大模型后训练——Online-RL基础
大型语言模型在能够执行指令和回答问题之前,需要经历预训练(Pre-training)和后训练(Post-training)两个核心阶段。
- 预训练阶段,模型通过学习从海量未标注的文本中预测下一个词或token来掌握基础知识。而在后训练阶段,模型则着重学习实际应用中的关键能力,包括准确理解并执行指令、熟练运用工具,以及进行复杂的逻辑推理。
- 后训练是将在海量无标签文本上训练的原始的通用语言模型转变为能够理解并执行特定指令的智能助手的过程。无论是想打造一个更安全的 AI 助手、调整模型的语言风格,还是提升特定任务的精确度,后训练都不可或缺。
后训练是大语言模型训练中发展最迅速的研究方向之一。
而在本课程中,就可以学习到三种常见的后训练方法——监督微调(SFT)、直接偏好优化(DPO)和在线强化学习(Online RL)——以及如何有效使用它们。
学习地址:Online-RL基础。
在本课中,我们将学习有关在线强化学习的基本概念,包括RL中高质量数据管理的方法、常见用例和原则。首先看看在线学习与离线学习语言模型强化学习的细微差异。
- 在在线学习中,通常模型通过实时生成新响应来学习,迭代地收集新响应及其相应的奖励,并在模型进一步学习和更新自身时使用该响应和奖励来更新其权重并强制执行新响应。
- 而相比之下,在离线学习中,模型纯粹从预先收集的提示响应或奖励元组中学习,在学习过程中不会产生新的响应。

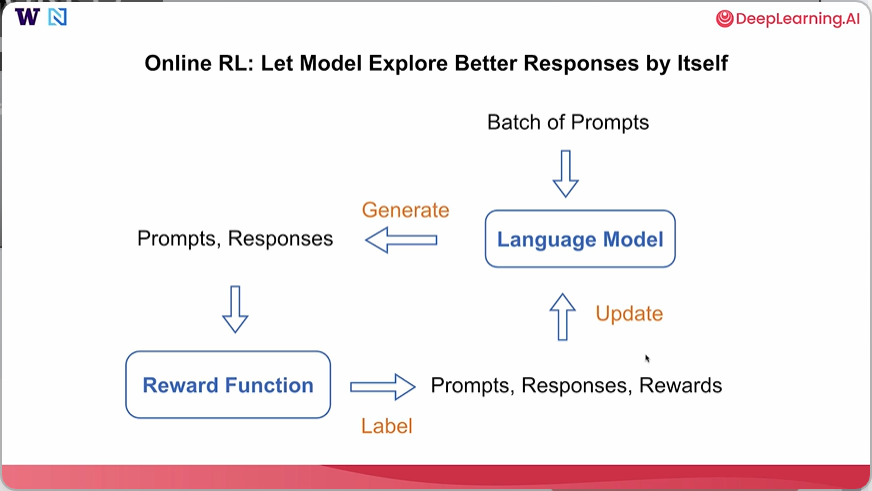
下面更详细地概述一下在线强化学习的工作原理:它通常是通过让模型自行探索更好的回应来实现的。通常我们可以从一批提示开始,将其发送到现有的语言模型,语言模型会根据这些提示生成相应的回应。在我们得到提示和回应的配对后,我们会将其发送到一个奖励函数,该奖励函数负责为每个提示和回应标注一个奖励。然后我们得到一个包含提示、回应和奖励的元组,我们将使用这个元组来更新语言模型。在这里,语言模型的更新可以使用不同的要素。我们将介绍其中两种,即近端策略优化(PPO)和组相对策略优化(GRPO)。
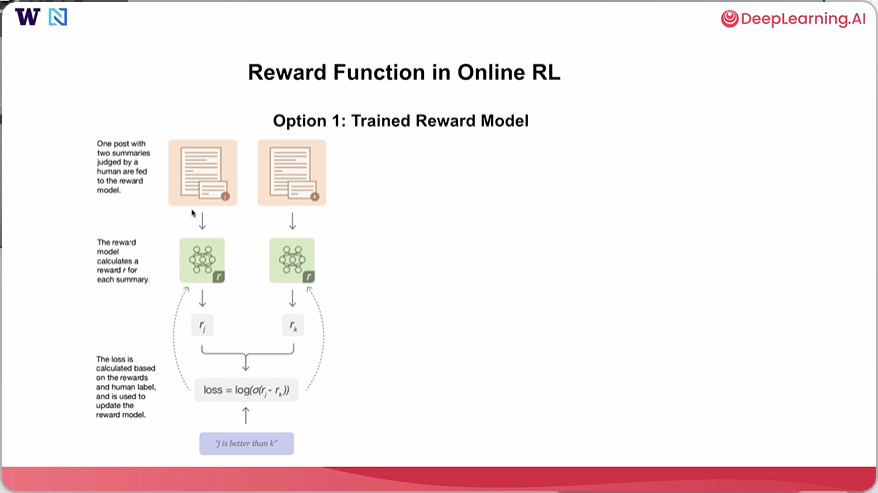
关于在线强化学习中奖励函数的不同选择。这里的第一个选择可以是一个经过训练的奖励模型。在这个模型中,你可以让模型生成多个回复,或者从不同来源收集回复,然后由人类进行评判。然后在训练过程中,我们会得到一个奖励模型。理想情况下,这个模型是根据这些数据训练出来的,它会为每个总结计算奖励。我们可以设计一个损失函数,根据奖励和人类标注来计算,这里的损失函数是两个奖励差值的 sigmoid 函数的对数,可用于更新奖励模型。
本质上,当人类标注者说回复 J 比回复 K 更好时,我们会设计损失函数,使得我们鼓励给回复 J 更高的奖励,抑制给回复 K 更高的奖励。通过这种方式,我们可以训练一个模型,让更受青睐的回复总是比不太受青睐的回复获得更高的奖励。
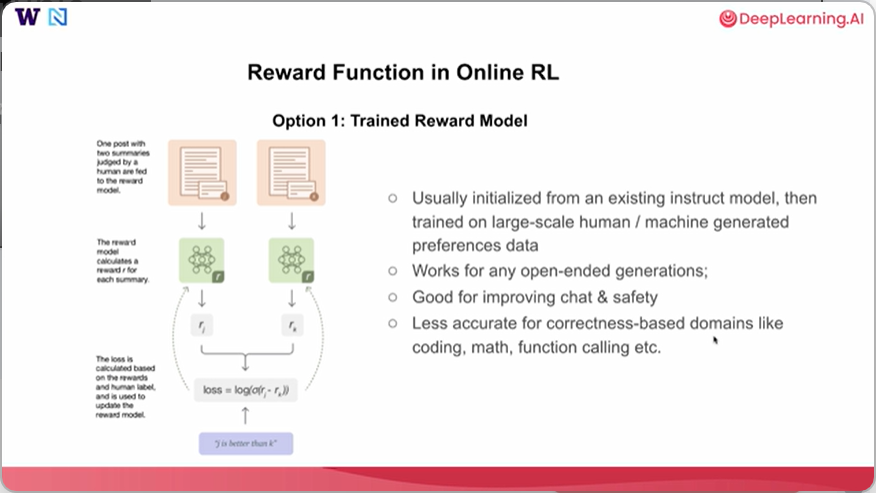
奖励模型通常从现有的指令模型初始化。然后在大规模的人类或机器生成的偏好数据上进行训练,这样的奖励模型适用于任何开放式生成任务。它在提升聊天能力或安全相关领域也很有效,但对于基于正确性的领域,比如硬编码、数学问题或函数调用等用例,可能准确性会稍低。
关于奖励函数第二个选择,可以为这些正确性领域设计一些可验证的奖励。例如,在数学领域,可以检查响应是否与给定的基本事实相匹配。如果我有一个提示和相应的响应,我们可以检查响应提供的确切答案是否与提供的事实相匹配。对于编码问题,我们可以通过运行单元测试来验证编码结果的正确性。
因此,如果提示给出了编码问题和响应,正确编写代码,我们总是可以以测试输入和理想测试输出的格式编写和提供大量的单元测试,然后询问代码,看看执行结果是否与这里提供的测试输出中的输出相匹配。通常可验证的奖励需要更多的努力来准备,比如说数学数据集的基本实况。然而,这里的努力真正得到了回报,因为它为我们提供了一个更可靠的奖励函数,甚至比这些领域的奖励模型更精确。它的工作方式也更经常用于训练推理模型,这在编码、数学等问题上非常好。

那么接下来,让我们更深入地比较两种流行的在线强化学习算法。第一种是近端策略优化(Proximal Policy Optimization,简称PPO),它被用于创建ChatGPT的第一个版本。第二种是群体相对策略优化(group relative policy optimization,简称GRPO),它由DeepSeek提出,并在DeepSeek的大部分训练中使用。
让我们先来看看PPO。通常,从一组查询 q 开始,将其发送到一个策略模型。这里的策略模型本质上就是一个语言模型本身,目的是对其进行更新和训练。这里的黄色模块通常指那些权重可更新的训练模型。稍后我们会看到蓝色模块,它们是权重实际上被冻结且在过程中不会更新的冻结模型。
所以,一旦我们将大多数查询发送到策略模型或语言模型本身,模型就会生成输出和响应,这里用 O 表示,并且软响应将提供给三个不同的模型。
- 第一个是参考模型,它是原始模型的副本,主要用于计算一些代码差异,希望借此能让语言模型与原始权重相比变化不会太大。
- 第二个是奖励模型,它接收查询的输入并在此处输出一个奖励,以对策略模型进行更新。
- 第三个是可训练的价值模型或评判模型,软评判模型试图将其分配给每个单独的标记,以便将那些响应级别的奖励分解为标记级别的奖励。
实际上,在我们得出奖励以及值函数或值模型的输出后,我们将使用一种称为广义优势估计的技术来估计这里称为优势 A 的概念,该概念试图通过观察个体优势来描述每个单独标记的贡献,即每个单独标记对整个响应的贡献,我们可以将其作为一种信号来指导策略模型的更新。
所以在近端策略优化算法(PPO)中,本质上你是在尝试最大化当前策略 的回报或优势。但由于你无法直接从最新的模型
中采样,在这个PPO目标函数公式中有一个重要的采样技巧。本质上,我们想要最大化一个期望优势,即
,这里的期望是基于
计算的,但我们只从某个语言模型的前一步得到数据,即旧的
。所以我们对旧的
生成的响应取期望,然后设计一个重要的比率,即
与旧的
的比率。其中,旧的
是前序步骤的语言模型,而
是当前步骤的语言模型。
通过这种方式,你本质上是在尝试最大化当前策略 的期望优势。并且在这个PPO损失函数中还有一些更多的细节,它试图控制这个比率,在训练过程中这个比率不会太大或太小。它还取直接比率乘以优势和裁剪比率乘以优势两者中的最小值。因此,这样的PPO利用了一种基于重要采样的方法,试图为给定的当前策略
最大化优势,这基本上就是关于PPO的大部分细节。
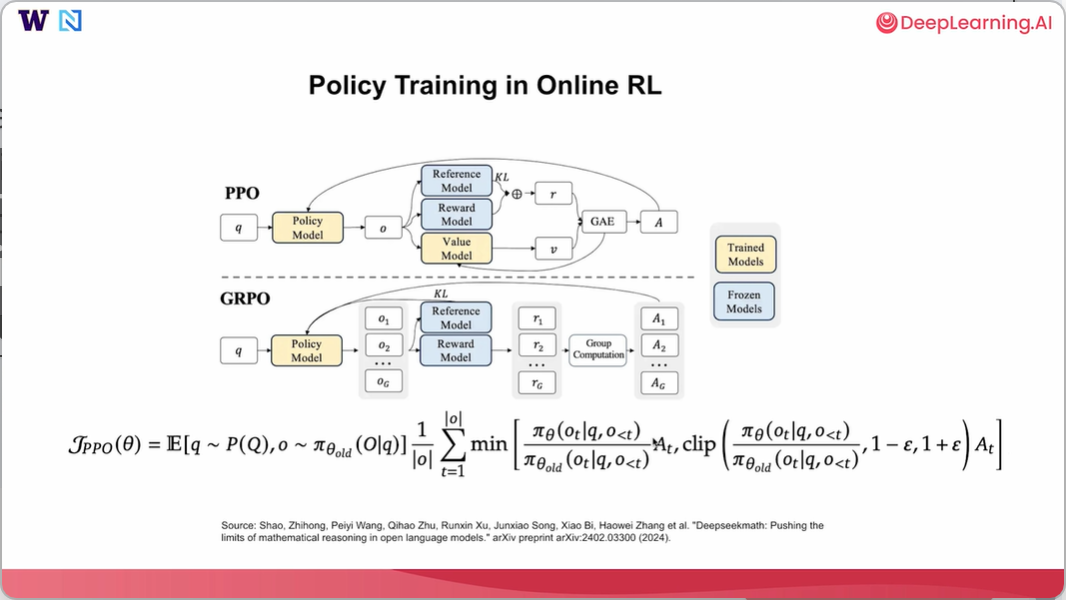
现在,我们来探讨一下GRPO。GRPO实际上与PPO非常相似,因为它同样使用优势函数,并通过几乎完全相同的公式来更新语言模型。但这里的主要区别在于计算优势函数的方式。与PPO类似,仍然从一个查询 q 开始,将其发送到策略模型。在这种情况下,策略模型会生成多个响应,即 到
作为一组。对于每个提示,会生成两个响应,并且仍然使用参考模型和奖励模型来计算每个响应的差异对和奖励。然后,针对同一查询得到一组多个输出和多个奖励。接着,使用一些分组计算来计算每个输出的相对奖励,并假设相对奖励就是每个单独token的优势。通过这种方式,得到每个token优势的更直接的估计值,并使用该优势来更新策略模型。
所以实际上,在得到优势之后,PPO和GRPO非常相似。 主要区别在于优势估计的方式,近端策略优化算法(PPO)实现了我们实际的价值模型,这个模型在整个过程中都需要训练,而广义近端策略优化算法(GRPO)则摆脱了这个价值模型,因此在内存使用上更高效。尽管摆脱这样一个价值模型的代价是,优势估计可能会更简单粗暴,并且对于同一回复中的每个token,优势值保持不变。
- 而对于近端策略优化算法(PPO),每个单独的token优势可能不同。简而言之,近端策略优化算法(PPO)所做的是使用一个实际的价值模型或评判模型为每个单独的token分配权重,通过这种方式,在整个生成过程中,每个单词或token将有不同的优势值,这表明哪个token更重要,哪个token不那么重要。
- 而在广义近端策略优化算法(GRPO)中,由于我们去掉了安全价值模型或评判模型,只要token在同一输出中,每个词token就会有相同的优势。所以,近端策略优化算法(PPO)通常会为每个单独的token提供更精细的优势反馈。而广义近端策略优化算法(GRPO)则为同一回复中的token提供更统一的优势。
最后,我想更详细地比较一下广义近端策略优化算法(GRPO)和近端策略优化算法(PPO)之间的用例。GRPO和PPO都是非常有效的在线强化学习算法,GRPO的设计更适合基于二元或正确性的奖励。如果只对完整回复而不是单个标记进行奖励分配的特性,你确实需要大量样本,那么GRPO是个不错的选择。不过,由于这里不需要价值模型,GRPO所需的内存更少。相比之下,PPO通常在奖励模型或二元奖励方面都能很好地工作,并且在涉及到训练良好的价值函数时,它的样本效率可能更高。然而,由于实际的价值模型,它可能需要更多的GPU内存。

所以在这节课中,我们学习了离线强化学习和在线强化学习之间的区别,并深入探讨了GRPO和PPO这两种算法。在下一节课中,我们将使用GRPO来提高指令模型的掩码能力。