抖音全新推荐大模型RankMixer
ps:今天研究了一下抖音推荐算法团队出的一篇论文RankMixer: Scaling Up Ranking Models in Industrial Recommenders,新鲜出炉2025.7.26发出的,全文看下来,里面有很浓的deepseek的味道,也是用了混合专家模型(Sparse MoE in RankMixer)。下面就大致分享一下模型中用到的主要模块我这里只做了整体性梳理,详细细节还需看原文。
论文地址如下RankMixer: Scaling Up Ranking Models in Industrial Recommenders
RankMixer模块架构图:
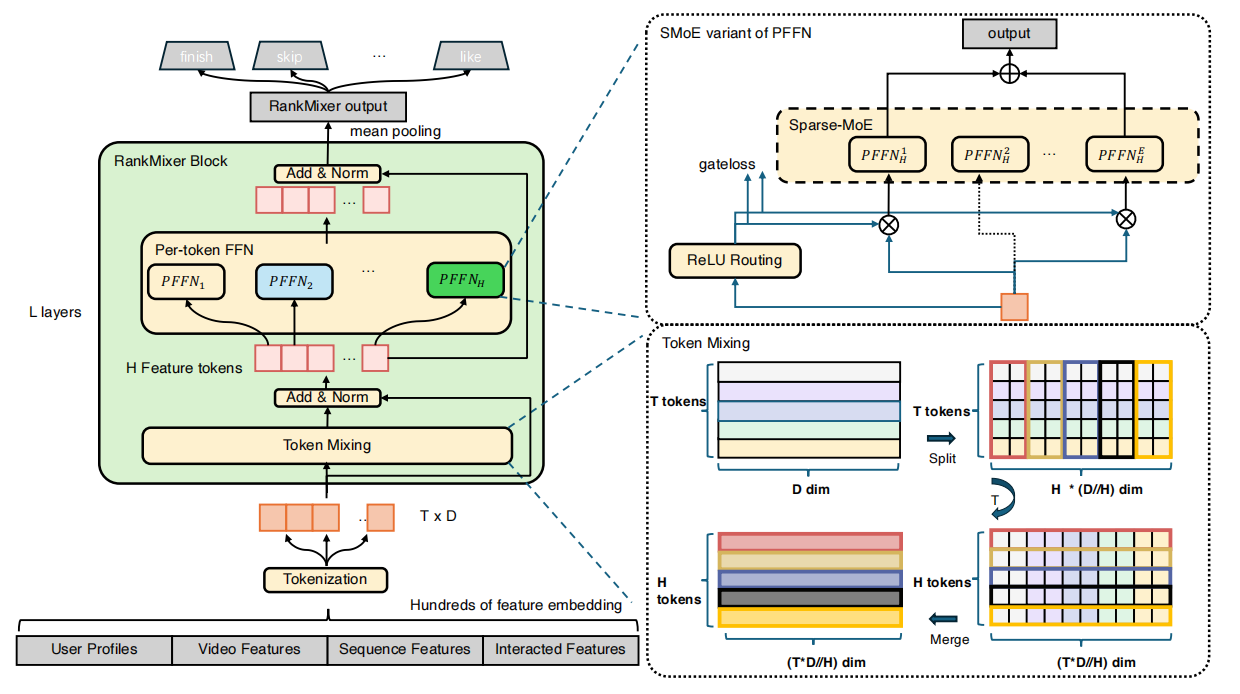
RankMixer流程详细介绍:
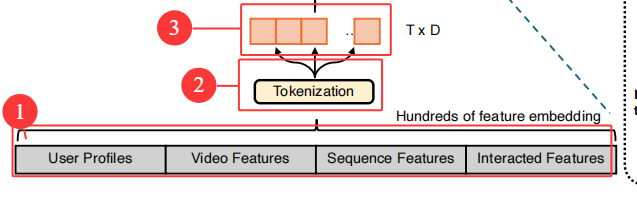
1.特征提取embedding,Tokenization序列化:
①特征提取embedding:将用户设置(用户画像),视频特征,序列特征,交互特征,等数百个特征进行embedding(词嵌入)。
②Tokenization序列化:Automatic Feature Tokenization机制,将输入Token化为维度对齐的Token序列。
③Token分组映射:基于业务先验知识按语义划分特征组,组内特征拼接后等距切分为固定维度的“Token”,每个Token代表一个语义一致的特征子空间,最后将切分后的向量统一映射到模型隐层维度。
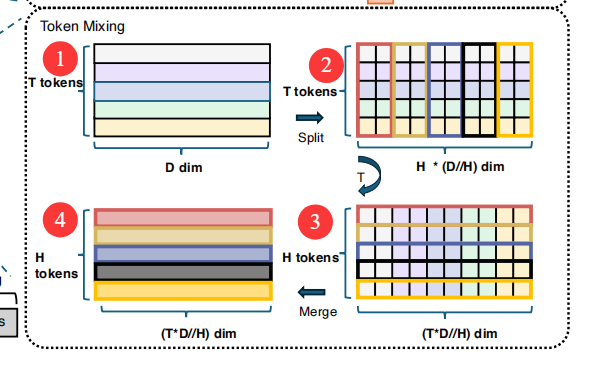
2.Token Mixing特征Token全局交叉信息的融合:
①将D维的T个tokens进行Split划分。
②将每个Token的向量分成H个小子空间。
③转置(T),拼接不同Token在对应head的向量,实现各Token之间的信息交换。
④进行Merge拼接成(T*D//H)维的H个tokens。
⑤最后通过残差和Layernorm,将TokenMixing的结果加回到切分后的原始Token上。
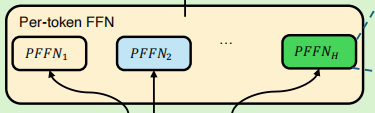
3.Per-token FFN稀疏混合专家模块:
①H个特征tokens通过ReLU Rounting路由机制激活更多专家节点神经元处理高信息量的令牌,并提升参数效率。(即混合专家模型).
tips:这里和deepseek的MoE混合专家模型异曲同工,用稀疏混合专家模块(MoE)代替原有的全连接层。减少计算量的同时提升精度。
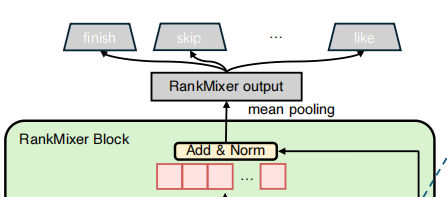
4.特征tokens整理输出:
①通过Per-token FFN模块输出的特征tokens和之前Token Mixing的tokens进行残差连接Layernorm。
②mean pooling平均池化,然后分类输出结束,喜欢,跳过,等等。