷积核作为权重,MLP为结构的深度学习网络算法,适用于图像处理