【网络与爬虫 39】Crawlee现代爬虫革命:TypeScript驱动的智能数据采集框架
关键词:Crawlee, 现代爬虫框架, TypeScript爬虫, 网页自动化, 数据采集, Playwright集成, 反爬虫技术, 分布式爬虫, 爬虫调度, 网页抓取
摘要:Crawlee是Apify开源的下一代网页爬虫和自动化库,基于TypeScript构建,提供了开箱即用的反爬虫能力、智能重试机制和强大的浏览器自动化功能。本文将深入解析Crawlee的核心特性、架构设计和实战应用,帮助开发者快速掌握这个现代化的爬虫解决方案,构建高效稳定的数据采集系统。
文章目录
- 引言:为什么我们需要新一代爬虫框架?
- Crawlee是什么?核心优势解析
- 什么是Crawlee?
- 核心优势
- 技术架构深度解析
- 架构组件说明
- 快速入门:第一个Crawlee爬虫
- 环境准备
- 基础爬虫示例
- 配置解释
- 高级特性详解
- 1. 智能反爬虫机制
- 2. 智能重试与错误恢复
- 3. 数据管道与存储
- 实战项目:构建电商价格监控系统
- 项目需求分析
- 完整实现
- 性能优化策略
- 1. 并发控制优化
- 2. 资源使用优化
- 3. 内存管理
- 监控与调试
- 1. 内置监控
- 2. 自定义监控
- 与其他工具的对比
- Crawlee vs Scrapy
- Crawlee vs Selenium
- 最佳实践建议
- 1. 项目结构组织
- 2. 错误处理策略
- 3. 数据质量保证
- 部署与运维
- 1. Docker部署
- 2. Kubernetes部署
- 3. 监控告警
- 常见问题解决
- 1. 内存溢出问题
- 2. 反爬虫检测问题
- 总结
- 核心价值
- 适用场景
- 技术优势
- 进一步学习资源
引言:为什么我们需要新一代爬虫框架?
想象一下,你正在使用传统的爬虫工具抓取一个现代化的电商网站。网站使用了React框架,数据通过Ajax异步加载,还部署了复杂的反爬虫机制。你发现:
- 传统的requests库无法处理JavaScript渲染的内容
- Selenium虽然能解决动态内容问题,但速度慢、资源消耗大
- 手动处理反爬虫、重试、错误恢复等逻辑让代码变得复杂
这就是为什么我们需要Crawlee——一个专为现代Web环境设计的爬虫框架。它不仅解决了上述所有问题,还提供了更多开箱即用的强大功能。
Crawlee是什么?核心优势解析
什么是Crawlee?
Crawlee是由Apify团队开源的现代化网页爬虫和自动化库,使用TypeScript编写,专门为处理现代Web应用而设计。它可以看作是传统爬虫工具的"升级版",集成了浏览器自动化、反爬虫规避、智能调度等功能。
核心优势
-
开箱即用的反爬虫能力
- 自动轮换User-Agent
- 智能代理管理
- 请求指纹伪造
-
强大的浏览器自动化
- 集成Playwright和Puppeteer
- 支持无头和有头模式
- 自动处理JavaScript渲染
-
智能调度系统
- 自适应并发控制
- 智能重试机制
- 优雅的错误处理
-
数据持久化
- 多种存储后端支持
- 自动数据导出
- 增量爬取能力
技术架构深度解析
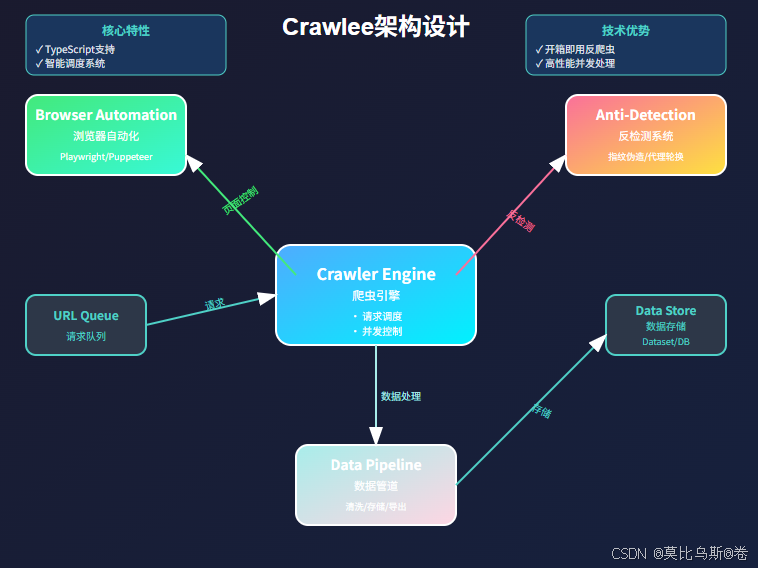
架构组件说明
Crawlee采用模块化架构设计,主要包含以下核心组件:
-
Crawler Engine(爬虫引擎)
- 负责整体调度和控制流程
- 管理请求队列和并发
- 处理错误恢复和重试
-
Browser Automation(浏览器自动化)
- 封装Playwright/Puppeteer接口
- 提供统一的浏览器操作API
- 自动管理浏览器生命周期
-
Anti-Detection(反检测)
- 指纹伪造和随机化
- 行为模拟和延迟控制
- 代理轮换和会话管理
-
Data Pipeline(数据管道)
- 数据清洗和转换
- 多格式导出支持
- 实时数据流处理
快速入门:第一个Crawlee爬虫
环境准备
# 创建新项目
mkdir crawlee-demo
cd crawlee-demo
npm init -y# 安装Crawlee
npm install crawlee
npm install @crawlee/playwright# 安装TypeScript支持(可选)
npm install -D typescript @types/node
基础爬虫示例
import { PlaywrightCrawler, Dataset } from 'crawlee';const crawler = new PlaywrightCrawler({// 请求处理函数requestHandler: async ({ request, page, enqueueLinks, log }) => {log.info(`正在处理: ${request.loadedUrl}`);// 等待页面加载完成await page.waitForLoadState('networkidle');// 提取数据const data = await page.evaluate(() => {const title = document.querySelector('h1')?.textContent;const price = document.querySelector('.price')?.textContent;return { title, price, url: window.location.href };});// 保存数据await Dataset.pushData(data);// 发现新链接await enqueueLinks({selector: 'a[href*="/product/"]',label: 'PRODUCT',});},// 错误处理failedRequestHandler: async ({ request, log }) => {log.error(`请求失败: ${request.url}`);},// 并发设置maxConcurrency: 5,// 请求延迟requestHandlerTimeoutSecs: 30,
});// 添加起始URL
await crawler.addRequests(['https://example-shop.com']);// 开始爬取
await crawler.run();
配置解释
- requestHandler: 核心处理函数,处理每个页面的逻辑
- failedRequestHandler: 失败请求的处理逻辑
- maxConcurrency: 最大并发数,控制爬取速度
- requestHandlerTimeoutSecs: 单个请求的超时时间
高级特性详解
1. 智能反爬虫机制
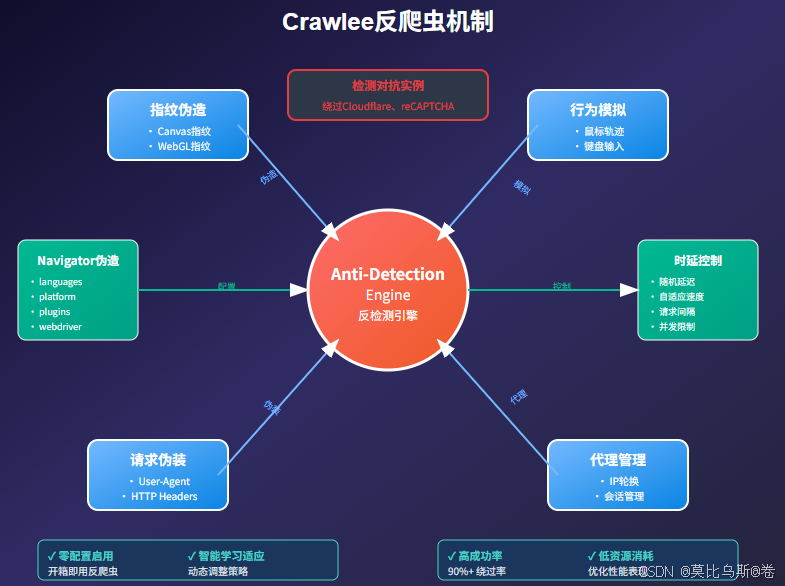
import { PlaywrightCrawler } from 'crawlee';const crawler = new PlaywrightCrawler({// 使用stealth插件launchContext: {useChrome: true,stealth: true,},// 代理配置useSessionPool: true,persistCookiesPerSession: true,// 请求拦截preNavigationHooks: [async ({ page, request }) => {// 设置随机视口await page.setViewportSize({width: 1200 + Math.floor(Math.random() * 400),height: 800 + Math.floor(Math.random() * 300),});// 模拟真实用户行为await page.addInitScript(() => {// 覆盖webdriver检测Object.defineProperty(navigator, 'webdriver', {get: () => undefined,});});},],requestHandler: async ({ page, request, log }) => {// 随机延迟await page.waitForTimeout(1000 + Math.random() * 2000);// 模拟鼠标移动await page.mouse.move(Math.random() * 1200,Math.random() * 800);// 处理页面内容...},
});
2. 智能重试与错误恢复
import { PlaywrightCrawler, RequestQueue } from 'crawlee';const crawler = new PlaywrightCrawler({// 重试配置maxRequestRetries: 3,// 自定义重试逻辑reclaim: async ({ request, log }) => {log.warning(`重新排队请求: ${request.url}`);return true;},requestHandler: async ({ request, page, log }) => {try {// 检测反爬虫页面const isBlocked = await page.locator('text=blocked').isVisible();if (isBlocked) {throw new Error('IP被封锁');}// 处理正常页面...} catch (error) {// 特定错误的重试策略if (error.message.includes('timeout')) {request.retryCount = (request.retryCount || 0) + 1;if (request.retryCount < 3) {throw error; // 触发重试}}// 记录错误但不重试log.error(`处理失败: ${error.message}`);}},
});
3. 数据管道与存储
import { PlaywrightCrawler, Dataset, KeyValueStore } from 'crawlee';
import { PrismaClient } from '@prisma/client';const prisma = new PrismaClient();const crawler = new PlaywrightCrawler({requestHandler: async ({ request, page, log }) => {// 提取结构化数据const productData = await page.evaluate(() => {return {title: document.querySelector('h1')?.textContent?.trim(),price: document.querySelector('.price')?.textContent?.trim(),description: document.querySelector('.description')?.textContent?.trim(),images: Array.from(document.querySelectorAll('.product-image img')).map(img => img.src),specs: Array.from(document.querySelectorAll('.spec-item')).map(item => ({name: item.querySelector('.spec-name')?.textContent,value: item.querySelector('.spec-value')?.textContent,})),timestamp: new Date().toISOString(),};});// 数据清洗const cleanData = {...productData,price: parseFloat(productData.price?.replace(/[^\d.]/g, '') || '0'),specs: productData.specs.filter(spec => spec.name && spec.value),};// 多重存储await Promise.all([// 保存到DatasetDataset.pushData(cleanData),// 保存到数据库prisma.product.create({ data: cleanData }),// 保存到Key-Value存储KeyValueStore.setValue(`product-${Date.now()}`, cleanData),]);log.info(`已保存产品: ${cleanData.title}`);},
});// 导出数据
await crawler.run();// 获取所有数据
const data = await Dataset.getData();
console.log(`共采集 ${data.items.length} 个产品`);// 导出为不同格式
await Dataset.exportToCSV('products.csv');
await Dataset.exportToJSON('products.json');
实战项目:构建电商价格监控系统
项目需求分析
我们要构建一个电商价格监控系统,需要:
- 监控多个电商平台的商品价格
- 处理JavaScript渲染的价格信息
- 应对各种反爬虫机制
- 实现价格变化预警
- 提供数据API接口
完整实现
import { PlaywrightCrawler, Dataset, RequestQueue } from 'crawlee';
import { PrismaClient } from '@prisma/client';
import nodemailer from 'nodemailer';interface ProductData {id: string;name: string;price: number;originalPrice: number;discount: number;availability: string;url: string;platform: string;timestamp: Date;
}class PriceMonitor {private crawler: PlaywrightCrawler;private prisma: PrismaClient;private emailTransporter: nodemailer.Transporter;constructor() {this.prisma = new PrismaClient();this.setupEmailTransporter();this.setupCrawler();}private setupEmailTransporter() {this.emailTransporter = nodemailer.createTransporter({service: 'gmail',auth: {user: process.env.EMAIL_USER,pass: process.env.EMAIL_PASS,},});}private setupCrawler() {this.crawler = new PlaywrightCrawler({launchContext: {useChrome: true,stealth: true,},useSessionPool: true,maxConcurrency: 3,requestHandlerTimeoutSecs: 60,preNavigationHooks: [async ({ page }) => {// 反爬虫设置await page.setViewportSize({width: 1920,height: 1080,});// 禁用图片加载以提高速度await page.route('**/*.{png,jpg,jpeg,gif,webp}', route => {route.abort();});},],requestHandler: async ({ request, page, log }) => {const platform = this.detectPlatform(request.url);log.info(`处理 ${platform} 商品: ${request.url}`);try {const productData = await this.extractProductData(page, platform, request.url);if (productData) {await this.saveProductData(productData);await this.checkPriceAlert(productData);}} catch (error) {log.error(`提取失败: ${error.message}`);}},failedRequestHandler: async ({ request, log }) => {log.error(`请求失败: ${request.url}`);},});}private detectPlatform(url: string): string {if (url.includes('amazon.com')) return 'Amazon';if (url.includes('taobao.com')) return 'Taobao';if (url.includes('jd.com')) return 'JD';return 'Unknown';}private async extractProductData(page: any, platform: string, url: string): Promise<ProductData | null> {// 等待页面加载await page.waitForLoadState('domcontentloaded');// 根据平台选择不同的提取策略switch (platform) {case 'Amazon':return await this.extractAmazonData(page, url);case 'Taobao':return await this.extractTaobaoData(page, url);case 'JD':return await this.extractJDData(page, url);default:return null;}}private async extractAmazonData(page: any, url: string): Promise<ProductData> {return await page.evaluate((url: string) => {const name = document.querySelector('#productTitle')?.textContent?.trim();const priceElement = document.querySelector('.a-price .a-offscreen');const price = priceElement ? parseFloat(priceElement.textContent.replace(/[^\d.]/g, '')) : 0;const originalPriceElement = document.querySelector('.a-price.a-text-price .a-offscreen');const originalPrice = originalPriceElement ? parseFloat(originalPriceElement.textContent.replace(/[^\d.]/g, '')) : price;const availability = document.querySelector('#availability span')?.textContent?.trim() || '';return {id: url.match(/\/dp\/([A-Z0-9]+)/)?.[1] || '',name: name || '',price,originalPrice,discount: originalPrice > price ? ((originalPrice - price) / originalPrice * 100) : 0,availability,url,platform: 'Amazon',timestamp: new Date(),};}, url);}private async extractTaobaoData(page: any, url: string): Promise<ProductData> {// 等待价格元素加载await page.waitForSelector('.tb-rmb-num', { timeout: 10000 });return await page.evaluate((url: string) => {const name = document.querySelector('.tb-detail-hd h1')?.textContent?.trim();const priceElement = document.querySelector('.tb-rmb-num');const price = priceElement ? parseFloat(priceElement.textContent.replace(/[^\d.]/g, '')) : 0;return {id: url.match(/id=(\d+)/)?.[1] || '',name: name || '',price,originalPrice: price,discount: 0,availability: '有货',url,platform: 'Taobao',timestamp: new Date(),};}, url);}private async extractJDData(page: any, url: string): Promise<ProductData> {await page.waitForSelector('.p-price .price', { timeout: 10000 });return await page.evaluate((url: string) => {const name = document.querySelector('.sku-name')?.textContent?.trim();const priceElement = document.querySelector('.p-price .price');const price = priceElement ? parseFloat(priceElement.textContent.replace(/[^\d.]/g, '')) : 0;return {id: url.match(/(\d+)\.html/)?.[1] || '',name: name || '',price,originalPrice: price,discount: 0,availability: '现货',url,platform: 'JD',timestamp: new Date(),};}, url);}private async saveProductData(data: ProductData) {// 保存到数据库await this.prisma.productPrice.create({data: {productId: data.id,name: data.name,price: data.price,originalPrice: data.originalPrice,discount: data.discount,availability: data.availability,url: data.url,platform: data.platform,timestamp: data.timestamp,},});// 同时保存到Datasetawait Dataset.pushData(data);}private async checkPriceAlert(currentData: ProductData) {// 获取历史价格const lastPrice = await this.prisma.productPrice.findFirst({where: {productId: currentData.id,platform: currentData.platform,},orderBy: {timestamp: 'desc',},skip: 1, // 跳过当前记录});if (lastPrice && lastPrice.price > currentData.price) {const priceDropPercent = ((lastPrice.price - currentData.price) / lastPrice.price * 100).toFixed(2);// 发送价格下降提醒await this.sendPriceAlert({productName: currentData.name,oldPrice: lastPrice.price,newPrice: currentData.price,dropPercent: priceDropPercent,url: currentData.url,platform: currentData.platform,});}}private async sendPriceAlert(alertData: any) {const mailOptions = {from: process.env.EMAIL_USER,to: process.env.ALERT_EMAIL,subject: `价格下降提醒: ${alertData.productName}`,html: `<h2>商品价格下降!</h2><p><strong>商品名称:</strong> ${alertData.productName}</p><p><strong>平台:</strong> ${alertData.platform}</p><p><strong>原价:</strong> ¥${alertData.oldPrice}</p><p><strong>现价:</strong> ¥${alertData.newPrice}</p><p><strong>降幅:</strong> ${alertData.dropPercent}%</p><p><a href="${alertData.url}" target="_blank">查看商品</a></p>`,};await this.emailTransporter.sendMail(mailOptions);console.log(`价格提醒已发送: ${alertData.productName}`);}// 添加监控商品async addProduct(url: string) {await this.crawler.addRequests([url]);}// 批量添加商品async addProducts(urls: string[]) {await this.crawler.addRequests(urls);}// 开始监控async startMonitoring() {console.log('开始价格监控...');await this.crawler.run();}// 获取价格历史async getPriceHistory(productId: string, platform: string) {return await this.prisma.productPrice.findMany({where: {productId,platform,},orderBy: {timestamp: 'desc',},});}
}// 使用示例
async function main() {const monitor = new PriceMonitor();// 添加要监控的商品await monitor.addProducts(['https://www.amazon.com/dp/B08N5WRWNW', // Echo Dot'https://detail.tmall.com/item.htm?id=123456789', // 天猫商品'https://item.jd.com/100012345678.html', // 京东商品]);// 开始监控await monitor.startMonitoring();
}// 定时任务
setInterval(() => {console.log('开始新一轮价格检查...');main().catch(console.error);
}, 60 * 60 * 1000); // 每小时检查一次if (require.main === module) {main().catch(console.error);
}
性能优化策略
1. 并发控制优化
const crawler = new PlaywrightCrawler({// 动态并发控制autoscaledPoolOptions: {minConcurrency: 1,maxConcurrency: 10,desiredConcurrency: 3,// 系统资源监控systemStatusOptions: {maxUsedCpuRatio: 0.8,maxUsedMemoryRatio: 0.7,},},// 请求队列优化requestQueueOptions: {forefront: true, // 优先处理重要请求},
});
2. 资源使用优化
const crawler = new PlaywrightCrawler({launchContext: {launchOptions: {// 禁用不必要的功能args: ['--no-sandbox','--disable-dev-shm-usage','--disable-background-timer-throttling','--disable-backgrounding-occluded-windows','--disable-renderer-backgrounding','--disable-images', // 禁用图片加载'--disable-javascript', // 如果不需要JS可以禁用],},},preNavigationHooks: [async ({ page }) => {// 阻止不必要的资源加载await page.route('**/*.{png,jpg,jpeg,gif,webp,svg,ico}', route => {route.abort();});await page.route('**/*.{css,woff,woff2,ttf}', route => {route.abort();});},],
});
3. 内存管理
import { Actor } from 'apify';const crawler = new PlaywrightCrawler({requestHandler: async ({ page, request, log }) => {try {// 处理页面...} finally {// 确保页面资源被释放await page.close();// 定期清理内存if (Math.random() < 0.1) { // 10%的概率global.gc && global.gc();}}},// 页面池管理browserPoolOptions: {maxOpenPagesPerBrowser: 5,retireBrowserAfterPageCount: 100,},
});
监控与调试
1. 内置监控
import { log, Statistics } from 'crawlee';const crawler = new PlaywrightCrawler({requestHandler: async ({ request, page, log }) => {const startTime = Date.now();try {// 处理逻辑...// 记录成功指标log.info(`成功处理: ${request.url}`, {duration: Date.now() - startTime,status: 'success',});} catch (error) {// 记录错误指标log.error(`处理失败: ${request.url}`, {duration: Date.now() - startTime,status: 'error',error: error.message,});throw error;}},
});// 获取统计信息
crawler.stats.on('requestFinished', (stats) => {console.log(`请求完成率: ${stats.requestsFinished}/${stats.requestsTotal}`);console.log(`成功率: ${(stats.requestsFinished / stats.requestsTotal * 100).toFixed(2)}%`);
});
2. 自定义监控
class CrawlerMonitor {private metrics = {requests: { total: 0, success: 0, failed: 0 },performance: { avgResponseTime: 0, maxResponseTime: 0 },resources: { memoryUsage: 0, cpuUsage: 0 },};startMonitoring() {// 定期收集指标setInterval(() => {this.collectMetrics();this.reportMetrics();}, 30000); // 每30秒}private collectMetrics() {const memUsage = process.memoryUsage();this.metrics.resources.memoryUsage = memUsage.heapUsed / 1024 / 1024; // MB// 可以集成更多监控指标...}private reportMetrics() {console.log('=== 爬虫监控指标 ===');console.log(`总请求数: ${this.metrics.requests.total}`);console.log(`成功率: ${(this.metrics.requests.success / this.metrics.requests.total * 100).toFixed(2)}%`);console.log(`内存使用: ${this.metrics.resources.memoryUsage.toFixed(2)} MB`);console.log('==================');}
}
与其他工具的对比
Crawlee vs Scrapy
| 特性 | Crawlee | Scrapy |
|---|---|---|
| 语言 | TypeScript/JavaScript | Python |
| 浏览器支持 | 原生集成 | 需要中间件 |
| 反爬虫 | 内置支持 | 需要插件 |
| 学习曲线 | 中等 | 较陡峭 |
| 性能 | 高 | 中等 |
Crawlee vs Selenium
| 特性 | Crawlee | Selenium |
|---|---|---|
| 设计目标 | 爬虫专用 | 通用自动化 |
| 反检测 | 强 | 弱 |
| 性能 | 高 | 低 |
| 易用性 | 好 | 一般 |
最佳实践建议
1. 项目结构组织
crawlee-project/
├── src/
│ ├── crawlers/
│ │ ├── amazon-crawler.ts
│ │ ├── taobao-crawler.ts
│ │ └── base-crawler.ts
│ ├── extractors/
│ │ ├── product-extractor.ts
│ │ └── price-extractor.ts
│ ├── utils/
│ │ ├── proxy-manager.ts
│ │ └── data-cleaner.ts
│ └── config/
│ └── crawler-config.ts
├── storage/
├── logs/
└── package.json
2. 错误处理策略
const crawler = new PlaywrightCrawler({// 分级错误处理failedRequestHandler: async ({ request, log }) => {const error = request.errorMessages?.[0];if (error?.includes('timeout')) {// 超时错误 - 重试request.retryCount = (request.retryCount || 0) + 1;if (request.retryCount < 3) {await RequestQueue.addRequest({...request,uniqueKey: `${request.url}-retry-${request.retryCount}`,});}} else if (error?.includes('blocked')) {// IP被封 - 更换代理await this.rotateProxy();await RequestQueue.addRequest(request);} else {// 其他错误 - 记录日志log.error(`无法恢复的错误: ${error}`);}},
});
3. 数据质量保证
class DataValidator {static validateProductData(data: any): boolean {const required = ['name', 'price', 'url'];const missing = required.filter(field => !data[field]);if (missing.length > 0) {console.warn(`缺少必要字段: ${missing.join(', ')}`);return false;}if (data.price <= 0) {console.warn('价格无效');return false;}return true;}static cleanProductData(data: any): any {return {...data,name: data.name?.trim(),price: parseFloat(data.price) || 0,description: data.description?.substring(0, 1000), // 限制长度};}
}
部署与运维
1. Docker部署
FROM node:18-alpineWORKDIR /app# 安装Playwright依赖
RUN apk add --no-cache \chromium \nss \freetype \freetype-dev \harfbuzz \ca-certificates \ttf-freefont# 安装项目依赖
COPY package*.json ./
RUN npm ci --only=production# 复制源码
COPY . .# 构建项目
RUN npm run build# 设置环境变量
ENV PUPPETEER_SKIP_CHROMIUM_DOWNLOAD=true
ENV PUPPETEER_EXECUTABLE_PATH=/usr/bin/chromium-browserEXPOSE 3000CMD ["npm", "start"]
2. Kubernetes部署
apiVersion: apps/v1
kind: Deployment
metadata:name: crawlee-app
spec:replicas: 3selector:matchLabels:app: crawlee-apptemplate:metadata:labels:app: crawlee-appspec:containers:- name: crawleeimage: crawlee-app:latestresources:requests:memory: "512Mi"cpu: "500m"limits:memory: "1Gi"cpu: "1000m"env:- name: NODE_ENVvalue: "production"- name: MAX_CONCURRENCYvalue: "5"
3. 监控告警
// 集成Prometheus监控
import client from 'prom-client';const register = new client.Registry();const requestCounter = new client.Counter({name: 'crawlee_requests_total',help: 'Total number of requests',labelNames: ['status'],
});const requestDuration = new client.Histogram({name: 'crawlee_request_duration_seconds',help: 'Request duration in seconds',buckets: [0.1, 0.5, 1, 2, 5, 10],
});register.registerMetric(requestCounter);
register.registerMetric(requestDuration);// 在请求处理中使用
const endTimer = requestDuration.startTimer();
try {// 处理请求...requestCounter.inc({ status: 'success' });
} catch (error) {requestCounter.inc({ status: 'error' });
} finally {endTimer();
}
常见问题解决
1. 内存溢出问题
// 解决方案:优化内存使用
const crawler = new PlaywrightCrawler({// 限制并发数maxConcurrency: 3,// 定期重启浏览器browserPoolOptions: {retireBrowserAfterPageCount: 50,},requestHandler: async ({ page, request }) => {try {// 处理页面...} finally {// 强制清理await page.evaluate(() => {// 清理DOMdocument.body.innerHTML = '';// 清理事件监听器window.removeEventListener;});}},
});
2. 反爬虫检测问题
// 解决方案:增强反检测能力
const crawler = new PlaywrightCrawler({preNavigationHooks: [async ({ page }) => {// 注入反检测脚本await page.addInitScript(() => {// 伪造navigator.languagesObject.defineProperty(navigator, 'languages', {get: () => ['zh-CN', 'zh', 'en'],});// 伪造navigator.pluginsObject.defineProperty(navigator, 'plugins', {get: () => [1, 2, 3],});// 伪造Canvas指纹const originalToDataURL = HTMLCanvasElement.prototype.toDataURL;HTMLCanvasElement.prototype.toDataURL = function(...args) {const result = originalToDataURL.apply(this, args);return result + Math.random().toString(36).substring(7);};});},],
});
总结
Crawlee作为新一代网页爬虫框架,通过以下特性重新定义了现代爬虫开发:
核心价值
- 开箱即用:无需复杂配置即可开始爬取
- 反爬虫优势:内置多种反检测机制
- 现代化架构:基于TypeScript,类型安全
- 高性能:智能并发控制和资源管理
- 可扩展性:模块化设计,易于定制
适用场景
- 电商数据采集:价格监控、商品信息抓取
- 新闻内容爬取:自动化新闻采集系统
- 社交媒体监控:品牌监控、舆情分析
- 竞品分析:市场数据收集和分析
- 学术研究:大规模网页数据采集
技术优势
相比传统爬虫工具,Crawlee在以下方面具有显著优势:
- 更好的反爬虫能力:内置指纹伪造、行为模拟
- 更高的开发效率:丰富的API和完善的错误处理
- 更强的可维护性:TypeScript类型安全和模块化设计
- 更好的性能:智能调度和资源管理
Crawlee不仅是一个爬虫库,更是一个完整的数据采集解决方案。它让开发者能够专注于业务逻辑,而不是底层的技术细节。在现代Web环境日益复杂的今天,Crawlee为我们提供了一个强大而优雅的解决方案。
无论你是爬虫新手还是经验丰富的开发者,Crawlee都值得加入你的技术栈。它的出现标志着网页爬虫技术进入了一个新的时代——更智能、更可靠、更高效的时代。
进一步学习资源
- Crawlee官方文档
- Crawlee GitHub仓库
- Apify平台
- Playwright文档
- TypeScript学习指南