数据处理和统计分析——09 数据分组
1 聚合
1.1 简介
- 在SQL中我们经常使用
GROUP BY将某个字段,按不同的取值进行分组,在Pandas中也有groupby()函数; - 分组之后,每组都会有至少1条数据,将这些数据进一步处理返回单个值的过程就是聚合,比如分组之后计算算术平均值,或者分组之后计算频数,都属于聚合。
1.2 单变量分组聚合
-
加载数据:
-
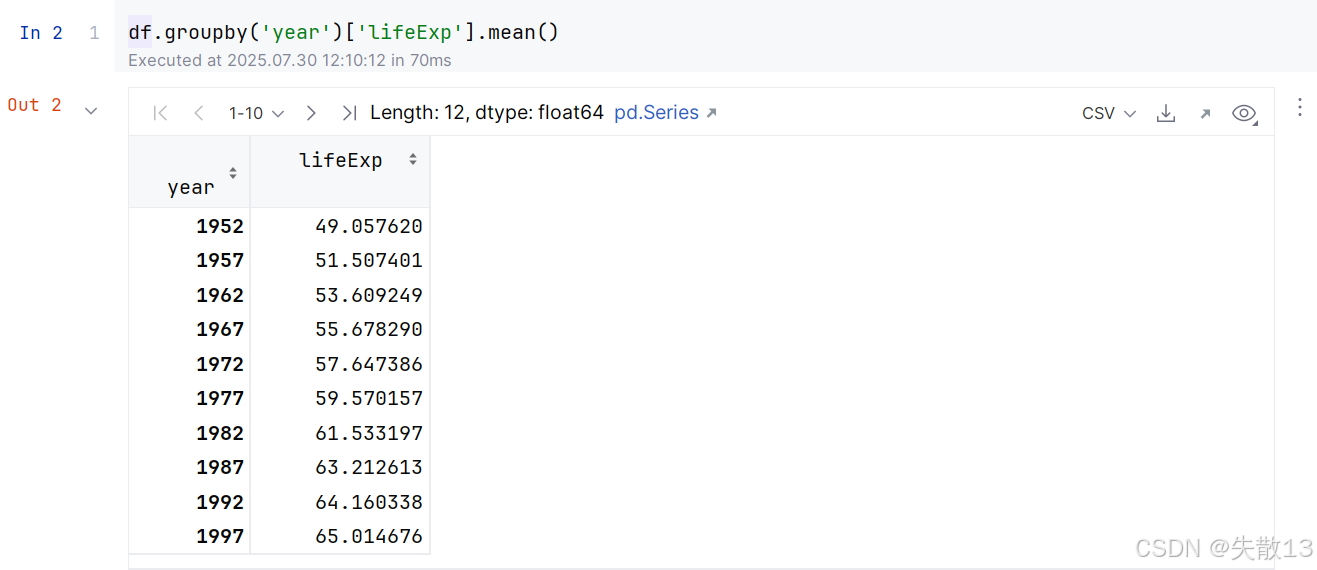
按照年份分组,计算平均寿命
-
查询年份:
-
对 1952 年进行聚合,计算平均寿命:

1.3 聚合函数
1.3.1 常用聚合函数
| Pandas 方法 | Numpy 函数 | 说明 |
|---|---|---|
| count | np.count_nonzero | 频率统计 (不包含 NaN 值) |
| size | 频率统计 (包含 NaN 值) | |
| mean | np.mean | 求平均值 |
| std | np.std | 标准差 |
| min | np.min | 最小值 |
| quantile() | np.percentile() | 分位数 |
| max | np.max | 求最大值 |
| sum | np.sum | 求和 |
| var | np.var | 方差 |
| describe | 计数、平均值、标准差,最小值、分位数、最大值 | |
| first | 返回第一行 | |
| last | 返回最后一行 | |
| nth | 返回第 N 行 (Python 从 0 开始计数) |
-
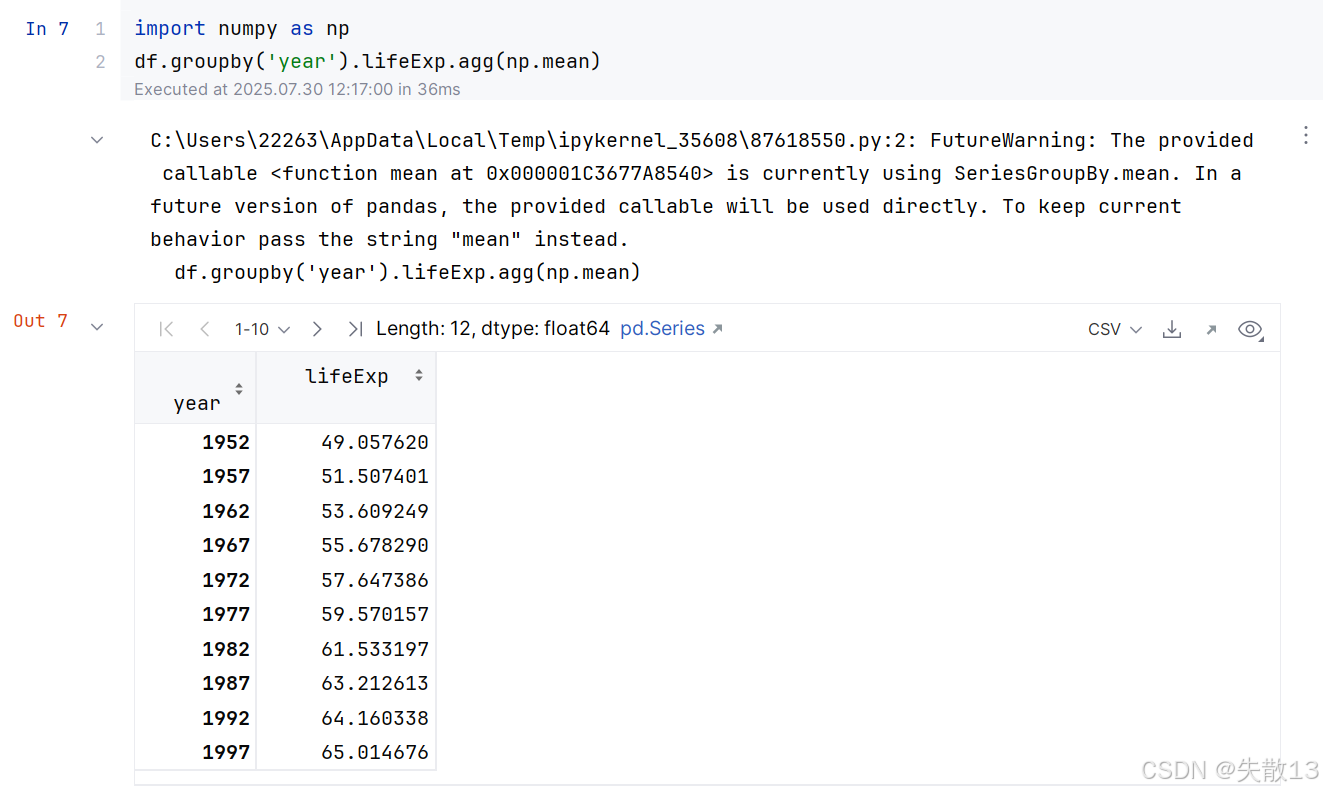
例:使用 Numpy 的求平均值方法
FutureWarning:提示在未来的 Pandas 版本中,提供的可调用对象(这里是np.mean)将直接被使用。为了保持当前的行为,应该传递字符串"mean"而不是np.mean。也就是说,建议将代码修改为df.groupby('year').lifeExp.agg("mean");
1.3.2 agg()函数
-
在 Python 的 Pandas 库中,
agg(是aggregate的缩写)是一个用于数据聚合操作的方法; -
agg方法常用于在分组操作(groupby)之后,对每个分组的数据进行聚合计算,比如计算每个分组的总和、平均值、最大值、最小值等;也可以在没有分组的情况下,直接对整个数据对象(如Series或DataFrame)进行聚合操作; -
对
Series对象使用agg:直接对Series对象调用agg方法,传入一个聚合函数(可以是内置函数,也可以是自定义函数),对整个Series的数据进行聚合;import pandas as pddata = [1, 2, 3, 4, 5] s = pd.Series(data) result = s.agg(sum) print(result) -
结合
groupby对DataFrame使用agg:先使用groupby对DataFrame进行分组,然后对每个分组调用agg方法,传入一个或多个聚合函数,对分组后指定列的数据进行聚合;import pandas as pddata = {'category': ['A', 'A', 'B', 'B'],'value': [10, 20, 30, 40] } df = pd.DataFrame(data) # 按category列分组,对value列求平均值 result = df.groupby('category').value.agg('mean') print(result) -
自定义函数:用户可以定义自己的聚合函数,然后传递给
agg方法;-
自定义函数若被
agg()函数当做聚合函数来使用时,自定义函数中有且至少要有一个参数。但agg()函数传递给自定义聚合函数的是一个Series对象,若想得到Series的每一个值,需要再自定义聚合函数中需要通过for循环迭代才能实现;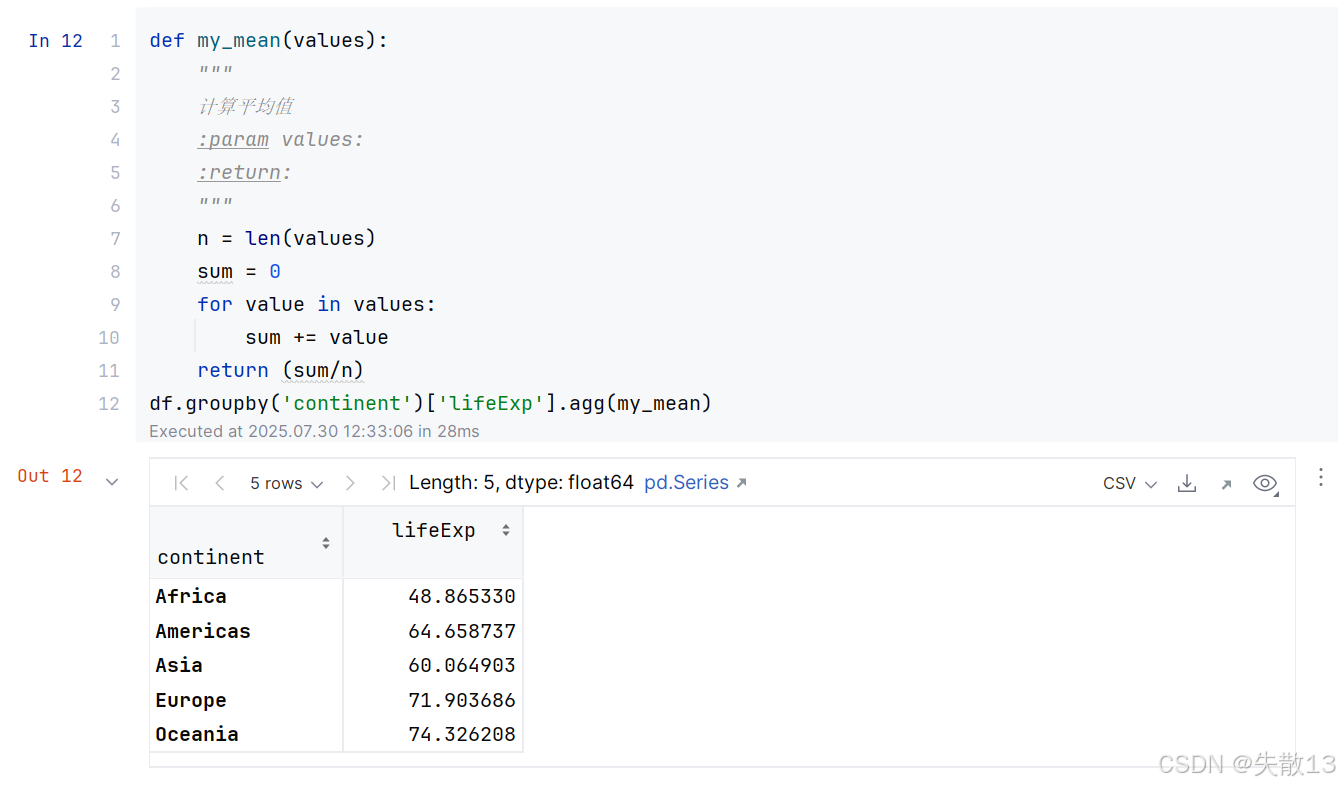
-
当然在自定义聚合函数中允许有多个参数,第一个参数用来接收DataFrame分组之后的值,其余参数可以自定义;
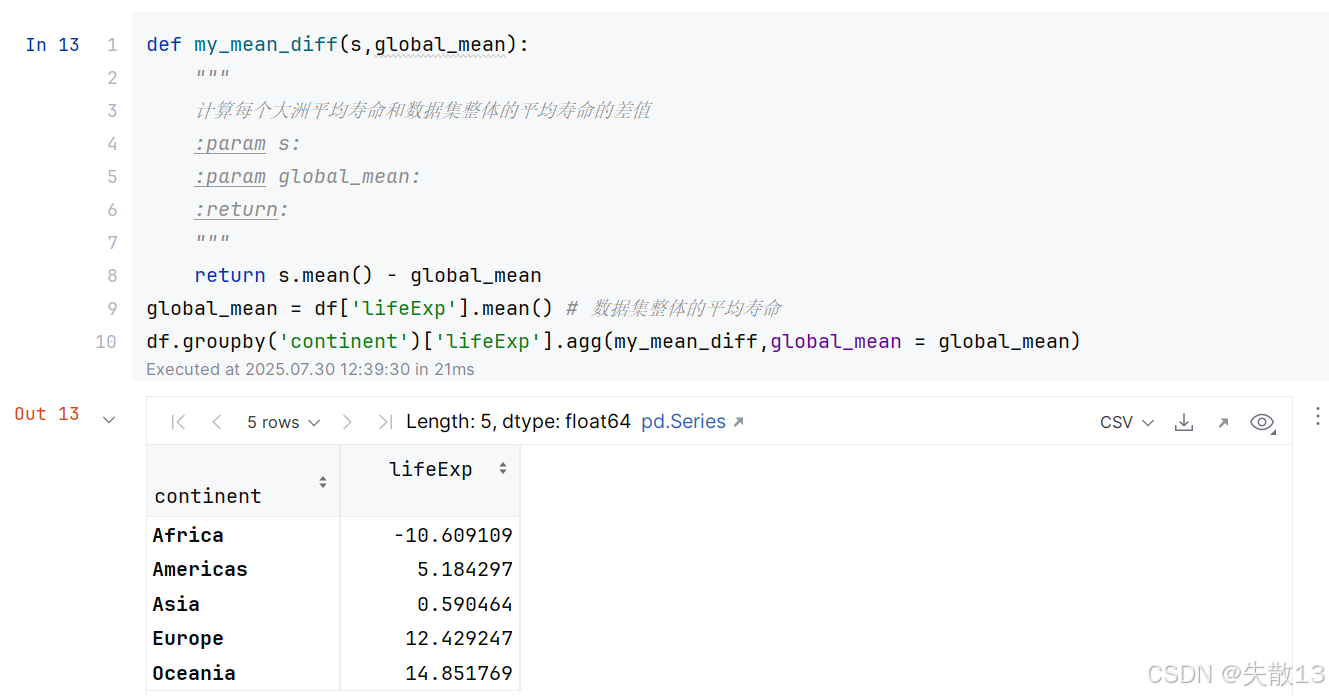
-
-
agg和aggregate效果一样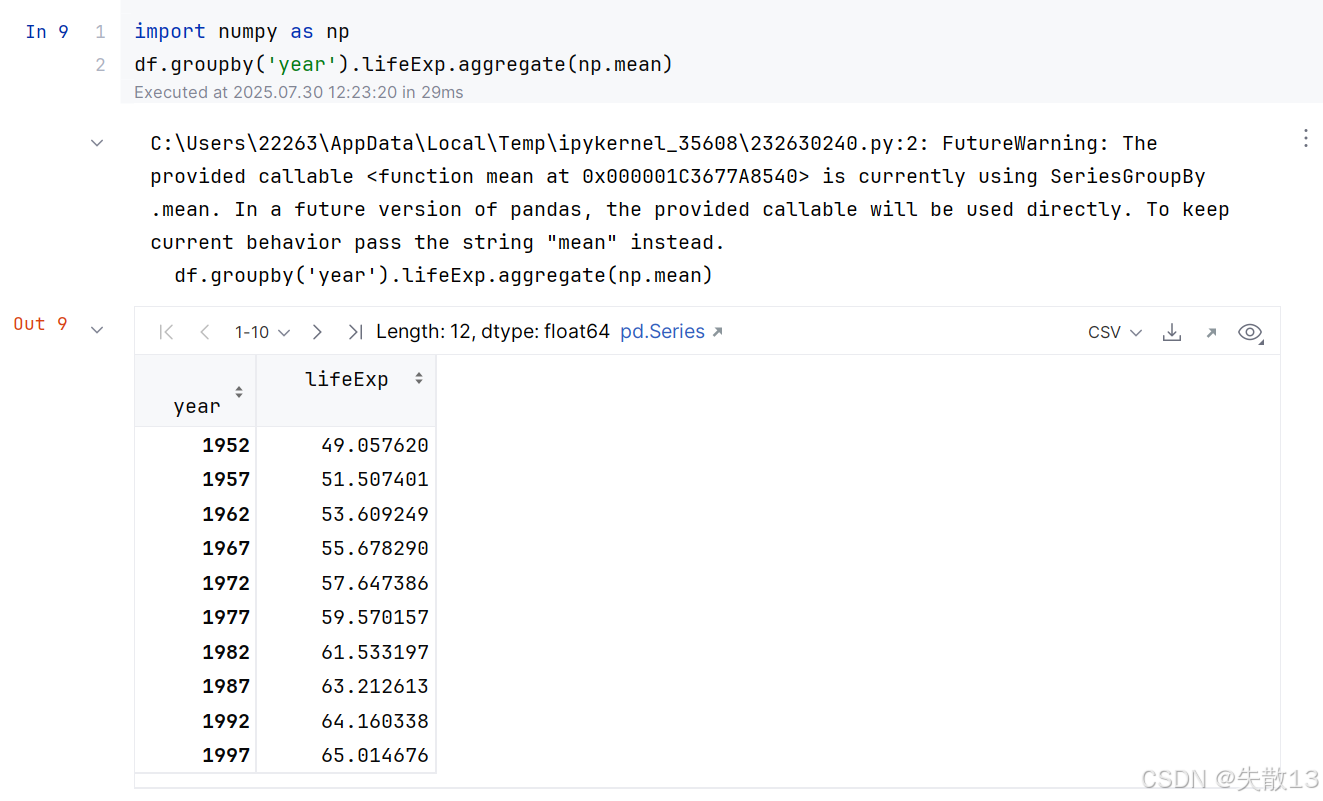
-
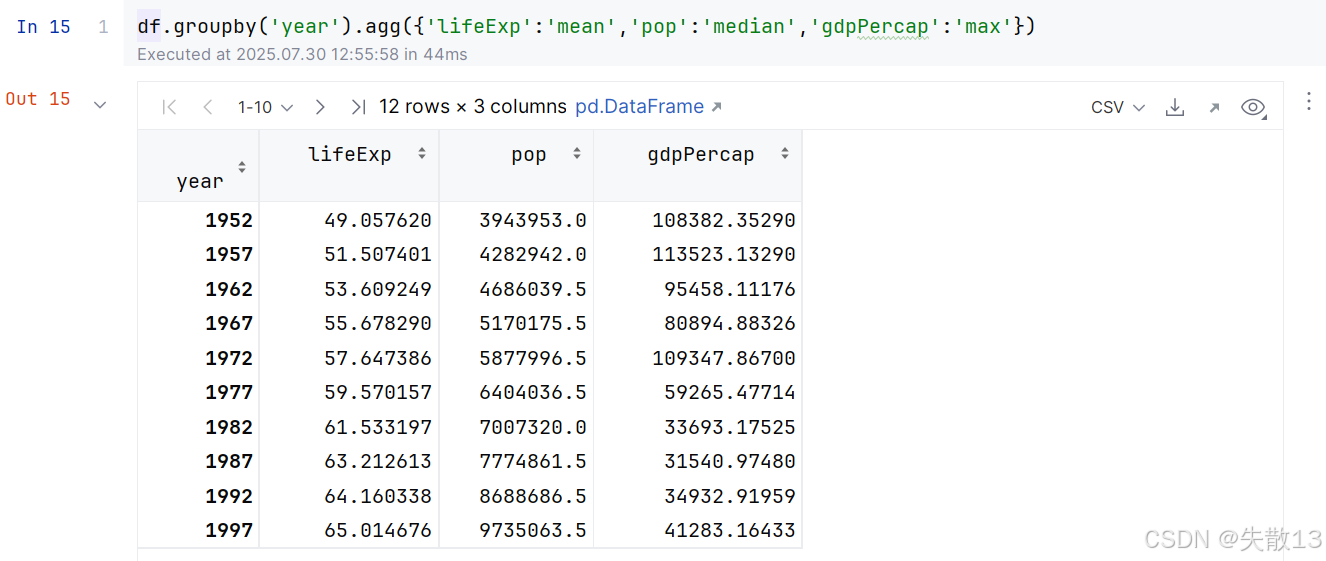
若想要对多个字段用不同的聚合方式,可以使用Python的字典数据类型,key是要聚合的字段,value是要使用的聚合方式;
1.3.3 同时使用多个聚合函数
-
若
groupby后面想接多个聚合函数,可以把这些聚合函数放入一个 Python 列表中,然后将这个列表传递给agg()函数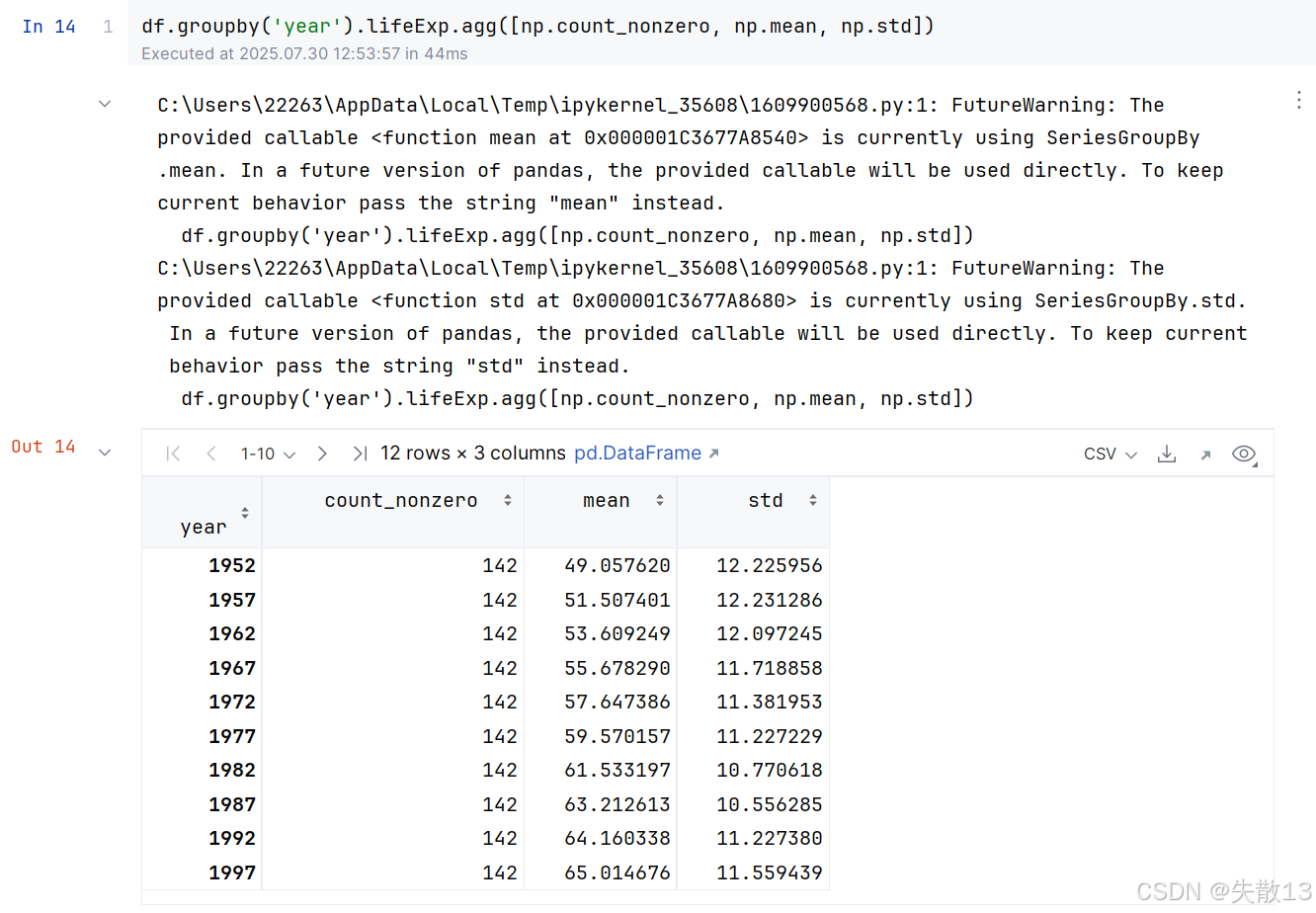
2 转换
2.1 简介
-
transform()函数- 功能:它会把 DataFrame 中的值传递给一个函数,然后由该函数对数据进行 “转换” 操作;
- 特点:转换后的数据与原始数据的形状(行数和列数等)相同,不会减少数据量。例如,对一个包含多组数据的列进行某种转换后,该列的行数和列数不会改变,只是每个数据的值按照函数规则发生了变化;
-
transform()VSaggregate()-
transform侧重于对数据进行转换,保持数据的原始结构和规模不变,不会减少数据量; -
aggregate侧重于对数据进行汇总,得到一个或少数几个关键的聚合结果,会减少数据量。
-
2.2 例:使用transform()计算z分数
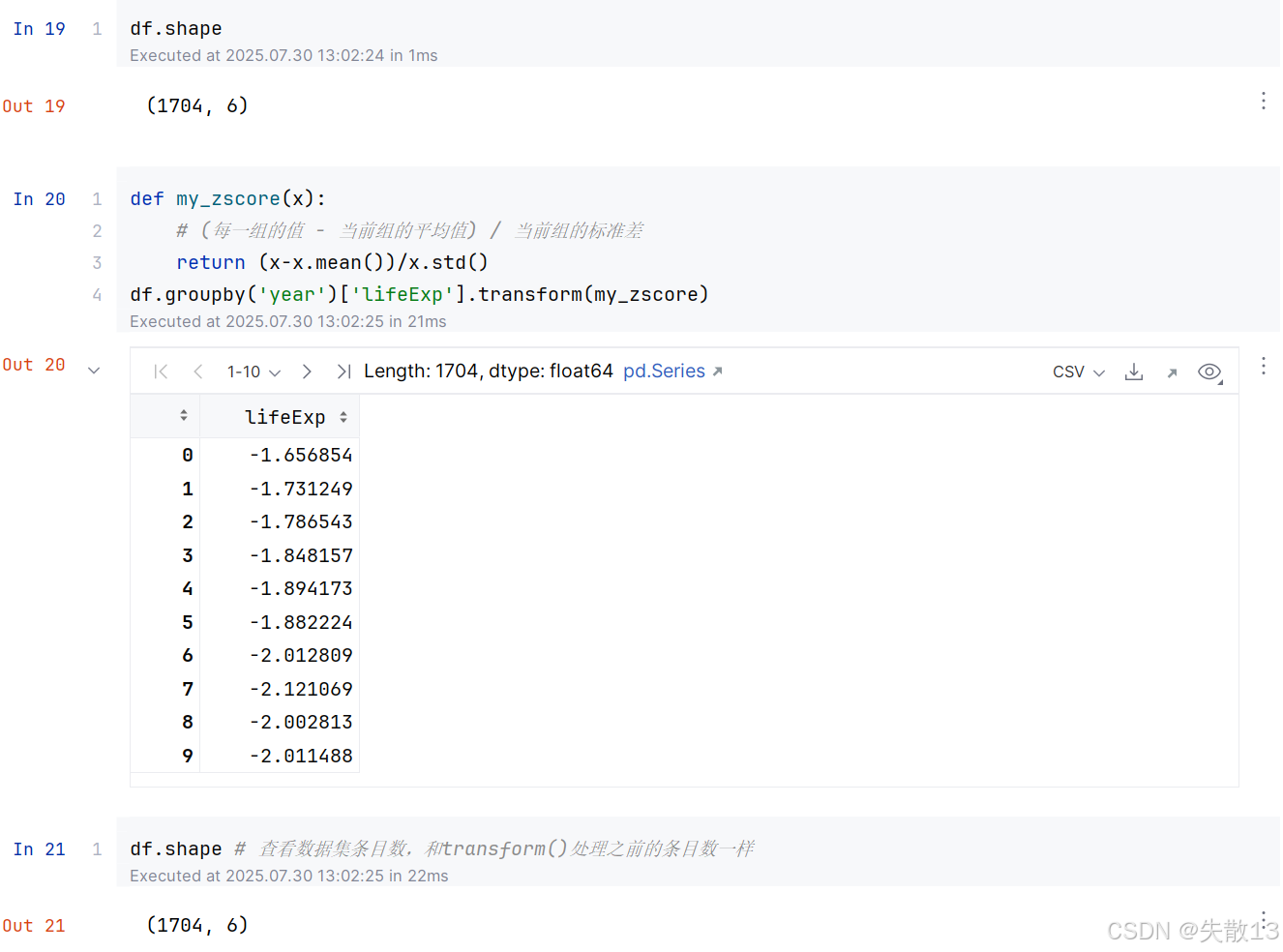
2.3 transform()填充缺失值
-
之前介绍了填充缺失值的各种方法,对于某些数据集,可以使用列的平均值来填充缺失值。某些情况下,可以考虑将列进行分组,分组之后取平均再填充缺失值;
-
加载数据:
-
构建缺失值
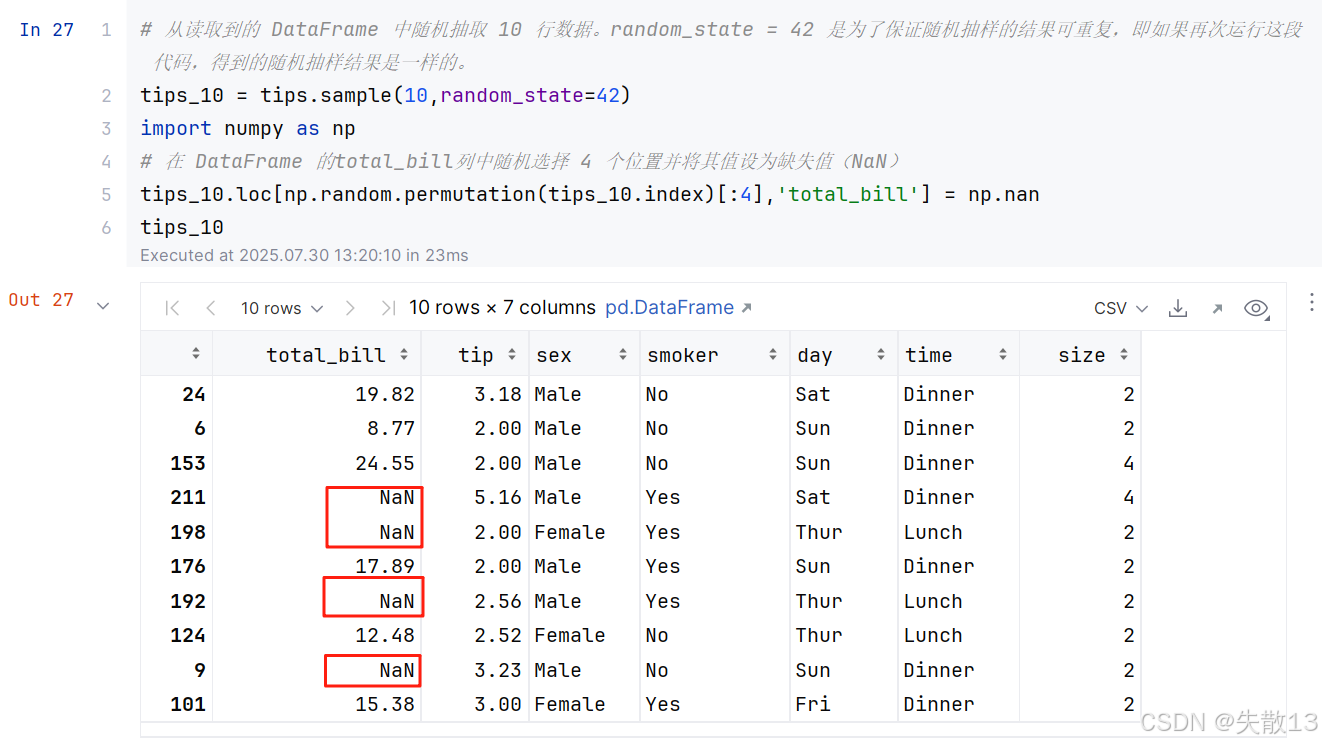
-
定义函数来填充缺失值
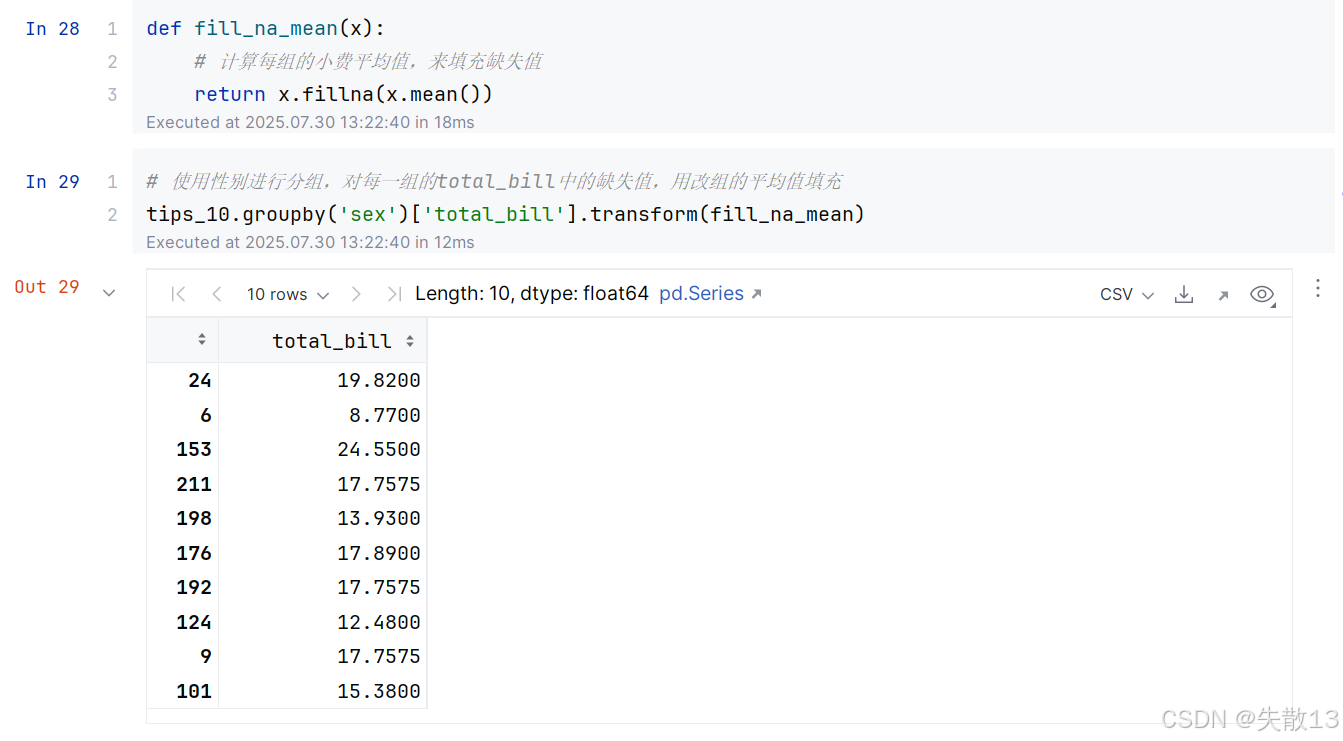
3 过滤
-
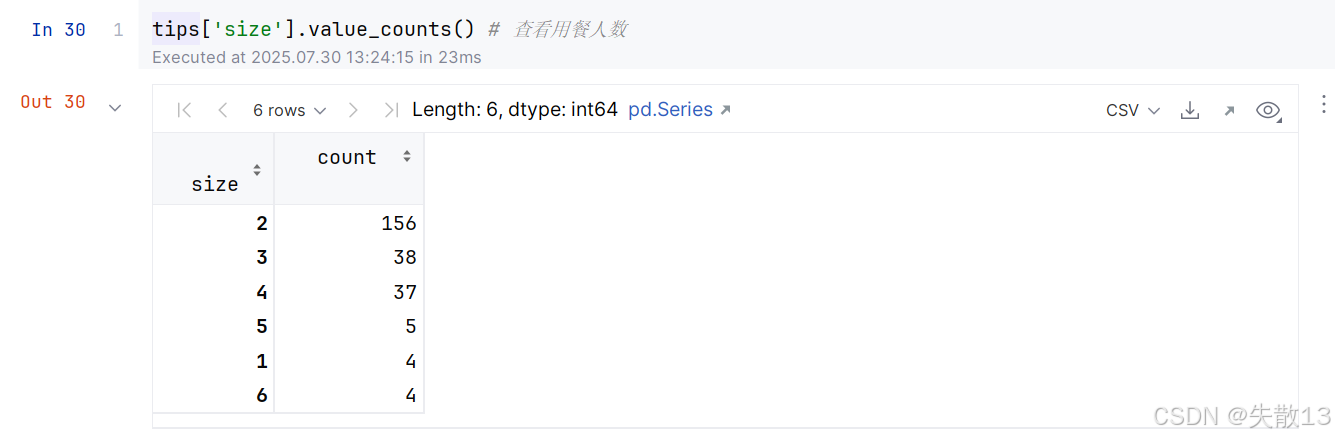
查看数据:
-
人数为1、5和6人的数据比较少,可以将这部分数据过滤掉。调用
filter()函数,传入一个返回布尔值的函数,返回False的数据会被过滤掉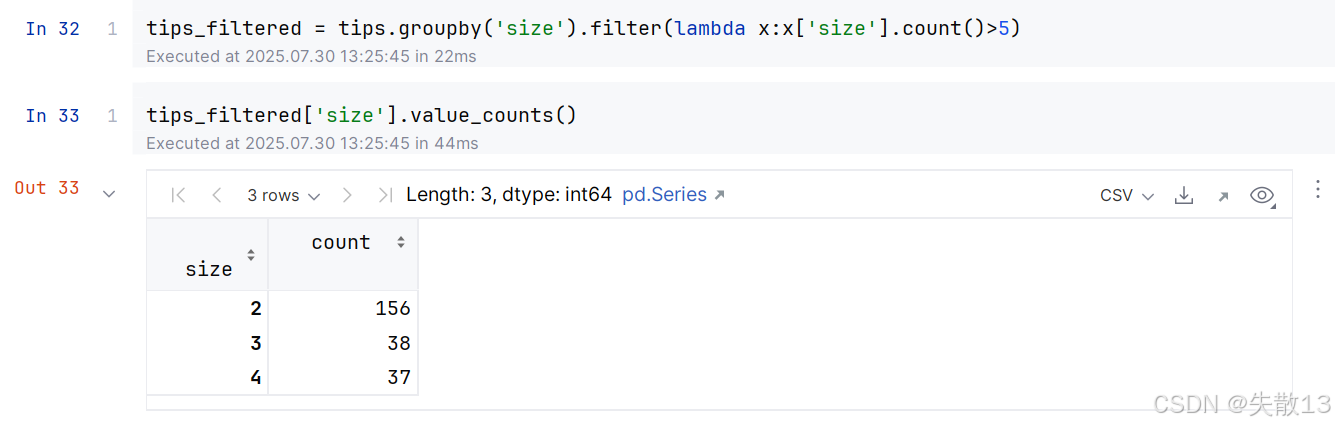
4 DataFrameGroupBy对象
4.1 分组
-
准备数据:
-
创建分组对象:

-
通过
groups属性查看计算过的分组
- 返回值是一个字典;
- 键(key):是分组的类别,也就是
sex列中的不同取值; - 值(value):是一个列表,包含了每个分组类别对应的行索引。例如,
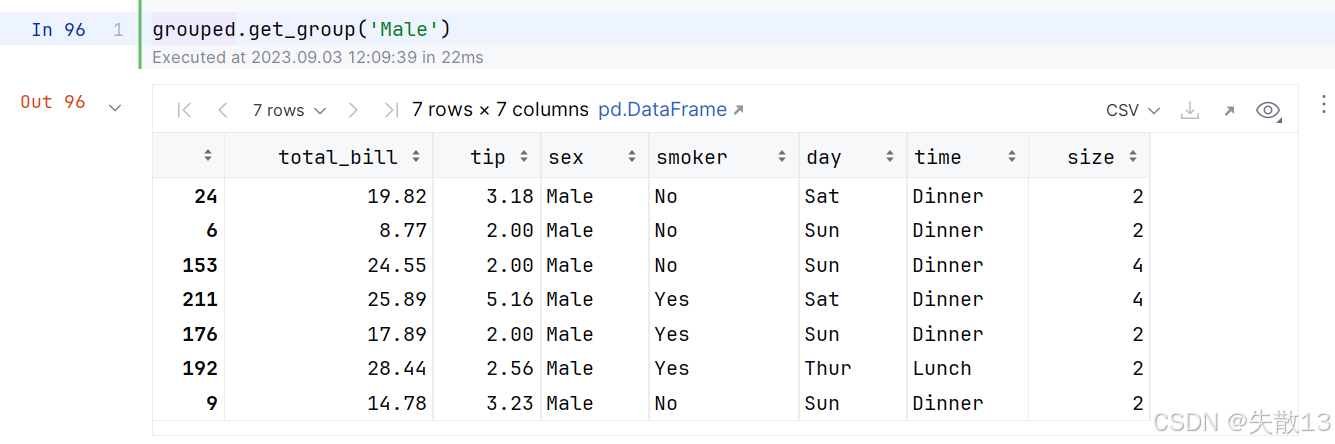
'Female'对应的行索引是[198, 124, 101],'Male'对应的行索引是[24, 6, 153, 211, 176, 192, 9];
-
分组后,就可以在分组的结果上进行
aggregate、transform计算了; -
可以从分组对象中获取指定分组:
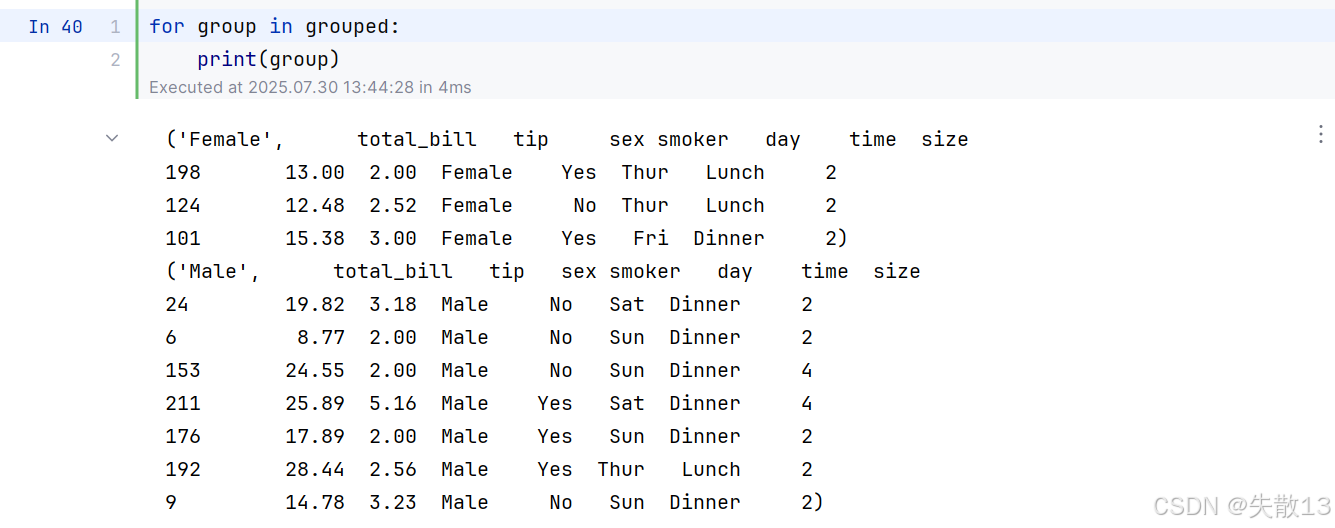
4.2 遍历分组
4.3 多个分组
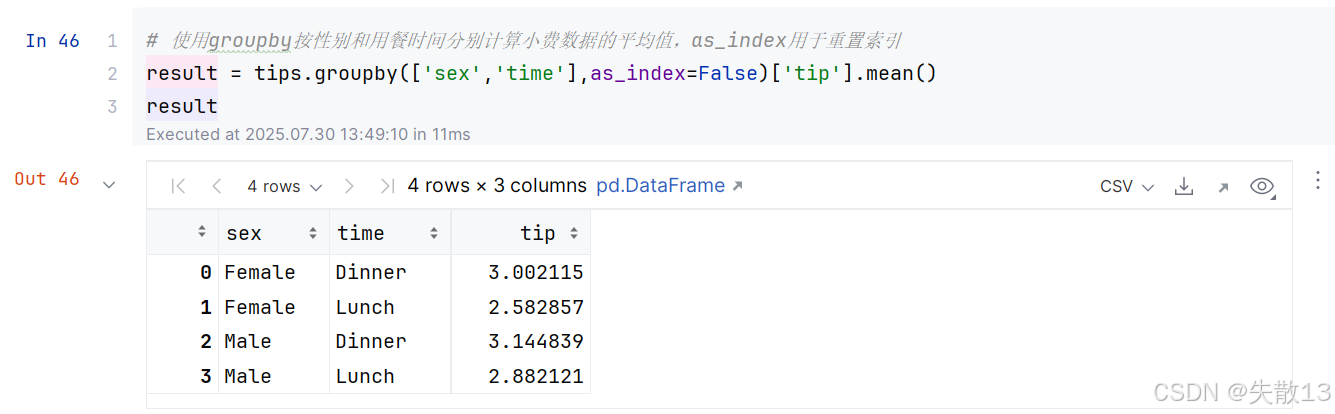
- 若不使用
as_index=False,可以使用result.reset_index()函数,都是重置索引。