GLM-4.5 解读:统一推理、编码与智能体的全能王
引言
大型语言模型 (LLM) 的发展日新月异,它们在特定领域的能力已经达到了令人惊叹的高度。例如,GPT-3 开启了通用语言理解的时代,而 OpenAI 的 o1 和 DeepSeek-R1 则通过强化学习,在编码、数据分析和复杂数学等推理任务上取得了突破。
然而,现有的 LLM 往往是“偏科生”:有的擅长编码,有的精于数学,有的则在通用推理上表现出色,但鲜有模型能够在所有这些领域都达到顶尖水平。这种能力的“不均衡”,限制了 LLM 在处理复杂、跨领域、需要多种能力协同的真实世界任务时的表现。
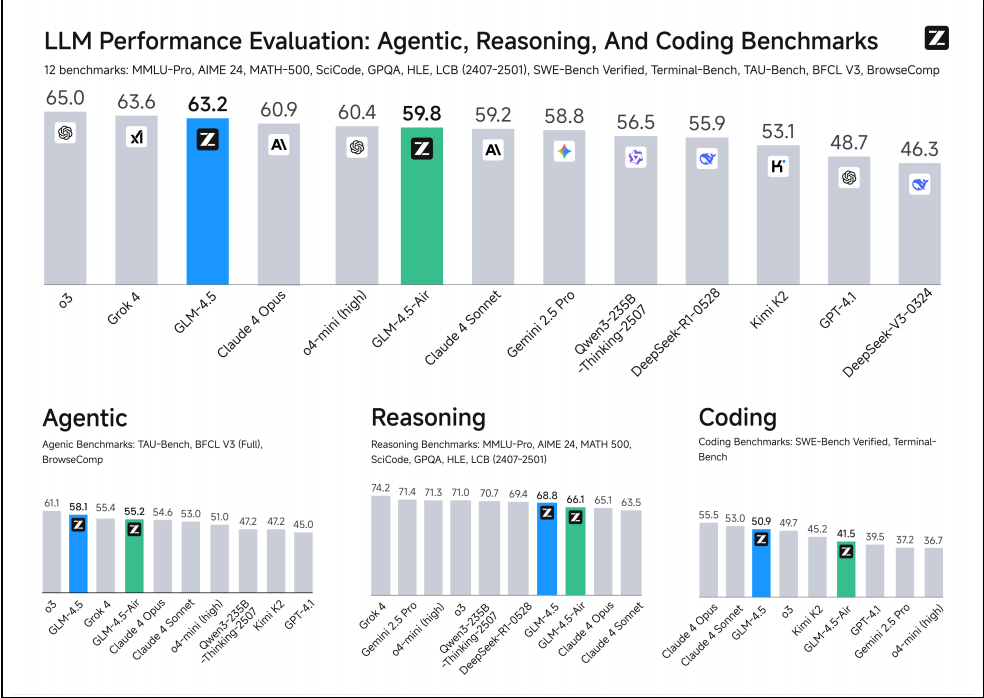
在这样的背景下,智谱 AI 推出了 GLM-4.5 系列模型,旨在统一推理、编码和智能体(Agentic)能力,打造一个真正的“全能型选手”。GLM-4.5 不仅仅是参数量的提升,更是在模型架构、训练策略、推理机制等方面进行了全面的革新,特别是其混合推理模式(思考 vs. 不思考)、强大的智能体能力、以及针对专家模型的自蒸馏等创新。
本文将作为 GLM-4.5 的深度技术解读,带你深入剖析其:
- 模型架构的精妙之处:如何通过“深”而非“宽”的 MoE 设计,提升推理能力。
- 预训练与中训练策略:如何通过多阶段、多领域的数据注入,奠定其强大的基础能力。
- 后训练的「专家培养皿」:如何通过 SFT 和 RL,培养出推理和智能体“专家”,再通过自蒸馏统一到一个模型中。
- 推理时的「思考/不思考」双模:如何实现性能与延迟的灵活平衡。
一、 GLM-4.5 设计哲学:统一、高效、智能
GLM-4.5 的核心设计哲学可以概括为以下几点:
- 能力统一 (Unified Capabilities):致力于在一个单一模型中,同时实现顶尖的推理、编码和智能体能力,避免“偏科”现象。
- 混合推理模式 (Hybrid Reasoning Models):在一个统一的框架内,集成思考模式 (thinking mode)(用于复杂、多步推理)和不思考模式 (non-thinking mode)(用于快速、上下文驱动的响应),让用户可以根据任务需求动态切换。
- 高效的 MoE 架构:采用混合专家 (MoE) 架构,在保证强大能力的同时,显著降低推理时的激活参数量,提高效率。
- 强大的智能体能力 (Agentic Abilities):原生支持函数调用,并在多个智能体基准上进行了深度优化。
- 知识蒸馏:通过“强到弱”的自蒸馏,将多个专家模型的能力高效地整合到一个统一的模型中。
二、 模型架构:更“深”的 MoE 与高效组件
GLM-4.5 系列包含两个旗舰模型:
- GLM-4.5: 355B 总参数,32B 激活参数。
- GLM-4.5-Air: 106B 总参数,12B 激活参数。
其架构在继