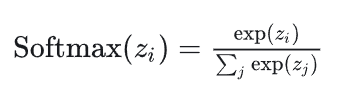第十九周-训练embedding
目录
摘要
一、Word2Vec 是什么?
二、Word2Vec 的两种训练模型
1. CBOW (Continuous Bag-of-Words) 连续词袋模型
2. Skip-gram (跳字模型)
三、Word2Vec 是如何训练得到 Embedding 的?
第1步:准备数据与定义问题
第2步:设计模型架构(一个浅层神经网络)
第3步:训练与学习
第4步:获取最终的 Embedding
四、训练中的关键技术优化
五、GloVe 是什么?
六、GloVe 的灵感与动机
七、GloVe 是如何训练得到 Embedding 的?
第1步:构建全局共现矩阵 X
第2步:定义模型目标
第3步:设计损失函数
第4步:模型训练与获取 Embedding
八、GloVe 与 Word2Vec 的对比总结
附:
摘要
Word2Vec和GloVe是两种主流的词嵌入方法。Word2Vec基于分布式假设,通过CBOW(用上下文预测中心词)和Skip-gram(用中心词预测上下文)两种浅层神经网络模型,将词语映射为稠密向量。其核心是通过局部上下文窗口学习词向量,并采用负采样等技术优化训练。而GloVe则利用全局词共现统计信息,通过构建共现矩阵并优化加权回归损失,直接捕捉词语间的共现规律。两者对比:Word2Vec擅长局部语义建模,GloVe更能反映全局统计特征,在词类比和相似度任务中各具优势。
Abstract
Word2Vec and GloVe are two mainstream word embedding methods. Word2Vec is based on the distributional hypothesis and maps words to dense vectors through two shallow neural network models, CBOW (predicting the center word from the context) and Skip-gram (predicting the context from the center word). Its core is learning word vectors through a local context window, with techniques such as negative sampling used to optimize training. GloVe, on the other hand, leverages global word co-occurrence statistics by constructing a co-occurrence matrix and optimizing a weighted regression loss, directly capturing the co-occurrence patterns between words. In comparison: Word2Vec excels at local semantic modeling, while GloVe better reflects global statistical features, with each having advantages in word analogy and similarity tasks.
一、Word2Vec 是什么?
核心思想:Word2Vec 不是一个复杂的算法,而是一个思想——“一个词的含义可以由它周围的词来定义”(分布式假设)。简单来说,就是通过观察一个词在大量文本中与哪些词为邻,来学习这个词的表示。
最终目标:将语言中的每一个词,映射成一个固定长度的、稠密的向量(通常为50-300维)。这些向量被称为 “词嵌入”。
关键特性:在理想情况下,这些向量空间中的几何关系可以捕捉到词之间的语义和语法关系。
-
语义关系:
vector(“国王”) - vector(“男人”) + vector(“女人”) ≈ vector(“女王”) -
语法关系:
vector(“走”) - vector(“慢走”) + vector(“快跑”) ≈ vector(“跑”) -
相似度:语义或用法相近的词,它们的向量在空间中的距离(如余弦相似度)会很近。例如,“咖啡”和“茶”的向量会很接近,但和“足球”的向量相距甚远。
二、Word2Vec 的两种训练模型
Word2Vec 主要通过两种不同的模型架构来实现这个思想:
1. CBOW (Continuous Bag-of-Words) 连续词袋模型
-
目标:根据上下文预测中心词。
-
工作原理:给定一个中心词(例如“狐狸”)周围一定窗口大小(例如前后各2个词)的上下文词(“那只”, “敏捷的”, “跳过了”, “懒狗”),模型的任务是预测出这个中心词本身。
-
特点:
-
训练速度快。
-
对高频词的效果更好。
-
在数据量较小的情况下表现不错。
-
2. Skip-gram (跳字模型)
-
目标:根据中心词预测上下文。
-
工作原理:与CBOW相反。给定一个中心词(例如“狐狸”),模型的任务是预测它周围窗口内的上下文词(“那只”, “敏捷的”, “跳过了”, “懒狗”)。
-
特点:
-
训练速度比CBOW慢。
-
在处理低频词和稀有词时表现更好。
-
通常在大数据集上能产生更精确的向量。
-
简单比喻:
-
CBOW:完形填空。给你一句话“那只 __ 的狐狸跳过了懒狗”,让你填“敏捷的”。
-
Skip-gram:猜朋友。给你一个人“马云”,让你猜他可能会和哪些人(“蔡崇信”、“张勇”、“创业者”)一起出现。
三、Word2Vec 是如何训练得到 Embedding 的?
虽然细节涉及神经网络,但其核心过程可以概括为以下几个关键步骤。我们以更流行的 Skip-gram 模型为例进行说明。
第1步:准备数据与定义问题
-
构建词汇表:从海量文本语料中提取出所有唯一的单词,构成一个词汇表
V,大小为V。 -
One-Hot 编码:每个词最初都被表示成一个长度为
V的向量,其中只有对应词索引的位置是1,其他全是0。例如,“狐狸”可能是[0,0,1,0,...,0],“狗”可能是[0,1,0,0,...,0]。 -
定义滑动窗口:设定一个窗口大小(如5),在文本上滑动。对于每个中心词,其窗口内的词都是它的“上下文词”。
此时,我们的任务是:输入是一个词的 One-Hot 向量,输出是它周围每个上下文词是词汇表中某个词的概率。
第2步:设计模型架构(一个浅层神经网络)
Word2Vec 使用了一个非常简单的三层神经网络(没有深度隐藏层):
-
输入层:接收一个中心词的 One-Hot 向量,尺寸为
[1 x V]。 -
隐藏层(投影层):一个尺寸为
[V x N]的权重矩阵W,通常被称为 “Look-up Table”。这里的N就是我们想要的词向量维度(如300维)。-
关键操作:当输入一个词的 One-Hot 向量与权重矩阵
W相乘时,实际上就是直接选取了W矩阵中对应行的向量。 -
这就是 Embedding 的诞生! 这个
[1 x N]的向量就是该中心词的中间表示,也就是我们最终要得到的词向量的雏形。
-
-
输出层:一个尺寸为
[N x V]的权重矩阵W’。它将隐藏层的N维向量映射回一个[1 x V]的向量。-
这个
[1 x V]的向量经过 Softmax 函数处理后,就变成了一个概率分布,表示词汇表中每一个词作为当前中心词的上下文词的概率。
-
第3步:训练与学习
-
前向传播:
-
输入中心词“狐狸”的 One-Hot 向量
x。 -
h = x * W→ 得到“狐狸”的N维词向量h。 -
u = h * W‘→ 得到一个V维的分数向量。 -
y_hat = softmax(u)→ 将分数转换为概率分布。
-
-
计算损失:
-
我们希望
y_hat的概率分布能够与真实的上下文词的分布一致。真实标签是多个上下文词的 One-Hot 向量(例如,“那只”、“敏捷的”等)。 -
使用负对数似然损失 来衡量预测概率与真实分布的差距。
-
-
反向传播与优化:
-
通过反向传播算法,计算损失函数对两个权重矩阵
W和W‘的梯度。 -
使用梯度下降法(如SGD)来更新
W和W’中的每一个权重值。
-
第4步:获取最终的 Embedding
-
训练完成后,我们关心的不是模型的预测能力,而是那个权重矩阵
W。 -
矩阵
W的每一行,就对应着词汇表中一个词的N维词向量! -
例如,“狐狸”这个词在词汇表中的索引是2,那么
W矩阵的第2行(一个300维的向量)就是“狐狸”的词嵌入。
四、训练中的关键技术优化
原始的 Softmax 计算成本极高(因为词汇表 V 通常很大,几万到百万),所以 Word2Vec 的作者引入了两种优化技术:
-
层次 Softmax:将词汇表中的所有词组织成一棵霍夫曼树。计算概率时,不再需要计算所有
V个词,只需要沿着树路径计算log(V)次,大大降低了计算复杂度。 -
负采样:这是更常用和有效的方法。它不再要求模型去预测所有上下文词,而是改为一个更简单的二分类任务:
-
正样本:真实的上下文词(如“敏捷的”),标签为1。
-
负样本:从词汇表中随机抽取
k个(如5个)非上下文词的词(如“飞机”、“音乐”),标签为0。 -
模型只需要判断一个词对(中心词,候选词)是“好邻居”还是“坏邻居”。这极大地简化了学习目标,提高了训练速度和词向量的质量。
-
五、GloVe 是什么?
GloVe的全称是 Global Vectors for Word Representation(用于词表示的全局向量)。
-
核心思想:Word2Vec基于局部上下文窗口(local context)进行学习,而GloVe的独特之处在于,它首先统计整个语料库的全局共现信息,然后基于此来学习词向量。
-
目标:直接捕获词汇在全局语料中共同出现的统计规律,并将这些规律直接编码到词向量中。
一个直观的比喻:
想象我们要了解一群人的关系:
-
Word2Vec(Skip-gram) 的方法像是:一次次地随机观察一个小团体(窗口)里的互动(A和B说话了,A和C也说话了),通过无数次这样的微观观察来慢慢揣测每个人的关系。
-
GloVe 的方法像是:直接拿到一份全局的统计报告,报告上写着“A和B在整个会议期间一共交谈了50次,A和C交谈了20次,B和C只交谈了2次...”。它直接利用这些宏观统计数据来推算关系的亲疏。
六、GloVe 的灵感与动机
GloVe的作者发现,词语之间的某种“关系”可以通过它们共现概率的比率来更好地体现。他们举了一个著名的例子:
假设我们有三个词:ice(冰),steam(蒸汽),和另一个随机词 solid(固体),gas(气体),water(水),fashion(时尚)。
-
我们统计
ice分别和solid,gas,water,fashion共同出现在一个窗口中的次数。 -
同样统计
steam分别和这些词共现的次数。 -
计算共现概率:
-
P(solid | ice) =
ice和solid共现的次数 /ice的总共现次数(很高) -
P(solid | steam) = ...(很低)
-
P(gas | ice) = ...(很低)
-
P(gas | steam) = ...(很高)
-
-
关键观察:如果我们计算这些概率的比率,会得到非常有意义的结果:
-
P(solid | ice) / P(solid | steam) >> 1 (冰与固体的关联远大于蒸汽与固体)
-
P(gas | ice) / P(gas | steam) << 1 (冰与气体的关联远小于蒸汽与气体)
-
P(water | ice) / P(water | steam) ≈ 1 (冰和蒸汽都与水高度相关)
-
P(fashion | ice) / P(fashion | steam) ≈ 1 (冰和蒸汽都与时尚无关)
-
这个比率能够清晰地区分相关词(solid, gas)、泛化词(water)和无关词(fashion)。GloVe的目标就是让学习到的词向量能够再现这种共现概率的比率关系。
七、GloVe 是如何训练得到 Embedding 的?
GloVe的训练过程比Word2Vec更“直接”,它没有使用神经网络,而是通过构建一个加权最小二乘回归模型来求解。
第1步:构建全局共现矩阵 X
-
遍历整个语料库。
-
定义一个滑动窗口(例如,中心词前后各5个词)。
-
统计任意两个词
i(中心词)和j(上下文词)在某个窗口内共同出现的次数。这个次数就是X_ij。 -
最终,我们得到一个庞大的
|V| x |V|的矩阵X,其中|V|是词汇表的大小。-
例如,
X_ice, solid = 100表示 “ice” 和 “solid” 在整个语料中共同出现了100次。
-
第2步:定义模型目标
GloVe希望,对于任意两个词 i 和 j,它们的词向量(w_i 和 w_j)以及偏置项(b_i 和 b_j)能够通过点积运算,近似于它们共现次数的对数值。
核心公式:
w_i · w_j + b_i + b_j ≈ log(X_ij)
-
为什么是
log(X_ij)?-
共现次数
X_ij是非常大的正整数,取对数后可以将其压缩到一个更平滑的范围内,便于模型优化。 -
点积运算是一个标量,与对数后的标量在数值上更匹配。
-
这个公式直接体现了GloVe的全局思想:词向量的内积应该捕捉共现频率的对数。
第3步:设计损失函数
我们不能简单地使用 (w_i · w_j + b_i + b_j - log(X_ij))^2 作为损失,因为需要处理一些特殊情况:
-
罕见共现:如果两个词从未共现(
X_ij = 0),那么log(X_ij)是负无穷大,无法计算。 -
权重问题:高频共现(如“的”和“是”)和低频共现(如“量子”和“力学”)的重要性是不同的。高频词对提供的信息更可靠。
因此,GloVe设计了一个加权均方误差损失函数:
J = Σ f(X_ij) * (w_i · w_j + b_i + b_j - log(X_ij))^2
这个函数有两个关键部分:
-
权重函数
f(X_ij):-
当
X_ij = 0时,f(X_ij) = 0,这样就避免了计算log(0)的问题。 -
当
X_ij增大时,f(X_ij)也增大,但不会无限增大(有一个上限),这给了高频共现更高的权重,同时又防止了极高频词对(如“的”、“是”)完全主导训练过程。 -
一个常用的
f(X_ij)函数形式是:当x < x_max(如x_max=100)时,f(x) = (x/x_max)^0.75;当x >= x_max时,f(x) = 1。
-
-
平方误差项:
(w_i · w_j + b_i + b_j - log(X_ij))^2,这是标准的回归损失。
第4步:模型训练与获取 Embedding
-
初始化:随机初始化所有词的词向量
w_i和偏置项b_i。 -
优化:使用梯度下降法来最小化上述的损失函数
J。模型会不断调整所有w和b,使得预测值w_i · w_j + b_i + b_j越来越接近目标值log(X_ij)。 -
获取结果:
-
训练完成后,我们得到的每一个词
i的向量w_i,就是它的最终词嵌入。 -
有时,GloVe也会将中心词向量和上下文词向量相加 (
w_i + w_j) 作为最终的词向量,因为实验表明这样效果更好。
-
八、GloVe 与 Word2Vec 的对比总结
| 特性 | Word2Vec (Skip-gram) | GloVe |
|---|---|---|
| 学习范式 | 局部(基于滑动窗口的预测) | 全局(基于整个语料的共现矩阵) |
| 训练数据 | 一个个局部的窗口样本流 | 一个预先计算好的全局共现矩阵 X |
| 核心思想 | 预测上下文 | 拟合共现概率的比率 / 共现频率的对数 |
| 训练效率 | 通过负采样可以非常高效 | 共现矩阵可能很大,但一旦构建好,训练也很高效 |
| 结果特点 | 在词汇类比任务上表现出色 | 同样出色,并且在某些词语相似度任务上可能更优 |
| 直观理解 | 微观洞察 | 宏观统计 |
附:
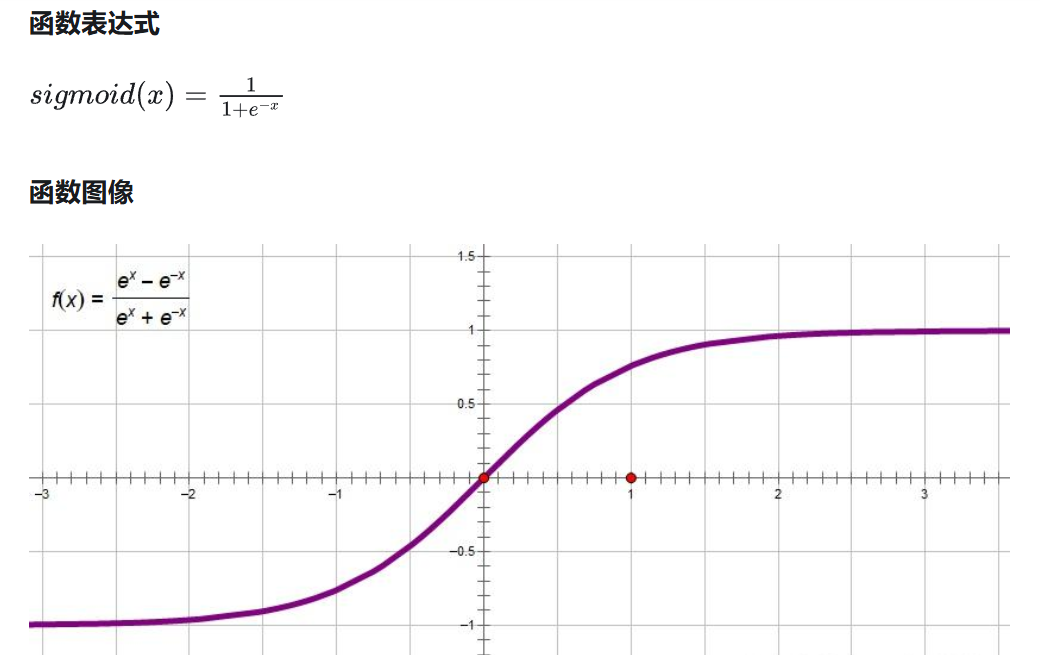
sigmoid函数容易饱和、出现梯度消失等问题。sigmoid函数只在原点附近有比较大的梯度变化,在两端梯度变化很小,经常处理2分类问题。
对于多分类问题,常用的方法是Softmax函数,它可以预测每个类别的概率且各项之和为1。
Softmax的公式如下