RHCA - CL260 | Day04:对象存储、存储池、用户认证
一、创建对象存储集群组件
-
Create BlueStore OSDs Using Logical Volumes 使用逻辑卷创建BlueStore硬盘
-
Introducing BlueStore 介绍BlueStore
-
BlueStore replaced FileStore as the default storage back end for OSDs. (BlueStore替换FileStore作为OSD的默认存储后端引擎。)
-
FileStore stores objects as files in a file system(XFS) on top of a block device.(FileStore将对象存储在块设备上的文件系统(XFS)中。)
-
BlueStore stores objects directly on raw block devices. BlueStore(将对象数据直接存储在裸盘设备中。)
-
1、BlueStore 架构
对象存储在ceph集群中,包含对象的集群范围唯一的ID,二进制数据,以及对象元数据。
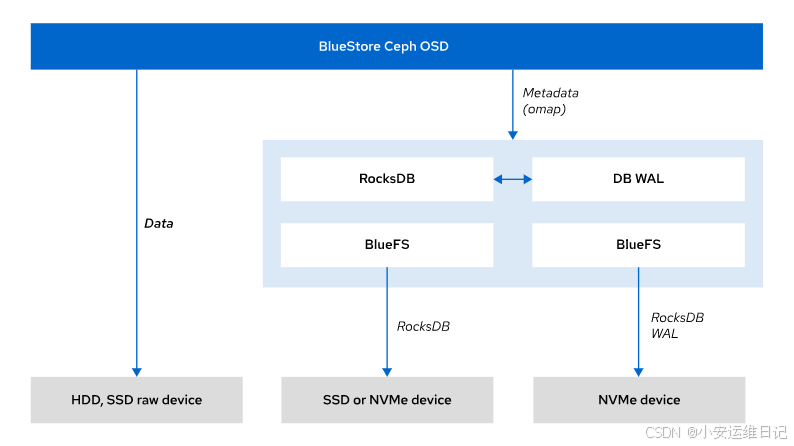
BlueStore 将对象元数据存储在块数据库中。块数据库以键值对K/V的形式将元数据存储在 RocksDB 数据库中,RocksDB 是一个高性能的键值存储系统。
块数据库位于存储设备上的一个小型 BlueFS 分区上。BlueFS 是一个极简文件系统,专门用于保存 RocksDB 文件。BlueStore 通过使用预写日志(WAL)将数据写入块存储设备。预写日志执行日志记录功能,并记录所有事务。
1. BlueStore 存储对象元数据
概念:
BlueStore 是 Ceph 的默认对象存储后端(从 Ceph Luminous 版本开始引入)。
它直接管理块设备(如 HDD 或 SSD),并提供高性能的对象存储功能。
元数据存储位置:
对象的元数据(如对象名称、大小、时间戳等)存储在块数据库中。
块数据库是一个专门用于存储元数据的组件。
2. 块数据库与 RocksDB
块数据库:
块数据库(Block Database)是 BlueStore 的一个核心组件,专门用于存储对象的元数据。
元数据包括对象的名称、大小、时间戳、对象属性等信息。
块数据库的主要任务是高效地管理这些元数据,以便快速检索和更新。
RocksDB 数据库:
RocksDB 是一个高性能的嵌入式键值存储系统,基于 LevelDB 开发,适用于大规模数据存储。是一个开源数据库,专门为快速存储和检索键值对而设计。
RocksDB 以键值对的形式存储数据(如对象元数据),并提供快速的读取和写入性能。支持高并发操作,适合用于大规模数据存储场景。
块数据库基于 RocksDB 实现:
BlueStore 使用 RocksDB 作为块数据库的后端存储引擎。
块数据库将对象的元数据以键值对的形式存储在 RocksDB 中。
RocksDB 提供了高效的键值存储和检索功能,使得块数据库能够快速处理元数据的读写操作。
块数据库的 RocksDB 实例驻留在 BlueFS 分区中。BlueFS 是一个极简文件系统,专门用于管理 RocksDB 的文件(如数据库文件和日志文件)。RocksDB 的文件存储在 BlueFS 分区上,而块数据库通过 RocksDB API 与 RocksDB 交互。
3. BlueFS 与块数据库
BlueFS 文件系统:
BlueFS 是 Ceph 专门为 RocksDB 设计的一个极简文件系统。
它非常轻量,专门用于管理 RocksDB 的文件(如数据库文件和日志文件)。
块数据库的位置:
块数据库的 RocksDB 实例驻留在存储设备上的一个小型 BlueFS 分区中。
BlueFS 分区是存储设备上的一个独立区域,专门用于存放 RocksDB 的元数据。
4. 预写日志(WAL)
概念:
预写日志(Write-Ahead Log,WAL)是一种日志记录机制,用于确保数据写入的可靠性和一致性。
在数据库和文件系统中,WAL 通常用于记录所有写操作,以便在系统崩溃时恢复数据。
在 BlueStore 中的作用:
BlueStore 使用 WAL 将数据写入块存储设备。WAL 的功能类似于日志系统,它会记录所有写操作(事务)。如果系统崩溃或发生故障,WAL 可以用于恢复未完成的事务,确保数据的完整性。
2、BlueStore 性能
FileStore先写数据到journal,然后再从journal回写数据到块设备。BlueStore通过将数据直接写入块设备并使用单独的数据流同时将事务记录到预写日志,从而避免了这种双重写入性能损失。
相同的工作负载,BlueStore写操作的速度大约是FileStore的两倍。
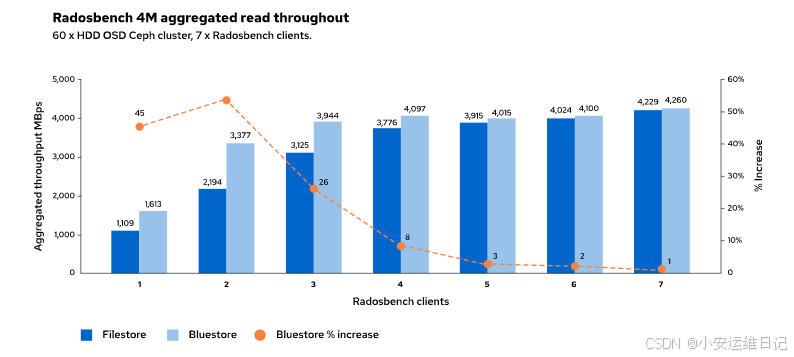
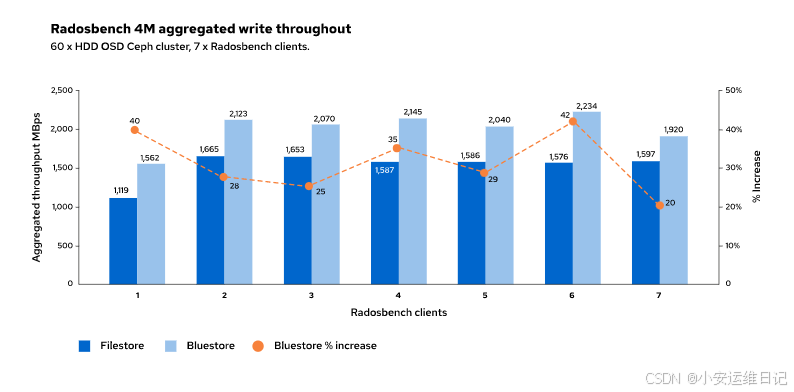
使用服务规范文件定义BlueStore数据、块数据库和预写日志设备的位置。下面以OSD服务对应的BlueStore设备为例进行说明。
service_type: osd
service_id: osd_example
placement:host_pattern: '*'
data_devices:paths:- /dev/vda
db_devices:paths:- /dev/nvme0
wal_devices:paths:- /dev/nvme1 BlueStore 根据 bluestore_min_alloc_size 参数的大小的对数据进行分片写入。默认值为4KiB。
如果写入的数据小于 chunk块 的大小,BlueStore将用零填充块的剩余空间。
数据小于块大小时的处理
- 零填充机制: 如果写入的数据大小小于 bluestore_min_alloc_size(例如只写入 1KiB 的数据),BlueStore 会将剩余的空间(3KiB)用零填充。 这样做是为了确保每次写入的数据块大小一致,从而优化存储和读取性能。
- 作用: 零填充机制可以简化底层存储管理,避免碎片化问题。 同时,它确保了数据的连续性和一致性,方便读取和检索。
3、数据库分片
Ceph是一个高度可扩展的分布式存储系统,它可以提供对象存储、块存储和文件系统三种存储形式。在Ceph中,底层的对象(Object)是数据存储的基本单元,它类似于传统文件系统中的文件。一个Ceph对象通常包含以下三个元素:data,xattr,omap。
-
data:保存对象的数据(对象的主体数据部分,它包含了实际存储的数据内容。在Ceph对象存储中,数据是作为一个原始的字节流存储的,不同于文件系统,对象存储不需要了解数据的格式或结构)
-
xattr(Extended Attributes):保存对象的扩展属性,这个属性是一个key/value(扩展属性是与对象相关联的键值对元数据,可以存储有关对象的额外信息,如MIME类型、修改日期、自定义标签等。Xattr为对象存储提供了丰富的、可搜索的元数据,这在文件系统中也是类似的概念)
-
omap(Object Map):保存到数据库中的key/vaule(对象映射是一个键值数据库,它存储在对象本身内部。Omap被用来存储更复杂的结构数据,如目录条目、索引或是其他需要快速查找的数据。Omap的使用使得Ceph在提供类似文件系统的功能时更为灵活和高效)
BlueStore可以限制存储在RocksDB中omap对象的大小,将它们存储到多个数据列,这个过程叫分片。
关于分片(Sharding):
在Ceph中,分片是指将对象分成多个较小的部分或"分片",这样做的目的是为了提高性能和可伸缩性。当对象变得非常大时,一个单一的大对象可能会成为性能瓶颈,因为每次读取或写入都需要处理整个对象。通过分片,Ceph能够并行处理对象的不同部分,从而提高了I/O性能,并减少了单个对象对于资源的占用。
分片通常在Ceph的RADOS(Reliable Autonomic Distributed Object Store)层实现,这是Ceph的基础,负责数据的存储、复制和恢复。每个分片都可以独立地复制、恢复和重新分配,从而使得Ceph能够有效地处理大规模数据。
在Ceph中,分片还与CRUSH(Controlled Replication Under Scalable Hashing)算法紧密相关,CRUSH算法负责将数据分散到集群中的不同存储设备上,它使用分片的方式来实现数据的均匀分布和高效的存储利用率。
在RHCS5中,分片是默认启用的。使用ceph config get验证是否为OSD启用了分。
-
命令:ceph config get osd.1 bluestore_rocksdb_cf
[ceph: root@node /]# ceph config get osd.1 bluestore_rocksdb_cf
true4、配置BlueStore OSDs
作为存储管理员,您可以使用Ceph Orchestrator服务在集群中添加或删除osd。添加OSD时,需要满足以下条件:
-
The device must not have partitions.(设备上不能有分区)
-
The device must not be mounted.(设备不能被挂载)
-
The device must have at least 5GB of space.(设备必须至少有5GB的空间)
-
The device must not contain a Ceph BlueStore OSD.(设备不能包含Ceph BlueStore OSD)
1)使用 ceph orch device ls 命令列出集群中所有主机的设备。
- 命令:ceph orch device ls
Nodes with the Yes label in the available column are candidates for OSD provisioning.
available 列中带有Yes标签的节点是OSD配置的候选节点。
2)如果需要只查看正在使用的存储设备,使用 ceph device ls 命令。
- 命令:ceph device ls
3)使用 ceph orch device zap 命令可以准备一个OSD设备。这个命令会删除设备上的所有分区,并清理所有数据。
- 命令:ceph orch device zap
4)使用 --force 选项可以强制摧毁一个之前的OSD设备。
- 命令:ceph orch device zap node /dev/vdb --force
注意:node是主机名称,vdb是设备名称,根据实际情况填写
Orchestrator-Managed Provisioning
Orchestrator服务可以发现群集主机中的可用设备,添加设备,并创建OSD守护程序。
1)使用命令 ceph orch apply osd --all-available-devices 配置所有可用的、未使用的设备。
- 命令:ceph orch apply osd --all-available-devices
2)如果要禁用自动管理OSD,可以设置unmanaged标记为ture。
- 命令:ceph orch apply osd --all-available-devices --unmanaged=true
Specific Target Provisioning(指定特定的OSD对象)
1)可以通过指定的设备和主机创建OSD守护进程。需要在指定主机和存储设备上创建单个OSD守护进程,使用ceph orch daemon add命令。
- 命令:ceph orch daemon add osd node:/dev/vdb
node是主机名称,vdb是设备名称,需要根据实际情况填写
2)需要停止OSD守护进程,使用带OSD ID的ceph orch daemon stop命令。
- 命令:ceph orch daemon stop osd.12
3)需要删除OSD守护进程,使用ceph orch daemon rm命令,并输入OSD ID。
- 命令:ceph orch daemon rm osd.12
4)需要释放OSD ID,使用ceph OSD rm命令。
- 命令:ceph osd rm 12
Service Specification Provisioning(通过Spec文件部署OSD)
使用服务规范文件描述OSD服务的集群布局。您可以使用过滤器自定义业务发放。通过过滤器,您可以在不知道具体硬件架构的情况下配置OSD服务。
下面是一个示例服务规范YAML文件,它定义了两个OSD服务,每个服务使用不同的过滤器来放置和BlueStore设备位置。
service_type: osd
service_id: osd_size_and_model
placement:host_pattern: '*' #匹配任何主机
data_devices:size: '100G:' #匹配100G或者以上容量的设备
db_devices:model: My-Disk #匹配有My-Disk标记的设备
wal_devices: size: '10G:20G' #匹配10G-20G容量的设备
unmanaged: true
---
service_type: osd
service_id: osd_host_and_path
placement:host_pattern: 'node[6-10]'
data_devices:paths:- /dev/sdb
db_devices:paths:- /dev/sdc
wal_devices:paths:- /dev/sdd
encrypted: true #设备加密运行ceph orch apply命令应用服务规范。
[ceph: root@ndoe /]# ceph orch apply -i service_spec.yml5、其他OSD工具
ceph-volume是一个模块化的部署工具,可以使用逻辑卷部署OSD。
ceph-volume工具支持LVM插件和裸盘设备。
1)使用 ceph-volume lvm 命令手动创建和删除BlueStore硬盘。
- 命令:ceph-volume lvm create --bluestore --data /dev/vdc
prepare 子命令用来配置OSD使用的逻辑卷。可以指定逻辑卷或设备名称。如果指定了设备名称,则会自动创建逻辑卷。
- 命令:ceph-volume lvm prepare --bluestore --data /dev/vdc
activate子命令为OSD启用systemd单元,以便它在引导时启动。要使用激活子命令,需要从ceph-volume lvm list 命令的输出中获取OSD的fsid(UUID)。
- 命令:ceph-volume lvm activate <osd-fsid>
ceph-volume 是 Ceph 存储集群中用于管理 OSD(Object Storage Daemon)存储设备的命令行工具,它使用 LVM(Logical Volume Manager)来管理存储卷。ceph-volume lvm create、ceph-volume lvm prepare 和 ceph-volume lvm activate 是 ceph-volume 工具中的几个子命令,它们在 OSD 创建和管理过程中扮演不同的角色。
ceph-volume lvm prepare 命令:用于准备一个物理设备,将其初始化为一个 OSD。这个命令会创建必要的 LVM 卷组和逻辑卷,但不会启动 OSD 进程。这个过程包括格式化设备、创建一些必要的元数据和标签,为后续的 activate 过程做准备。执行完 prepare 命令之后,OSD 还不会对外提供服务。
ceph-volume lvm activate 命令:用于激活一个已经 prepare 的 OSD。这个命令会启动相关的 OSD 进程,并将其加入到 Ceph 集群中开始提供服务。activate 过程通常包括挂载存储卷,并启动 OSD 守护进程。
ceph-volume lvm create 命令:是一个更高级的命令,它将 prepare 和 activate 命令的步骤合并为一步,简化了流程。当你运行 ceph-volume lvm create 时,它会自动执行 prepare 和 activate 的所有步骤,创建一个新的 OSD,并立即启动它。
总结:
ceph-volume lvm prepare 是创建 OSD 的第一步,主要负责初始化存储设备并准备 LVM 卷。
ceph-volume lvm activate 是创建 OSD 的第二步,用于激活和启动已准备好的 OSD。
ceph-volume lvm create 是一个便捷的命令,自动完成 prepare 和 activate 的全部步骤。
通常情况下,直接使用 ceph-volume lvm create 可以更快速地设置一个新的 OSD。但是在需要更细粒度控制或调试的情况下,可以单独使用 prepare 和 activate 命令来分步执行 OSD 的创建和激活过程。
2)OSD创建完成后,使用systemctl start ceph-osd@$id命令启动集群中状态为up和in的OSD操作系统。
- 命令:systemctl start ceph-osd@$id
3)batch子命令可以同时创建多个osd。
- 命令:ceph-volume lvm batch --bluestore /dev/vdc /dev/vdd
4)inventory子命令提供节点上所有物理存储设备的信息。
- 命令:ceph-volume inventory
Lab: 使用LVM创建BlueStore硬盘
1. 使用逻辑卷手动创建BlueStore硬盘
[root@foundation0 ~]# ssh root@serverc
[root@serverc ~]# cephadm shell
[ceph: root@serverc /]# ceph -s
[ceph: root@serverc /]# ceph df //查看当前集群存储大小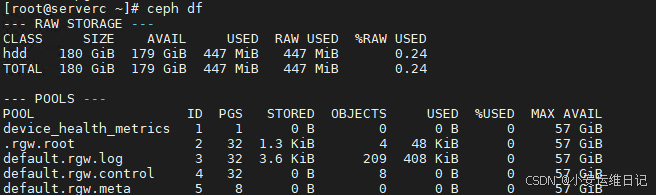
[ceph: root@serverc /]# ceph osd tree //查看当前OSD tree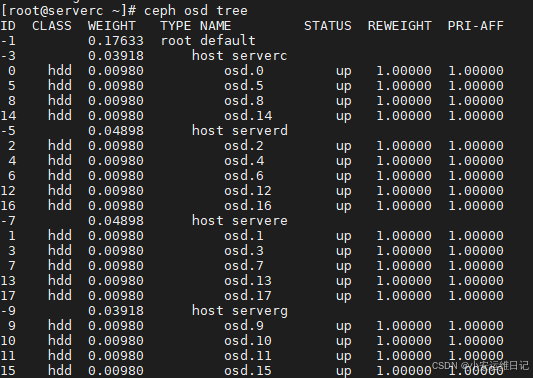
[ceph: root@serverc /]# ceph orch device ls //列出集群中所有活动的磁盘设备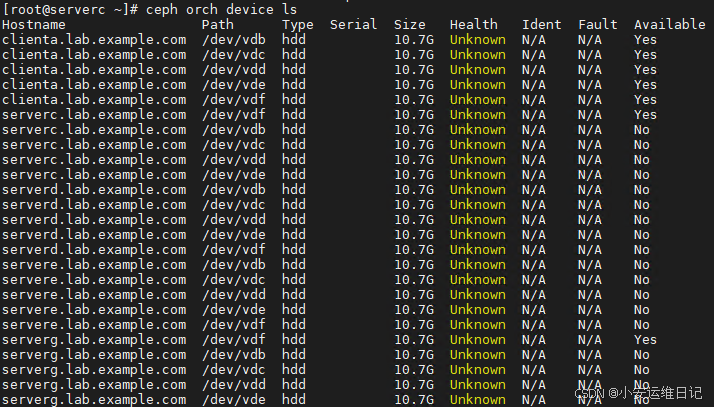
[ceph: root@serverc /]# ceph orch device ls | awk /server/ | grep Yes![]()
使用serverc.lab.example.com上的磁盘设备“/dev/vde”和“/dev/vdf”创建两个OSD守护进程。
[ceph: root@serverc /]# ceph orch daemon add osd serverc.lab.example.com:/dev/vde
Create osd(s) 9 on host 'serverc.lab.example.com'
[ceph: root@serverc /]# ceph orch daemon add osd serverc.lab.example.com:/dev/vdf
Create osd(s) 10 on host 'serverc.lab.example.com'验证守护进程是否正在运行。
[ceph: root@serverc /]# ceph orch ps | grep -ie osd.9 -ie osd.10
osd.10 serverc.lab.example.com running (19s) 5s ago 19s - 16.2.0-117.el8cp 2142b60d7974 01684e62bf3b
osd.9 serverc.lab.example.com running (66s) 5s ago 65s - 16.2.0-117.el8cp 2142b60d7974 da76d6e214f7
2. 通过orchestrator service自动管理所有设备,创建OSD进程
启用编排器服务,从可用的集群设备自动创建OSD守护进程
[ceph: root@serverc /]# ceph orch apply osd --all-available-devices
Scheduled osd.all-available-devices update ... 验证是否有一个all-available-devices服务被创建
[ceph: root@serverc /]# ceph orch ls
验证新硬盘是否存在。
[ceph: root@serverc /]# ceph osd tree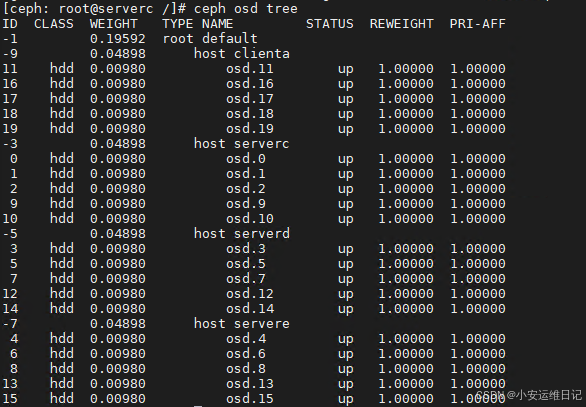
3. 停止servere主机的vde设备,并删除该设备(不推荐)
关闭servere.lab.example.com上/dev/vde设备关联的OSD守护进程并移除。
[ceph: root@serverc /]# ceph orch device ls | grep 'servere.lab.example.com'
servere.lab.example.com /dev/vdb hdd 10.7G Unknown N/A N/A No
servere.lab.example.com /dev/vdc hdd 10.7G Unknown N/A N/A No
servere.lab.example.com /dev/vdd hdd 10.7G Unknown N/A N/A No
servere.lab.example.com /dev/vde hdd 10.7G Unknown N/A N/A No
servere.lab.example.com /dev/vdf hdd 10.7G Unknown N/A N/A No[ceph: root@serverc /]# ceph osd tree
[ceph: root@serverc /]# ceph orch daemon stop osd.17
Scheduled to stop osd.17 on host 'servere.lab.example.com'
[ceph: root@serverc /]# ceph orch daemon rm osd.17 --force
Removed osd.17 from host 'servere.lab.example.com'[ceph: root@serverc /]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
...
15 hdd 0.00980 osd.17 down 1.00000 1.00000
[ceph: root@serverc /]# ceph osd rm 17
removed osd.17[ceph: root@serverc /]# ceph orch osd rm status
servere.lab.example.com done, waiting for purge ... ...
[ceph: root@serverc /]# ceph orch osd rm status
No OSD remove/replace operations reported //再次确认删除进程已经完成补充:移除OSD步骤(推荐)
删除 Ceph 集群中的 OSD 设备是一个需要谨慎进行的操作,因为它会直接影响到集群的数据和性能。以下是删除 OSD 设备的一般步骤:
1)标记 OSD 为 out
首先,确保 OSD 上没有活动数据。通过将 OSD 标记为 out,Ceph 将开始将该 OSD 上的数据迁移到集群中的其他 OSD 上。
ceph osd out osd.<osd-id>
2)等待数据迁移完成
在 OSD 被完全清空之前,需要等待 Ceph 将所有数据迁移至其他 OSD。可以通过以下命令检查数据迁移的状态:
ceph -s
3)停止 OSD 进程
当 OSD 上的数据迁移完成后,可以停止该 OSD 进程。这可以通过以下命令来完成(需要在对应的 OSD 主机上执行):
systemctl stop ceph-osd@<osd-id>
4)从 CRUSH map 移除 OSD
从 CRUSH map 中移除 OSD,以确保集群不会再将数据分布到该 OSD 上。
ceph osd crush remove osd.<osd-id>
5)从集群中移除 OSD 认证
移除 OSD 的 CephX 认证。
ceph auth del osd.<osd-id>
6)从集群中移除 OSD
最后,从 Ceph 集群配置中移除 OSD。
ceph osd rm osd.<osd-id>
7)删除 OSD 的 LVM 卷和分区
这一步涉及实际的磁盘操作,你需要在 OSD 所在的物理主机上执行。首先找到 OSD 使用的 LVM 卷和分区,然后使用 LVM 工具移除它们。
ceph-volume lvm zap /dev/<设备名> --destroy //手动管理
或:
ceph orch device zap --force host /dev/<device> //集群管理
注意:--destroy 参数会销毁所有数据,确保你已经正确迁移了所有数据并且确定无误后再执行此命令。
8)清理 OSD 目录(如果需要)
如果 OSD 是用目录而非磁盘设备创建的,你需要手动删除 OSD 目录:
rm -rf /var/lib/ceph/osd/ceph-<osd-id>
请注意,上述步骤可能会因 Ceph 版本和你的集群配置而有所不同。建议在进行这些操作之前,仔细阅读 Ceph 的官方文档,并根据你的集群情况做相应的调整。另外,强烈建议在进行此类操作之前,确保集群处于健康状态,并且有数据备份,以防万一出现数据丢失的情况。
ceph-volume lvm zap 和 ceph orch device zap 都是用于清除 Ceph OSD 设备上的数据的命令,但它们的使用上下文和执行细节有所不同。
1、ceph-volume lvm zap
是一个较低级别的工具,它直接作用于指定的设备,清除 LVM 和分区信息,使设备可以重新用于创建新的 OSD。这个命令通常在手动部署和管理 OSD 时使用。
- /dev/<device>: 替换为你要清除的实际设备路径,比如 /dev/sdb。
- --destroy 参数: 强制清除设备上的所有数据,包括 LVM 元数据和分区表,这将使数据不可恢复。
使用 ceph-volume lvm zap 需要管理员对系统和 Ceph 架构有较深的了解,因为它直接与底层存储设备交互。
2、ceph orch device zap
是 Ceph Orchestrator 的一部分,它提供了一个更高级别的操作,用于准备或清除集群中的设备。这个命令通常用于自动化部署和管理环境中。
- host: 指定要清除设备的主机名。
- /dev/<device>: 同样替换为要清除的实际设备路径。
- --force 参数: 忽略安全性检查,强制清除设备上的所有数据。
使用 ceph orch device zap 可以更加简单地集成到 Ceph Orchestrator 的自动化流程中,它通常与其他 Orchestrator 命令一起使用,以便统一管理集群。
总结: 两个命令都可以清除 OSD 设备上的数据,但 ceph-volume lvm zap 更多用于手动管理和需要直接控制存储设备的情况,而 ceph orch device zap 通常用于通过 Ceph Orchestrator 进行集群设备管理的自动化环境。在使用这些命令时,重要的是要确保你正在操作正确的设备,因为这些命令执行后,设备上的数据将不可恢复。
启动服务器上的/dev/vde设备。验证Orchestrator服务是否正确地重新添加了OSD守护进程。
- 命令:ceph orch device zap host /dev/<device> --force
[ceph: root@serverc /]# ceph orch device zap --force servere.lab.example.com /dev/vde
[ceph: root@serverc /]# ceph orch device ls | grep servere
servere.lab.example.com /dev/vdb hdd 10.7G Unknown N/A N/A No
servere.lab.example.com /dev/vdc hdd 10.7G Unknown N/A N/A No
servere.lab.example.com /dev/vdd hdd 10.7G Unknown N/A N/A No
servere.lab.example.com /dev/vde hdd 10.7G Unknown N/A N/A No
servere.lab.example.com /dev/vdf hdd 10.7G Unknown N/A N/A No
备注:因前面设置了--all-available-devices,所有设备会自动管理,所以zap格式化后的磁盘被再次使用
[ceph: root@serverc /]# ceph device ls | grep 'servere.lab.example.com:vde'
osd.ID
[ceph: root@serverc /]# ceph orch ps | grep osd.ID
osd.ID servere.lab.example.com running ... ...4. 以YAML格式查看OSD服务
[ceph: root@serverc /]# ceph orch ls --service-type osd --format yaml
service_type: osd
service_id: all-available-devices
service_name: osd.all-available-devices
placement:host_pattern: '*'
spec:data_devices:all: truefilter_logic: ANDobjectstore: bluestore
status:created: '2023-10-25T14:42:35.731891Z'running: 0size: 5
events:
- 2023-10-25T14:42:35.763930Z service:osd.all-available-devices [INFO] "service wascreated"
---
service_type: osd
service_id: default_drive_group
service_name: osd.default_drive_group
placement:host_pattern: server*
spec:data_devices:paths:- /dev/vdb- /dev/vdc- /dev/vdd- /dev/vdefilter_logic: ANDobjectstore: bluestore
status:created: '2023-10-25T04:55:47.712417Z'running: 0size: 4复制内容,重新创建一个all-available-devices.yaml文件,内容如下:
[ceph: root@serverc /]# vim all-available-devices.yaml
service_type: osd
service_id: all-available-devices
service_name: all-available-devices
placement:host_pattern: '*'
unmanaged: true //添加unmanaged: true
...将all-available-devices.yaml服务更改应用于服务。
[ceph: root@serverc /]# ceph orch apply -i all-available-devices.yaml
Scheduled osd.all-available-devices update...
Scheduled osd.default_drive_group update...
验证osd。所有可用设备服务现在具有非托管标志。
[ceph: root@serverc /]# ceph orch ls或者:
[ceph: root@serverc /]# ceph orch apply osd --all-available-devices --unmanaged=true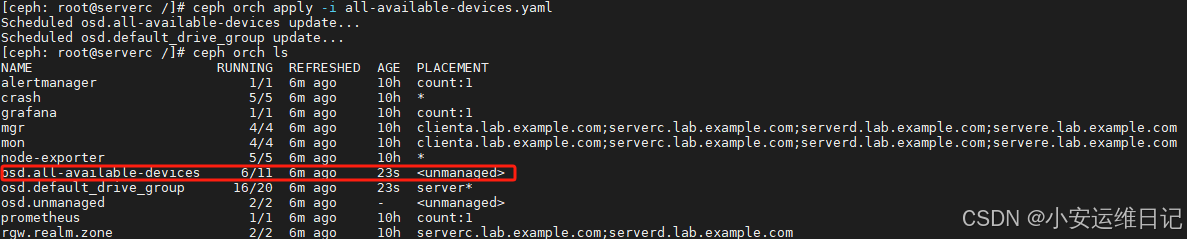
5. 停止serverd主机上面/dev/vdf设备的OSD进程
停止serverd主机上面/dev/vdf设备的OSD进程。确认删除进程正确地完成。清空serverd主机上面的/dev/vdf设备,确认orch服务不会自动使用干净的设备创建新OSD。
[ceph: root@serverc /]# ceph device ls | grep 'serverd.lab.example.com:vdf'
297fa02b-7318-463c-9 serverd.lab.example.com:vdf osd.ID[ceph: root@serverc /]# ceph orch daemon stop osd.ID
[ceph: root@serverc /]# ceph orch daemon rm osd.ID --force
[ceph: root@serverc /]# ceph orch osd rm status
No OSD remove/replace operations reported[ceph: root@serverc /]# ceph osd rm ID
[ceph: root@serverc /]# ceph orch device zap --force serverd.lab.example.com /dev/vdf
[ceph: root@serverc /]# ceph orch device ls | awk /serverd/
serverd.lab.example.com /dev/vdf hdd ... ... Yes[ceph: root@serverc /]# sleep 60
[ceph: root@serverc /]# ceph orch device ls | awk /serverd/
serverd.lab.example.com /dev/vdf hdd ... ... Yes
[ceph: root@serverc /]# exit
[root@serverc ~]# exit二、创建并配置存储池
1、理解存储池
存储池是存储对象的逻辑分区,客户端写数据对象到存储池中。客户端通过集群地图获取的存储池列表,决定将数据对象写入到哪里去。
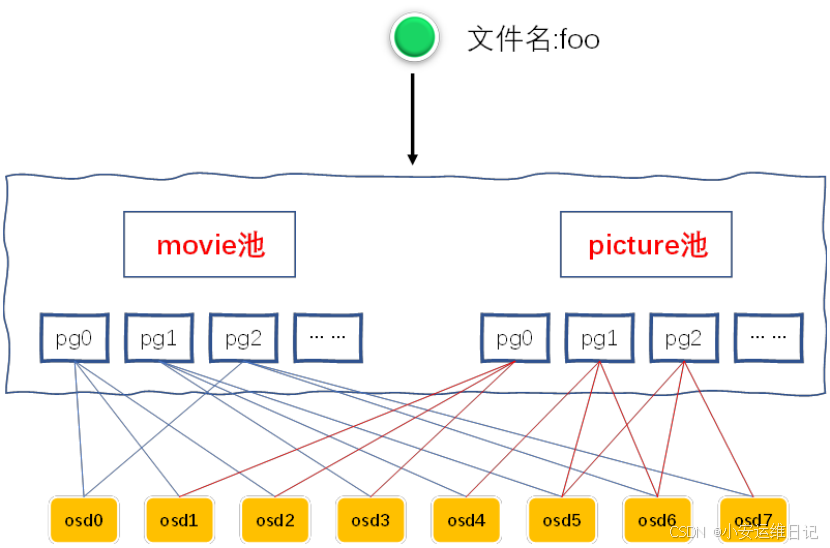
Pool Type(存储池类型)
有效的存储池类型有复制池和纠删码池。默认存储池为复制池,通过将数据对象复制到多个OSD中实现数据备份功能。(因为是完整的数据拷贝,复制池需要更多存储设备,数据的可用性也更高!)纠删码存储池相比较而言需要更少的存储设备和网络负载即可,但是会消耗更多的CPU资源(因为需要对数据进行校验计算)。
A pool's type cannot be changed after creating the pool.
一旦存储池创建后,存储池的类型不可以再修改。
Pool Attributes(存储池属性)
当你创建存储池是需要指定的一些属性。
- The pool name, which must be unique in the cluster.(全局唯一的池名称)
- The pool type.(存储池类型,决定了数据的可靠性)
- The number of placement groups(PGs) in the pool.(PG数量)
- Optionally,a CRUSH rule set.(可选项,CRUSH规则)
提示:当不知道PG数量该如何设置时可以使用https://old.ceph.com/pgcalc/计算器(网址可能会失效,可以搜索)
![]()
Ceph PG(Placement Groups)计算器是一种在线工具,用于帮助管理员确定理想的 PG 数量,以便在 Ceph 集群中实现最佳性能和数据分布。这些计算器通常需要输入如存储池的预期大小、OSD(Object Storage Daemon)的数量以及复制或纠错编码的级别等信息。
截至我所知的信息止步日期(2023年),Ceph 官方并没有提供专门的 PG 计算器网站,但是社区和其他第三方提供了一些非官方的 PG 计算器工具。你可以在网上搜索 "Ceph PG calculator" 来找到这些工具。
一个流行的 PG 计算器可以在以下网址找到:
https://pgcalc.vincent-legoll.fr/
https://ceph.com/pgcalc/
请注意,使用这些在线 PG 计算器时,应该谨慎并以你自己的集群情况为参考。Ceph 集群的性能和稳定性与 PG 的数量有很大关系,PG 数量过多或过少都会对集群性能产生负面影响。Ceph 官方文档建议一定数量的 OSD 应该使用特定范围内的 PG 数量。在确定 PG 的数量时,最好的做法是结合 Ceph 文档、经验法则以及 PG 计算器的建议进行决策。
还需要注意的是,Ceph 的版本更新可能会改变 PG 数量的建议和计算方式,因此始终参照当前运行的 Ceph 版本的官方文档是非常重要的。
2、创建复制存储池
1)使用如下命令创建复制池。
- 命令:ceph osd pool create pool-name pg-num pgp-num replicated crush-rule-name
- pool-name is the name of the new pool.(pool-name为新池名)
- pg-num is the total configured number of PGs for this pool.(pg-num为该池配置的pg总数)
- gpg-num is the effective number of PGs for this pool. Set this equal to pg-num.(gpg-num为该池的有效pg数)
- replicated specifies that this is a replicated pool, and is the default if not includeed in the command.(replicated指定这是一个复制池,如果命令中没有包含此参数,则为默认值)
- cursh-rule-name is the name of the CRUSH rule set you want to use for this pool. The osd_pool_default_crush_replicated_ruleset configuration parameter sets the default value.(要用于此池的CRUSH规则集的名称)
2)显示存储池列表
- 命令:ceph osd pool ls
3)查看存储池详细信息
- 命令:ceph osd pool ls detail
4)查看PG和OSD的对应关系
- 命令:ceph pg dump
5)查看PG地图关系,3是存储池编号,1f是池中PG的编号
- 命令:ceph pg map 3.1f
6)修改存储池的PG数量
- 命令:ceph osd pool get <pool_name> pg_num
<pool_name>:存储池的名称,例如 my_pool。
pg_num:指定查询存储池的 PG 数量。
- 命令:ceph osd pool set <pool_name> pg_num <new_pg_num>
<new_pg_num>:新的 PG 数量,例如 256。
7)使用ceph osd pool create命令创建存储池时,如果没有指定副本的数量,则使用osd_pool_default_size配置参数的值作为默认副本数量,该参数的默认值为3.
- 命令:ceph config get mon osd_pool_default_size
例如:查看集群存储池默认副本数为3
[ceph: root@node /]# ceph config get mon osd_pool_default_size
38)pool-name是存储池的名称,number-of-replicas是副本数量
- 命令:ceph osd pool set pool-name size <number-of-replicas>
- 命令:ceph osd pool get pool-name size
[ceph: root@node /]# ceph osd pool set my_pool size 3
[ceph: root@node /]# ceph osd pool get my_pool size9)可以配置存储池使用自动动态缩放PG,RHCS5默认开启了自动缩放PG。集群中的每个池都有一个pg_autoscale_mode选项,其值为on、off或warn。
- on: Enables automated adjustments of the PG count for the pool.(on:启用自动调整池的PG数。)
- off: Disables PG autoscaling for the pool.(off:关闭PG池的自动缩放。)
- warn: Raises a health alert and changes the cluster health status to HEALTH_WARN when the PG count needs adjustment.(warn:当PG计数需要调整时,引发健康警报并将集群健康状态更改为HEALTH_WARN。)
下面的例子在Ceph MGR节点上启用pg_autoscaler模块,并将池的自动缩放模式设置为on:
- 命令:ceph mgr module enable pg_autoscaler
- 命令:ceph osd pool get pool-name pg_autoscale_mode
- 命令:ceph osd pool set pool-name pg_autoscale_mode on
- 命令:ceph config get mon osd_pool_default_pg_autoscale_mode
- 命令:ceph osd pool autoscale-status
[ceph: root@node /]# ceph mgr module enable pg_autoscaler //启用功能
module: 'pg_autoscaler' is already enabled(always-on)[ceph: root@node /]# ceph osd pool set .mgr pg_autoscale_mode on //对池的pg_autoscale自动缩放模式设置为on:
set pool 7 pg_autoscale_mode to on
[ceph: root@node /]# ceph osd pool get .mgr pg_autoscale_mode//查看集群里 池的自动缩放模式设置
[ceph: root@node /]# ceph config get mon osd_pool_default_pg_autoscale_mode//查看自动缩放状态
[ceph: root@node /]# ceph osd pool autoscale-statusLab: 创建和配置复制池
1. 创建和配置复制池,查看自动缩放状态
Login to serverc as root to run the cephadm shell.
[root@foundation0 ~]# ssh root@serverc
[root@serverc ~]# cephadm shell
[ceph: root@serverc /]# ceph -s创建一个名为replpool1的复制池,包含64个PG(pg)。
[ceph: root@serverc /]# ceph osd pool create replpool1 64 64
pool 'replpool1' created
[ceph: root@serverc /]# ceph osd pool ls
...
replpool1[ceph: root@serverc /]# ceph osd pool get replpool1 pg_num
pg_num: 64
验证PG自动缩放是否为replpool1池启用,并且它是新池的默认值。
[ceph: root@serverc /]# ceph osd pool get replpool1 pg_autoscale_mode
gp_autoscale_mode: on
[ceph: root@serverc /]# ceph config get mon osd_pool_default_pg_autoscale_mode
on列出池,确认是否存在“replpool1”池。
[ceph: root@serverc /]# ceph osd lspools
1 device_health_metrics
2 .rgw.root
... ...
6 replpool1 //新创建池查看自动缩放状态。
[ceph: root@serverc /]# ceph osd pool autoscale-status
2. 设置池的副本个数和最小副本数
将replpool1池的副本个数设置为4。将I/O所需的最小副本数设置为2。
-
命令:ceph osd pool set replpool1 size 4
-
命令:ceph osd pool set replpool1 min_size 2
[ceph: root@serverc /]# ceph osd pool set replpool1 size 4 //默认为3
set pool 6 size to 4
[ceph: root@serverc /]# ceph osd pool get replpool1 size
size: 4[ceph: root@serverc /]# ceph osd pool set replpool1 min_size 2
set pool 6 min_size to 2
[ceph: root@serverc /]# ceph osd pool get replpool1 min_size
min_size: 2
验证:
[ceph: root@serverc /]# ceph osd pool ls detail
...
pool 6 'replpool1' replicated size 4 min_size 2 crush_rule 0 object_hash rjenkins pg_num 64 pgp_num 64 autoscale_mode on last_change 306 flags hashpspool stripe_width 0
3. 设置池的应用程序类型为rbd
将池的应用程序类型设置为rbd。
- 命令:ceph osd pool application enable replpool1 rbd
[ceph: root@serverc /]# ceph osd pool application enable replpool1 rbd
enabled application 'rbd' on pool 'replpool1'执行ceph osd pool ls detail命令检查池配置是否正确。
[ceph: root@serverc /]# ceph osd pool ls detail
...
pool 6 'replpool1' replicated size 4 min_size 2 crush_rule 0 object_hash rjenkins pg_num 64 pgp_num 64 autoscale_mode on last_change 307 flags hashpspool stripe_width 0 application rbd4. 设置池的重命名
将replpool1池重命名为newpool。删除newpool pool。
- 命令:ceph osd pool rename <pool_name> <new_pool>
[ceph: root@serverc /]# ceph osd pool rename replpool1 newpool
pool 'replpool1' renamed to 'newpool'
[ceph: root@serverc /]# ceph osd pool ls
...
newpool
5. 删除池
Delete the newpool pool.
- 命令:ceph osd pool delete <pool_name> <pool_name> --yes-i-really-really-mean-it
[ceph: root@serverc /]# ceph osd pool delete newpool注意提示:
Error EPERM: WARNING: this will *PERMANENTLY DESTROY* all data stored in pool newpool. If you are *ABSOLUTELY CERTAIN* that is what you want, pass the pool name *twice*, followed by --yes-i-really-really-mean-it.
错误EPERM:警告:这将永久破坏存储在池newpool中的所有数据。如果你“绝对确定”这就是你想要的,传递池名“两次”,后面跟着--yes-i-really-really-mean-it。
[ceph: root@serverc /]# ceph osd pool delete newpool newpool --yes-i-really-really-mean-it
pool 'newpool' removed注意提示:
Error EPERM: pool deletion is disabled; you must first set the mon_allow_pool_delete config option to true before you can destroy a pool.
错误EPERM:池删除被禁用;在销毁池之前,必须首先将mon_allow_pool_delete配置选项设置为true。
- 设置临时规则:ceph tell mon.* config set mon_allow_pool_delete true
- 设置永久规则:ceph config set mon mon_allow_pool_delete true
[ceph: root@serverc /]# ceph tell mon.* config set mon_allow_pool_delete true
mon.serverc.lab.example.com" {"success": ""
}
mon.serverd.lab.example.com" {"success": ""
}
mon.servere.lab.example.com" {"success": ""
}
mon.clienta.lab.example.com" {"success": ""
}[ceph: root@serverc /]# ceph config set mon mon_allow_pool_delete true
[ceph: root@serverc /]# ceph config get mon mon_allow_pool_delete
true
[ceph: root@serverc /]# ceph osd pool delete newpool newpool --yes-i-really-really-mean-it
pool 'newpool' removed三、配置纠删码存储池
对象存储在纠删码存储池中会被切分为多个数据块,分别存储在不同的OSD设备中。
通过对数据块的校验计算,计算编码数据块,将编码数据块也存储在不同的OSD设备中。
当OSD损坏后,纠删码块可以用来重建对象数据。
1、纠删码工作原理
To summarize how erasure coded pools work:
-
Each object's data is divided into k data chunks.(对象数据被分隔为K个数据块)
-
m coding chunks are calculated.(m个校验数据块)
-
The coding chunk size is the same as the data chunk size.(块的大小一致)
-
The object is stored on a total of k + m OSDs.(对象最终存储在k+m个OSD中)
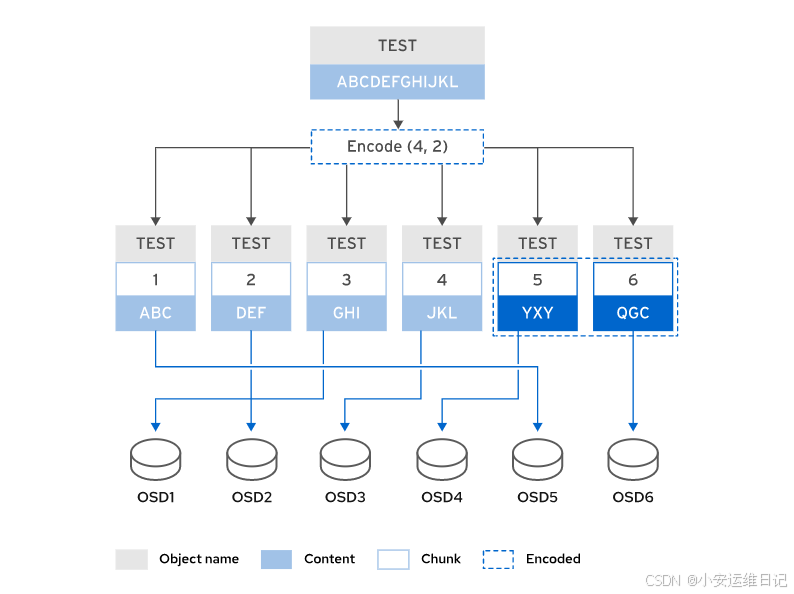
备注:文件名TEST,数据内容ABCDEFGHIJKL,采用K+M(4+2)的Erasure Coded Pool。
数据内容被分隔为ABC,DEF,GHI,JKL分别存储在各个OSD中,然后计算编码数据YXY,QGC,也存储在OSD中。
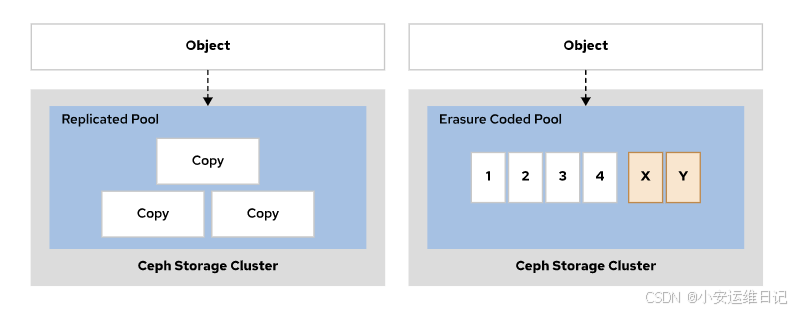
纠删码存储池可以比复制池更高效地利用存储容量。比如,3副本的存储池,会使用3倍的存储容量,而4+2的纠删码存储池只需要占用1.5倍存储容量。
- 4+2 (1:1.5 ratio)
- 8+3 (1:1.375 ratio)
- 8+4 (1:1.5 ratio)
纠删码存储池使用更少的存储设备可以提供和复制池类似的数据保护效果,可以降低成本减少集群存储设备的数量。但是,继续校验数据需要效果更多的CPU和内存资源,会降低性能。
使用如下命令创建erasure coded纠删码池。
- 命令:ceph osd pool create pool-name pg-num pgp-num erasure erasure-code-profile crush-rule-name
- pool-name(存储池名称)
- pg-num(PG数量),pgp-num(PGP数量)
- erasure(指定创建纠删码存储池)
- erasure-code-profile(指定profile的名称),可以使用ceph osd erasure-code-profile set命令创建profile
- crush-rule-name指定存储池使用的CRUSH规则
2、Erasure Code 配置文件
Erasure code profile用来配置erasure coded池中数据块和coding块个数(K和M的个数),以及插件和coding算法的使用。Ceph在安装时会自动创建一个名称为default的profile。这个profile配置了2个data chunks和2个coding chunk(2+2)。
使用以下命令创建一个新的profile文件。
- 命令:ceph osd erasure-code-profile set profile-name <arguments>
he following arguments are available:
k: The number of data chunks that are split across OSDs. The default value is 2.(k:跨osd分割的数据块数量,默认值为2)
m: The number of OSDs that can fail before the data becomes unavailable. The default value is 2.(m:在数据不可用之前可以故障的osd数量,默认值为2)
directory: This optional parameter is the location of the plug-in library. The default value is /usr/lib64/ceph/erasure-code.(可选参数是插件库的位置。默认值为“/usr/lib64/ceph/erasure-code”,相对容器里面的目录结构)
plugin: This optional parameter defines the erasure coding algorithm to use.(plugin:可选参数,定义使用的擦除编码算法)
crush-failure-domain: This optional parameter defines the CRUSH failure domain, By default, it is set to host.(可选参数,定义CRUSH故障域,默认为host)
crush-device-class: This optional parameter selects only OSDs backed by devices of this class for the pool. Typical classes might include hdd, ssd, or nvme.(可选参数只为池选择该类设备支持的osd。典型的类可能包括hdd、ssd或nvme)
crush-root: This optional parameter sets the root node of the CRUSH rule set.(可选参数设置CRUSH规则集的根节点)
key=value: Plug-ins might have key-value parameters unique to that plug-in.(插件可能具有该插件独有的键值参数)
重要:已经存在的存储池不可以修改erasure code profile。
1)Use the ceph osd erasure-code-profile ls command to list existing profiles.
- 命令:ceph osd erasure-code-profile ls,列出现有配置文件。
2)Use the ceph osd erasure-code-profile get command to view the details of an existing profile.
- 命令:ceph osd erasure-code-profile get ,查看现有配置文件的详细信息。
3)Use the ceph osd erasure-code-profile rm command to remove an existing profile.
- 命令:ceph osd erasure-code-profile rm ,删除一个已存在的配置文件。
3、管理和操作池
您可以查看和修改现有池,并更改池的配置设置。
1)Rename a pool by using the ceph osd pool rename command.
- 命令:ceph osd pool rename,重命名存储池
修改存储池名称不会影响存储池中的数据,如果修改的存储池有对应的和存储池名称绑定的用户权限,则需要更新用户的权限
2)Delete a pool by using the ceph osd pool delete command.
- 命令:ceph osd pool delete <pool_name>,使用ceph osd pool Delete命令删除池。
3)Prevent pool deletion fro a specific pool by using the ceph osd pool set pool-name nodelete true command. Set nodelete back to false to allow deletion of the pool.
- 命令:ceph osd pool set pool-name nodelete true,用于防止从指定池删除池。使用实例将nodelete设置回false以允许删除池。
4)View and modify pool configuration settings by using the ceph osd pool set and ceph osd pool get command.
- 命令:ceph osd pool set和 ceph osd pool get,查看和修改存储池配置。
5)List pools and pool configuration settings by using the ceph osd lspools and ceph osd pool ls detail commands.
- 命令:ceph osd lspools和ceph osd pool ls detail,列出池和池配置设置。
6)List pools usage and performance statistics by using the ceph df and ceph osd pool stats commands.
- 命令:ceph df和ceph osd pool stats命令列出池的使用情况和性能统计信息。
7)Enable Ceph applications for a pool by using the ceph osd pool application enable command. Application types are cephfs for Ceph File System, rbd for Ceph Block Device, and rgw for RADOS Gateway.
- 命令:ceph osd pool application enable <type>,为池启用Ceph应用。应用程序类型是:
-
Ceph文件系统的cepfs
-
Ceph块设备的rbd
-
RADOS网关的rgw
8)Set pool quotas to limit the maximum number of bytes or the maximum number of objects that can be stored in the pool by using the ceph osd pool set-quota command.(设置为0代表删除配额)
- 命令:ceph osd pool set-quota,设置池配额,限制池中可以存储的最大字节数或最大对象数。
警告:Deleting a pool removes all data in the pool and is not reversible. Your must set mon_allow_pool_delete to true to enable pool deletion. 删除存储池将删除存储池中的所有数据,且删除操作不可逆转。必须将mon_allow_pool_delete设置为true才能启用池删除。
[ceph: root@node /]# ceph config set mon mon_allow_pool_delete true配置这些示例设置值以启用防止池重新配置的保护:
-
osd_pool_default_flag_nodelete(设置为true,防止存储池被删除)
-
osd_pool_default_flag_nopgchange(设置为true,防止修改PG和PGP的值)
-
osd_pool_default_flag_nosizechange(设置为true,防止修改副本数量)
Lab: Creating and Configuring EC Pools
1. 创建和配置EC纠删码池
Login to serverc as root to run the cephadm shell.
[root@foundation0 ~]# ssh root@serverc
[root@serverc ~]# cephadm shell
[ceph: root@serverc /]# ceph -s查看已配置的擦除编码配置文件。
- 命令:ceph osd erasure-code-profile ls
- 命令:ceph osd erasure-code-profile get default
[ceph: root@serverc /]# ceph osd erasure-code-profile ls
default
[ceph: root@serverc /]# ceph osd erasure-code-profile get default
k=2
m=2
plugin=jerasure
technique=read_sol_van创建一个名为ecprofile-k4-m2的擦除代码配置文件,其值为k=4和m=2。
- 命令:ceph osd erasure-code-profile set ecprofile-k4-m2 k=4 m=2
[ceph: root@serverc /]# ceph osd erasure-code-profile set ecprofile-k4-m2 k=4 m=2
[ceph: root@serverc /]# ceph osd erasure-code-profile get ecprofile-k4-m2
crush-device-class=
crush-failure-domain=host
crush-root=default
jerasure-per-chunk-alignment=false
k=4
m=2
plugin=jerasure
technique=reed_sol_van
w=8使用具有64个PG和rgw应用程序类型的ecprofile-k4-m2配置文件创建一个名为ecpool1的纠删码池。
[ceph: root@serverc /]# ceph osd pool create ecpool1 64 64 erasure ecprofile-k4-m2
pool 'ecpool' created
[ceph: root@serverc /]# ceph osd pool application enable ecpool1 rgw
enabled application 'rgw' on pool 'ecpool1'查看ecpool1池的详细信息。您的池ID可能不同。
[ceph: root@serverc /]# ceph osd pool ls detail
... ...
pool 7 'ecpool1' erasure profile ecprofile-k4-m2 size 6 min_size 5 crush_rule 1 object_hash rjenkins pg_num 64 pgp_num 64 autoscale_mode on last_change 322 flags hashpspool stripe_width 16384 application rgw旧版本纠删码存储池只支持rgw,设置该参数让RBD和CephFS也可以使用该存储池
[ceph: root@serverc /]# ceph osd pool set ecpool1 allow_ec_overwrites true
set pool 7 allow_ec_overwrites to true删除“ecpool1”池。
[ceph: root@serverc /]# ceph osd pool delete ecpool1 ecpool1 --yes-i-really-really-mean-it
pool 'ecpool1' removed
[ceph: root@serverc /]# exit //退出容器
[root@serverc ~]# exit //退出2. 使用Ceph Dashboard创建一个复制池。
Open a web browser and navigate to https://serverc.lab.example.com:8443
Log in asadmin by using redhat as the password. You should see the Dashboard page.
打开web浏览器,使用admin密码redhat,您应该看到Dashboard页面。
1)Click Pools to display the Pools page Click Create. 单击“池”,进入“池”页面。单击“创建”。
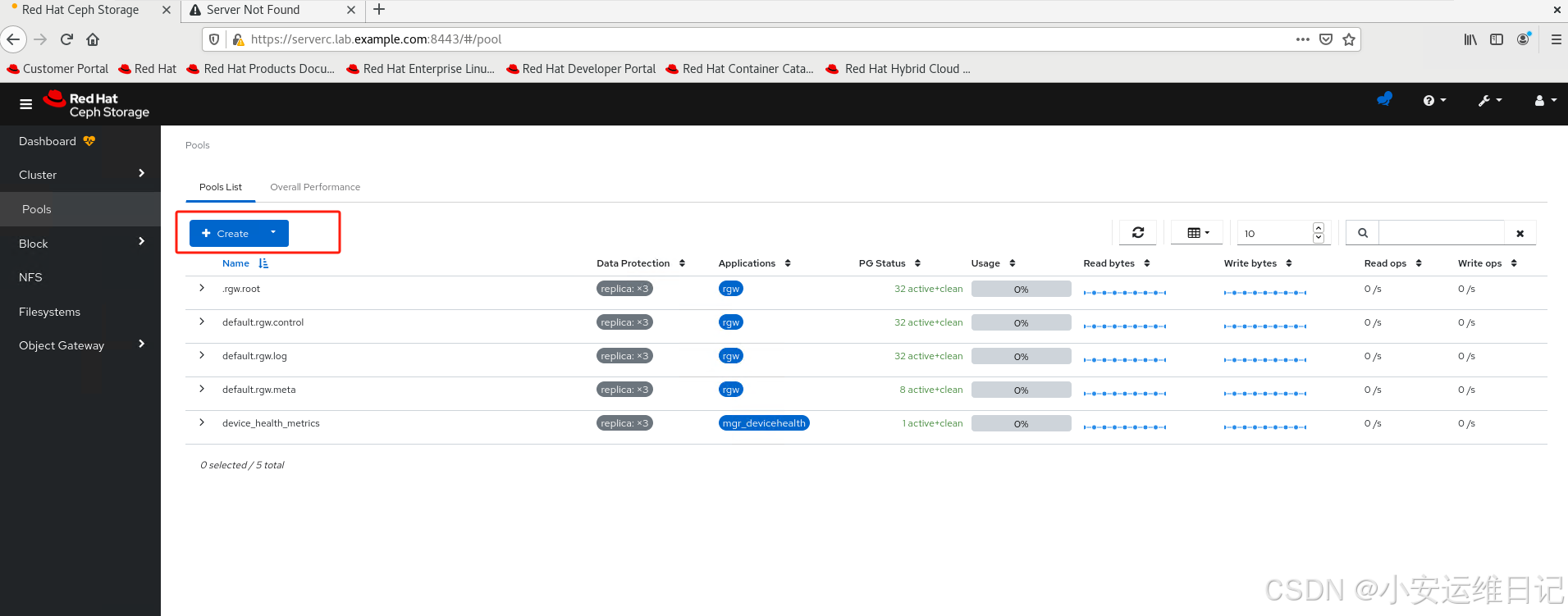
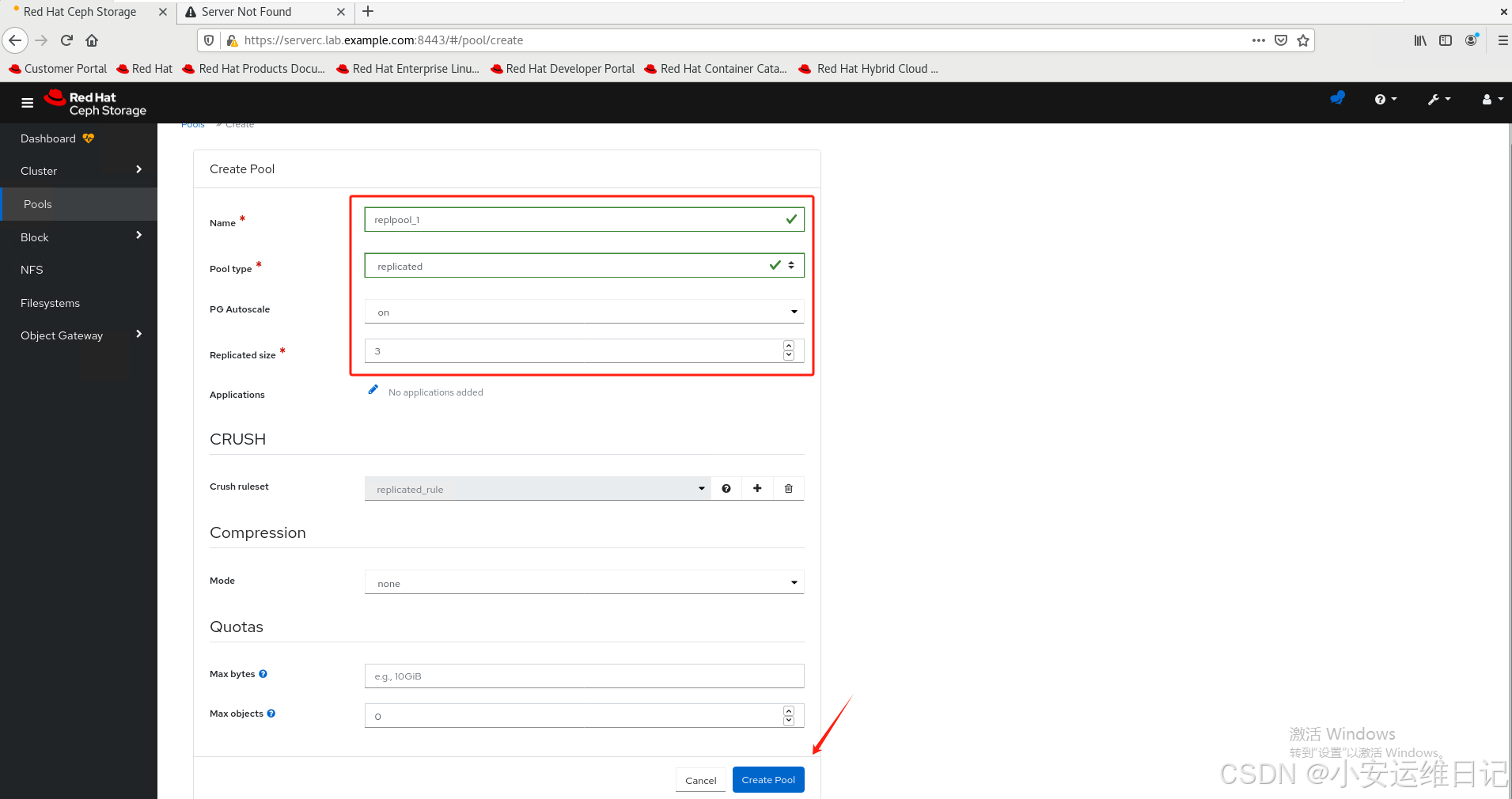
2)Enter replpool1 in the Name field, replicated in the Pool type field, on in the PG Autoscale field, and 3 in the Replicated size. Leave other values as default. Click CreatePool.
在Name字段中输入replpool_1,在Pool type字段中输入replicated,在PG Autoscale字段中输入on,在replicated size中输入3。其他值保持默认值。单击CreatePool。
3. 使用Ceph Dashboard创建一个纠删码池
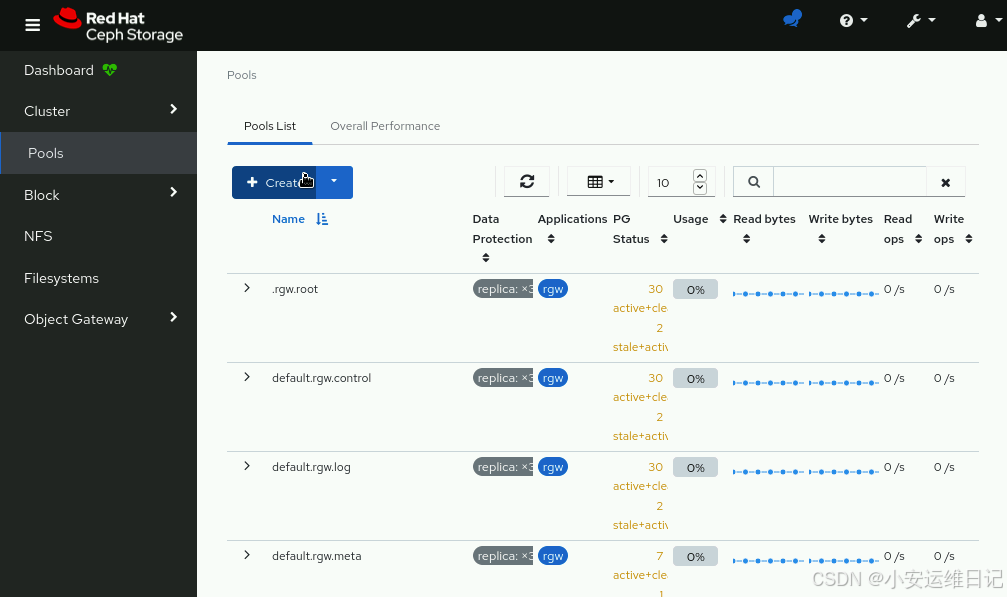
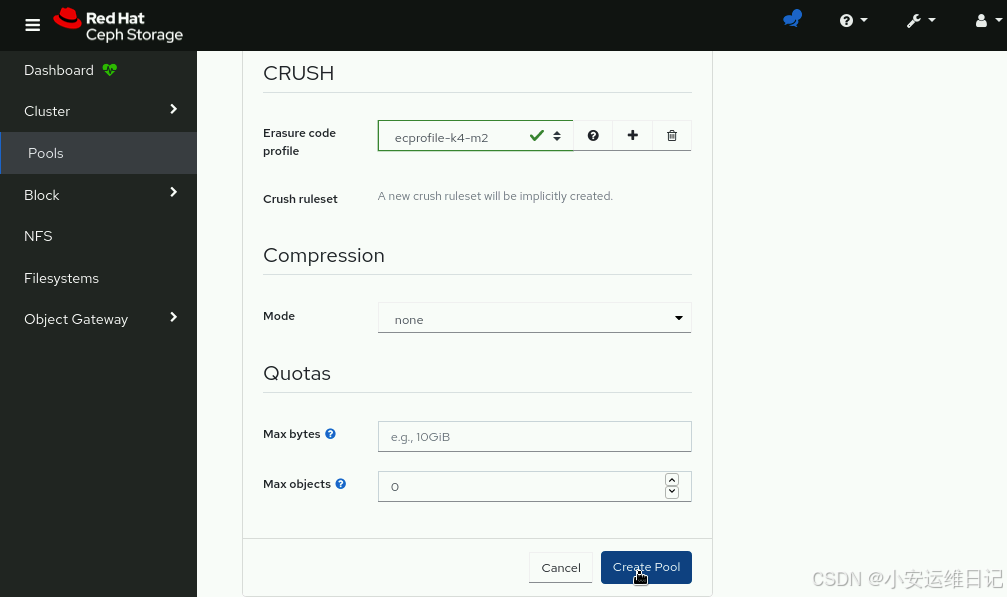
1)Create an erasure coded pool using the Ceph Dashboard. Click Pools to display the Pools page. Click Create.使用Ceph Dashboard创建一个纠删码池。单击“池”,进入“池”页面。单击Create。
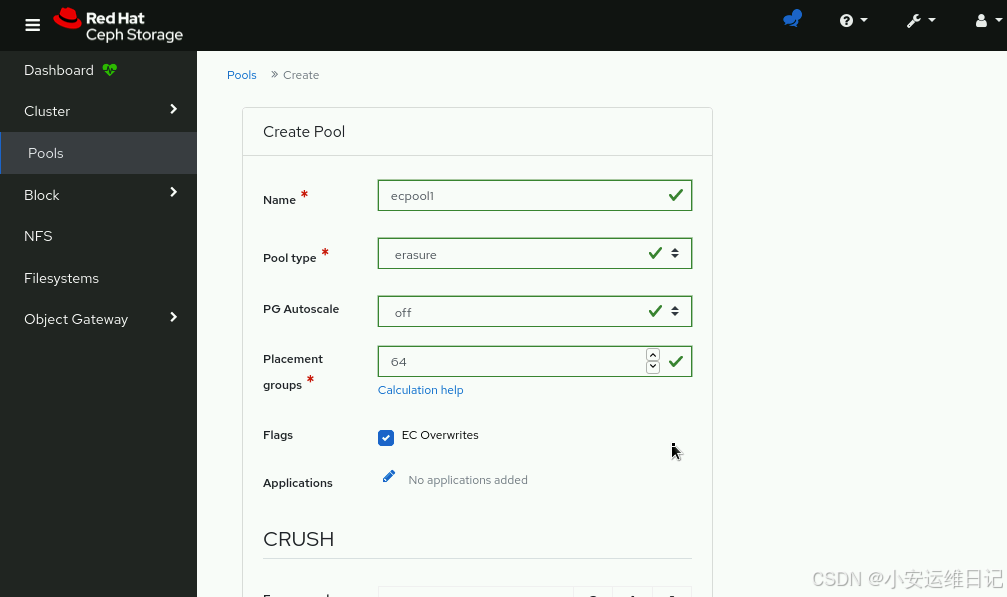
2)Enter ecpool1 in the Name field, erasure in the Pool type field, off in the PG Autoscale field, and 64 in the Placement groups fields. Check the EC Overwrites box of the Flags section, and select the ecprofile-k4-m2 profile from the Erasure code profile field. Click Create Pool. 在Name字段中输入ecpool1,在Pool type字段中输入erasure,在PG Autoscale字段中输入off,在Placement groups字段中输入64。选中Flags部分的EC Overwrites框,并从Erasure code profile字段中选择ecprofile-k4-m2 profile。单击CreatePool。
四、存储池命名空间
命名空间是对存储池中对象的逻辑分组;通过命名空间,可以限制用户仅可以访问自己空间中的数据;如果没有命名空间,我们只能创建更多的存储池,来限制用户的访问权限,但是,更多的存储池就意味着更多的PG和OSD,以及相关的计算代价。有了命名空间可以有效地解决该文件。
重要(Important):Namespaces are currently only supported for applications that directly use librados. RBD and RGW client do not currently support this feature.
命名空间目前仅支持通过librados直接访问的形式使用!!!
将数据存储到命名空间中,客户端程序必须指定存储池的名称和命名空间的名称,默认每个存储池都有一个空名称的命名空间,被称为default namespace。
使用rados命令可以在存储池中存储和读取数据,使用-N和--namespace可以指定命名空间。
- 命令:rados -p <pool_name> -N <namespace> put <objects> <local_files>
- 命令:rados -p <pool_name> -N <namespace> ls
The following example stores the /etc/services file as the srv object in the mytestpool pool, under the system namespace. (这里的命令是语法讲解,不能照抄,需要理解)
下面的示例 将本地的 /etc/services 文件上传到 Ceph 存储集群的 mytestpool 存储池中,上传的对象在该存储池中的命名空间 system 下,并且上传后的对象名称为 srv。
[ceph: root@node /]# rados -p mytestpool -N system put srv /etc/services
[ceph: root@node /]# rados -p mytestpool -N system ls
srvrados 是 Ceph 存储集群的命令行接口工具,用于直接与 RADOS(Reliable Autonomic Distributed Object Store)交互。RADOS 是 Ceph 分布式存储系统的底层存储引擎,负责存储所有数据对象。该命令的组成如下:
- rados: 调用 rados 工具。
- -p : 指定要操作的 Ceph 存储池名称,这里是 mytestpool。
- -N : 指定命名空间为 system。命名空间用于隔离池中的对象集,可以将对象逻辑上分组在一起。
- put: 这是一个操作选项,表示要将本地文件上传到存储池中。
- srv: 指定上传对象的名称,在 Ceph 存储池中将使用此名称作为对象的标识符。
- /etc/services: 指定要上传的本地文件路径,这里是系统的 /etc/services 文件。
使用--all选项列出池中所有命名空间中的所有对象。要获得JSON格式的输出,请添加--format=json-pretty选项。
-
命令:rados -p <pool_name> -all ls [--format=json-pretty]
[ceph: root@node /]# rados -p mytestpool --all ls
system srv
flowers anemone
flowers iris
system magic
flowers rosemytest //空白是默认命名空间
system networks[ceph: root@node /]# rados -p mytestpool --all ls --format=json-pretty
[{"name": "srv","namespace": "system"},{"name": "anemone","namespace": "flowers"}... ...
]五、管理Ceph身份验证
1、Autenticating 用户认证
红帽Ceph集群环境中客户端,应用程序,集群进程之间都使用认证方式通信。cephx协议基于共享密钥的工作原理。默认安装程序会开启cephx认证协议,所有客户端和集群之间通信均需要认证。
Ceph在以下几个方面使用用户帐户:
- For internal communication between Ceph daemons.(用于Ceph守护进程之间的内部通信)
- For client applications accessing the cluster throught the librados library.(对于通过librados库访问集群的客户机应用程序)
- For cluster administrators.(适用于集群管理员)
在安装过程中Ceph进程默认就会创建和名称匹配的用户,比如osd.1或者mgr.serverc等。客户端访问librados的账户名名称通常是以client.为前缀。(比如client.openstack、client.rgw.hostname等)
默认Ceph会创建一个超级管理员账户client.admin,该用户可以执行ceph和rados命令。
Ceph默认使用 client.admin 用户执行管理命令,除非我们通过--name或--id选项指定特定的用户。我们可以设置CEPH_ARGS环境变量定义集群名称或者用户ID。
[ceph: root@node /]# export CEPH_ARGS="--id cephuser"//如果您想要删除或取消这个环境变量的设置,可以使用 unset 命令:
[ceph: root@node /]# unset CEPH_ARGS- 当在命令行上使用 Ceph 命令行工具(如 ceph, rados, rbd, 等)与 Ceph 集群交互时,通常需要通过 --id 或 -n 参数指定客户端 ID。如果不想每次执行命令时都输入这些参数,可以通过设置 CEPH_ARGS 环境变量来简化这个过程。执行 ceph status 时,实际上就等同于执行了 ceph --id cephuser status。
- 请注意,使用 export 设置的环境变量只对当前的 shell 会话有效。当关闭当前的终端或开始一个新的会话时,环境变量的设置将不再有效,除非在 .bashrc、.bash_profile、.zshrc 等 shell 初始化文件中再次设置环境变量,那每次打开新的 shell 会话时,变量都会被自动设置。
- 要从初始化文件中删除环境变量,您需要编辑相应的文件,删除或注释掉包含 export CEPH_ARGS="--id cephuser" 的行,然后重新加载文件(通常是通过打开新的终端窗口,或者在当前窗口执行 source <初始化文件>)。
注意:使用 --id选项时,用户名称不要包含client.前缀,--id选项会自动添加client.前缀,而--name选项则需要指定client.前缀。
最终的终端用户在Ceph集群上没有帐户。应用程序可以通过其他机制提供自己的用户身份验证。
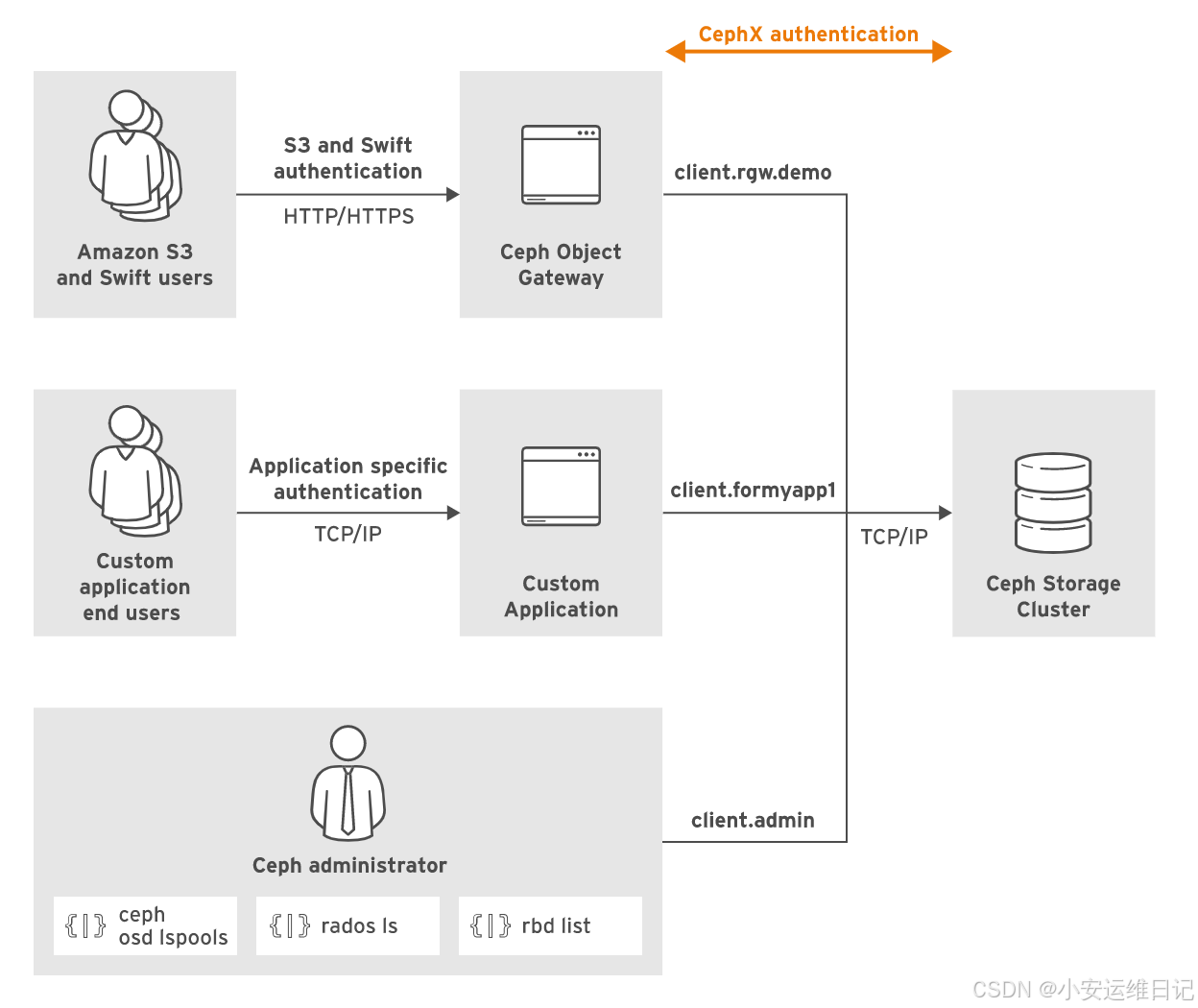
Ceph Object Gateway拥有自己的用户数据库,用于对Amazon S3和Swift用户进行身份验证,但使用client.rgw.hostname帐户访问集群。
2、Key-ring 密钥环文件
对于身份验证,客户端必须配置一个Ceph用户名和一个包含用户密钥的密钥环key-ring文件。Ceph用户需要这个密匙环文件才能访问RedHat Ceph Storage集群。Ceph自动为您创建的每个用户帐户生成密钥环文件。但是,您仍然需要将该文件拷贝到需要它的客户机系统或应用程序服务器。
在这些客户端系统上,librados使用/etc/ceph/ceph.conf配置文件中的keyring参数来定位keyring文件。默认值为“/etc/ceph/$cluster.$name.keyring”。例如,对于客户端。“/etc/ceph/ceph.client.openstack.keyring”。
备注:key-ring文件使用明文存储密钥,我们需要使用Linux系统的权限保护该文件,只能让特定的用户访问该文件。
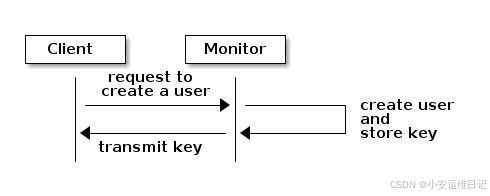
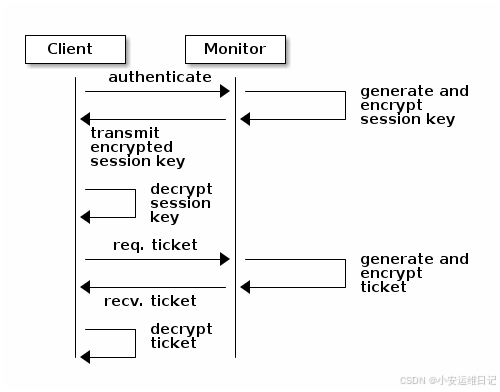
3、传送密钥
Cephx协议并不会在网络上传递共享密钥。客户端会访问mon请求一个session key,mon会使用共享密钥加密一个session key并传递给客户端,客户端使用正确的共享密钥解密session key,然后使用session key访问存储集群。
4、配置用户认证
通过使用ceph、rados和rbd等命令行工具,管理员可以使用--id和--keyring选项指定用户帐户和密钥环。如果未指定,命令将作为客户端进行身份验证。管理用户。在本例中,ceph命令作为客户端进行身份验证operator3用户,列出可用的池:
[ceph: root@node /]# ceph --id operator3 osd lspools
1 myfirstpool
2 mysecondpool注意:使用--id选项时,用户名称不要包含client.前缀,--id选项会自动添加client.前缀,而--name选项则需要指定client.前缀。
如果您将密钥环文件存储在其默认位置,则不需要--keyring选项。cephadm shell自动从/etc/ceph目录挂载密钥环。
5、使用Cephx进行授权
当您创建一个新的用户帐户时,您需要授予它权限,以控制该用户在RedHat Ceph Storage集群中被授权访问Ceph集群的权限。Cephx中的权限称为capability,可以根据守护进程类型(mon、osd、mgr或mds)授予权限。
Ceph Capabilities
在cephx中,对于每种守护进程类型,有几个功能可用:
-
r grant read access. Each user account should have at least read access on the Monitors to be able to retrieve the CRUSH map.(授予读访问权限。每个用户帐户至少应该对mon具有读访问权限,以便能够检索CRUSH map.)
-
w grant write access. Clients need write access to store and modify objects on OSDs.(授予写访问权限。客户端需要有写权限来存储和修改osd上的对象。)
-
x grant authoriztion to execute extended object classes. This allows clients to perform extra operations on bojects such as setting locks with rados lock get or listing RBD images with rbd list.(x授予执行扩展对象类的授权。这允许客户端对对象执行额外的操作,例如使用rados lock get设置锁或使用RBD list列出RBD图像。)
-
* grants full access. (*授予完全访问权限。)
-
class-read and class-write are subsets of x. (class-read和class-write是x的子集。)
例子:创建formapp1用户帐户,并赋予其从任何池中存储和检索对象的能力:
-
命令:ceph auth get-or-create client.username mon 'allow r' osd 'allow rw'
[ceph: root@node / ]# ceph auth get-or-create client.formyapp1 mon 'allow r' osd 'allow rw'
[ceph: root@node / ]# ceph auth get client.formyapp1
[client.formyapp1]key = AQAFneVl1iJkIBAAJLsLhU+GIo4r22ngOpBcug==caps mon = "allow r"caps osd = "allow rw"6、使用配置文件设置功能
cephx提供预定义的 capability profiles 配置文件。在创建用户帐户时,可以使用配置文件简化用户访问权限的配置。使用rbd配置文件定义新的rbd帐户的访问权限。客户端应用程序可以使用此帐户使用RADOS块设备对Ceph存储进行基于块的访问。
- 命令:ceph auth get-or-create client.username mon 'profile rbd' osd 'profile rbd'
[ceph: root@node /]# ceph auth get-or-create client.forrbd mon 'profile rbd' osd 'profile rbd'
[ceph: root@node /]# ceph auth get client.forrbd
[client.forrbd]key = AQCrnOVlLyh0CxAAy18Sb0sxNe8TXvjWWFS35Q==caps mon = "profile rbd"caps osd = "profile rbd"The rbd-read-only profile works the same way but grants read-only access.
rbd-read-only 配置文件的工作方式相同,但授予只读访问权限。
Ceph utilizes other existing profiles for internal communication between daemons.
Ceph利用其他现有配置文件在守护进程之间进行内部通信。
You cannot create your own profiles, Ceph defines them internally.
您不能创建自己的配置文件,Ceph在内部定义了它们。
profile osd, profile rbd, profile rbd-read-only, profile bootstrap-osd
7、限制访问
Restrict user OSD permissions such that users can only access the pools they need.
限制用户仅可以访问特定存储池。
-
命令:ceph auth get-or-create client.username mon 'profile rbd' osd 'profile rbd' pool=poolname
[ceph: root@node /]# ceph auth get-or-create client.formyapp2 mon 'allow r' osd 'allow rw pool=myapp'
# ceph auth get client.formyapp2
[client.formyapp2]key = AQAlnuVltHHUDRAA3nlf1ACwMjMxJ9VgO9NM8g==caps mon = "allow r"caps osd = "allow rw pool=myapp"如果在配置功能时没有指定池,则代表对所有存储池具有权限。
Cephx机制可以通过其他方式限制对对象的访问:
- 通过对象名称前缀限制。例子:限制了对所有池中以pref开头的对象的访问:
mon 'allow r' osd 'allow rw object_prefix pref'
[ceph: root@node /]# ceph auth get-or-create client.formyapp3 mon 'allow r' osd 'allow rw object_prefix pref'- 通过命名空间进行限制。创建命名空间,以便对池中的对象进行逻辑分组。然后,您可以将用户帐户限制为属于特定命名空间的对象:
mon 'allow r' osd 'allow rw namespace=photos'
[ceph: root@node /]# ceph auth get-or-create client.designer mon 'allow r' osd 'allow rw namespace=photos'- 通过路径限制。Ceph文件系统(cepfs)利用这种方法来限制对特定目录的访问。下面的例子创建了一个新的用户账号webdesigner,它只能访问/webcontent目录及其内容:
/webcontent rw
[ceph: root@node /]# ceph fs authrize cephfs client.webdesigner /webcontent rw
[ceph: root@node /]# ceph auth get client.webdesigner- 通过Monitor命令限制。此方法将管理员限制为特定的命令列表。创建一个名为operator1的用户帐户,并限制其只能访问两个命令:
mon 'allow r, allow command "auth get-or-create", allow command "auth list"'
[ceph: root@node /]# ceph auth get-or-create client.operator1 mon 'allow r, allow command "auth get-or-create", allow command "auth list"'8、用户管理
1)需要列出现有的用户帐号,使用ceph auth list命令:
-
命令:ceph auth list
[ceph: root@node /]# ceph auth list
osd.0key: AQCn1VZhlW2DLhAAJYKaCwX7ycDCqEDPxERjkA==caps: [mgr] allow profile osdcaps: [mon] allow profile osdcaps: [osd] allow *
... ...2)要获取特定帐户的详细信息,使用ceph auth get命令:
-
命令:ceph auth get client.admin
[ceph: root@node /]# ceph auth print-key client.admin ;echo //;echo 换行显示
AQA11VZhyq8VGRAAOus0I5xLWMSdAW/759e32A==3)您可以使用ceph auth print-key打印密钥:
-
命令:ceph auth print-key client.admin
[ceph: root@node /]# ceph auth print-key client.admin ;echo //;echo 换行显示
AQA11VZhyq8VGRAAOus0I5xLWMSdAW/759e32A==4)需要导出和导入用户帐号,使用ceph auth export和ceph auth import命令。
-
命令:ceph auth export client.username > ~/username.export
-
命令:ceph auth import -i ~/username.export
[ceph: root@node /]# ceph auth export client.operator1 > ~/operator1.export
[ceph: root@node /]# ceph auth import -i ~/operator1.export9、创建新用户
ceph auth get-or-create命令创建一个新的用户帐户并生成它的密钥。默认情况下,该命令将此密钥打印到stdout,因此通常添加-o选项以将标准输出保存到密钥环文件中。下面的例子创建了一个用户名为app1的帐户,该帐户拥有对所有池的读写权限,并将keyring文件存储在/etc/ceph/ceph.client.app1.keyring中:
- 命令:ceph auth get-or-create client.username mon 'allow r' osd 'allow rw' -o /etc/ceph/ceph.client.username.keyring
[ceph: root@node /]# ceph auth get-or-create client.app1 mon 'allow r' osd 'allow rw' -o /etc/ceph/ceph.client.app1.keyring身份验证需要密钥环key-ring文件,因此必须将该文件复制到使用此新用户帐户操作的所有客户机系统。
10、修改用户权限
示例:修改了osd上的app1用户帐户功能,使其只允许对myapp池进行读写访问:
-
命令:ceph auth caps client.username mon 'allow r' osd 'allow rw pool=pool_name'
[ceph: root@node /]# ceph auth caps client.app1 mon 'allow r' osd 'allow rw pool=myapp'
updated caps for client.app1定义一个空字符串来删除所有功能:
-
命令:ceph auth caps client.username osd ' '
[ceph: root@node /]# ceph auth caps client.app1 osd ''
updated caps for client.app111、删除用户
ceph auth del命令用来删除用户帐户:
-
命令:ceph auth del client.username
[ceph: root@node /]# ceph auth del client.app1
update然后可以删除关联的密钥环文件。
Lab: 管理Ceph身份验证
1. 创建存储池及用户账户并授权
Login to serverc as root user.
[root@foundation0 ~]# ssh root@serverc创建一个名为replpool1的复制池,包含64个PG(pg)。
[root@serverc ~]# cephadm shell --mount /etc/ceph:/etc/ceph
[ceph: root@serverc /]# ceph osd pool create replpool1 64 64
pool 'replpool1' created
[ceph: root@serverc /]# ceph osd pool ls在reppool1池的docs命名空间中创建具有读写功能的client.docedit的用户。使用适当的目录和文件名保存关联的密钥环文件:/etc/ceph/ceph.client.docedit.keyring
[ceph: root@serverc /]# ceph auth get-or-create client.docedit \
mon 'allow r' osd 'allow rw pool=replpool1 namespace=docs' | tee \
/etc/ceph/ceph.client.docedit.keyring在replpool1池的docs命名空间中创建具有读取功能的client.docget用户。使用适当的目录和文件名保存关联的密钥环文件:/etc/ceph/ceph.client.docget.keyring
[ceph: root@serverc /]# ceph auth get-or-create client.docget \
mon 'allow r' osd 'allow r pool=replpool1 namespace=docs' | tee \
/etc/ceph/ceph.client.docget.keyring验证您是否正确创建了两个用户名。
[ceph: root@serverc /]# ceph auth ls | grep -A 3 -ie docedit -ie docget
client.doceditkey: AQCMID5jxN1yERAAKQdBFR7C0HTQ24khgHnbtA==caps: [mon] allow rcaps: [osd] allow rw pool=replpool1 namespace=docs
client.docgetkey: AQArID5jqVqJMBAABA+pCpFbOOhAoVvWfL/i0Q==caps: [mon] allow rcaps: [osd] allow r pool=replpool1 namespace=docs
installed auth entries:[ceph: root@serverc /]# exitgrep -A //表示在显示匹配行的同时,还要显示该行之后的指定行数。(-A 是 "after" 的缩写,即“之后”的意思。使用 grep -A 时,你可以指定一个数值来告诉 grep 在每个匹配行之后额外显示多少行。)
grep 还有两个类似的选项:-B 和 -C。
-B 用于显示匹配行之前的内容("before"),
-C 则同时显示匹配行之前和之后的内容("context")。
这些选项在需要了解匹配行上下文的情况下非常有用。
2. 密钥环文件复制到该服务器
您的应用程序在服务器上运行。将用户的密钥环文件复制到该服务器,以允许应用程序使用集群进行身份验证。
[root@serverc ~]# rsync -v /etc/ceph/ceph.client.docedit.keyring serverd:/etc/ceph/
[root@serverc ~]# rsync -v /etc/ceph/ceph.client.docget.keyring serverd:/etc/ceph/使用带--mount选项的cephadm shell来挂载/etc/ceph目录。存储和检索对象以验证密钥环是否正常工作。这两个文件应该是相同的,因为diff命令没有显示任何输出。
[root@serverd ~]# cephadm shell --mount /etc/ceph:/etc/ceph
[ceph: root@serverd /]# rados --id docedit -p replpool1 -N docs put adoc /etc/hosts
[ceph: root@serverd /]# rados --id docedit -p replpool1 -N docs ls
adoc
//--id指定用户,-p指定存储池,-N指定命名空间,put子命令代表上传文件(/etc/hosts),叫adoc[ceph: root@serverd ~]# rados --id docget -p replpool1 -N docs get adoc /tmp/test
//下载docs命名空间中的adoc文件,下载到/tmp/test
[ceph: root@serverd /]# ls /tmp/test
/tmp/test
[ceph: root@serverd ~]# diff /etc/hosts /tmp/test3. 确认cllient.docget用户只授予r权限
确认cllient.docget用户不能在reppool1池的docs命名空间中存储对象:(因为只授予r权限)
[ceph: root@serverc ~]# rados --id docget -p replpool1 -N docs put writetest /etc/hosts
error putting mypool/writetest: (1) Operation not permitted4. 修改cllient.docget用户权限
授予cllient.docget用户在replpool1池中的docs名称空间上的读写能力,以及在 non-yet-created的 docarchive池 上的读写能力。确认cllient.docget用户现在可以在docs命名空间中存储对象。
[ceph: root@serverc ~]# ceph auth caps client.docget mon 'allow r' osd 'allow rw pool=replpool1 namespace=docs, allow rw pool=docarchive'
//测试
[ceph: root@serverc /]# rados --id docget -p replpool1 -N docs put writetest /etc/hosts
[ceph: root@serverc /]# rados --id docget -p replpool1 -N docs ls
adoc
writetest
注意:ceph auth caps命令会覆盖之前的权限设置,所以权限需要写全部所有权限。
补充:定义权限时可以对未创建的存储池设置权限。
退出cephadm shell,并通过删除客户端进行清理 client.docedit 和 client.docget用户,删除关联的密钥环文件。
[ceph: root@serverc ~]# exit
[root@serverc ~]# rm /etc/ceph/ceph.client.docedit.keyring
[root@serverc ~]# rm /etc/ceph/ceph.client.docget.keyring
[root@serverc ~]# ssh serverd rm /etc/ceph/ceph.client.docedit.keyring
[root@serverc ~]# ssh serverd rm /etc/ceph/ceph.client.docget.keyring[root@serverc ~]# cephadm shell -- ceph auth del client.docedit
[root@serverc ~]# cephadm shell -- ceph auth del client.docget## 创建用户client.forrbd,并通过提前设置好的profile授权,rbd是profile的名称
## 授权用户可以访问块存储,和rbd类似的另一个名称为 rbd-read-only 的profile可以授权用户对块存储只读的权限。
[ceph@serverc ~]$ cephadm shell -- ceph auth get-or-create client.forrbd mon 'profile rbd' osd 'profile rbd'
# 创建用户client.formyapp3,限制该用户仅可以对任何存储池中的对象名称以pref开始的文件有读写权限。
[ceph@serverc ~]$ cephadm shell -- ceph auth get-or-create client.formyapp3 mon 'allow r' osd 'allow rw object_prefix pref'
# 创建operator1用户,限制它仅可以执行auth get-or-create和auth list命令。
[ceph@serverc ~]$ cephadm shell -- ceph auth get-or-create client.operator1 mon 'allow r, allow command "auth get-or-create", allow command "auth list"'
[root@serverc ~]# cephadm shell -- ceph auth list | grep -A 3 -ie forrbd -ie formyapp3 -ie operator1认证流程:
思维导图:
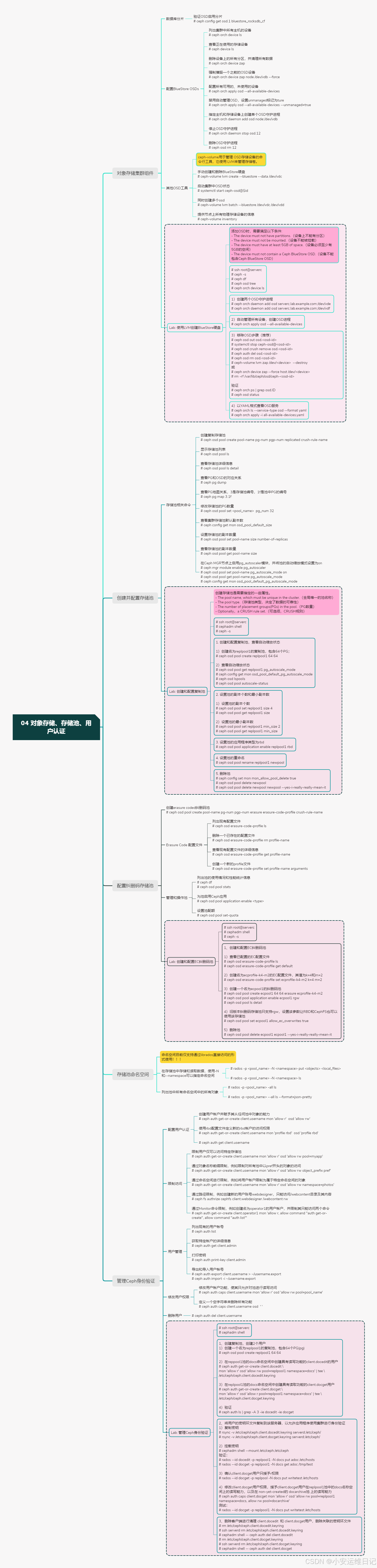
小结:
本篇为 【RHCA认证 - CL260 | Day04:对象存储、存储池、用户认证】的开篇学习笔记,希望这篇笔记可以让您初步了解到 BlueStore 架构,如何使用逻辑卷创建BlueStore硬盘、如何创建和配置复制池、配置纠删码存储池,如何管理Ceph身份验证,不妨跟着我的笔记步伐亲自实践一下吧!
Tip:毕竟两个人的智慧大于一个人的智慧,如果你不理解本章节的内容或需要相关环境、视频,可评论666并私信小安,请放下你的羞涩,花点时间直到你真正的理解。