李宏毅深度学习教程 第8-9章 生成模型+扩散模型
【2025版】12 生成式对抗网络GAN 一 – 基本概念介紹_哔哩哔哩_bilibili
目录
1. GAN生成式对抗网络
2. GAN的训练 散度差异
3.WGAN
4.训练GAN
5. 如何客观评估GAN
6. 条件型生成(按照要求)
7. Cycle GAN(互转配对)
8. diffusion model 扩散模型
1. GAN生成式对抗网络
生成式问题:模型的创造力 没有标准答案 就像大家头脑风暴各自围绕话题说一说,
比如问模型想吃一个水果 机器人会回答 苹果、梨、草莓等等,
又比如让模型根据描述 生成更多的文字/图片/视频。
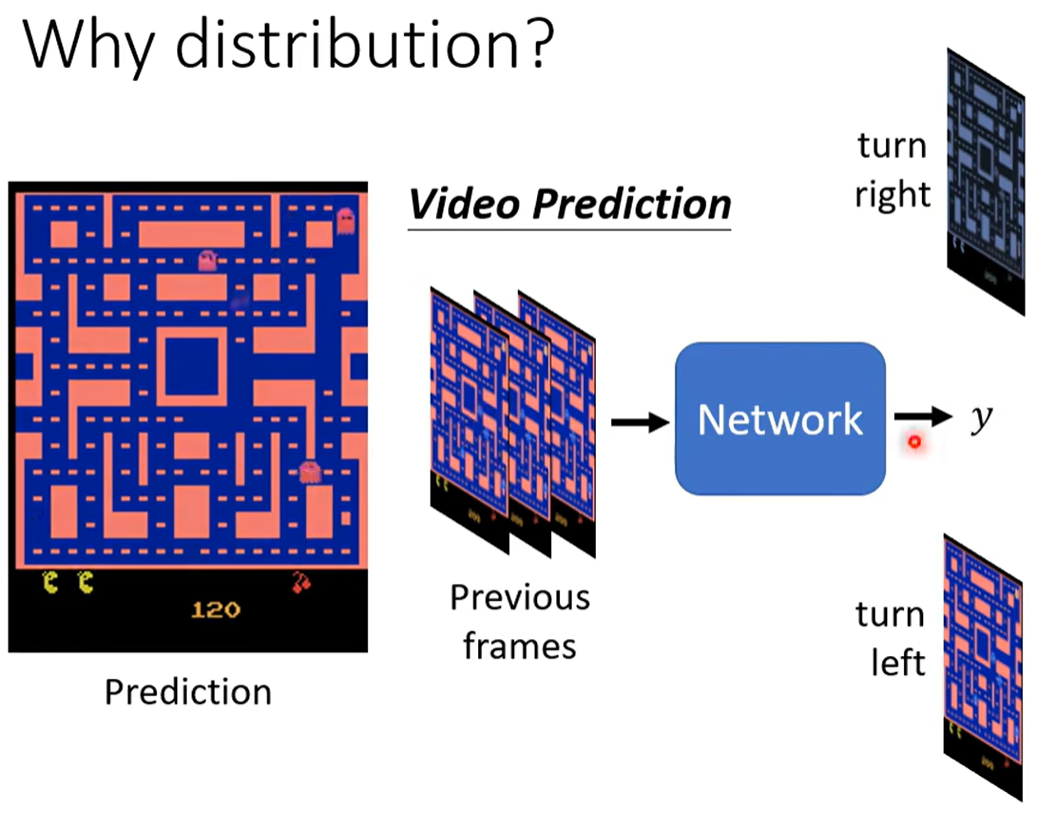
在监督学习下会存在问题:比如一个预测下一帧的游戏图像 给网络过去几帧的游戏画面,
但因为训练数据对同一个转角 有向左走、向右走这样不同且矛盾的数据,所以训练的结果网络会学会“两面讨好”,输出“又要接近向左走 又要接近向右转”。
我可以给一个二项分布 让机器可能学到 0则左转 1则右转,这样就不会冲突。
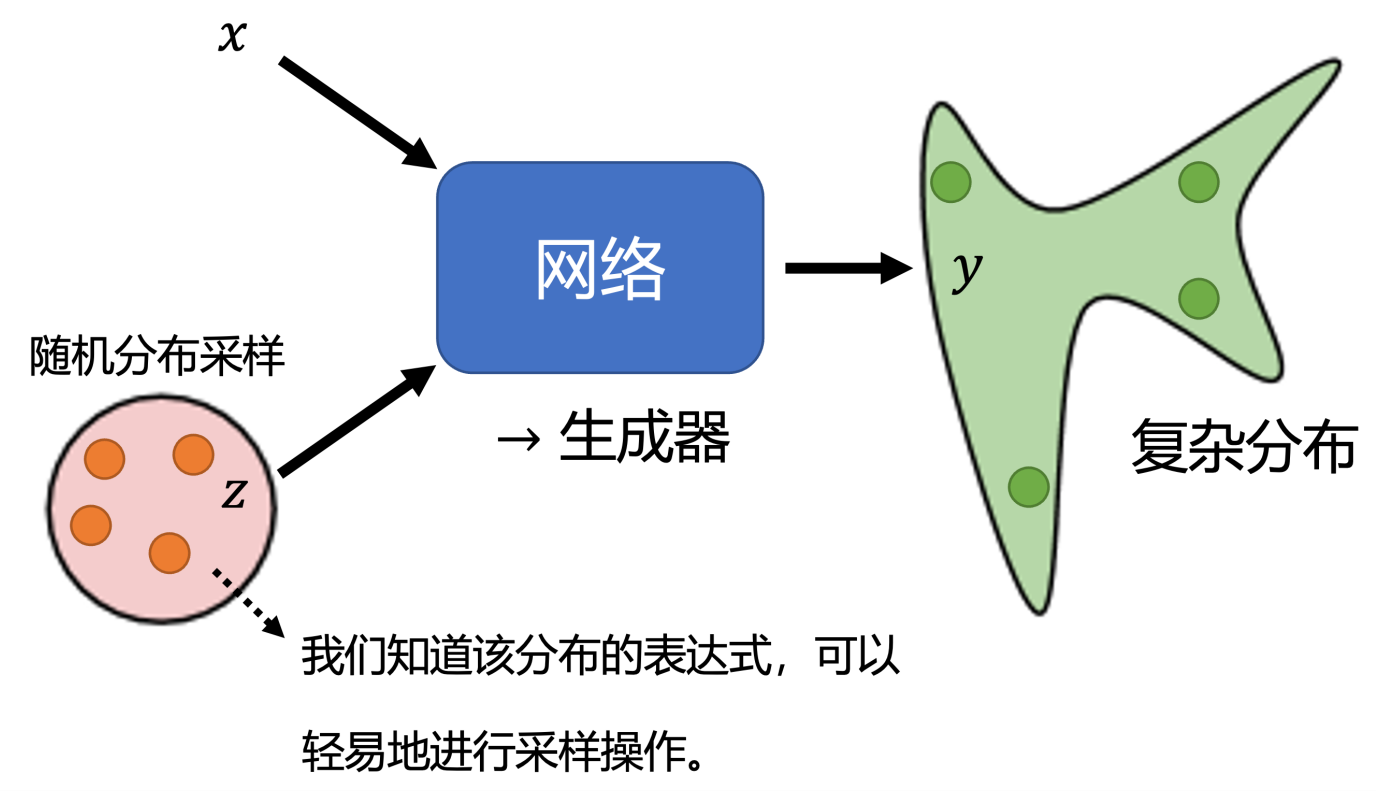
总的操作为:输入x 并在一个随机分布(通常用正态分布)获得采样值z 一起送到网络中,然后产生最后的输出y,这样就可以实现输出结果的分布是非固定,不冲突的。
2. GAN的训练 散度差异
把原始样本和生成器生成的样本混在一起,辨别器discriminator需要从中挑出生成器生成的样本。(就像图灵测试 一方尝试装得像 一方尽量区分) 进行“骗”与“找”的对抗,二者一起越来越强。
原始数据的分布p 和生成数据分布q,生成器要让这两个分布尽可能接近,判别器做二分类操作。
训练过程:固定生成器G 训练辨别器D ; 再固定辨别器D 训练生成器G;二者交替。
需要设置 生成数据q(x) 参考数据p(x) 的差异度量divergence,
相当于最小最大博弈过程,可用Conjugate共轭对偶的知识 设置差异函数。 经典差异函数有KL JS.

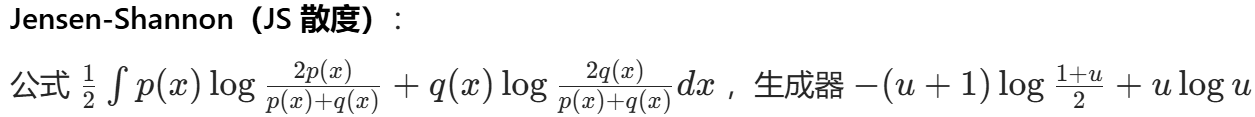
3.WGAN
JS散度的问题:原始 GAN 中,当生成分布与真实分布几乎没有重叠时,JS 散度为常数 log 2。这意味着基于 JS 散度构建的判别器损失对于生成器参数梯度几乎为零,导致生成器难以更新参数。
如果要构建一张人物头像,对于一组随机像素,几乎不可能恰好就是一张人物头像。
所以人物头像的分布,在高维的空间中其实是非常狭窄的,就算是这两个分布实际上很相似,也很难有任何的重叠的部分。
WGAN 使用 Wasserstein 距离(推土机距离),可以衡量两个分布之间的真实 “距离”,即使两个分布没有重叠,仍然能够提供有意义的梯度信息,使得生成器能够在训练初期也能稳定地更新参数,避免了梯度消失问题,从而让训练过程更加稳定和可控。
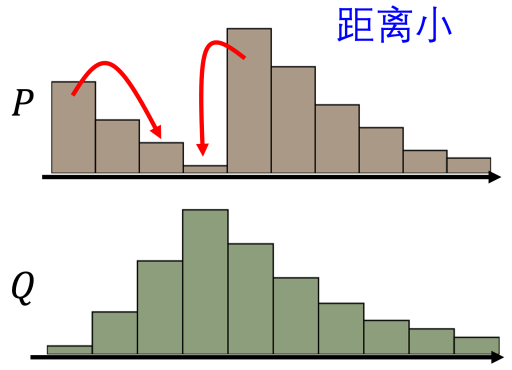
Wasserstein 距离:所有边缘分布为Pr Pg 的最小联合分布距离。
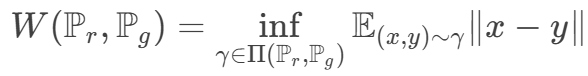
对偶问题为
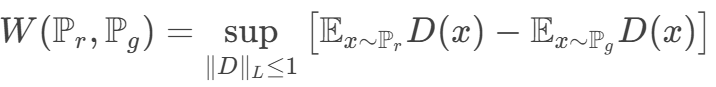
![]()
这个条件限制(可以使用梯度惩罚/谱归一化的操作) 保证训练的平滑收敛
![]()
![]()
本来两个分布 p和 q 距离非常遥远,要它一步从开始就直接跳到结尾,这是非常困难的。但是如果用 Wasserstein 距离,可以让 它们慢慢挪近到一起,最后就可以让它们对齐在一起。所以在训练时它可以让我们的生成器一步一步地变好,而不是一下子就变好。
4.训练GAN
训练难点是 需要生成器和判别器同时训练 互相一步一步一起变强
1. 假设一方突然太强 另一方就会很难进行判别/生成操作 导致训练停止

2. 文本生成时,生成器输出的词是离散的 微小参数变化可能不改变最终输出词 导致梯度无法回传
技巧:1. 生成器与判别器交替训练几步 保持二者势均力敌
2. 标签平滑:判别器对真实样本标签 标1.0会使得判别过于自信 可以缩减改标为0.9
3. 使用 VAE(变分自编码器) Flow-based Generative Model 等其它算法
5. 如何客观评估GAN
主观上:人眼看这张图是否合乎常理 像现实中真的物品 但需要找客观的评估指标
一个想法:训练一个图像的分类系统 会输出生成的这张图片是某一类别的概率分布
如果某样概率特别特别大 那说明就是这个类别;否则四不像 说明生成的质量比较差
比如一个专门生成“辛普森一家”的生成器 生产了下面两张图片 哪张图生成的更符合要求呢?
丢到分类系统里 这个“霸子”概率特别高 说明就是“霸子”;下面这张几个都不太属于,则不符合要求

但会出现模式坍塌的问题 多样性降低 生成数据的分布只是原来真实数据分布的一小部分
比如说我给了它一堆各种品类苹果的样本 模式坍塌值生成器只会拼命生成某一类苹果
但判别器会觉得它生成的图片都没问题 但检测不出多样性太少
(这会导致看几张它生成的图片不觉得有问题,但看多了很多雷同的 就知道生成器有问题)

度量多样性:看之前分类系统 概率分布的平均分布,如果平均分布很集中说明多样性比较差;
如果平均分布比较分散 说明有较好的多样性。
评估的难点:1.同时考虑生成图片的质量和多样性 2.定量评估一个 对于人来说主观的东西
FID(Frechet Inception Distance)使用预训练的Inception-v3网络提取生成图像和真实图像的高维特征,然后计算两个分布之间的Frechet距离(即均值和协方差的差异)。
![]()
距离越小,生成数据越接近真实数据的多样性
6. 条件型生成(按照要求)
生成器根据条件x 与随机变量z 生成y
提出文字要求(条件) 可以用 Transformer 把文字转成向量,再喂给生成器。
普通判别器只看生成的图片真不真实,条件型判别器则要 "双查",还要看图片和条件对不对得上(比如 "红眼睛" 的条件,不能生成蓝眼睛)。
训练时,可以故意搞些 "错题"(比如用 "黑头发" 的文字配 "黄头发" 的图)让判别器练手,确保它能精准判断 "内容是否符合条件"。
除了文字条件外,条件型生成还能做 "图片变图片"(Pix2pix),原理和文字变图一样,只是 "条件 x" 从文字换成了图片。
例如:给张素描,生成实景;给张白天的街景,生成夜景;给张房屋设计图,生成 3D 效果图。
7. Cycle GAN(互转配对)
如果没有成对的 pariwise训练数据(比如有一堆真人照片和动漫头像,却没有 "同一个人" 的真人 - 动漫对照图),怎么让 AI 把真人转成动漫风格?
Cycle GAN ——在没有 "配对数据" 的情况下,学会两种风格的转换。
核心思路:用 "循环一致性" 逼 AI 学规律 就像学翻译时,把中文译成英文,再把英文译回中文,两次翻译后要和原文差不多 ——Cycle GAN 用了同样的 trick: 训练两个生成器:G 负责把 "真人域" 转成 "动漫域",F 负责把 "动漫域" 转回 "真人域"。
强制要求:一张真人照片经 G 转成动漫后,再经 F 转回真人,结果必须和原图几乎一样。
这样一来,G 不敢乱生成(否则 F 转不回去),只能学到 "保留原图特征 + 转换风格" 的规律(比如把真人的五官保留,换成动漫的线条和色彩)。
Cycle GAN 还能双向工作:既能把真人转动漫,也能把动漫转真人。每个方向都配一个判别器,确保转换后的图片符合目标域的风格(比如动漫转真人时,结果要像真实照片)。
文字风格、语音文字互转、缩句与扩充也同理可用Cycle GAN操作。
8. diffusion model 扩散模型
去噪扩散概率模型(Denoising Diffusion Probabilistic Model,DDPM)
“塑像就在石头里,我只是把不需要的部分去掉”——米开朗基罗
我要生成一张猫的图像 就是从一张随机像素点开始,重复用噪声预测器去噪 越来越接近一只猫。
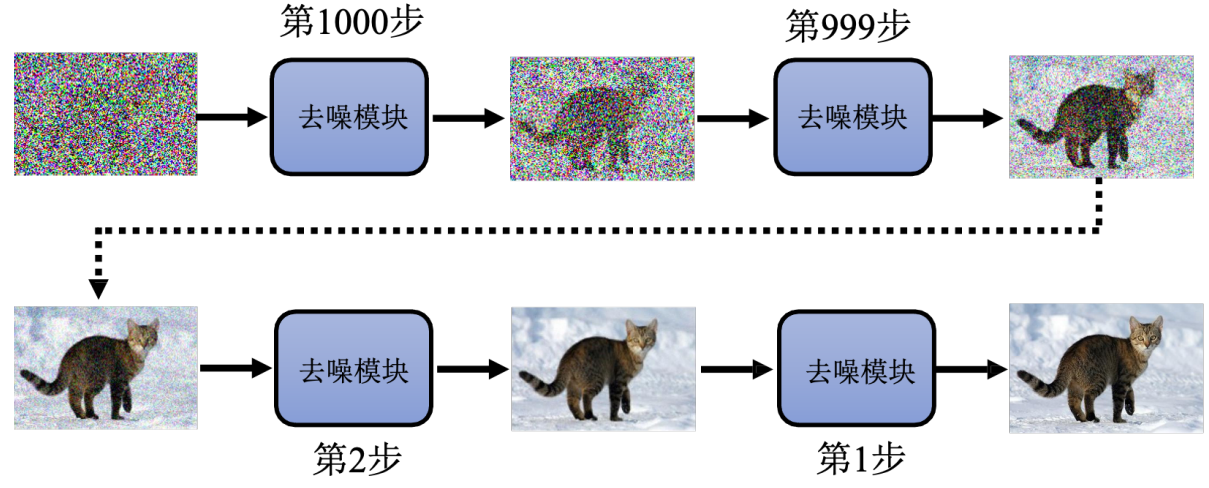
Q:为啥不直接端到端 从噪声图直接到结果
A:使用一个噪声预测器 比端到端产生一个带噪声的猫的图片 简单的多
训练数据:第n步去噪应该去成什么样子呢?
用一只猫的图像 一步一步加噪声;第n步去噪的训练参考 就是这个第n次加噪("前向扩散")
就像老师故意把作业弄脏,让学生练习 "擦掉脏东西"—— 练熟了,模型自然会在生成时反向操作,从纯噪声里 "擦掉" 所有噪声
想实现“文生图” 只需给去噪模块加个 "文字理解" 功能
目标:噪声预测器会结合文字,判断该保留哪些特征(比如 "帽子" 的形状)、去掉哪些噪声
训练时,用 "图片 + 对应文字" 的数据:先给图片加噪声,再让模型结合文字预测噪声