【AI论文】ScreenCoder:通过模块化多模态智能体推动前端自动化中的视觉到代码生成技术发展
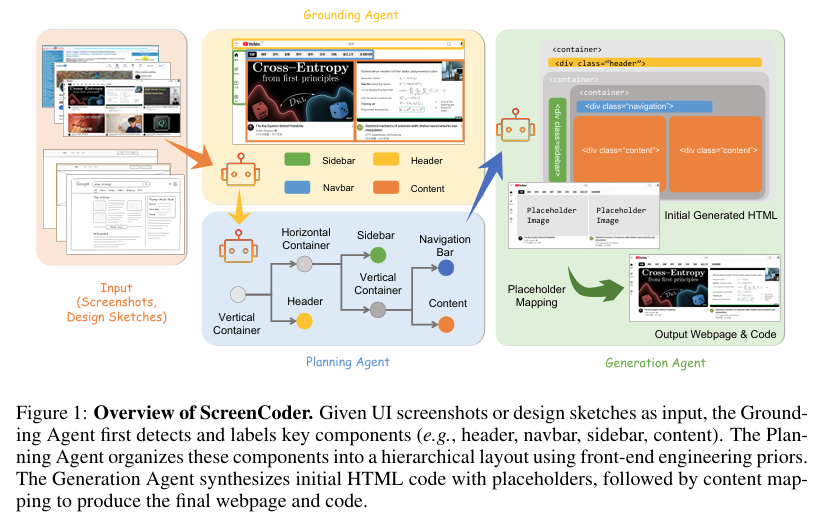
摘要:将用户界面(UI)设计自动转换为前端代码,对于加速软件开发和实现设计工作流程的普及化具有巨大潜力。尽管近期的大型语言模型(LLMs)在文本到代码的生成方面取得了进展,但许多现有方法仅依赖自然语言提示,这限制了它们在捕捉空间布局和视觉设计意图方面的有效性。相比之下,实际中的UI开发本质上具有多模态特性,通常从视觉草图或模型图开始。为解决这一差距,我们引入了一个模块化多智能体框架,该框架通过三个可解释的阶段执行UI到代码的生成:定位、规划和生成。定位智能体利用视觉语言模型检测并标记UI组件,规划智能体利用前端工程先验知识构建层次化布局,生成智能体则通过基于自适应提示的合成生成HTML/CSS代码。与端到端黑箱方法相比,这种设计提高了鲁棒性、可解释性和保真度。此外,我们将该框架扩展为一个可扩展的数据引擎,可自动生成大规模的图像-代码对。利用这些合成示例,我们对开源视觉语言模型(VLM)进行了微调和强化,显著提升了其对UI的理解能力和代码质量。大量实验表明,我们的方法在布局准确性、结构一致性和代码正确性方面达到了最先进的性能。我们的代码已在https://github.com/leigest519/ScreenCoder上公开提供。Huggingface链接:Paper page,论文链接:2507.22827
研究背景和目的
研究背景:
随着软件开发的快速发展,前端工程和用户界面(UI)设计的自动化成为提升开发效率和降低技术门槛的关键。传统的UI开发过程往往耗时且需要专业的编程知识,限制了非开发人员参与界面创建的能力。近年来,大型语言模型(LLMs)在文本到代码的生成方面取得了显著进展,例如Qwen3等系统能够根据自然语言指令生成前端代码。然而,这些方法主要依赖于文本提示,难以有效捕捉UI设计中的空间布局和视觉设计意图。
在实际的UI开发中,设计过程本质上是多模态的,通常从视觉草图或模型图开始。现有的视觉语言模型(VLMs)虽然能够直接解释UI设计图像并生成结构化代码,但在处理复杂的UI到代码转换任务时仍面临诸多挑战。这些挑战包括但不限于:理解图像中的UI组件、规划组件的层次布局以及生成符合前端工程标准的HTML/CSS代码。现有VLMs在处理这些任务时,常常出现组件遗漏、错误分类以及布局违规等问题,导致生成的代码质量不高。
研究目的:
本研究旨在解决现有VLMs在UI到代码生成任务中的局限性,提出一种模块化多智能体框架,通过分解任务为定位、规划和生成三个可解释的阶段,提高UI到代码生成的准确性、结构一致性和代码正确性。同时,本研究还希望构建一个可扩展的数据引擎,自动生成大规模的图像-代码对,用于微调和强化开源VLM,从而进一步提升其对UI的理解和代码生成能力。
研究方法
1. 模块化多智能体框架设计:
本研究提出的模块化多智能体框架由三个核心智能体组成:定位智能体、规划智能体和生成智能体。
-
定位智能体:利用视觉语言模型(VLM)检测并标记UI图像中的关键结构组件,如侧边栏、头部、导航栏和主要内容区域。通过明确的语义标签,支持交互式和基于语言的UI设计。
-
规划智能体:根据定位智能体提供的语义标签和边界框坐标,构建层次化布局树。该布局树反映了Web设计中常见的空间关系和布局模式,为代码生成提供结构化上下文。
-
生成智能体:利用自适应提示合成技术,将布局树转换为HTML/CSS代码。每个组件的生成过程都结合了布局上下文和可选的用户指令,支持交互式设计。
2. 数据引擎构建:
为了解决高质量图像-代码对数据集稀缺的问题,本研究构建了一个可扩展的数据引擎。该引擎能够自动生成大规模的UI设计图像及其对应的HTML/CSS代码,用于微调和强化开源VLM。
-
数据生成:利用提出的模块化多智能体框架,生成包含多样化UI设计和布局模式的图像-代码对。
-
微调与强化学习:应用冷启动监督微调(SFT)和基于视觉语义奖励的强化学习(RL),对开源VLM(如Qwen2.5-VL)进行训练,提升其对UI的理解和代码生成能力。
3. 实验设计:
为了验证提出的方法的有效性,本研究进行了广泛的实验,包括定量评估和定性比较。
-
定量评估:使用包含3000个高质量UI图像-代码对的基准测试集,评估不同方法在布局准确性、结构一致性和代码正确性方面的性能。评估指标包括块匹配率、文本相似度、位置对齐度和颜色一致性等。
-
定性比较:通过可视化示例,展示提出的方法在生成UI代码方面的优势,与基线方法进行对比。
研究结果
1. 定量评估结果:
实验结果表明,提出的方法在布局准确性、结构一致性和代码正确性方面均达到了最先进的性能。具体来说:
-
块匹配率:提出的方法在块匹配率上显著优于其他基线方法,表明其能够更准确地检测和标记UI图像中的组件。
-
文本相似度:生成的代码与真实代码在文本相似度方面也表现出色,说明生成的代码在语法和语义上更接近真实代码。
-
位置对齐度和颜色一致性:提出的方法在位置对齐度和颜色一致性方面同样优于基线方法,表明其能够更好地保持UI设计的视觉一致性。
2. 定性比较结果:
通过可视化示例,可以清晰地看到提出的方法在生成UI代码方面的优势。与基线方法相比,提出的方法生成的代码更准确地反映了原始UI设计的布局和结构,且生成的网页在视觉上更接近真实设计。
3. 数据引擎效果:
利用数据引擎生成的大规模图像-代码对进行微调和强化学习后,开源VLM在UI理解和代码生成能力方面得到了显著提升。这表明数据引擎在解决高质量数据集稀缺问题方面发挥了重要作用。
研究局限
尽管本研究在UI到代码生成任务中取得了显著进展,但仍存在一些局限性:
1. 组件识别准确性:
尽管定位智能体在大多数情况下能够准确检测和标记UI组件,但在处理复杂或模糊的UI设计时,仍可能出现遗漏或错误分类的情况。
2. 布局规划灵活性:
规划智能体在构建层次化布局树时,主要依赖于简单的空间启发式和组合规则。对于更复杂或非标准的布局模式,规划智能体的灵活性可能受到限制。
3. 代码生成多样性:
生成智能体在生成HTML/CSS代码时,主要依赖于自适应提示合成技术。尽管这种方法能够生成符合前端工程标准的代码,但在代码多样性方面可能仍有提升空间。
4. 数据引擎扩展性:
尽管数据引擎能够自动生成大规模的图像-代码对,但在处理更复杂或多样化的UI设计时,数据引擎的扩展性可能面临挑战。
未来研究方向
针对本研究的局限性,未来可以从以下几个方面展开进一步研究:
1. 提升组件识别准确性:
探索更先进的视觉语言模型和技术,提升定位智能体在复杂或模糊UI设计中的组件识别准确性。例如,可以结合上下文信息和领域知识,改进组件检测和标记算法。
2. 增强布局规划灵活性:
研究更灵活的布局规划方法,使规划智能体能够处理更复杂或非标准的布局模式。例如,可以引入基于机器学习的布局规划算法,自动学习并适应不同的布局模式。
3. 丰富代码生成多样性:
探索多样化的代码生成策略,提升生成智能体在生成HTML/CSS代码时的多样性。例如,可以结合生成对抗网络(GANs)或变分自编码器(VAEs)等技术,生成更多样化的代码示例。
4. 扩展数据引擎应用范围:
研究如何扩展数据引擎的应用范围,使其能够处理更复杂或多样化的UI设计。例如,可以引入更丰富的UI设计元素和布局模式,生成更多样化的图像-代码对。同时,可以探索数据引擎在其他相关领域的应用,如移动应用界面生成、游戏UI设计等。
5. 集成交互式设计反馈:
未来工作可以进一步集成交互式设计反馈机制,使设计师能够在生成过程中实时调整布局树或重新提示特定组件,而无需重新启动整个过程。这将有助于提升设计的灵活性和效率。
6. 探索跨领域应用:
尽管本研究主要关注Web UI设计,但模块化多智能体框架的设计具有一定的通用性。未来可以探索该框架在其他设计领域的应用,如移动应用界面生成、桌面应用界面设计以及游戏UI设计等。通过扩展组件标签集和领域特定的规划逻辑,可以轻松地将框架适应于不同的设计领域。
7. 持续学习与个性化辅助:
为了应对实际部署环境中的噪声或低分辨率输入截图,可以研究持续学习策略,使系统能够根据用户修正或手动编辑的代码进行增量式细化。这将有助于提升系统的鲁棒性和适应性。同时,可以探索个性化UI代码辅助工具的开发,根据用户的偏好和习惯提供定制化的代码生成服务。