01数据结构-图的概念和图的存储结构
01数据结构-图的概念和图的存储结构
- 前言
- 1.图的概念
- 1.1图的基本概念
- 1.2图的基本术语
- 2.图的存储
- 2.1邻接矩阵
- 2.2邻接表
- 2.3十字链表
- 2.4邻接多重表
- 2.5边集数组
前言
在线性表中,每个元素之间只有一个直接前驱和一个直接后继。在树形结构中,数据元素之间是层次关系,并且每一层上的数据元素可能和下一层中多个元素相关,但只能和上一层中一个元素相关。但这仅仅都只是一对一,一对多的简单模型,如果要描述多对多的复杂关系就需要图数据结构了
1.图的概念
1.1图的基本概念
图G是由两个集合V和E组成,记为G = (V,E),其中V是顶点的有限非空集合,E是V中顶点偶对的有限集,这些顶点偶对称之为边(弧)。
V是一个有限的的非空集合,我们也称之为顶点集合,其元素称之为顶点或者点。V = {v1,v2,v3,v4,v5}。我们用|V|来表示顶点的数目。
E是由V中的点组成的无序对构成的集合的边集,其元素称之为边,且同一点对在E中可以重复出现多次(如果比标上边的重数的话,每一点对只要出现一次就行了)。用|E|表示边数。
我们的算法就是实现这两个集合的之间的逻辑完备性。
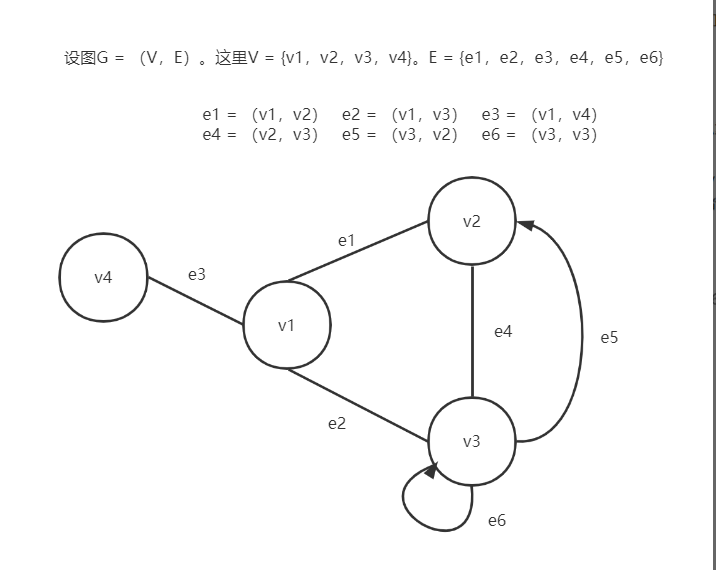
图1
1.2图的基本术语
-
简单图
- 在图结构中,若不存在顶点到其自身的边,且同一条边不重复出现,则称这样的图为简单图
-
无向图
- 在图G中,如果代表边的顶点偶对是无序的,则称G为无向图。
- 若<vi,vj>无方向性,则称此时的图为无向图,关系用(vi,vj),称之为一条边。
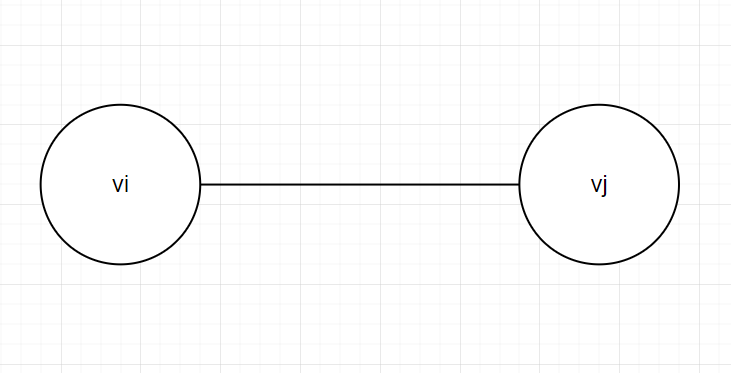
图2
-
有向图
- 在图G中,如果表示边的顶点偶对是有序的,则称G为有向图。一个图要么为无向图,要么为有向图。不存在部分有向或者部分无向的情况。
- 设vi,vj为图中的两个顶点,若关系<vi,vj>存在方向行,则称相应的图为有向图。vi为弧尾,vj为弧头。
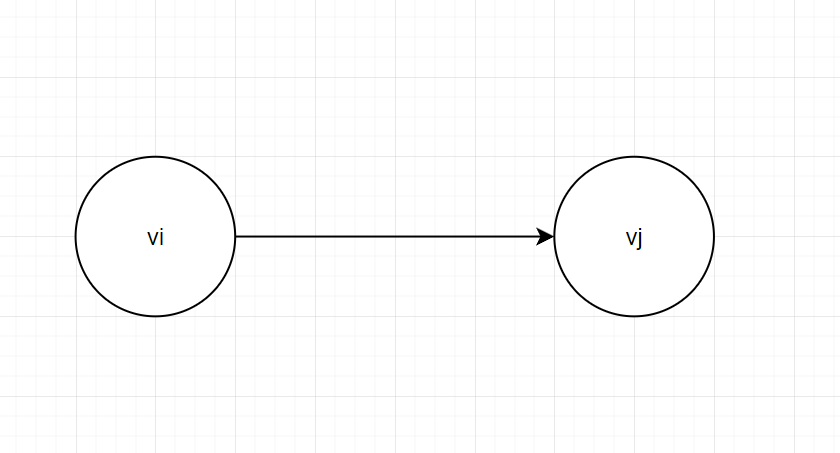
图3
-
有向无环图
- 如果有一个有向图,从任一顶点出发无法经过若干条边回到该顶点,那么它就是一个有向无环图
图4
- 如果有一个有向图,从任一顶点出发无法经过若干条边回到该顶点,那么它就是一个有向无环图
-
完全图
- 如果图中的每两个顶点之间,都存在一条边,我们就称这个图为完全图
- 完全无向图:有n(n-1)条边
- 完全有向图:有n(n-1)/2条边
- 如果图中的每两个顶点之间,都存在一条边,我们就称这个图为完全图
-
端点和邻接点
- 在一个无向图中,若存在一条边(i,j),则称顶点i和顶点j为该边的两个端点。并称它们互为邻接点。
- 在一个有向图中,若存在一条边<i,j>,则称顶点i和顶点j为该边的两个端点。它们互为邻接点。此时,顶点i为起点。顶点j为终点。
-
顶点的度,入度和出度
- 顶点的度:无向图中顶点所具备的边得数目
- 入度和出度:出度,入度使用于有向图
- 出度:一个顶点的出度为x,是指有x条边以改顶点为起点(以当前节点,出发的边的数量,就表示出度)
- 入度:一个顶点的入度为x,是指有x条边以改顶点为终点(以当前节点为终点的边,就表示入度)
-
子图
- 设有两个图G = (V,E)和G‘ = (V’,E’),若V‘是V的子集。则称G’是G的子图。
-
路径和路径长度
- 在一个图G=(V, E)中,从顶点i到顶点j的一条路径是一个顶点序列(i, i1, i2, …, im, j),若此图G是无向图,则边(i, i1), (i1, i2), …(im, j) 属于E(G);若此图是有向图,则<i, i1>, <i1, i2>, …<im, j> 属于E(G)。路径⻓度是指一条路径上经过的边的数目。若一条路径上除开始点和结束点可以相同外,其余顶点均不相同,则称此路径为简单路径。
-
回路或环
-
如果一条路径上的开始点与结束点为同一个顶点,则称此路为回路或者为环。开始点和结束点相同的简单路径被称为简单回路或者简单环。
-
如果经过图中各边一次且恰好一次的环路,称之为欧拉环路,也就是其⻓度恰好等于图中边的总数,{ C,A,B,A,D,C,D,B,C}就是一条欧拉环路。
-
如果是经过图中的各顶点一次且恰好一次的环路,称作哈密尔顿环路,其⻓度等于构成环路的边数。{C,A,D,B,C}就是一条哈密尔顿环路。
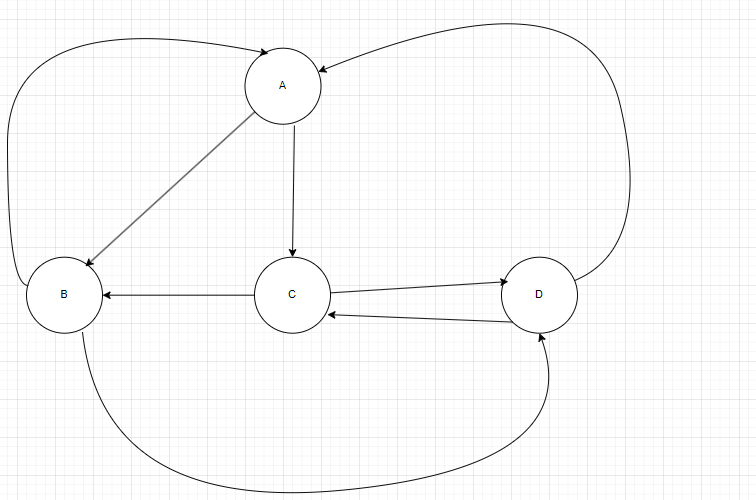
图5
-
-
连通,连通图和连通分量(无向图)
- 在无向图G中,若从顶点x到顶点y存在相互抵达的路径(直接或间接的路径),则称x和y是连通的。
- 如果G中任意两个顶点都连通,则称G为连通图,否则称为非连通图。
- 无向图G中的极大连通子图称为G的连通分量
- 对于连通图只有一个极大连通子图,就是它本身,是唯一的。
- 非连通图有多个极大连通子图。(非连通图的极大连通子图叫做连通分量,每个分量都是一个连通图)。之所以称为极大是因为如果此时加入一个不在图中的点集中的点都会导致它不再连通。
- 至于极小连通子图,首先只有连通图才有极小连通子图这个概念。就像一个四边形,四个节点四条边,其实三条边就能连通了,所以四个节点三条边,就OK了,就是在能连通的前提下,把多余的边去掉。
-
强连通图和强连通分量(有向图)
- 在有向图G中,若从顶点i到顶点j有路径,则称从顶点i到顶点j是连通的。
- 若图G中的任意两个顶点i和顶点j都连通,即从顶点i到顶点j和从顶点j到顶点i都存在路径,则称图G是强连通图。
- 有向图G中的极大强连通子图称为G的强连通分量。显然,强连通图只有一个强连通分量,即自身,非强连通图有多个强连通分量。
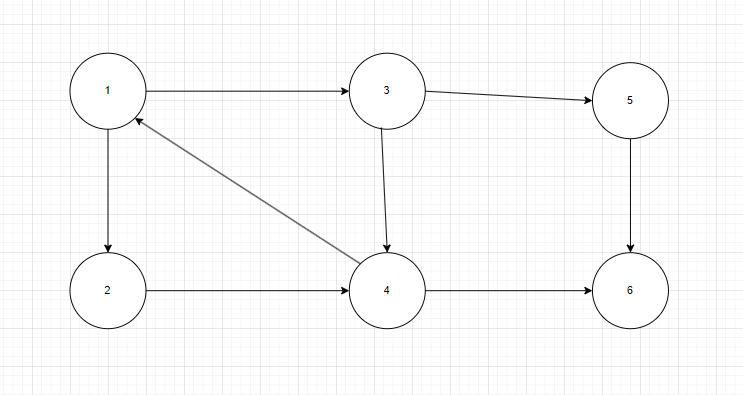
图6
如图6,强连通分量:{1,2,3,4},{5},{6}
- 稠密图,稀疏图
- 当一个图接近完全图的时候,称之为疏密图;相反,当一个图含有较少的边数,则称之为稀疏图。
- 一般对于这个边的个数,说法比较多,通常认为边小于nlogn(n是顶点的个数)的图称之为稀疏图,反之称为稠密图。
- 权和网
- 图中的每一条边都可以附有一个对应的数,这种与边相关的数称为权。权可以表示从一个顶点到另一个顶点的距离或者花费的代价。边上带有权的图称为带权图,也称之为网。
2.图的存储
刚刚介绍的都是图的一些逻辑概念,我们需要考虑的哪些逻辑行为,这些逻辑行为暂时都是空中楼阁,我们不知道怎么实现,整个图分两个集合:顶点集和边集,我们在存储上就是想办法存这两个集合。
假设现在有逻辑结构,顶点集合(a1,a2,a3),边集合(<a1,a2>,<a1,a3>,<a3,a1>,<a3,a2>),我们存储结构需要思考顶点怎么存,边怎么存,我们一般用数组来存顶点,边怎么存完全是根据顶点来确定,如果用指针来存顶点,即每个顶点存的都是指针,边就变为a指针和b指针建立关系,这种连接关系容量需求比较大,因为地址的值需要存,存完之后的关联关系比较麻烦,所以我们一般不考虑链式来存顶点。用数组存顶点的这种方式我们叫作邻接。
接下来看边怎么存。我们可以用二维数组来存,因为边就是a1边到其他所有顶点的可能性,a2边到其他所有顶点的可能性,a3边到其他所有顶点的可能性…,这不就是典型的二维矩阵嘛。如果顶点我们用数组存,边用二维矩阵存,组合起来就是图的邻接矩阵表示法。
我们还可以用链表来存边,看图7,假设我们知道了A点的地址,我们可以利用A找到B,E,D,既然能找到,意味着我们可以通过一条单向链表找到A出度的所有信息,同理B,E,C,D都可以出度的信息,我们在存顶点的时候多存个指针域来帮助我们指向出度的信息,我们把用链表存边的方式叫作表,和用数组存顶点的方式:邻接,组合起来就叫邻接表。
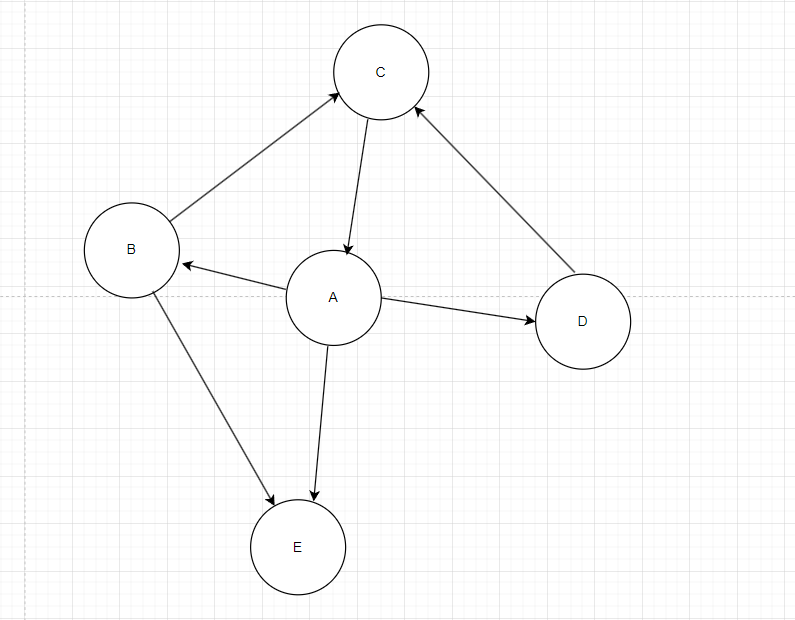
图7
2.1邻接矩阵
如图8有一个图G,我们用数组存顶点,我这里在数组中多写了几个索引,是因为可能还会有新的顶点加入,由于是下标扩容比较复杂,我们干脆在定义的时候就定义得大一些。定义一个int nums来约束空间的访问,大家不要看0,1,2…真正的其实只有一行,我这里只是让大家看下下标而已,由于是数组,我们知道空间首地址后,直接用索引0,1,2…就可以间接访问里面的真实数据a,b,c了
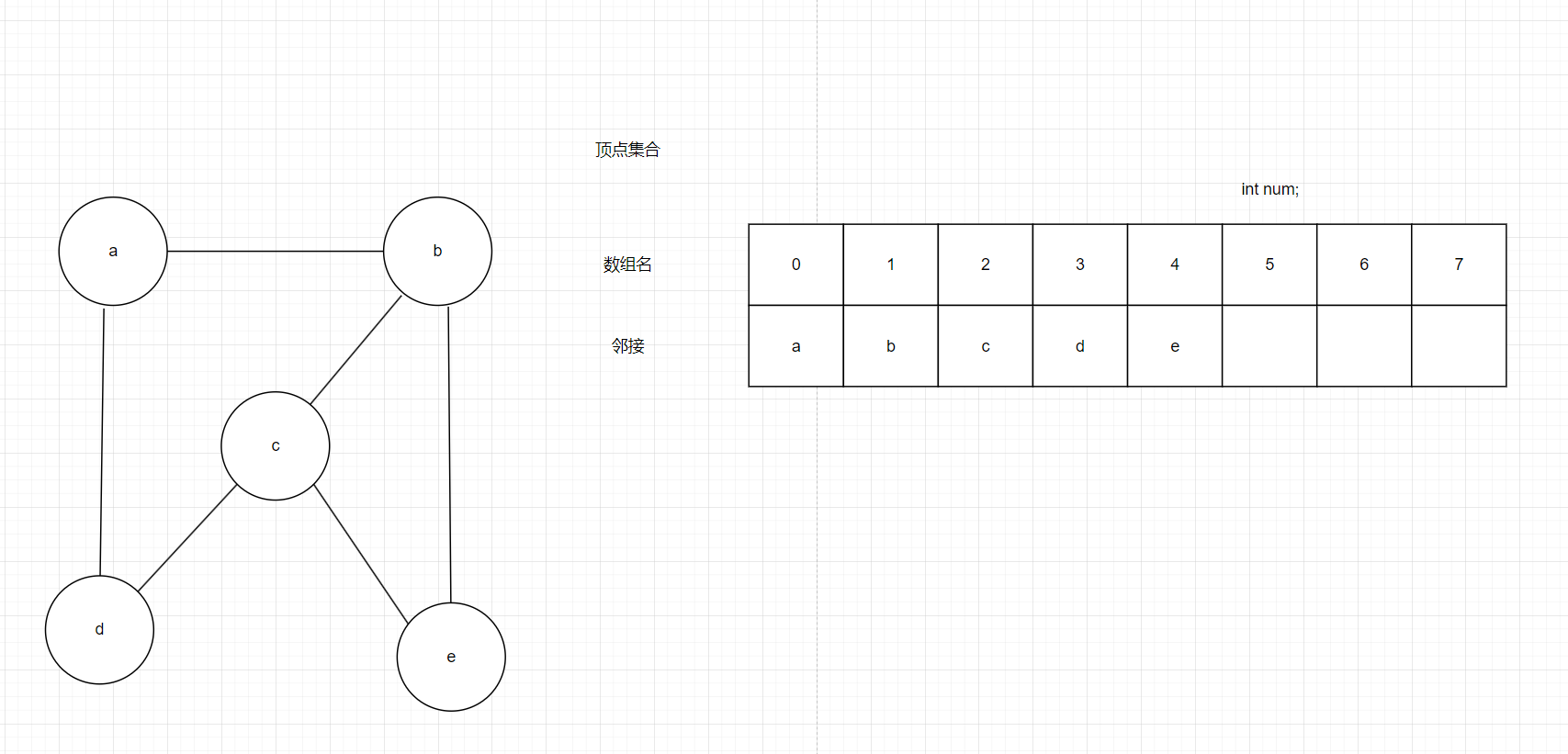
图8
如图9边用二维数组来存,要概括完所有的情况,其实就是全排列,从a边到其他所有顶点的可能性,从b边到其他所有顶点的可能性…,由于是无向图,我们发现第i行就等于第i列的元素,这也算是无向图的一个小性质吧
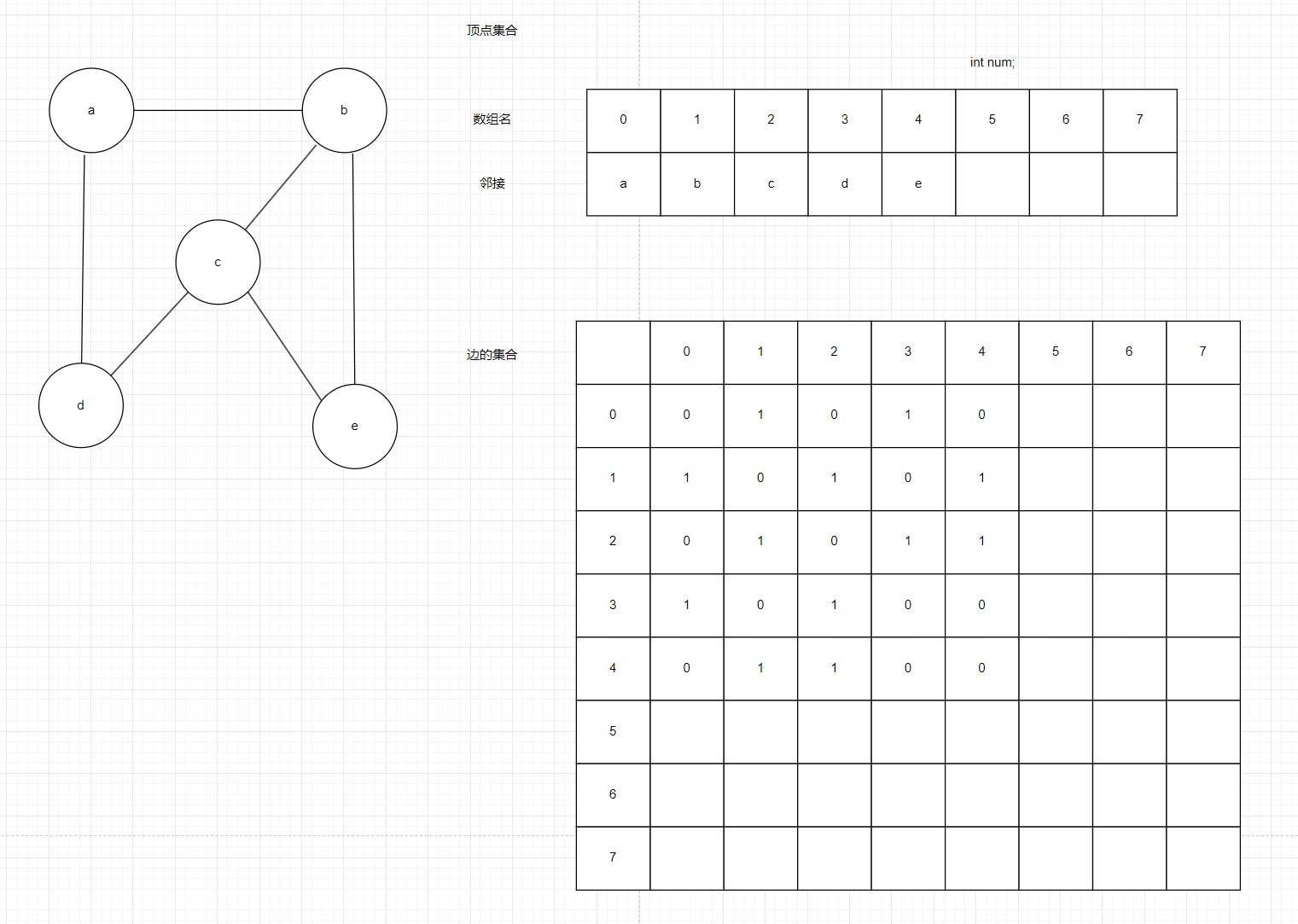
图9
邻接矩阵可以存无向图也可以存有向图,因为从图是否有方向来讲就只有这两种可能性了。
邻接矩阵优点:通用,从边组成的矩阵来看很好计算度。在无向图中计算度,遍历一行或一列,有向图中点入度(列),出度(行)
邻接矩阵缺点:无向图的边组成的矩阵是对称矩阵,有向图的边组成的矩阵是稀疏矩阵,边很少时,顶点很多时,矩阵中0出现的很频繁,会浪费空间。解决方法就是我们马上要讲的邻接表。
2.2邻接表
我们用邻接表主要都是用来存有向图,无向图就不考虑
- 正邻接表
用节点表示边,边<vi,vj>有vi,vj两个属性,这个节点需要有两个属性,一个表示弧头,一个表示弧尾,我们希望能用这个节点存目的地(弧尾),那怎么表示弧头呢?我们用一张表来说明,注意这里的index只是人为理解,真正存的数据是data,用顶点标号作为出度的弧尾,用节点来存出度的弧头,注意不要理解为A指向B,B指向D,D指向E,而是A指向B,A指向D,A指向E,且后面的顺序可以随意调换。
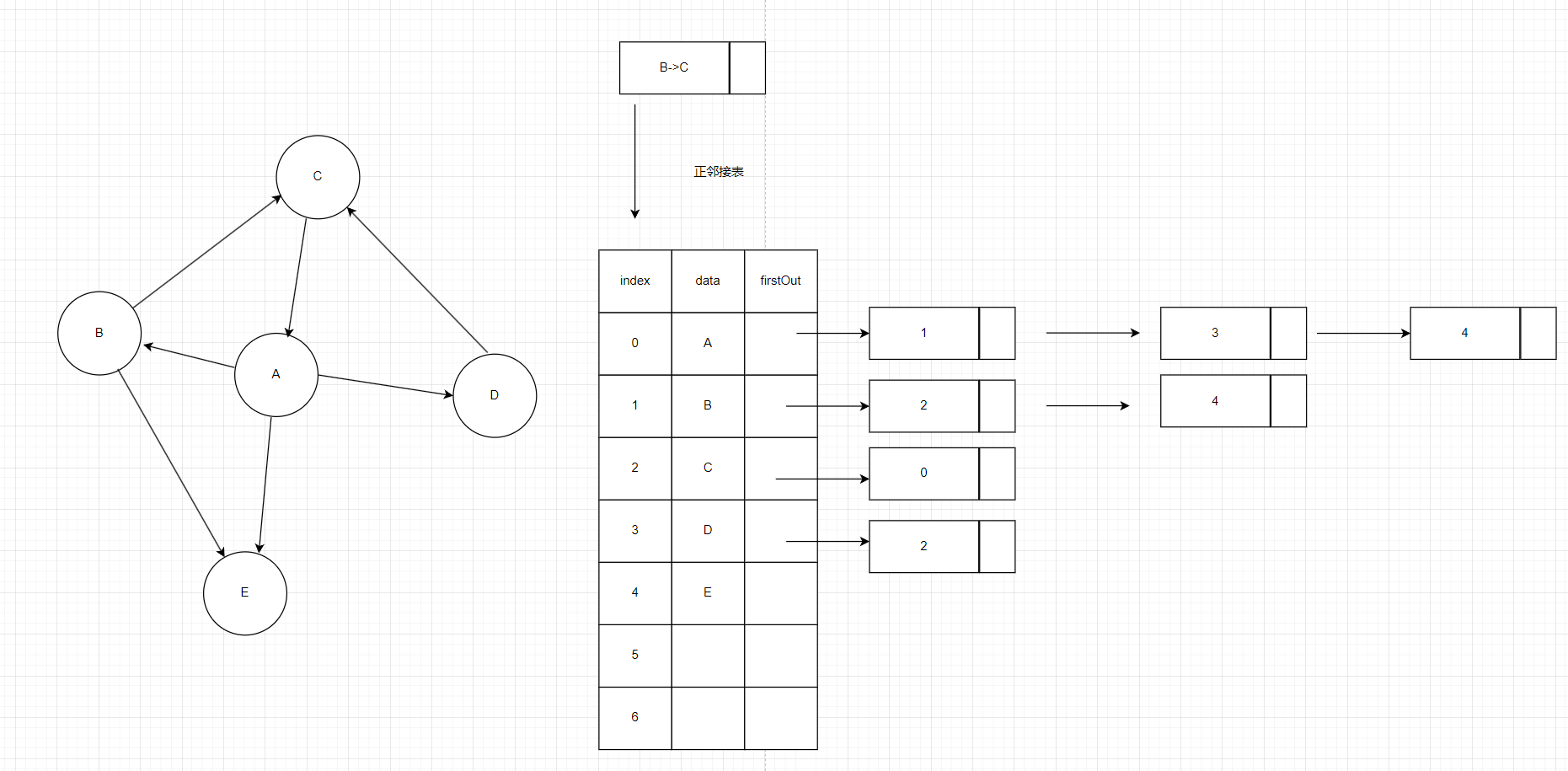
图10
正邻接矩阵的优势:空间少了,有多少条边就有多少个节点,计算出度,遍历就行。
正邻接矩阵的缺点:计算入度时,我们所有的节点都要遍历,例如我们要看E的入度,要遍历所有的节点看有几个节点等于4。为解决这个问题人们又发明了逆邻接表
- 逆邻接表
用节点表示边,用顶点标号表示入度的弧头,用firstIn表示入度的弧尾,如图11
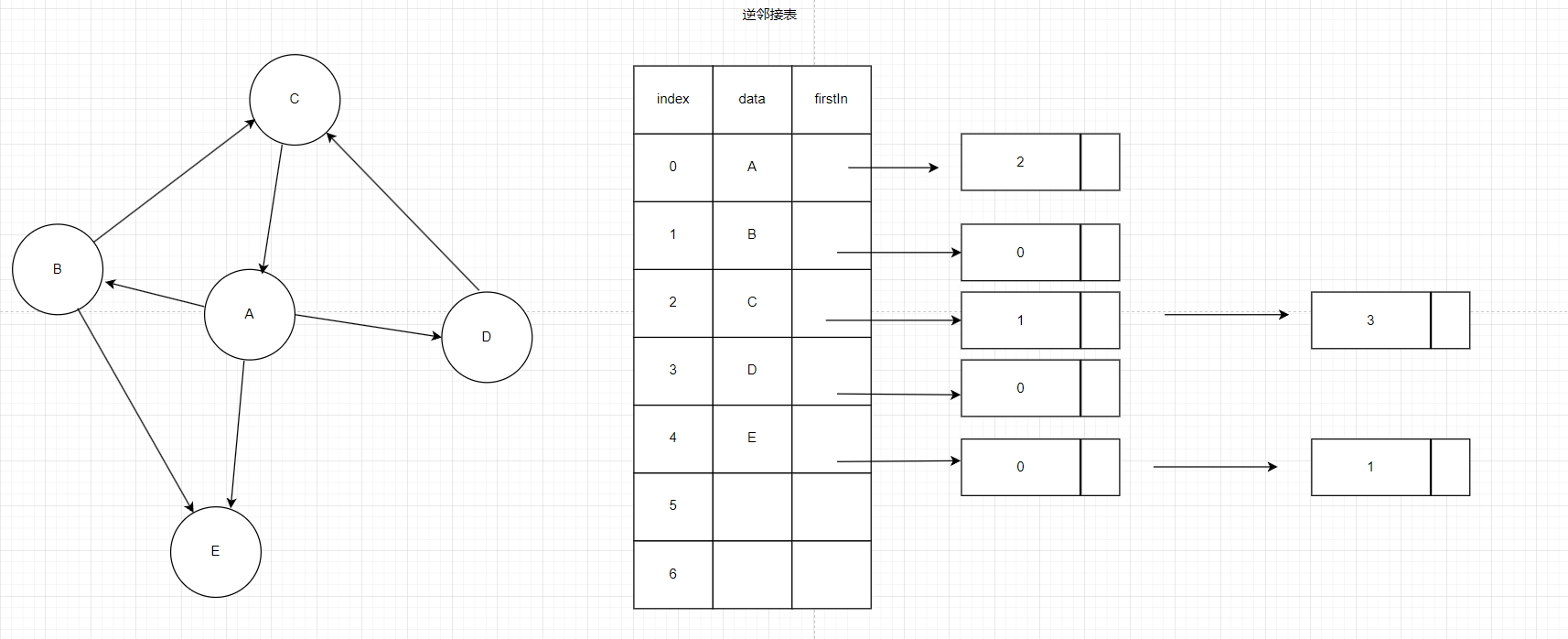
图11
逆邻接矩阵的缺点:计算出度时,我们所有的节点都要遍历。
要想又好计算出度又好计算入度,人们发明了十字链表法。
后面十字链表,邻接多重表,边集数组的图我就暂时不画全,后面的代码比较复杂,到时候再详细写一下,这里只介绍一下。
2.3十字链表
由于设计出度,入度的问题,十字链表主要用来存有向图
一个顶点的结构里面既要表示入度的首地址,也要表示出度的首地址,可以理解为正邻接表和逆邻接表的合体,因为我们依然要遵顼不能浪费空间的原则,所以有多少个节点还是要有多少条边,我们就需要改变一下节点的结构,如图12如果A指向的是tail,那么说明A是弧头指向弧尾(tNext),如果A指向的是head,那么说明A是弧尾指向弧头(hNext),这样改变每个节点的结构后,就能实现多少个节点就有多少条边了。
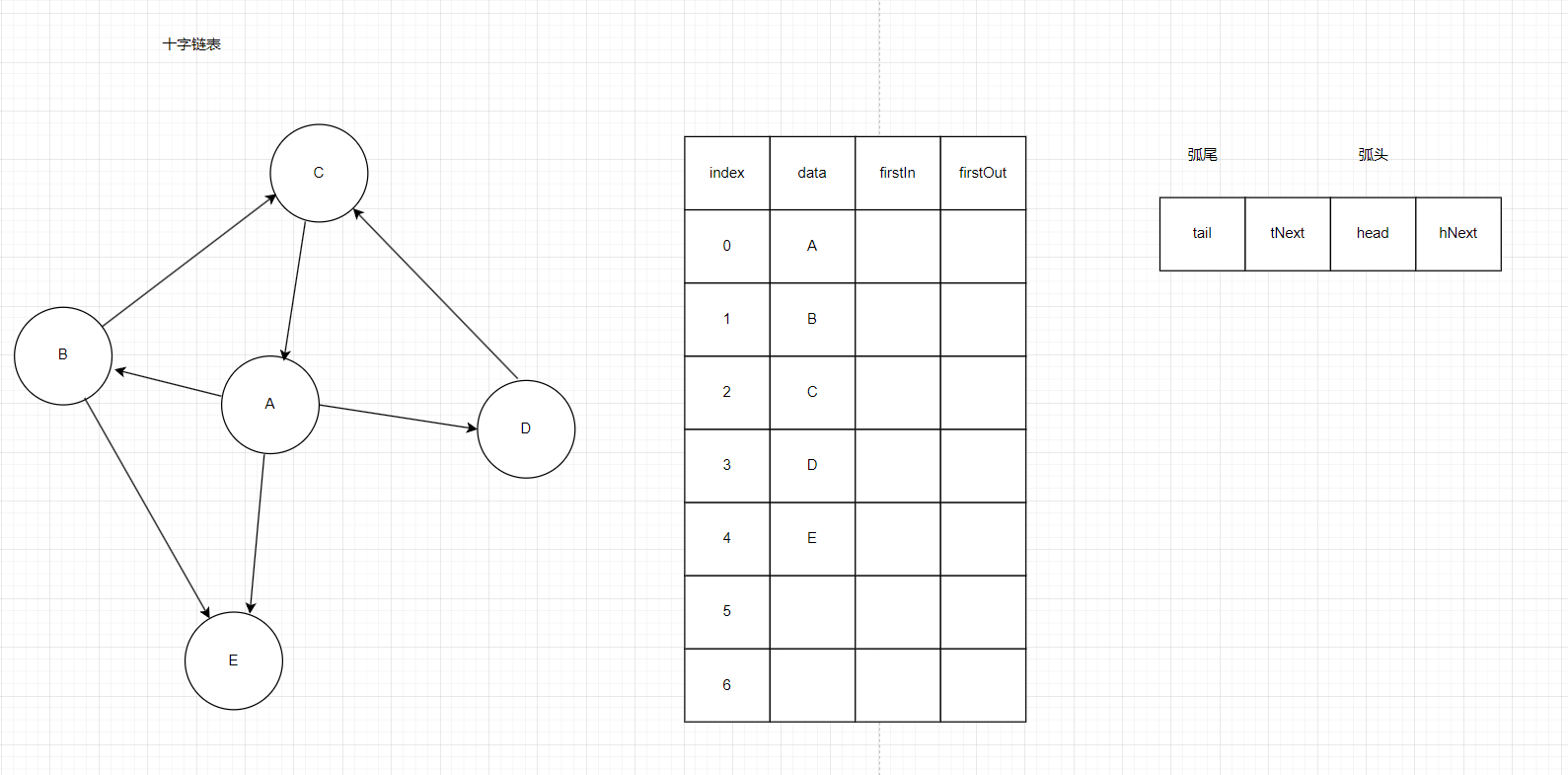
图12
2.4邻接多重表
用于无向图,有多少个节点就有多少条边节约空间,代码实现要复杂的多
a能到b,b也能到a,但是我们只保留这条边一次,我们把十字链表里面的结构做个更改,把弧尾改为顶点i,把弧头改为顶点j。iLink指向下一条依附于顶点i(即ivex所指向的顶点)的边节点。通过这个指针可以遍历所有与顶点i相连的边。jLink指向下一条依附于顶点j(即jvex所指向的顶点)的边节点。通过这个指针可以遍历所有与顶点j相连的边。
b能到c,那以b出发的jLink会到下一个点,如果我们要删除某一条边的话,假设我们删除a和b之间的那条边,a找到a到b,直接释行吗?显然是不行的,因为b也指向了这个节点,如果第一次找到的时候直接删除,会使b指向空指针,所以要删除一条边的话需要“夹逼准则”,从a找到和从b找到都要找。
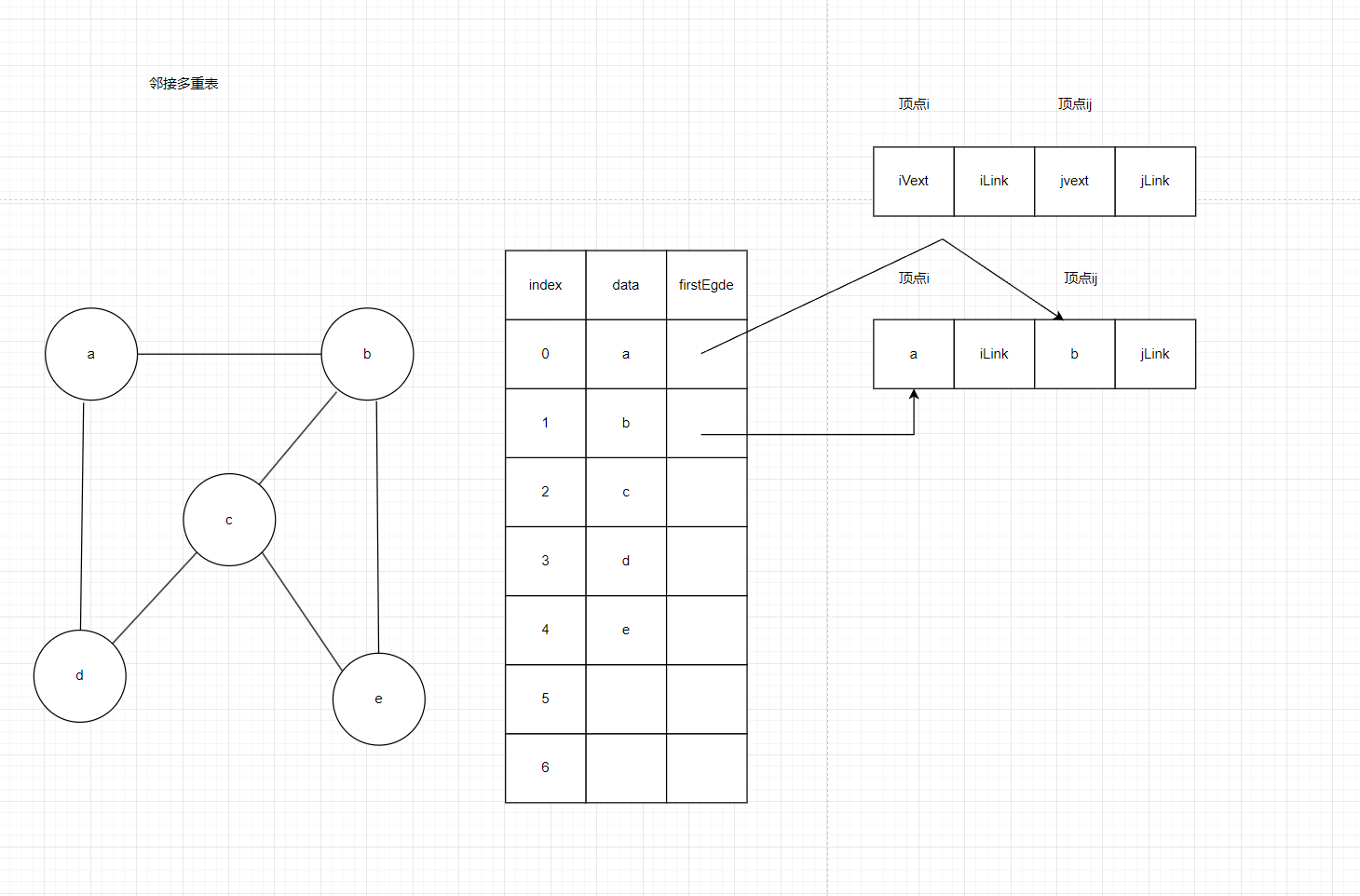
图13
2.5边集数组
边集数组由两个一维数组构成,一个存储顶点信息,另一个存储边的信息,边的信息包括起点下标、终点下标和权值后面讲最小生成树的时候会详细介绍
大概先写这些吧,今天的博客就先写到这,谢谢您的观看。