大模型性能测试实战指南:从原理到落地的全链路解析
一、大模型性能测试的核心价值与挑战
在AI技术快速发展的今天,大模型的性能直接影响用户体验和商业价值。与传统软件不同,大模型的流式响应(Token逐个生成)、长上下文处理能力以及高计算资源消耗,使其性能测试面临全新挑战。
为什么大模型需要专门的性能测试方法?
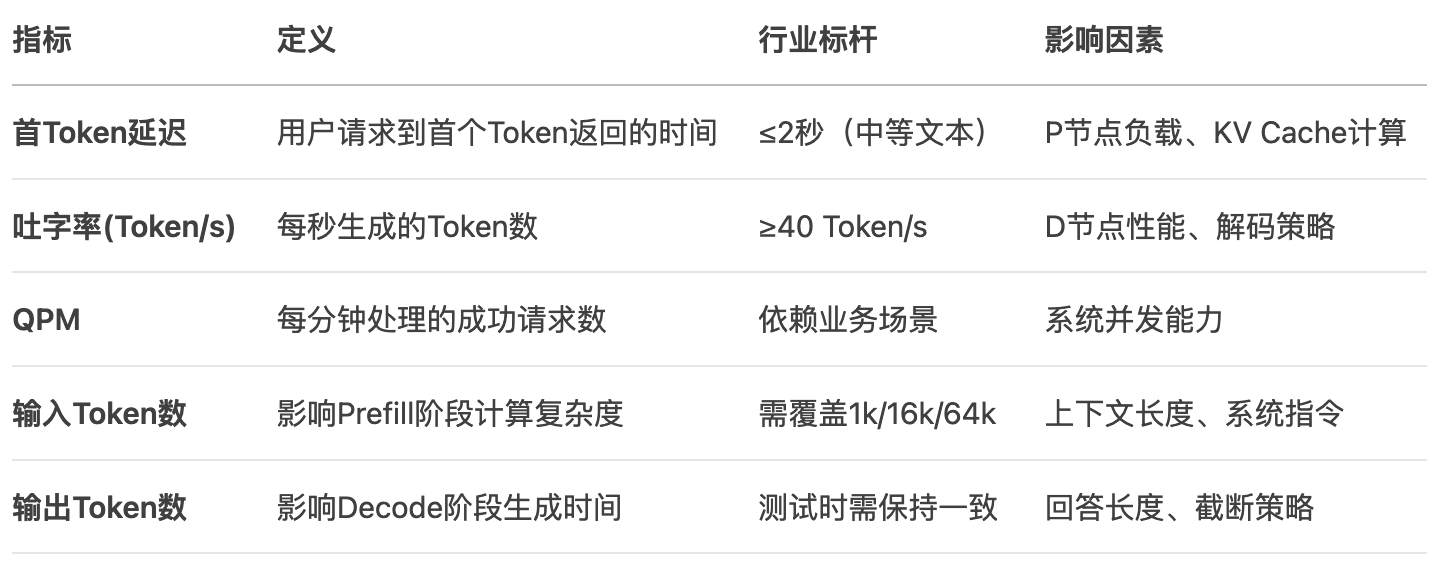
- 流式响应特性:传统性能测试关注TPS(每秒事务数)和响应时间,但大模型的"思考-回答"模式需要测量首Token延迟、吐字率等新指标。
- 计算密集型:大模型的推理依赖GPU/TPU,显存、计算单元利用率成为关键瓶颈。
- 长上下文依赖:输入Token数直接影响计算复杂度,需针对性设计测试数据。
性能测试不仅能发现系统瓶颈,还能为容量规划、成本优化提供数据支撑,确保AI服务的高可用性与经济性。
二、大模型工作原理与测试关键点
1. 流式响应机制
-
大模型的响应分为两阶段:
- 思考阶段(Prefill):模型解析输入、检索知识、规划回答框架(计算密集型)。
- 回答阶段(Decode):逐个生成Token返回(IO密集型)。
# 流式响应数据结构示例
{"choices": [{"delta": {"content": "思考过程..."}, # 思考阶段数据"finish_reason": null}]
}
2. PD分离架构(Prefill-Decode)
-
现代大模型系统通常采用分离架构:
- P节点:处理请求预处理和首Token生成(高计算负载)。
- D节点:负责后续Token生成(高显存占用)。
-
测试时需分别监控两类节点的资源利用率。
https://media/image2.png
三、五大核心性能指标与行业标准
四、实战:从零搭建测试环境
1. 云服务准备(以主流云平台为例)
pip install openai # 安装兼容SDKclient = OpenAI(api_key="your_api_key",base_url="https://api.example.com/v1"
)
2. 测试数据设计原则
- 真实性:使用线上真实对话数据。
- 多样性:覆盖不同输入长度(1k/16k/64k Token)。
- 防缓存:添加UUID避免缓存干扰。
messages = [{"role": "system", "content": "你是一个AI助手"},{"role": "user", "content": f"[{uuid.uuid4()}] 解释量子计算"}
]
五、Locust压力测试实战
1. 自定义指标实现
from locust import HttpUser, task, events@events.init.add_listener
def register_metrics(environment):environment.stats.custom_stats["first_token_latency"] = []class ModelUser(HttpUser):@taskdef test_stream(self):start_time = time.time()with self.client.post("/chat", stream=True, json={"messages": [...]}) as resp:for line in resp.iter_lines():if not first_token_received:latency = time.time() - start_timeenvironment.stats.custom_stats["first_token_latency"].append(latency)first_token_received = True
2. 阶梯式压测策略
# locustfile.yaml
stages:- duration: 5m; target: 1 # 预热- duration: 10m; target: 8 # 基准测试- duration: 10m; target: 32 # 压力测试- duration: 5m; target: 64 # 极限测试
六、性能瓶颈分析与优化
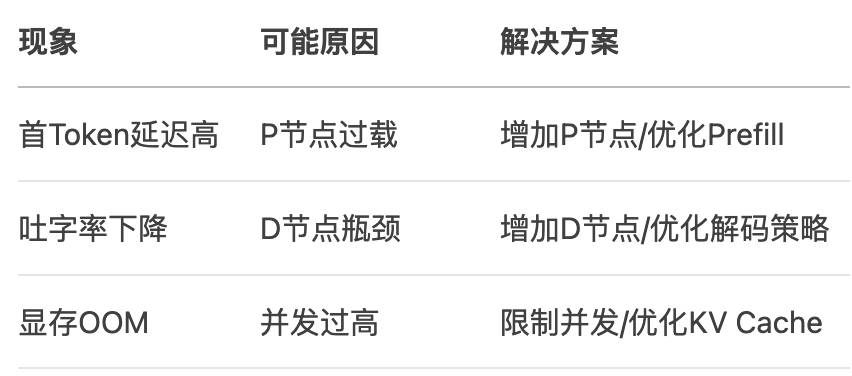
1. 常见瓶颈场景
2. 性能优化黄金法则
30-60-10原则:
- 首Token延迟≤3秒
- 吐字率≥60 Token/s
- GPU利用率保持在70%-90%
七、前沿挑战:多模态测试
随着多模态模型(文本+图像+音频)兴起,测试复杂度升级:
- 混合输入测试:需同时模拟文本、图片、音频请求。
- 跨模态一致性:使用CLIP Score等指标评估图文相关性。
- 资源监控:视觉模型显存占用更高,需针对性优化。
结语:测试工程师的AI时代角色
掌握大模型性能测试,你将不再是简单的"用例执行者",而是:
- AI系统健康的"体检医生":精准定位瓶颈。
- 性能优化的" forensic 专家":从数据反推架构缺陷。
- 技术决策的"战略顾问":为成本与性能平衡提供依据。

思考题:在测试百亿参数大模型时,如何平衡测试深度与资源成本?欢迎在评论区探讨!