51c视觉~合集52
我自己的原文哦~ https://blog.51cto.com/whaosoft143/14316646
#xxx
....
#xxx
....
#xxx
....
#xxx
....
#xxx
....
#xxx
....
#xxx
....
#xxx
....
#xxx
....
#xxx
....
#xxx
....
#xxx
....
#xxx
....
#xxx
....
#xxx
....
#xxx
....
#xxx
....
#xxx
....
#xxx
....
#SemanticVLA
哈工大提出SemanticVLA:机器人操作成功率提升21.1%,推理延迟降低2.7倍
最近,机器人领域的研究者们一直在努力让机器人能更好地理解我们的世界并执行复杂任务。视觉-语言-动作(Vision-Language-Action, VLA)模型是实现这一目标的关键技术,它试图将视觉感知、语言指令和机器人动作直接端到端地联系起来。然而,这类模型在实际部署时常常遇到两个头疼的问题:一是“看得太多”,处理了大量无关的视觉信息,导致效率低下;二是“理解太浅”,语言指令和视觉场景的对齐不够深入,影响了动作的准确性。
为了解决这些挑战,来自哈尔滨工业大学(深圳)和华为诺亚方舟实验室的研究者们共同提出了一种名为SemanticVLA的新框架。这项工作已被人工智能顶级会议 AAAI 2026 接收为Oral论文。SemanticVLA,全称“语义对齐的稀疏化与增强”(Semantic-Aligned Sparsification and Enhancement),它的核心思想非常巧妙:在感知信息时做“减法”,只关注与任务最相关的部分,同时在“理解”层面做“加法”,增强语义和空间信息的融合,从而实现更高效、更精准的机器人操作。
- 论文标题: SemanticVLA: Semantic-Aligned Sparsification and Enhancement for Efficient Robotic Manipulation
- 论文作者: Wei Li, Renshan Zhang, Rui Shao, Zhijian Fang, Kaiwen Zhou, Zhuotao Tian, Liqiang Nie
- 作者机构: 哈尔滨工业大学(深圳)、华为诺亚方舟实验室
- 论文地址: https://arxiv.org/abs/2511.10518
- 项目主页: https://github.com/JiuTian-VL/SemanticVLA
- 录用会议: AAAI 2026 (Oral)
背景:VLA模型的“效率”与“理解”困境
想象一下,你让一个机器人“把桌上的红苹果递给我”。对于人类来说,这个任务很简单。但对VLA模型而言,它首先要“看”到整个房间的景象,这个景象包含了桌子、椅子、背景墙、以及桌上的各种物品。
传统VLA模型,如OpenVLA,会把摄像头捕捉到的所有像素信息一股脑地塞给一个强大的视觉编码器进行处理。这就导致了感知冗余(perceptual redundancy):模型花费了大量算力去分析那些与“红苹果”无关的背景和干扰物。
更重要的是,模型需要将“红苹果”这个词和图像中对应的物体精确关联起来。如果这种关联只是“浅尝辄止”,即指令-视觉对齐肤浅(superficial instruction-vision alignment),模型可能就无法准确地从一堆水果中定位到那个又红又圆的苹果,更别提后续的抓取动作了。这两个问题共同构成了当前VLA模型在走向实际应用时的主要障碍。
SemanticVLA:双管齐下的高效感知与深度理解
为了破解上述困境,SemanticVLA设计了一套精巧的“组合拳”。它不再“一视同仁”地处理所有视觉信息,而是通过一个双路并行的架构,有选择性地提取和融合信息。
整个框架的核心可以概括为三个关键组件:
1. 语义引导的双重视觉剪枝器 (SD-Pruner)
这是SemanticVLA实现“感知减法”的关键。它包含两条并行的剪枝路径,分别处理不同维度的信息:
- 指令驱动剪枝器 (ID-Pruner): 这条路径使用擅长理解图文关系的SigLIP模型。它的第一步是构建一个视觉-语言相似度矩阵 ,用于衡量每个视觉图像块(token) 与每个指令单词(token) 之间的关联程度。
-
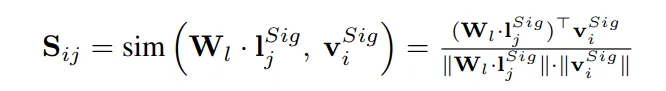
- 基于这个相似度矩阵,ID-Pruner会从两个维度进行双向剪枝:
- 从视觉到语言(V-to-L):通过聚合相似度分数,找到指令中最关键的几个词(如“苹果”、“桌子”),这些词的对应视觉特征构成了与任务意图最相关的“全局线索”。
- 从语言到视觉(L-to-V):反过来,通过聚合分数,找到与整个指令最相关的几个视觉图像块,这些图像块构成了场景中的“局部语义锚点”。 通过这种方式,它能从海量视觉数据中筛选出最关键的语义信息。
- 空间聚合剪枝器 (SA-Pruner): 另一条路径则使用精于捕捉几何和空间结构的DINOv2模型。它不侧重于理解“是什么”,而是关注“在哪里”、“形状如何”。它会将富含几何信息的特征压缩成少数几个“任务自适应”的视觉令牌(tokens),高效地表征场景的空间布局。
通过ID-Pruner和SA-Pruner的协同工作,SemanticVLA能将原始高达256个视觉令牌的输入,压缩到32个甚至16个,极大地降低了后续处理的计算负担,同时保留了语义和空间的核心信息。
2. 语义互补的层次化融合器 (SH-Fuser)
筛选出关键信息后,如何将它们有效“捏合”在一起呢?SH-Fuser扮演了“融合大师”的角色。它并非简单地将两条路径的输出在最后拼接,而是在两个视觉编码器(SigLIP和DINOv2)的多个不同深度层级上,进行层次化的信息交互和融合。这确保了语义线索(来自SigLIP)在早期就能得到空间几何先验(来自DINOv2)的补充和增强,从而生成对任务更全面的连贯表示。
3. 语义条件的动作耦合器 (SA-Coupler)
在动作生成阶段,SemanticVLA也进行了创新。传统的VLA模型通常将一个7自由度(DoF)的机器人动作(3维平移、3维旋转、1维夹爪)拆解成7个独立的数值进行预测。这种方式不仅冗长,也缺乏语义上的整体性。
SA-Coupler则将这7个自由度耦合成了3个具有明确语义的动作元语:平移(translation)、旋转(rotation)和夹爪(gripper)。每个元语由一个专门的、可学习的动作占位符令牌(placeholder token)表示,其结构如下:
其中, 分别代表第 个未来时间步的平移、旋转和夹爪动作的初始令牌。这样做的好处是,模型可以直接在更高维度的语义空间中学习“移动到某处”、“旋转一定角度”或“开合爪子”这些原子动作,而不是去预测一堆孤立的数字。这不仅使行为建模更高效、更符合直觉,也显著减少了需要预测的动作令牌数量(从7个减为3个)。
实验效果:性能与效率的双重飞跃
理论说得好,还得看疗效。研究者们在主流的仿真基准LIBERO和真实世界的机器人平台上对SemanticVLA进行了广泛的实验验证。
仿真任务大获全胜
在LIBERO基准测试中,包含了空间推理、物体泛化、目标理解和长时程任务等四大类挑战。
结果显示,SemanticVLA全面超越了包括OpenVLA、π₀在内的所有SOTA方法。其标准版SemanticVLA取得了97.7%的总体成功率,位列第一。值得一提的是,它在最具挑战性的长时程任务(Long)中也取得了第一的成绩。与强大的基线模型OpenVLA-OFT相比,SemanticVLA在总体成功率上高出0.6%,而与原始的OpenVLA相比,成功率更是提升了21.1%之多。
在效率方面,SemanticVLA的优势更加惊人。
与OpenVLA相比,SemanticVLA将训练所需的总计算量(FLOPs)降低了约3.6倍,训练时间从11.7小时缩短到3.9小时。在推理时,其延迟从0.240秒降低到0.089秒,速度提升了2.7倍。即便是更轻量的SemanticVLA-Lite版本(仅用16个视觉令牌),也能在极高的效率下达到95.8%的成功率,实现了最佳的性能-效率权衡。
真实世界表现稳健
研究团队还在AgileX Cobot Magic和Galaxea R1 Lite两个真实机器人平台上验证了模型的泛化能力,任务包括物体放置、开关抽屉、折叠T恤等。
在真实世界中,SemanticVLA同样表现出色,总体成功率达到了77.8%,显著优于其他对比方法(55.6%)。这证明了SemanticVLA的语义对齐和稀疏化策略并非只在仿真中有效,而是能够稳健地迁移到充满噪声和变化的真实物理世界。
上图展示了SemanticVLA在真实世界中执行长时程任务的过程,可以看到它能够准确理解指令,并连贯地完成一系列复杂操作。
可视化分析:模型在“想”什么?
为了探究SemanticVLA为何如此有效,研究者们对其内部的注意力机制进行了可视化。
从可视化结果可以看出:
- ID-Pruner确实能够根据指令,将注意力集中在与任务相关的物体和区域上,有效过滤了背景干扰。
- SA-Pruner则捕捉到了更广泛的场景结构信息,作为ID-Pruner的补充。
- 模型能够自动识别出指令中的关键词(如“橙色”、“大”、“左边”),并将这些语义线索与视觉场景中的具体特征对应起来,实现了精准的语义-视觉对齐。
总结
总的来说,SemanticVLA通过一套精心设计的“语义对齐稀疏化与增强”机制,成功地解决了当前VLA模型在感知效率和语义理解上的核心痛点。它不仅在仿真和真实世界任务中取得了SOTA的性能,更重要的是,它以一种优雅且高效的方式,为如何构建更智能、更实用的机器人操作代理提供了一个全新的思路。
....