【AI论文】Rep-MTL:释放表征级任务显著性在多任务学习中的潜力
摘要:尽管多任务学习(Multi-Task Learning, MTL)在跨任务挖掘互补知识方面展现出巨大潜力,但现有的多任务优化(Multi-Task Optimization, MTO)技术仍局限于通过以优化器为核心的损失缩放(loss scaling)和梯度操控策略来解决任务冲突,却未能实现稳定可靠的性能提升。本文提出,任务交互天然发生的共享表征空间蕴含着丰富信息,且具备与现有优化器形成互补操作的潜力,尤其在促进任务间互补性方面——这一方向在MTO领域鲜有探索。基于这一洞察,我们提出Rep-MTL框架,通过挖掘表征级任务显著性(representation-level task saliency),量化任务特定优化与共享表征学习之间的交互关系。具体而言,Rep-MTL利用基于熵的惩罚机制和样本级跨任务对齐策略引导任务显著性,旨在通过保障各任务的有效训练(而非单纯解决冲突)来缓解负迁移,同时显式促进互补信息的共享。实验在覆盖任务迁移(task-shift)和领域迁移(domain-shift)场景的四个具有挑战性的MTL基准数据集上展开。结果表明,即使采用基础的等权重策略,Rep-MTL仍能实现具有竞争力的性能提升,且效率优势显著。除标准性能指标外,幂律指数(Power Law exponent)分析进一步验证了Rep-MTL在平衡任务特定学习与跨任务共享方面的有效性。项目页面详见[此处(原文HERE处需替换为实际链接)。Huggingface链接:Paper page,论文链接:2507.21049
研究背景和目的
研究背景:
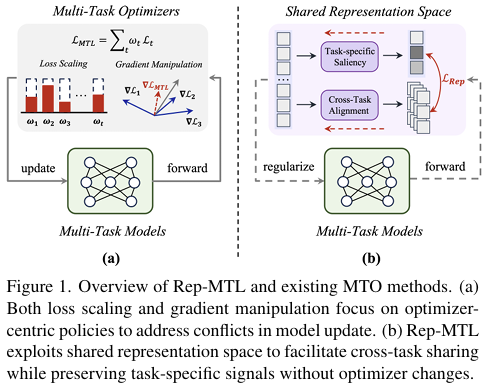
多任务学习(Multi-Task Learning, MTL)作为一种利用多个相关任务间互补知识来提升模型泛化能力和效率的机器学习方法,近年来在计算机视觉、自然语言处理等多个领域取得了显著进展。然而,随着任务数量和复杂度的增加,传统的多任务优化(Multi-Task Optimization, MTO)技术面临诸多挑战。现有方法主要集中于通过优化器调整损失缩放(loss scaling)和梯度操控(gradient manipulation)来解决任务间的冲突,但这些方法往往忽略了任务间潜在的互补性,导致负迁移(negative transfer)现象,即一个任务的学习干扰了其他任务的学习效果。
研究目的:
本研究旨在提出一种新的多任务优化框架Rep-MTL,通过挖掘表征空间中的任务显著性(representation-level task saliency),量化任务特定优化与共享表征学习之间的交互关系,从而更有效地利用任务间的互补性。具体目标包括:
- 缓解负迁移:通过保持各任务的有效训练,减少任务间的干扰。
- 促进互补信息共享:显式地鼓励任务间互补信息的传递,提升整体模型性能。
- 提高优化效率:设计一种无需修改优化器或网络架构的轻量级正则化方法,提升多任务学习的训练速度和稳定性。
研究方法
1. 任务显著性量化:
Rep-MTL通过计算共享表征空间中各任务对表征变化的敏感度(即梯度),来量化任务显著性。具体地,对于每个任务,计算其损失函数相对于共享表征的梯度,这些梯度反映了任务对共享表征的依赖程度,即任务显著性。
2. 任务显著性调节(TSR):
为了减轻负迁移,Rep-MTL引入基于熵的惩罚项来调节任务显著性分布。通过鼓励任务显著性分布的多样性,确保各任务在共享表征空间中保留其特有的学习模式,从而减少任务间的直接冲突。
3. 跨任务显著性对齐(CSA):
为了促进任务间的互补信息共享,Rep-MTL采用对比学习的方式,对齐样本级别的跨任务显著性。具体地,对于同一批样本,将不同任务下的表征显著性作为正样本对,而不同样本间的显著性作为负样本对,通过对比损失函数拉近正样本对的距离,推远负样本对的距离。
4. 联合优化:
将任务显著性调节和跨任务显著性对齐作为正则化项,与原始的多任务学习目标联合优化。通过调整正则化项的权重,平衡任务特定学习和跨任务共享之间的关系。
研究结果
1. 性能提升:
在四个具有挑战性的多任务学习基准数据集(NYUv2、Cityscapes、Office-31和Office-Home)上的实验结果表明,Rep-MTL即使与基本的等权重策略结合,也能实现与现有最先进方法相当或更优的性能。特别是在任务迁移和领域迁移场景下,Rep-MTL展现了更强的鲁棒性和泛化能力。
2. 负迁移缓解:
通过Power Law指数分析发现,Rep-MTL训练的模型在共享参数上的指数值更低,表明任务间的互补信息共享更有效,负迁移现象得到缓解。同时,任务特定解码器的指数值更平衡且更低,说明各任务的有效训练得到了保持。
3. 效率优势:
与梯度操控方法相比,Rep-MTL展现了更高的训练效率。具体地,Rep-MTL在NYUv2数据集上的训练时间比Nash-MTL和FairGrad等复杂方法分别快了约26%和12%。
研究局限
1. 超参数敏感性:
尽管Rep-MTL在一定范围内对超参数设置具有鲁棒性,但最优性能仍依赖于正则化项权重的精细调整。未来工作需进一步探索自适应超参数调整策略。
2. 复杂场景下的性能波动:
在极端复杂的任务或领域迁移场景下,Rep-MTL的性能可能出现波动,表明当前方法在处理高度异构任务时仍存在局限性。
3. 理论分析的深度:
尽管实验结果验证了Rep-MTL的有效性,但对其工作原理的深入理论分析仍显不足。未来需结合更多理论工具(如信息论、优化理论)来揭示表征级任务显著性的本质。
未来研究方向
1. 自适应超参数调整:
开发基于模型训练动态的自适应超参数调整策略,减少对人工调参的依赖,提升方法的易用性和泛化能力。
2. 复杂多任务场景下的优化:
探索在高度异构或动态变化的多任务场景下,如何进一步提升Rep-MTL的性能和稳定性。例如,引入任务关系学习或元学习策略来动态调整任务显著性。
3. 理论分析的深化:
结合信息论、优化理论等工具,深入分析表征级任务显著性的工作原理,为多任务学习提供更坚实的理论基础。
4. 跨模态多任务学习:
将Rep-MTL框架扩展至跨模态多任务学习场景(如视觉-语言联合学习),探索其在更复杂任务中的应用潜力。
5. 实际应用验证:
在真实世界的应用场景(如自动驾驶、医疗诊断)中验证Rep-MTL的有效性和实用性,推动多任务学习技术从实验室走向实际应用。