JAVAEE--5.多线程之常见的锁策略
常见的锁策略
注意:接下来讲解的锁策略不仅仅是局限于JAVA,任何和"锁"相关的话题,都可能会涉及到以下内容,这些特性主要是给锁的实现者来参考的
乐观锁 VS 悲观锁(预测锁冲突的概率是否高)
悲观锁:
总是假设最坏的情况,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿到这个数据就会阻塞直到他拿到锁
简而言之: 假设出现锁冲突的概率很大 => 接下来围绕加锁要做很多工作
乐观锁:
假设数据一般情况下不会产生并发冲突,所以在数据进行提交更新的时候,才会正式对数据是否产生并发冲突进行检测,如果发现并发冲突了,则让返回用户错误的信息,让用户决定如何去做
简而言之: 假设出现锁冲突的概率很小
Synchronized 初始使用乐观锁策略,同时会偷偷统计所冲突的次数,如果发现锁冲突的次数达到了一定程度,也就是当发现锁竞争比较频繁的时候,就会自动切换成悲观锁的策略
重量级锁 VS 轻量级锁(效果和悲观乐观是重叠的,站在的角度不一样)
重量级锁:
加锁的开销比较大,要做更多的工作 [往往,悲观锁的时候,会做的重]
轻量级锁:
加锁的开销比较小,要做更少的工作 [往往,乐观锁的时候,会做的轻]
synchronized也是自适应的
挂起等待锁 VS 自旋锁
挂起等待锁
挂起等待锁就是属于 悲观锁/重量级锁 的一种典型实现
挂起等待锁相当于"让出了CPU资源",CPU就可以用来做别的事情了,过了一段时间之后,再来拿锁,适合"悲观锁"这样的场景,锁竞争十分激烈,预测拿到锁的概率不大,不妨把CPU让出来,充分的做其他的事情
自旋锁
自旋锁就属于 乐观锁/轻量级锁 的一种典型实现
自旋锁,忙等的过程中,不会释放cpu资源,不停的检测锁是否被释放,一旦锁被释放了就立即有机会能够获取到锁了
synchronized 是自适应的
轻量级锁就是基于自旋的方式实现的
(JVM 内部,用户态代码实现的)
重量级锁 就是基于 挂起等待的方式实现的
(调用操作系统api,在内核中实现的)
公平锁 VS 非公平锁
公平锁
遵守"先来后到",B比C先来的,当A释放锁之后,B就能先于C获取到锁
非公平锁
不遵守"先到后到",B和C都有可能获取到锁
synchronized属于非公平锁,当N个线程竞争同一把锁,其中一个线程先拿到了锁,后续该线程释放锁之后,剩下的N-1个线程就是要重新竞争,谁拿到锁就都不一定了
如果需要使用公平锁,就需要做额外的操作(比如引入队列,记录每个线程加锁的顺序)
可重入锁 VS 不可重入锁
死锁问题
如果一个线程,针对一把锁连续加锁两次,就可能出现死锁
如果把锁生定位"可重入"(reentrant),就可以避免死锁了
操作:
1).记录当前是哪个线程持有了这把锁
2).在加锁的时候判定,申请当前锁的线程,是否就是锁的持有者线程
3).计数器,记录加锁的次数,从而确定合适真正的释放锁
synchronized关键字锁都是可重入的
读写锁
所谓读写锁,把"加锁操作"分成两种情况
读加锁 如果多个线程同时读这个变量,没有线程安全问题
写加锁 但是,一个线程读/一个线程写 或者两个线程都写就会产生这种问题
读写锁,提供了两种加锁的api
加读锁 如果两个线程都是按照读方法加锁,此时不会产生锁冲突
加写锁 如果两个线程都是加写锁,此时会产生锁冲突
解锁的api是一样的 如果一个线程是读锁,一个线程是写锁,也会产生锁冲突
读写锁 本身也是系统的内置的锁
读写锁就是把读操作和写操作区分对待,Java标准库提供了ReentrantReadWriteLock类,实现了读写锁
ReentrantReadWriteLock.ReadLock类表示一个读锁,这个对象提供了lock/unlock方法进行加锁解锁
ReentrantReadWriteLock.WriteLock类标识一个写锁,这个对象也提供了lock/unlock方法进行加锁解锁
(这两个放入finally中,确保能够执行到)
synchronized并非是读写锁
读写锁特别适合于"频繁读,不频繁写"的场景中
synchronized的加锁过程(锁升级)
synchronized
1)乐观悲观,自适应
2)重量轻量,自适应
3)自旋挂起等待,自适应
4)非公平锁
5)可重入锁
6)不是读写锁
当代码执行到synchronized 代码块中,jvm 大概做哪些事情
锁升级的过程
刚开始使用synchronized加锁,首先锁会处于"偏向锁"的状态
当遇到线程之间的锁竞争,升级到"轻量级锁"
进一步的统计竞争出现的频次,达到一定程度之后,升级到"重量级锁"
synchronized 加锁的时候,会经历 无锁 => 偏向锁 => 轻量级锁 => 重量级锁
偏向锁
偏向锁不是真的加锁(真的加锁,开销可能会比较大),偏向锁只是做了标记(标记的过程,非常的轻量高效)
偏向锁 => 轻量级别 :出现竞争
轻量级锁 => 重量级锁 :竞争激烈
上述锁升级的过程,主要是为了能够让synchronized这个锁很好的适应不同的场景,就可以降低程序员的负担
对于当前JVM的实现来说,上述锁升级的过程,属于"不可逆"
锁消除(编译器的优化策略)
编译器会对你写的synchronized代码做出判定,判定这个地方是否确实需要加锁
如果这里没有必要加锁的,就能够自动把synchronized干掉
例如:Vector,StringBuffer 自带synchronized
锁消除虽然存在,但是写代码的时候,不能无脑加锁
锁粗化(编译器的优化策略)
锁的粒度:粗和细(和代码量有关,并且是实际执行的)
代码越少,粒度就越细,代码越多,粒度就越大
一段代码中,有多次加锁解锁操作,编译器和JVM会自动进行锁的粗化
细粒度代码每一次加锁都会有可能涉及到阻塞等待
频繁的申请释放锁可能会影响到性能,每一次申请锁都有一定的开销的
锁的粗化就是把多个细粒度的锁变成一个粗粒度的锁
CAS(Compare and Swap)
比较内存中的数据和cpu寄存器中的数据,如果相同,就交换(内存和另一个寄存器中的数据)
一个内存的数据,和两个寄存器中的数据进行操作(寄存器1和寄存器2)
比较内存中的值和寄存器1中的值是否相等
如果相等,则交换内存的数据和寄存器2的数据
如果不相等就不交换,返回false
以下代码为伪代码,仅为了方便理解
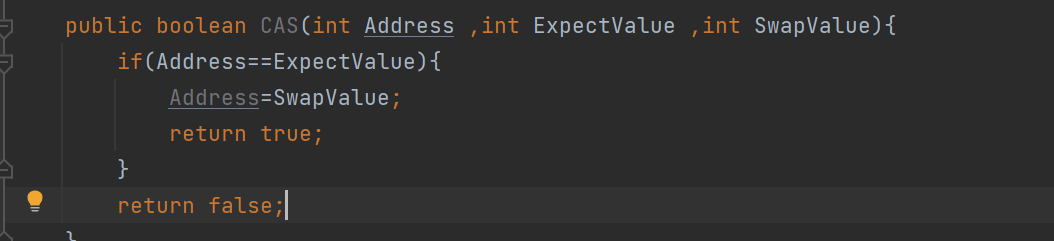
此处的代码并
不是原子的,真是的CAS是一个原子的硬件指令完成的
当多个线程同时对某个资源进行CAS操作,只能有一个线程操作成功,但是并不会阻塞其他的线程,其他的线程只会收到操作失败的信号
CAS可以理解为是乐观锁的一种实现方式
CAS具体的使用场景
1)基于CAS实现"原子类"
int/long 在进行++操作的时候,并不是原子的
基于CAS实现原子类,对int/long等这些类型进行封装,从而可以原子的完成++,--等操作
原子类在 Java 标准库中,也有现成的实现
public static void main(String[] args) throws InterruptedException {AtomicInteger atomicInteger =new AtomicInteger(0);Thread thread1=new Thread(()->{for(int i=0;i<5000;i++){atomicInteger.incrementAndGet();}});Thread thread2=new Thread(()->{for(int i=0;i<5000;i++){atomicInteger.incrementAndGet();}});thread1.start();thread2.start();thread1.join();thread2.join();System.out.println(atomicInteger.get());}
结果

incrementAndGet()=++i;
getAndIncrement()=i++;
decrementAndGet()=--i;
getAndDecrement()=i--;
源码中的native修饰的方法是"本地方法",这个方法的实现是在JVM内部,通过C++代码实现的
Unsafe不太安全(这里的代码偏底层的代码,需要有一定的操作系统和硬件的理解才能正确的使用这里的代码,一般不建议直接使用Unsafe)
原子类的伪代码如下:
private int value;public int getAndIncrement(){int oldValue =value;while(CAS(value,oldValue,oldValue+1)!=true){oldValue=value;}return oldValue;循环的判断条件里对比value和oldValue是否相同,相同就讲oldValue+1的值给value
也意味着没有线程穿插到两个代码之间,此时就可以安全的修改变量的内容
如果不相同意味着上方的赋值和此处的CAS之间有其他的线程穿插执行,其他线程修改了Value的值
这个循环条件能感知到是否有其它线程进行修改,如果有修改则CAS返回false,再次循环
2)实现自旋锁
基于CAS实现更灵活的锁(自旋锁)
public class SpinLock{private Thread Oner=null;public void Lock(){//查看锁是否被线程持有,如果锁被别的线程持有就自旋等待,如果没有被别线程持有,则尝试加锁while(!CAS(this.Oner , null ,Thread.currentThread())){//被别的线程持有,则自旋等待}}public void unlock(){this.Oner=null;}}CAS存在的问题---ABA问题
ABA问题是什么 ?
例如:
CAS(value,oldValue,swapValue)
如果value的值和oldValue值一样,则,将swapValue的值赋给value
但是这期间,value的值也许会发生变化,线程无法区分这个值是否始终是value或者是经历了一个变化过程
通常不会发生异常,但是不能排除一些的特殊情况
异常的过程:银行存款有100,有两个线程A,B都读取到了100,并且都计划将100改为50,线程A先改了,在B执行前,有人给存款又打了50,所以B读取到的余额是100,所以B又执行了一次扣款操作
解决方案:要给修改的值引入版本号(或者时间戳),读取数值是否相同的时候,也要读取版本号是否相同,如果版本号也相同,此时真正的执行修改操作,并且版本号+1,如果当前版本高于获取到的版本号,就操作失败(认为数据已经被修改过了)