提升工作效率的利器:Qwen3 大语言模型
Qwen3:创新的语言模型,跨越未来的智能对话
1. Qwen3概述
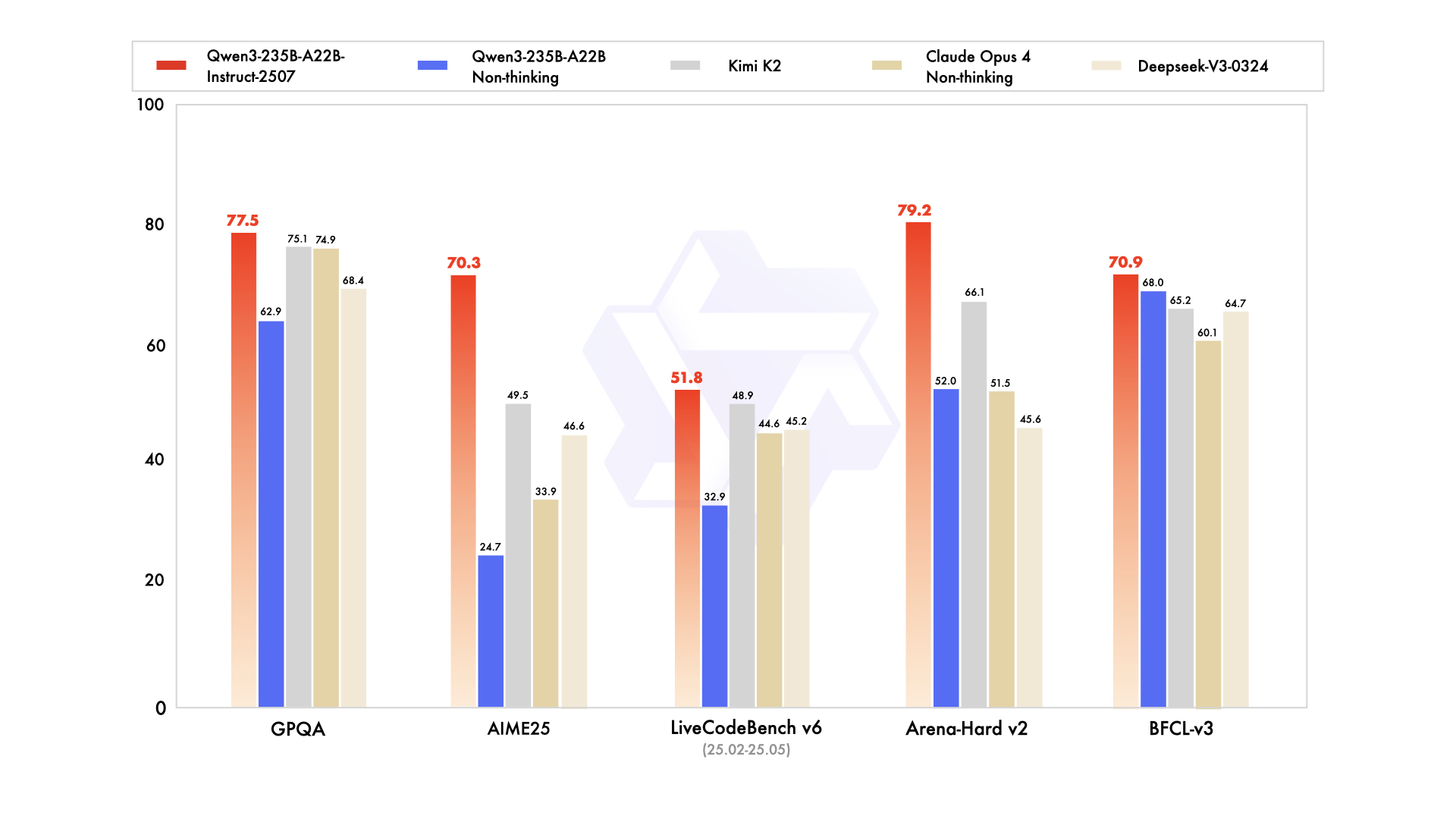
Qwen3 是由阿里云Qwen团队开发的一系列大型语言模型,自发布以来便吸引了众多开发者和企业的关注。它的最新版本为 Qwen3-235B-A22B-Instruct-2507,在多个领域取得了显著的进展,包括指令执行、逻辑推理、文本理解、科学计算、编码及工具使用等。

通过访问 Qwen Chat、Hugging Face 或 ModelScope,用户可以体验到最新的Qwen3模型,并获取相关文档。Qwen3的文档详细说明了如何快速入门、进行推理,以及在不同框架上本地运行模型。
2. Qwen3的特色功能
Qwen3在多个方面都显著提升了其性能:
- 支持256K-token长上下文理解:这是处理复杂对话和文档的重要特性。
- 跨语言知识覆盖的显著提升:支持100多种语言和方言,增强了多语言指令执行和翻译的能力。
- 与用户偏好的对齐改善:在主观和开放式任务中,Qwen3能提供更为贴近用户需求的响应。
- 思维模式和非思维模式的灵活切换:用户可以根据不同需求选择逻辑推理和一般聊天,保证最佳性能。
3. 使用Qwen3生成内容
使用Qwen3模型进行文本生成非常简单。以下是通过Transformers库使用Qwen3生成内容的代码示例:
from transformers import AutoModelForCausalLM, AutoTokenizermodel_name = "Qwen/Qwen3-235B-A22B-Instruct-2507"# 加载tokenizer和模型
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name,torch_dtype="auto",device_map="auto"
)# 准备模型输入
prompt = "给我一个关于大型语言模型的简短介绍。"
messages = [{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(messages,tokenize=False,add_generation_prompt=True,
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)# 进行文本生成
generated_ids = model.generate(**model_inputs,max_new_tokens=16384
)output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
content = tokenizer.decode(output_ids, skip_special_tokens=True)print("内容:", content)
注意:更新版的Qwen3-235B-A22B仅支持非思维模式,并且无需再指定
enable_thinking=False。
4. 在不同环境中运行Qwen3
4.1 ModelScope
建议用户特别是在中国大陆的用户使用ModelScope。它提供与Transformers相似的Python API,可以用CLI工具modelscope download来解决下载检查点的问题。
4.2 llama.cpp
llama.cpp支持在各种硬件上以最低的设置进行LLM推理。要使用CLI,可以运行以下命令:
./llama-cli -hf Qwen/Qwen3-8B-GGUF:Q8_0 --jinja --color -ngl 99 -fa -sm row --temp 0.6 --top-k 20 --top-p 0.95 --min-p 0 -c 40960 -n 32768 --no-context-shift
4.3 Ollama
在安装好Ollama后,可以通过以下命令启动Ollama服务:
ollama serve
# 确保在使用ollama时保持该服务运行
要拉取模型检查点并运行模型,可以使用如下命令:
ollama run qwen3:8b
Ollama服务还可以通过OpenAI兼容的API访问。
4.4 其它工具
LMStudio、ExecuTorch、MNN及OpenVINO等工具也支持Qwen3,可在特定平台上运行模型。
5. 部署Qwen3
Qwen3支持多种推理框架,这里展示如何使用SGLang和vLLM进行模型部署。
5.1 SGLang
python -m sglang.launch_server --model-path Qwen/Qwen3-8B --port 30000 --reasoning-parser qwen3
在http://localhost:30000/v1上可提供兼容OpenAI的API服务。
5.2 vLLM
vllm serve Qwen/Qwen3-8B --port 8000 --enable-reasoning --reasoning-parser deepseek_r1
同样在localhost:8000/v1上提供兼容OpenAI的API服务。
6. 结论
Qwen3凭借其强大的功能和灵活的应用场景,适合开发者在多语言任务、文本生成、逻辑推理等多种场景中使用。无论是进行内容生成,还是构建智能对话系统,Qwen3都将是你可靠的选择。对比同类项目,Qwen3最大特色在于灵活的模式切换、出色的多语言能力和在复杂任务中的表现,是目前开源大型语言模型中的佼佼者。
其他同类项目如OpenAI的GPT-3、Meta的LLaMA及Google的BERT等,虽然也有丰富的语言处理能力,但在可定制化、易用性及多语言支持等方面,各个模型的特性和优势有所不同。Qwen3将为用户提供更贴近需求的工具,推动更智能的对话系统的创新。