五、Envoy集群管理
因语雀和CSDN MarkDown格式有区别,导入到CSDN时可能会有格式显示问题,请查看原文链接:
https://www.yuque.com/dycloud/pss8ys
一、Cluster Manger 详解
1.1 Cluster Manger 定义
Envoy 中的 Cluster Manager 是流量管理的核心组件,负责管理所有上游集群(如后端服务集群)的配置、状态和连接池。以下是详细说明:
| 功能 | 说明 |
|---|---|
| 集群生命周期管理 | 负责集群的创建、更新、销毁(通过 xDS 动态配置或静态配置) |
| 连接池管理 | 维护到后端实例的 TCP/HTTP 连接池,复用连接降低延迟 |
| 负载均衡 | 集成负载均衡算法(Round Robin、Least Request 等),分配流量到健康实例 |
| 健康检查 | 主动监控后端健康状态,隔离故障节点 |
| 流量控制 | 实现熔断、限流、异常检测(Outlier Detection) |
| 协议协商 | 处理 HTTP/1.1、HTTP/2、gRPC 等协议的转换与优化 |
Envoy 支持同时配置任意数量的上游集群,并基于 Cluster Manger 管理他们:
- Cluster Manager 负责为集群管理上游主机的健康状态、负载均衡机制、链接类型及使用协议等。
- 生成集群配置的方式有静态或动态(CDS)两种
{"transport_socket_matches": [],"name": ...,"alt_stat_name": ...,"type": ...,"cluster_type": {...},"eds_cluster_config": {...},"connect_timeout": {...},"per_connection_buffer_limit_bytes": {...},"lb_policy": ...,"load_assignment": {...},"health_checks": [],"max_requests_per_connection": {...},"circuit_breakers": {...},"upstream_http_protocol_options": {...},"common_http_protocol_options": {...},"http_protocol_options": {...},"http2_protocol_options": {...},"typed_extension_protocol_options": {...},"dns_refresh_rate": {...},"dns_jitter": {...},"dns_failure_refresh_rate": {...},"respect_dns_ttl": ...,"dns_lookup_family": ...,"dns_resolvers": [],"use_tcp_for_dns_lookups": ...,"dns_resolution_config": {...},"typed_dns_resolver_config": {...},"wait_for_warm_on_init": {...},"outlier_detection": {...},"cleanup_interval": {...},"upstream_bind_config": {...},"lb_subset_config": {...},"ring_hash_lb_config": {...},"maglev_lb_config": {...},"original_dst_lb_config": {...},"least_request_lb_config": {...},"round_robin_lb_config": {...},"common_lb_config": {...},"transport_socket": {...},"metadata": {...},"protocol_selection": ...,"upstream_connection_options": {...},"close_connections_on_host_health_failure": ...,"ignore_health_on_host_removal": ...,"filters": [],"load_balancing_policy": {...},"lrs_report_endpoint_metrics": [],"track_timeout_budgets": ...,"upstream_config": {...},"track_cluster_stats": {...},"preconnect_policy": {...},"connection_pool_per_downstream_connection": ...
}
上面是 Cluster 的完整配置,下面来学习下常用的一些配置
1.2 集群预热(Cluster Warmup)
集群在服务器启动或者通过 CDS 进行初始化时需要一个预热的过程,这意味着集群存在下列状况
- 初始服务发现加载 (例如DNS 解析、EDS 更新等)完成之前不可用
- 配置了主动健康状态检查机制时,Envoy会主动发送健康状态检测请求报文至发现的每个上游主机;于是,初始的主动健康检查成功完成之前不可用
当新节点加入或配置更新时,Envoy 不会立即将全部流量切换到新节点,而是**渐进式增加流量**,避免冷启动问题
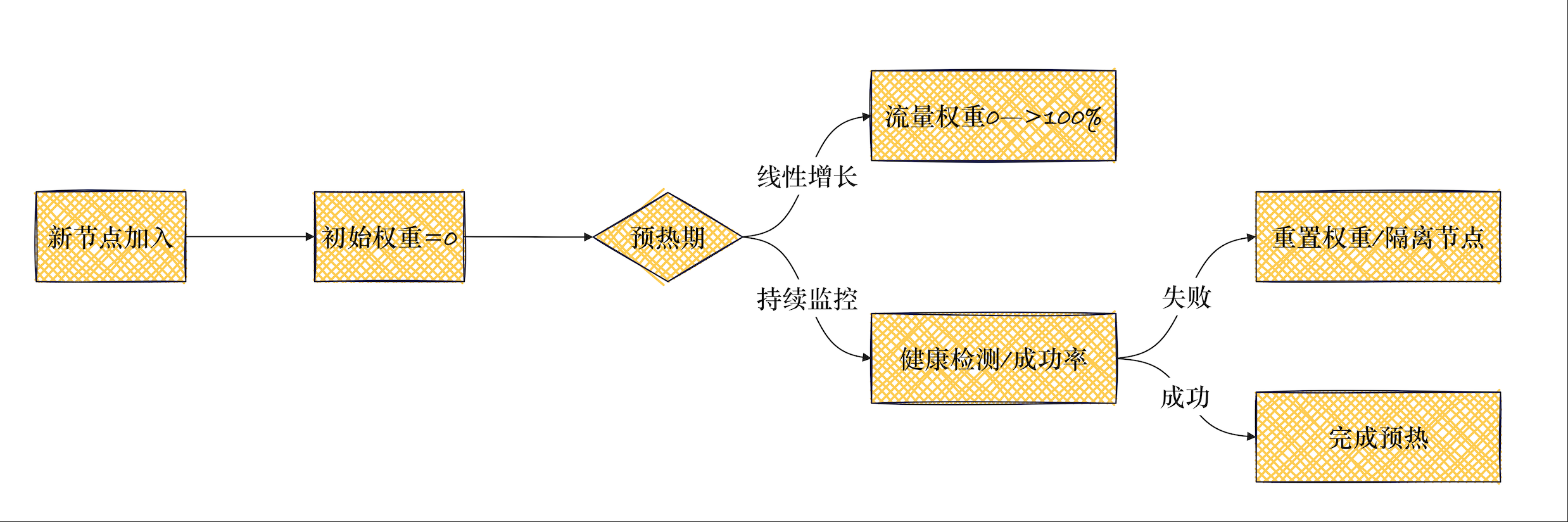
集群预热配置:
https://www.envoyproxy.io/docs/envoy/v1.35.0/api-v3/config/cluster/v3/cluster.proto#envoy-v3-api-msg-config-cluster-v3-cluster-slowstartconfig
clusters:
- name: webclusterconnect_timeout: 1slb_policy: ROUND_ROBIN# 集群预热配置slow_start_config:slow_start_window: 60s # 预热时间窗口aggression: 1.0 # 流量增长系数(1.0=线性)min_weight_percent: 10% # 初始最小流量权重common_lb_config:healthy_panic_threshold: 50% # 最低健康节点比例1.3 服务发现
https://www.envoyproxy.io/docs/envoy/v1.35.0/intro/arch_overview/upstream/service_discovery#arch-overview-service-discovery-types
服务发现是Envoy确定上游服务实例(endpoints)位置的关键配置。在Envoy中,服务发现通过<font style="color:rgb(251, 71, 135);">cluster</font>配置中的<font style="color:rgb(251, 71, 135);">type</font>字段指定,主要支持以下几种类型:
1.3.1 STATIC
静态配置,直接在配置文件中写死端点列表
clusters:
- name: static_clustertype: STATICload_assignment:cluster_name: static_clusterendpoints:- lb_endpoints:- endpoint:address:socket_address: address: 192.168.1.10port_value: 8080- endpoint:address:socket_address: address: 192.168.1.11port_value: 80801.3.2 STRICT_DNS
严格DNS模式。Envoy会定期解析配置的DNS域名,并将解析结果作为端点。如果DNS返回多个IP,Envoy会使用所有IP。Envoy会持续监控DNS变化(根据<font style="color:#DF2A3F;">dns_refresh_rate</font>配置)。
clusters:
- name: dns_clustertype: STRICT_DNSdns_lookup_family: V4_ONLY # 解析类型:V4_ONLY/V6_ONLY/AUTOdns_refresh_rate: 5s # DNS 刷新间隔respect_dns_ttl: false # 是否遵循 DNS TTLload_assignment:cluster_name: dns_clusterendpoints:- lb_endpoints:- endpoint:address:socket_address: address: backend.service.consul # DNS 域名port_value: 801.3.3 LOGICAL_DNS
逻辑DNS模式。与<font style="color:#DF2A3F;">STRICT_DNS</font>类似,但只在需要建立新连接时才使用DNS解析结果(不主动缓存和更新所有记录)。适用于大型DNS轮询场景。它不会像<font style="color:#DF2A3F;">STRICT_DNS</font>那样预解析所有地址,而是按需使用,如访问由DNS负载均衡的服务(如AWS ELB)。
1.3.4 EDS
通过<font style="color:#262626;">xDS API</font>动态获取端点。这是服务网格(如Istio)中最常用的方式。端点由控制平面(如Istio Pilot)动态下发,支持复杂负载均衡和健康状态管理。
clusters:
- name: eds_clustertype: EDSeds_cluster_config:eds_config:resource_api_version: V3api_config_source:api_type: GRPCtransport_api_version: V3grpc_services:- envoy_grpc:cluster_name: xds_cluster # xDS 服务器集群1.3.5 ORIGINAL_DST
使用下游连接的原始目标地址作为上游地址。通常用于透明代理。当连接通过<font style="color:#DF2A3F;">iptables</font>重定向到Envoy时,Envoy会提取原始目标地址。
clusters:
- name: original_dst_clustertype: ORIGINAL_DSTlb_policy: CLUSTER_PROVIDED
1.3.6 最终一致性
最终一致性(Eventual Consistency) 指当服务实例发生变化(新增/下线)时:
- 不同组件(Envoy代理、控制平面)不会立即看到相同状态
- 经过一段时间后,所有组件会收敛到一致状态
Envoy的服务发现并未采用完全一致的机制,而是假设主机以最终一致的方式加入或离开网格,它结合主动健康状态检查机制来判定集群的健康状态;
- 健康与否的决策机制以完全分布式的方式进行,因此可以很好地应对网络分区
- 为集群启用主机健康状态检查机制后,Envoy基于如下方式判定是否路由请求到一个主机
| Discovery Status | Health Check OK | Health Check Failed |
|---|---|---|
| Discovered | Route | Don’t Route |
| Absent | Route | Don’t Route / Delete |
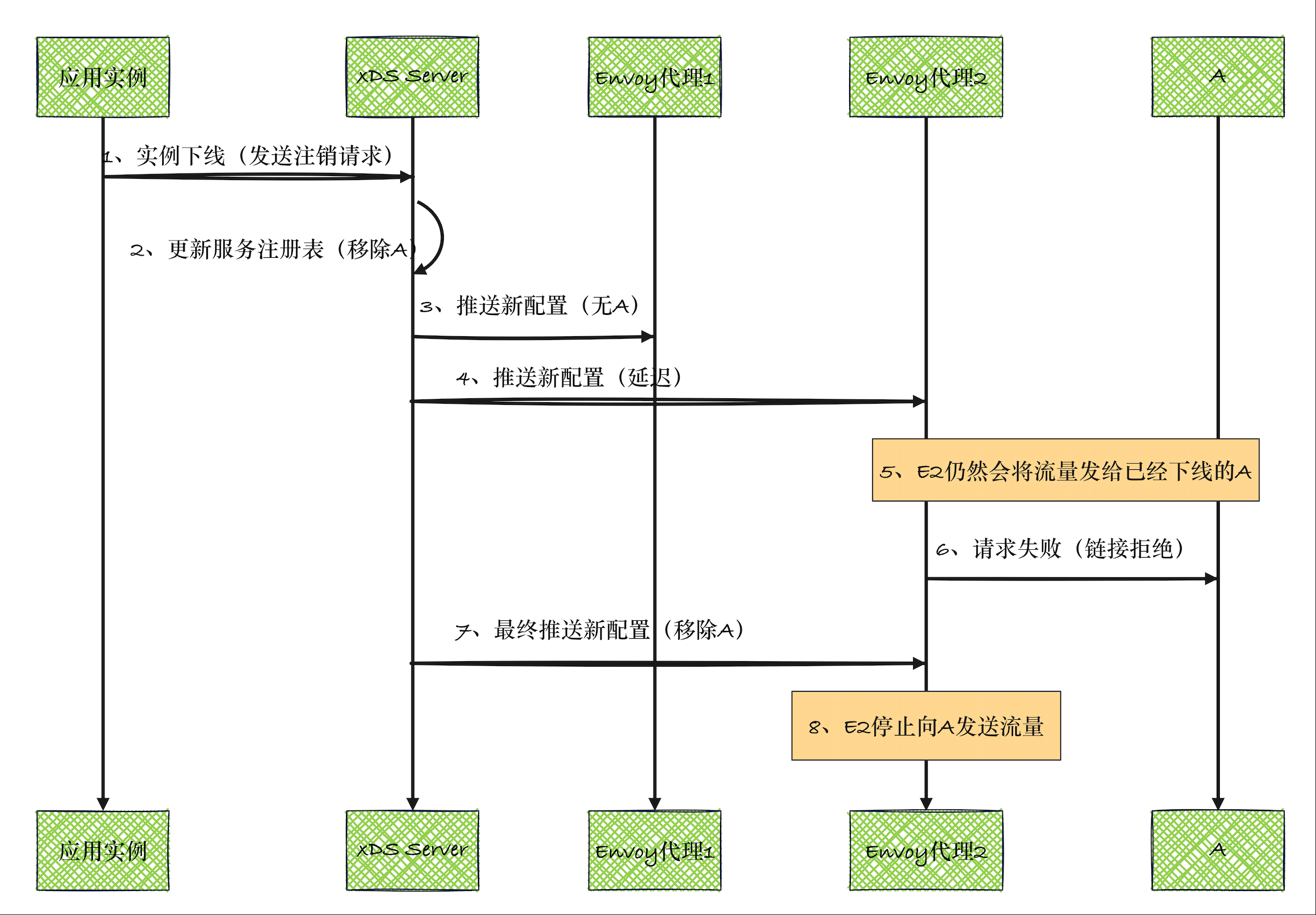
| 时间 | 控制平面 | Envoy 1 | Envoy 2 | 一致性状态 |
|---|---|---|---|---|
| T0 | 记录实例A,B,C | 已知A,B,C | 已知A,B,C | 强一致 |
| T1 | 收到A下线请求 | - | - | 不一致开始 |
| T2 | 移除A,版本v2 | 仍为v1(A,B,C) | 仍为v1(A,B,C) | 不一致 |
| T3 | 推送v2到Envoy1 | 更新为v2(B,C) | v1(A,B,C) | 不一致 |
| T4 | 推送v2到Envoy2 | v2(B,C) | 仍为v1(A,B,C) | 不一致 |
| T5 | - | - | 更新为v2(B,C) | 最终一致 |
1.4 Upstreams 健康状态检测
https://www.envoyproxy.io/docs/envoy/v1.35.0/api-v3/config/core/v3/health_check.proto#envoy-v3-api-msg-config-core-v3-healthcheck
健康状态检测用于确保代理服务器不会将下游客户端的请求代理至工作异常的上游主机;
Envoy支持两种类型的健康状态检测,二者均基于集群进行定义
<font style="color:#DF2A3F;">主动检测(Active Health Checking)</font>:Envoy周期性地发送探测报文至上游主机,并根据其响应判断其健康状态;Envoy目前支持三种类型的主动检测:<font style="color:rgb(243,193,9);"></font><font style="color:rgb(0,0,0);">HTTP</font>:向上游主机发送HTTP请求报文<font style="color:rgb(243,193,9);"></font><font style="color:rgb(0,0,0);">L3/L4</font>:向上游主机发送L3/L4请求报文,基于响应的结果判定其健康状态,或仅通过连接状态进行判定;<font style="color:rgb(243,193,9);"></font><font style="color:rgb(0,0,0);">Redis</font>:向上游的redis服务器发送Redis PING ;
<font style="color:#DF2A3F;">被动检测(Passive Health Checking)</font>:Envoy通过异常检测(Outlier Detection)机制进行被动模式的健康状态检测;- 目前,仅
<font style="color:#DF2A3F;">http router</font>、<font style="color:#DF2A3F;">tcp proxy</font>和<font style="color:#DF2A3F;">redis proxy</font>三个过滤器支持异常值检测; - Envoy支持以下类型的异常检测:
<font style="color:#DF2A3F;">连续5XX</font>:意指所有类型的错误,非http router过滤器生成的错误也会在内部映射为5xx错误代码;<font style="color:#DF2A3F;">连续网关故障</font>:连续5XX的子集,单纯用于http的502、503或504错误,即网关故障;<font style="color:#DF2A3F;">连续的本地原因故障</font>:Envoy无法连接到上游主机或与上游主机的通信被反复中断;<font style="color:#DF2A3F;">成功率</font>:主机的聚合成功率数据阈值;
- 目前,仅
1.4.1 Upstreams 主动健康状态检测
集群的主机健康状态检测机制需要显式定义,否则,发现的所有上游主机即被视为可用;定义语法:
clusters:- name: ... # 集群名称...load_assignment:endpoints:- lb_endpoints:- endpoint:health_check_config:port_value: ... # 自定义健康状态检测时使用的端口......health_checks:- timeout: ... # 超时时长interval: ... # 正常检测的时间间隔initial_jitter: ... # 初始检测时间点散开量(单位: 毫秒)interval_jitter: ... # 间隔检测时间点散开量(单位: 毫秒)unhealthy_threshold: ... # 连续多少次不健康后才标记为unhealthyhealthy_threshold: ... # 连续多少次健康后才标记为healthy(第一次健康即为healthy)http_health_check: {...} # HTTP类型健康检查(四选一, 必填一种)tcp_health_check: {...} # TCP健康检查grpc_health_check: {...} # gRPC健康检查custom_health_check: {...} # 自定义健康检查reuse_connection: ... # 是否重用连接, 默认 trueno_traffic_interval: ... # 无流量时的探测间隔unhealthy_interval: ... # 标记为unhealthy后的特殊探测间隔unhealthy_edge_interval: ... # 刚变unhealthy时的检测间隔healthy_edge_interval: ... # 刚变healthy时的检测间隔tls_options: {...} # TLS相关配置transport_socket_match_criteria: {...} # 匹配 transport socket 的kv对(可选)...1.4.1.1 主动健康状态检测:TCP
clusters:- name: local_serviceconnect_timeout: 0.25slb_policy: ROUND_ROBINtype: EDSeds_cluster_config:eds_config:api_config_source:api_type: GRPCgrpc_services:- envoy_grpc:cluster_name: xds_clusterhealth_checks:- timeout: 5sinterval: 10sunhealthy_threshold: 2healthy_threshold: 2tcp_health_check: {}空负载的tcp检测意味着仅通过连接状态判定其检测结果
非空负载的tcp检测可以使用<font style="color:#DF2A3F;">send</font>和<font style="color:#DF2A3F;">receive</font>来分别指定请求负荷及于响应报文中期望模糊匹配的结果;
health_checks:
- timeout: 2sinterval: 10stcp_health_check:# 发送两个字节:0x01 0x00send:text: "0100"# 期望响应:包含 "PONG" 或 "OK"receive:- text: "504F4E47" # "PONG" 的十六进制- text: "4F4B" # "OK" 的十六进制工作流程:
- 建立 TCP 连接
- 发送字节
<font style="color:rgb(251, 71, 135);">01 00</font> - 等待响应数据
- 验证响应是否包含
<font style="color:rgb(251, 71, 135);">PONG</font>或<font style="color:rgb(251, 71, 135);">OK</font>的十六进制值 - 响应匹配则标记健康
1.4.1.2 主动健康状态检测:HTTP
https://www.envoyproxy.io/docs/envoy/v1.35.0/api-v3/config/core/v3/health_check.proto#envoy-v3-api-msg-config-core-v3-healthcheck-httphealthcheck
http类型的检测可以自定义使用的path、host和期望的响应码等,并能够在必要时修改(添加
/删除)请求报文的标头 。
具体配置语法如下
health_checks:- timeout: ... # 例如: 5sinterval: ... # 例如: 10sunhealthy_threshold: ... # 例如: 2healthy_threshold: ... # 例如: 2http_health_check:host: ... # 检测时使用的主机Host头,默认为集群名称path: ... # 必需,例如: /healthzservice_name_matcher: ... # (可选)用于检查目标服务名称request_headers_to_add: # (可选)要添加的自定义Header列表- header:key: ...value: ...request_headers_to_remove: # (可选)要移除的header key列表- ...expected_statuses: # (可选)可接受的HTTP响应状态码范围- start: ... # 例如: 200end: ... # 例如: 204示例:
health_checks:
- timeout: 1sinterval: 5sunhealthy_threshold: 3healthy_threshold: 2http_health_check:path: /api/healthmethod: POSTrequest_headers_to_add:- header: { key: "Content-Type", value: "application/json" }request_headers_to_remove: ["X-Envoy-Internal"] # 移除指定头expected_statuses:- start: 200end: 200# 发送 JSON 请求体send: text: '{"check": true}'工作流程:
- 每 5s 发送
<font style="color:rgb(251, 71, 135);">POST /api/health</font>请求 - 包含头
<font style="color:rgb(251, 71, 135);">Content-Type: application/json</font> - 包含请求体
<font style="color:rgb(251, 71, 135);">{"check": true}</font> - 要求返回 200 OK
- 连续 2 次成功标记健康,连续 3 次失败标记不健康
1.4.1.3 主动健康状态检测:gRPC
https://www.envoyproxy.io/docs/envoy/v1.35.0/api-v3/config/core/v3/health_check.proto#envoy-v3-api-msg-config-core-v3-healthcheck-grpchealthcheck
使用 gRPC 标准健康检查协议,适合 gRPC 服务。
grpc_health_check:service_name: svc.prod # 服务名(空字符串表示通用检查)authority: health.envoy # 覆盖 authority 头initial_metadata: []
例如:
health_checks:
- timeout: 3sinterval: 10sgrpc_health_check:service_name: "com.example.Service"# 设置自定义元数据initial_metadata:- key: "x-health-token"value: "envoy-check"- 发送 gRPC 请求到
<font style="color:rgb(251, 71, 135);">/grpc.health.v1.Health/Check</font> - 包含头
<font style="color:rgb(251, 71, 135);">x-health-token: envoy-check</font> - 请求体:
<font style="color:rgb(251, 71, 135);">{"service": "com.example.Service"}</font> - 期望响应:
<font style="color:rgb(251, 71, 135);">{"status": "SERVING"}</font> - 其他状态视为失败
1.4.1.4 自定义健康检查
https://www.envoyproxy.io/docs/envoy/v1.35.0/api-v3/config/core/v3/health_check.proto#envoy-v3-api-msg-config-core-v3-healthcheck-grpchealthcheck
通过扩展过滤器实现自定义逻辑(需编码实现)。
{"name": ...,"typed_config": {...}
}
示例:
1、实现接口
class CustomHealthChecker : public HealthChecker {void onInterval() override {// 自定义检测逻辑if (customCheckPassed()) {handleSuccess(); // 标记健康} else {handleFailure(); // 标记不健康}
}
};2、配置实例
health_checks:
- timeout: 5sinterval: 15scustom_health_check:name: custom_checkertyped_config:"@type": type.googleapis.com/myapp.CustomCheckerConfigcheck_port: 8888secret_token: "xyz"1.4.2 Upstreams 异常检测
https://www.envoyproxy.io/docs/envoy/v1.35.0/api-v3/config/cluster/v3/outlier_detection.proto#envoy-v3-api-msg-config-cluster-v3-outlierdetection
Envoy的被动健康检查(Passive Health Checking),也称为异常检测(Outlier Detection),是一种基于实际流量表现实时隔离异常节点的机制。与主动检查不同,它不发送探测请求,而是通过分析真实请求的响应状态、延迟等指标来识别故障节点。
- 快速响应突发故障:毫秒级检测请求失败
- 补充主动检查的不足:解决主动检查间隔期的故障盲区
- 减少无效流量:及时隔离问题节点
- 自动恢复:隔离期满后自动重试
outlier_detection:consecutive_5xx: ... # 连续5xx错误阈值,默认5interval: ... # 分析扫描间隔,默认10s/10000msbase_ejection_time: ... # 主机弹出的基准时长,默认30s/30000msmax_ejection_percent: ... # 允许被弹出的主机百分比,默认10enforcing_consecutive_5xx: ... # 5xx异常弹出激活百分比,默认100enforcing_success_rate: ... # 成功率异常弹出激活百分比,默认100success_rate_minimum_hosts: ... # 成功率弹出最少主机数,默认5success_rate_request_volume: ... # 成功率统计所需请求数,默认100success_rate_stdev_factor: ... # 异常因子(需*1000),如1.3写1300consecutive_gateway_failure: ... # 网关失败弹出阈值,默认5enforcing_consecutive_gateway_failure: ... # 网关失败弹出激活百分比,默认0split_external_local_origin_errors: ... # 区分本地/外部故障,默认falseconsecutive_local_origin_failure: ... # 本地原因连续失败阈值,默认5enforcing_consecutive_local_origin_failure: ... # 本地失败弹出激活百分比,默认100enforcing_local_origin_success_rate: ... # 本地成功率弹出激活百分比,默认100failure_percentage_threshold: ... # 故障百分比阈值(如85),默认85enforcing_failure_percentage: ... # 故障百分比异常弹出激活百分比,默认0enforcing_failure_percentage_local_origin: ... # 本地故障百分比异常弹出激活百分比,默认0failure_percentage_minimum_hosts: ... # 故障百分比弹出最少主机数,默认5failure_percentage_request_volume: ... # 故障百分比弹出统计所需请求数,默认50max_ejection_time: ... # 主机弹出的最长时长(如300s),默认300s/300000ms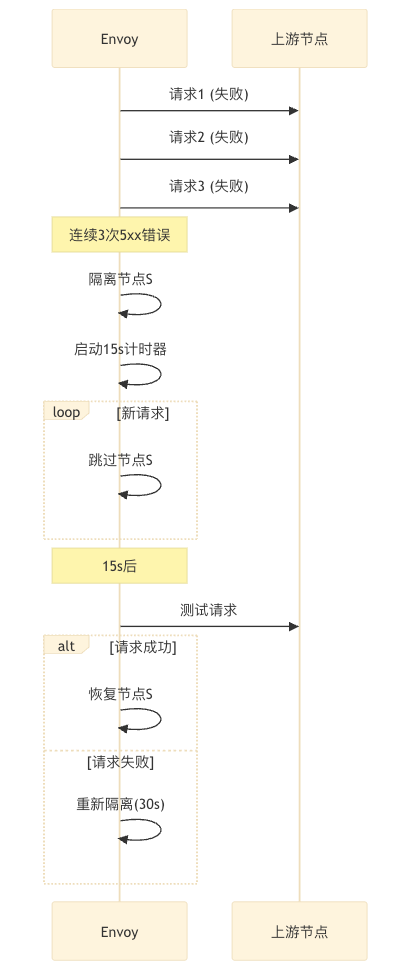
1.5 负载均衡策略
https://www.envoyproxy.io/docs/envoy/v1.35.0/api-v3/config/cluster/v3/cluster.proto#envoy-v3-api-enum-config-cluster-v3-cluster-lbpolicy
Envoy 提供了多种负载均衡策略,每种策略适用于不同的场景,并支持组合使用。以下是所有负载均衡策略的详细说明:
| 策略类型 | 算法描述 | 适用场景 | 关键参数 |
|---|---|---|---|
| Weighted Round Robin | 带权重的轮询 | 异构集群 | <font style="color:#DF2A3F;">weight</font> |
| Least Request | 选择最少请求的节点 | CPU密集型服务 | <font style="color:#DF2A3F;">choice_count</font> |
| Ring Hash | 一致性哈希 | 会话保持 | <font style="color:#DF2A3F;">hash_key</font> |
| Maglev | 更快的哈希算法 | 大型集群 | <font style="color:#DF2A3F;">table_size</font> |
| Random | 完全随机 | 简单场景 | - |
| Original Destination | 按原始目标IP路由 | 透明代理 | - |
| Subset | 子集负载均衡 | 元数据路由 | <font style="color:#DF2A3F;">metadata</font> |
clusters:- name: ... # 集群名称...load_assignment:cluster_name: ... # 必须,与cluster的name一致endpoints: # LocalityLbEndpoints列表- locality: # 位置定义region: ... # 区域zone: ... # 可选sub_zone: ... # 可选lb_endpoints: # 端点列表- endpoint:address:socket_address:address: ... # IP或DNSport_value: ... # 端口health_check_config: # 端点健康检查相关port_value: ... # 可选,仅端口健康检查场景load_balancing_weight: ... # 可选, 当前端点权重metadata: {} # 可选, 端点元数据health_status: ... # 健康状态(UNKNOWN, HEALTHY, UNHEALTHY, DRAINING, TIMEOUT, DEGRADED)load_balancing_weight: ... # 当前locality权重priority: ... # 优先级(一般0,数字越低优先级越高)policy: # 当前Locality的负载均衡策略drop_overloads: # 过载丢弃控制- category: ... # 分类名drop_percentage: numerator: ... # 百分比分子denominator: ... # 百分比分母overprovisioning_factor: ... # 超配因子(默认140)# 更多locality可继续添加# Endpoint全局策略与配置endpoint_stale_after: ... # 端点过期时长,0表示永远不过期lb_subset_config: {} # 子集负载均衡配置,可选ring_hash_lb_config: {} # ring_hash负载均衡配置,可选original_dst_lb_config: {} # original_dst负载均衡配置,可选least_request_lb_config: {} # least_request负载均衡,可选common_lb_config: # LB相关的全局参数healthy_panic_threshold: ... # Panic阈值,默认50%zone_aware_lb_config: {} # 区域感知LB配置locality_weighted_lb_config: {} # Locality权重LB配置ignore_new_hosts_until_first_hc: ... # 新主机首次健康检查前是否不参与LB1.5.1 Weighted Round Robin(加权轮询)
根据节点权重分配流量比例。
lb_policy: ROUND_ROBIN
load_assignment:endpoints:- lb_endpoints:- endpoint:address: 10.0.0.1:8080load_balancing_weight: 80 # 权重80- endpoint:address: 10.0.0.2:8080load_balancing_weight: 20 # 权重20流量比例:节点1获得80%流量,节点2获得20%
1.5.2 Least Request(最少请求)
选择当前活跃请求数最少的节点。
lb_policy: LEAST_REQUEST
lb_config:least_request_lb_config:choice_count: 2 # 随机选择2个节点,从中选取最优<font style="color:#DF2A3F;">choice_count</font>:提高该值可减少热点(默认2)
适用场景:处理时间差异大的服务(如CPU密集型)
1.5.3 RingHash(环哈希)
一致性哈希算法,相同哈希键的请求路由到相同节点。
lb_policy: RING_HASH
lb_config:ring_hash_lb_config:minimum_ring_size: 1024 # 哈希环的最小值,环越大调度结果越接近权重酷比,默认为1024,最在值为8M;maximum_ring_size: 8192 # 哈希环的最大值,默认为8M;不过,值越大越消耗计算资源;hash_function: XX_HASH # # 哈希算法, 支持XX_HASH或 MURMUR_HASH_2两种
---
routes:
- match: path: "/user"route:cluster: user-servicehash_policy: # 定义哈希键- header: header_name: "x-user-id"哈希键来源:HTTP头、Cookie、源IP等
最小环大小:建议至少为节点数的10倍
1.5.4 sMaglev
Google提出的更快的哈希算法,适合超大规模集群。
lb_policy: MAGLEV
lb_config:maglev_lb_config:table_size: 65537 # 质数(默认65537)
优势:比Ring Hash快30%,内存占用更低
限制:节点变化时哈希表需全量重建
1.5.5 Random(随机)
完全随机选择节点
lb_policy: RANDOM1.5.6 Original Destination(原始目标)
使用下游连接的原始目标IP进行路由。
lb_policy: ORIGINAL_DST_LB
lb_config:original_dst_lb_config:use_http_header: true # 从X-Envoy-Original-Dst头获取用途:透明代理、TCP转发
1.5.7 节点优先级及优先级调度
Envoy 的节点优先级(Priority)和优先级调度是一种高级负载均衡机制,允许将上游节点划分为多个优先级组,实现故障转移和流量分层管理。以下是详细说明:
- 优先级组(Priority Levels)
节点被分组为不同优先级(数字越小优先级越高):<font style="color:rgb(251, 71, 135);">Priority 0</font>:最高优先级(主节点组)<font style="color:rgb(251, 71, 135);">Priority 1</font>:次优先级(备用节点组)<font style="color:rgb(251, 71, 135);">Priority N</font>:更低优先级(灾难恢复节点组)
- 调度原则
- 优先将流量发送到最高优先级的健康节点组
- 当高优先级组不健康时,流量自动降级到下一优先级组
- 高优先级组恢复后,流量自动切回
- 健康节点定义
通过主动健康检查(<font style="color:rgb(251, 71, 135);">health_checks</font>)或被动异常检测(<font style="color:rgb(251, 71, 135);">outlier_detection</font>)确定节点健康状态
EDS配置中,属于某个特定位置的一组端点称为<font style="color:#DF2A3F;">LocalityLbEndpoints</font>,它们具有相同的位置(<font style="color:#DF2A3F;">locality</font>)、权重(<font style="color:#DF2A3F;">load_balancing_weight</font>)和优先级(<font style="color:#DF2A3F;">priority</font>);
<font style="color:#DF2A3F;">locality</font>:从大到小可由<font style="color:rgb(0,0,0);">region</font>(地域)、<font style="color:rgb(0,0,0);">zone</font>(区域)和<font style="color:rgb(0,0,0);">sub_zone</font>(子区域)进行逐级标识;<font style="color:#DF2A3F;">load_balancing_weight</font>:可选参数,用于为每个<font style="color:#DF2A3F;">priority/region/zone/sub_zone</font>配置权重,取值范围[1,n);通常,一个<font style="color:#DF2A3F;">locality</font>权重除以具有相同优先级的所有locality的权重之和即为当前locality的流量比例;- 此配置仅启用了位置加权负载均衡机制时才会生效;
<font style="color:#DF2A3F;">priority</font>:此LocalityLbEndpoints组的优先级,默认为最高优先级0;
通常,Envoy调度时仅挑选最高优先级的一组端点,且仅此优先级的所有端点均不可用时才进行故障转移
至下一个优先级的相关端点;
注意,也可在同一位置配置多个<font style="color:#DF2A3F;">LbEndpoints</font>,但这通常仅在不同组需要具有不同的负载均衡权重或不同 的优先级时才需要;
基础配置:
load_assignment:cluster_name: webclusterendpoints:- priority: 0 # 最高优先级组lb_endpoints:- endpoint:address: 10.0.0.1:8080- endpoint:address: 10.0.0.2:8080- priority: 1 # 次优先级组lb_endpoints:- endpoint:address: 10.0.0.3:8080- endpoint:address: 10.0.0.4:8080优先级组权重
endpoints:
- priority: 0lb_endpoints: [...]load_balancing_weight: 9 # 权重9
- priority: 1lb_endpoints: [...]load_balancing_weight: 1 # 权重1当两个优先级组都健康时,P0 获得90%流量,P1 获得10%
1.6 熔断
1.6.1 熔断介绍
多级服务调度用场景中,某上游服务因网络故障或服务繁忙无法响应请求时很可能会导致多级上游调用者大规模级联故障,进而导致整个系统不可用,此即为服务的雪崩效应;
服务雪崩效应是一种因“服务提供者”的不可用导致“服务消费者”的不可用,并将不可用逐渐放大的过程;
服务网格之上的微服务应用中,多级调用的长调用链并不鲜见;
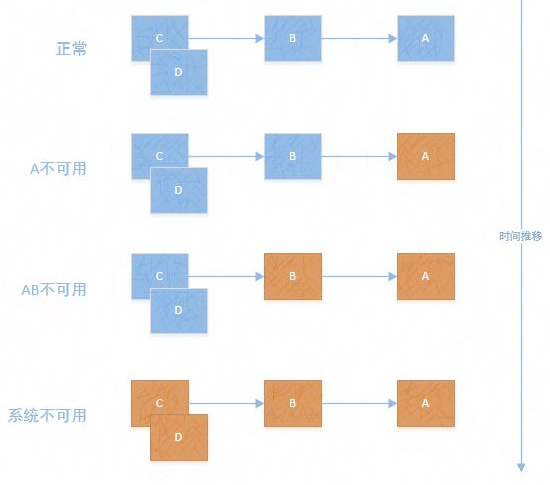
熔断:上游服务(被调用者,即服务提供者)因压力过大而变得响应过慢甚至失败时,下游服务(服务消费者)通过暂时切断对上游的请求调用达到牺牲局部,保全上游甚至是整体之目的;
- 熔断打开(Open):在固定时间窗口内,检测到的失败指标达到指定的阈值时启动熔断;
- ✓所有请求会直接失败而不再发往后端端点;
- 熔断半打开(Half Open):断路器在工作一段时间后自动切换至半打开状态,并根据下一次请求的返回结果判定状态切换
- ✓****请求成功:转为熔断关闭状态;
- ✓ ****请求失败:切回熔断打开状态;
- 熔断关闭(Closed):一定时长后上游服务可能会变得再次可用,此时下游即可关闭熔断,并再次请求其服务;
- 总结起来, 熔断是分布式应用常用的一种流量管理模式,它能够让应用程序免受上游服务失败、延迟峰值或其它网络异常的侵害;
- Envoy在网络级别强制进行断路限制,于是不必独立配置和编码每个应用;
1.6.2 断路器
断路器是一种自动故障保护机制,当上游服务出现异常时,临时切断流量避免级联故障。其状态机如下:
| 类型 | 作用 | 配置参数 | 触发条件 |
|---|---|---|---|
| 连接数限制 | 限制最大TCP连接数 | <font style="color:rgb(251, 71, 135);">max_connections</font> | 连接数 > 阈值 |
| 待处理请求限制 | 限制等待队列大小 | <font style="color:rgb(251, 71, 135);">max_pending_requests</font> | 待处理请求 > 阈值 |
| 并发请求限制 | 限制活跃请求数 | <font style="color:rgb(251, 71, 135);">max_requests</font> | 活跃请求 > 阈值 |
| 重试限制 | 限制重试次数 | <font style="color:rgb(251, 71, 135);">max_retries</font> | 重试次数 > 阈值 |
| 异常检测熔断 | 基于错误率熔断 | <font style="color:rgb(251, 71, 135);">outlier_detection</font> | 错误率 > 阈值 |
每个断路器都可在每个集群及每个优先级的基础上进行配置和跟踪,它们可分别拥有各自不同的设定;
注意:在Istio中,熔断的功能通过连接池(连接池管理)和故障实例隔离(异常点检测)进行定义,而Envoy的断路器通常仅对应于Istio中的连接池功能;
通过限制某个客户端对目标服务的连接数、访问请求、队列长度和重试次数等,避免对一个服务的过量访问 某个服务实例频繁超时或者出错时交其昨时逐出,以避免影响整个服务。
circuit_breakers:thresholds:- priority: DEFAULT # 默认优先级max_connections: 100 # 最大连接数max_pending_requests: 200 # 最大待处理请求max_requests: 50 # 最大并发请求max_retries: 3 # 最大重试次数track_remaining: true # 实时统计剩余配额- priority: HIGH # 高优先级流量max_connections: 200max_requests: 1001.6.3 连接池
连接池的常用指标
- 最大连接数:表示在任何给定时间内, Envoy 与上游集群建立的最大连接数,适用于 HTTP/1.1;
- 每连接最大请求数:表示在任何给定时间内,上游集群中所有主机可以处理的最大请求数;若设为 1 则会禁止 keepalive 特性;
- 最大请求重试次数:在指定时间内对目标主机最大重试次数
- 连接超时时间:TCP 连接超时时间,最小值必须大于 1ms;最大连接数和连接超时时间是对 TCP 和 HTTP 都有效的通用连接设置;
- 最大等待请求数:待处理请求队列的长度,若该断路器溢出,集群的 upstream_rq_pending_overflow计数器就会递增
| 配置项 | 作用 | 协议支持 | 推荐值 |
|---|---|---|---|
<font style="color:rgb(251, 71, 135);">max_connections</font> | 最大连接数 | TCP/HTTP | 根据节点容量 |
<font style="color:rgb(251, 71, 135);">idle_timeout</font> | 空闲连接超时 | HTTP | 300-600s |
<font style="color:rgb(251, 71, 135);">max_requests_per_connection</font> | 单连接最大请求数 | HTTP/1.1 | 1000-10000 |
<font style="color:rgb(251, 71, 135);">max_concurrent_streams</font> | 最大并发流 | HTTP/2 | 100-200 |
<font style="color:rgb(251, 71, 135);">tcp_keepalive</font> | TCP保活设置 | TCP | 开启 |
tcp 连接池:
upstream_connection_options:tcp_keepalive:keepalive_time: 300 # 空闲连接存活时间(s)keepalive_interval: 30keepalive_probes: 3per_connection_buffer_limit_bytes: 32768 # 单连接缓冲区限制
http 连接池:
clusters:
- name: http_servicecommon_http_protocol_options:idle_timeout: 300s # 空闲连接超时max_requests_per_connection: 1000 # HTTP/1.1单连接请求上限http2_protocol_options: max_concurrent_streams: 100 # HTTP/2并发流上限
1.6.4 熔断器
熔断器是断路器的具体实现,通过<font style="color:rgb(251, 71, 135);">outlier_detection</font>实现被动熔断:
- 基于真实请求的失败率隔离节点
- 与断路器协同工作,提供双层保护
熔断器的常用指标(Istio上下文)
- 连续错误响应个数:在一个检查周期内,连续出现5xx错误的个数,例502、503状态码
- 检查周期:将会对检查周期内的响应码进行筛选
- 隔离实例比例:上游实例中,允许被隔离的最大比例;采用向上取整机制,假设有10个实例,13%则最多会隔离2个实例
- 最短隔离时间:实例第一次被隔离的时间,之后每次隔离时间为隔离次数与最短隔离时间的乘积
outlier_detection:interval: 5s # 检测窗口(5-10s)base_ejection_time: 30s # 初始隔离时间max_ejection_time: 300s # 最大隔离时间(指数退避)max_ejection_percent: 20 # 最大隔离比例(防过载)# 触发条件(三选一)consecutive_5xx: 5 # 连续5xx错误# 或success_rate_request_volume: 100 # 最小请求量success_rate_stdev_factor: 1900 # 标准差因子(1900=1.9)# 或failure_percentage_threshold: 85 # 失败率百分比Envoy 的功能真的是太多了,更多的功能可以去官网查看,用到某些功能查询即可。