单表查询-模糊匹配
1、 模糊匹配
在项目中常用模糊匹配,比如说找出姓张的用户。可以用LIKE ‘张%’去实现。like条件分为三种情况是:
(1) 通配符在后面,如a like ‘L’||’%’,这种情况大部分是可以用索引去优化,打开LIKE_OPT_FLAG参数可以优化成a>=‘L’ AND a <‘M’。
(2) 通配符在前面,这种情况在匹配数据时候需要扫描全表数据后才能匹配到数据。
(3) 前后都有通配符,这种情况在匹配数据时候也是需要扫描全表数据后才能匹配到数据。
接下来通过例子来对比这三种情况的效率
2、 测例
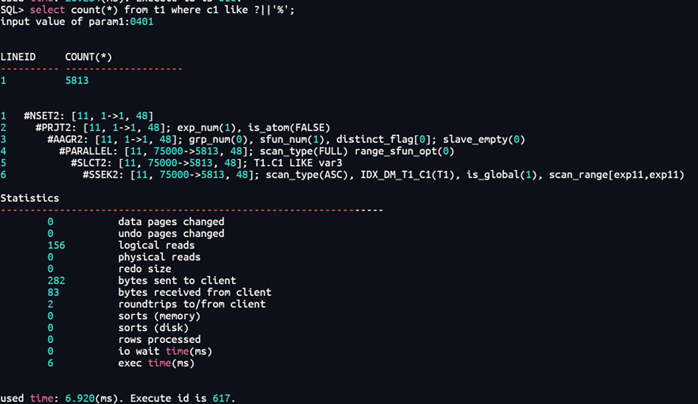
(1)通配符在后
select count(*) from t1 where c1 like ?||'%';
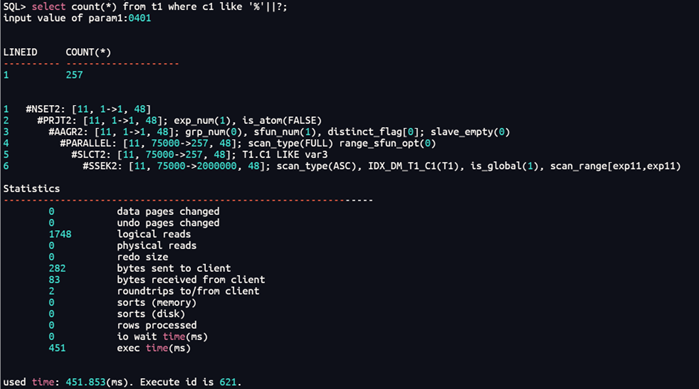
(2)通配符在前
select count(*) from t1 where c1 like '%'||?;
(3)通配符前后
select count(*) from t1 where c1 like '%'||?||'%';
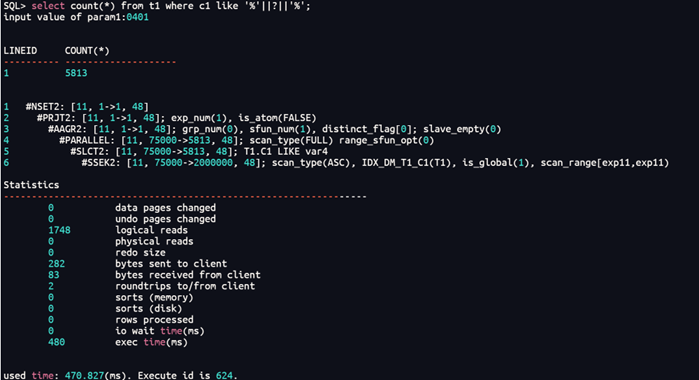
通过例子验证,数据库在做模糊匹配的时候,尽量选择通配符在后面的情况,这样like匹配的效率更高。
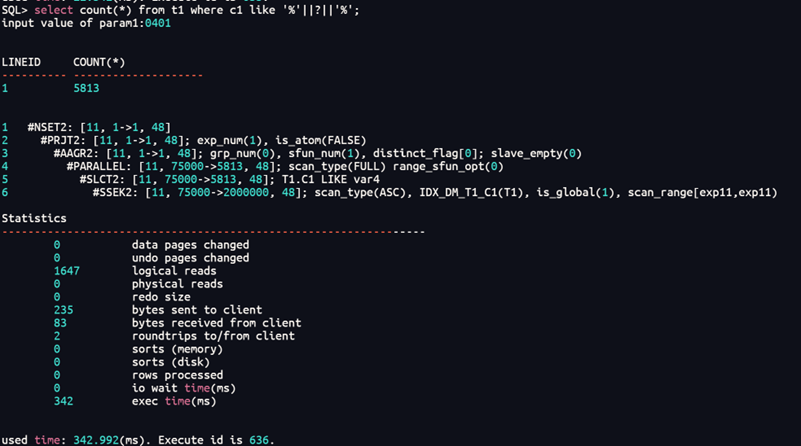
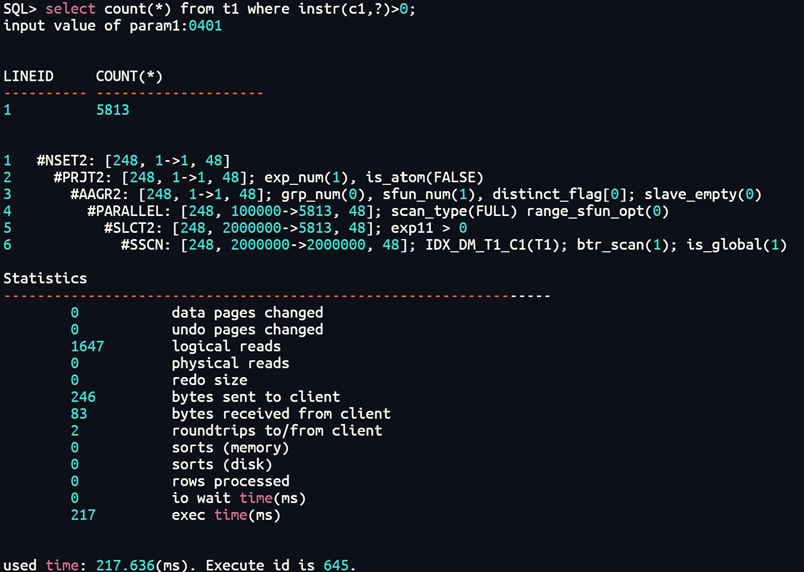
3、对比like、instr之间的效率
Like方式:select count(*) from t1 where c1 like '%'||?||'%';
Instr方式:select count(*) from t1 where instr(c1,?)>0;
4、 小结
1、使用like一般建议通配符在后。
2、like和instr相互转换和效率对比
