李宏毅NLP-10-语音分离
Speech Separation

从混合音频中分离出目标说话者的语音,滤除其他声音干扰的能力。人类能在拥挤、嘈杂的环境中,专注于单个说话者的声音,这描述了 鸡尾酒会效应:即使周围有音乐、交谈、噪音等多种声音,人类仍能 “筛选” 出想听的语音(比如在派对上和朋友对话时,自动忽略背景噪音)。
机器如何模仿人类,从混合音频中分离目标语音?(比如解决会议录音中 “多说话者重叠” 的识别难题。)
Speech Enhancement
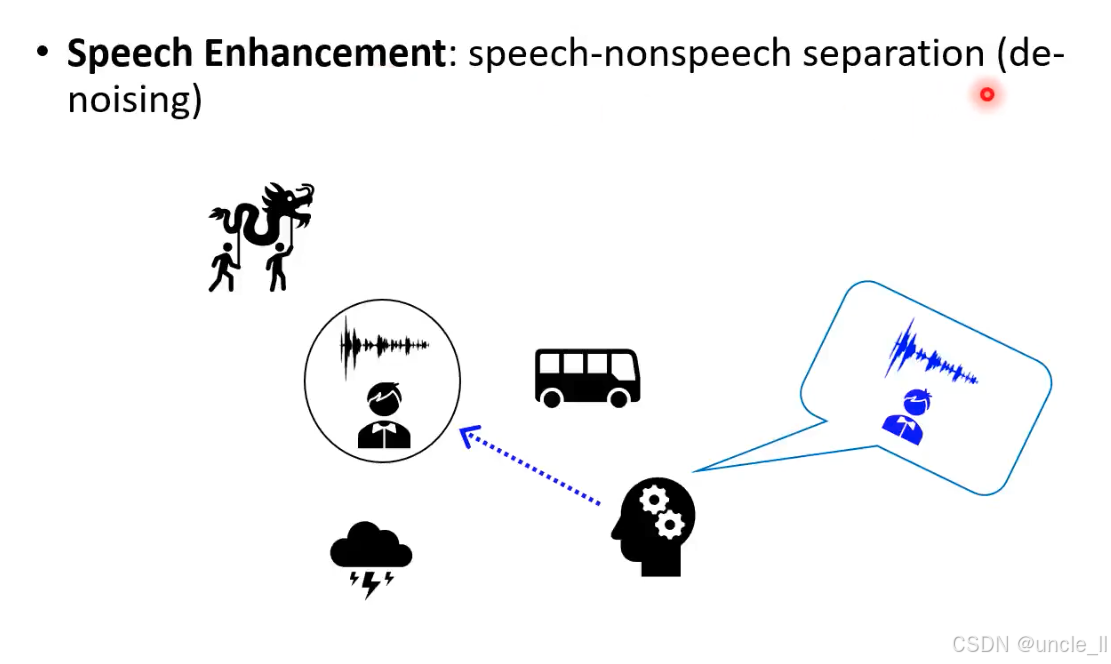
Speech Enhancement(语音增强)” 的核心任务 “语音 - 非语音分离(降噪) 。提升语音信号质量的技术,核心是 分离 “语音” 和 “非语音噪音”(de-noising,降噪)。让机器像人类大脑一样,从混合音频中 “提纯” 出可理解的语音,滤除环境噪音、干扰声等。
Speaker Separation
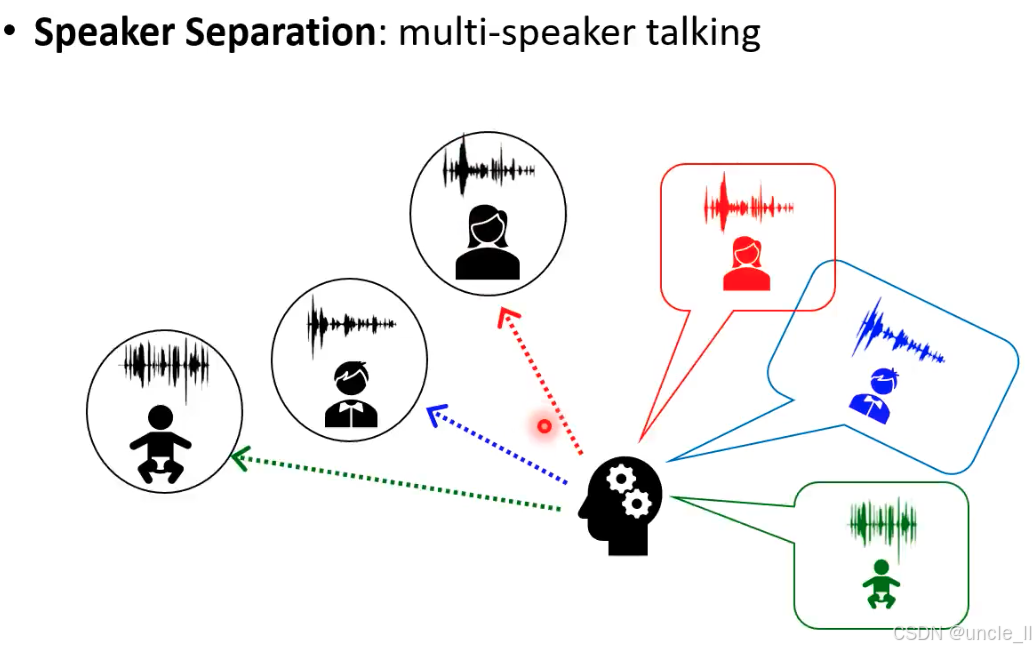
Speaker Separation(说话人分离):从多说话者同时发声的混合音频中,分离出每个说话人独立的语音信号。
场景:会议讨论(多人同时发言)、家庭对话(父母 + 孩子同时说话)、社交场合(多人交谈)等。
Speaker Separation
说话人分离(Speaker Separation)” 的核心任务设定,从输入输出特性、应用场景到技术约束,逐层解析如下:
- 核心流程:混合音频 → 分离单说话人音频
- 输入(Mixed audio):
红色 + 蓝色叠加的波形,代表 两个说话人同时发声的混合音频(时间上完全重叠)。 - 处理模块(Speaker Separation):
接收混合音频,输出 两个独立的说话人音频(红色和蓝色波形,分别对应两个说话人)。 - 输出特性:
Input and output have the same length(输入和输出长度相同),且Seq2seq is not needed(无需序列到序列模型)。- 原因:说话人分离是 “同长度信号转换”(时间维度不变,仅分离不同说话人的时频成分),而非 “长度可变的序列映射”(如语音识别将音频转文字,长度不同)。
- 任务约束(Bullet Points 解析)
图中列出三个关键设定,界定了该任务的研究范围:
(1)Focusing on Two speakers
- 含义:任务聚焦于 分离两个说话人 的场景(简化版问题,延伸可扩展到多说话人,但二分离是基础)。
- 价值:降低复杂度,便于模型学习 “如何区分两个不同说话人的时频特征”,是多说话人分离的基础。
(2)Focusing on Single microphone
- 含义:仅用 单个麦克风 采集混合音频,而非多麦克风阵列。
- 挑战:
多麦克风可利用空间信息(如说话人方位)辅助分离,而单麦克风只能从 时频特征、声纹差异 区分说话人,难度更高(更贴近真实场景:手机录音、会议单麦采集等)。
(3)Speaker independent: training and testing speakers are completely different
- 含义:训练集和测试集的说话人完全不同(模型从未见过测试集的说话人)。
- 目标:让模型学习 通用的 “说话人区分能力”,而非记忆特定说话人的声纹(泛化到 unseen speakers)。
- 对比:若训练和测试用同一批说话人,模型可能 “作弊”(记住声纹),而非真正学习分离逻辑。

说话人分离任务中 “训练数据的合成方法”,核心逻辑是 “通过人工叠加单说话人音频,低成本生成混合音频训练数据”
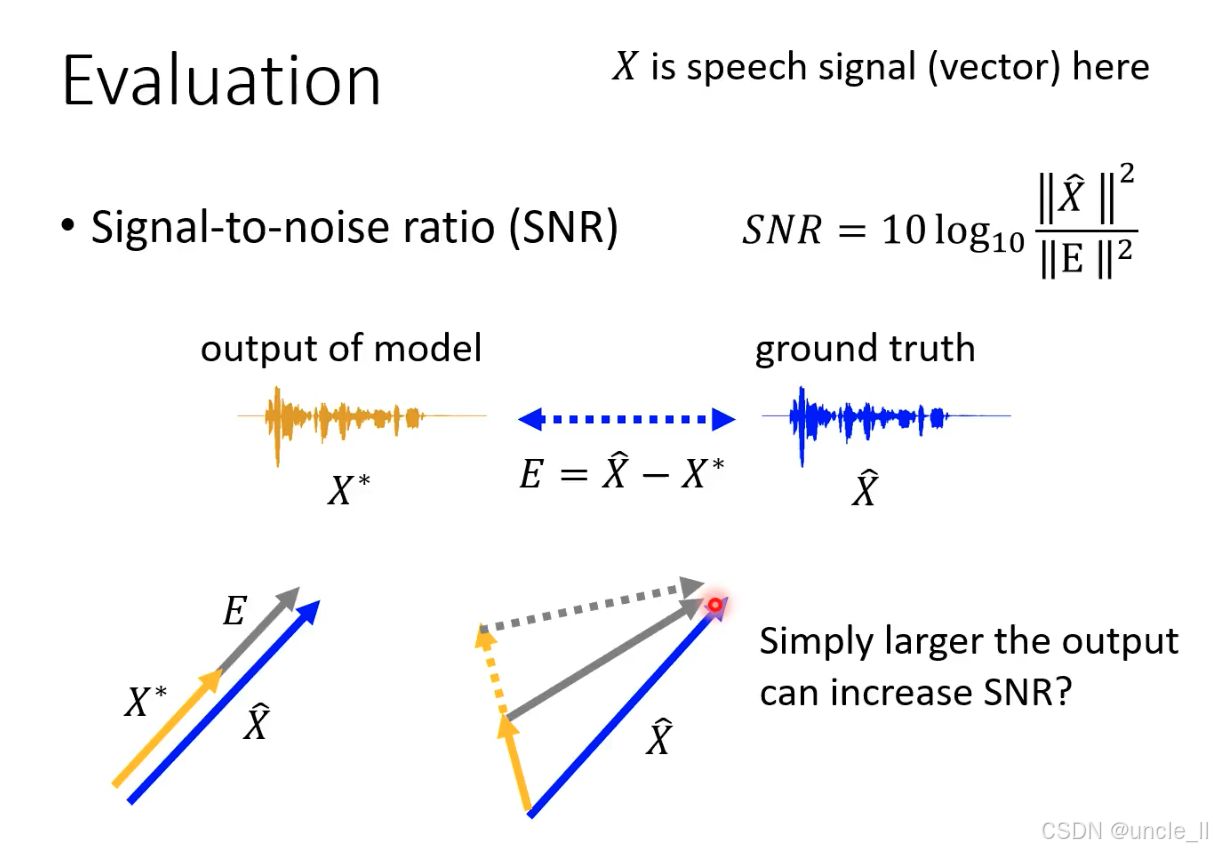
语音信号评估指标 —— 信噪比(SNR)
信号能量与误差能量的比值,单位为分贝(dB)。值越大,说明模型输出越接近真实信号(误差越小)。
SNR 的局限性:“幅度作弊” 问题
Simply larger the output can increase SNR? 揭示了 SNR 的核心缺陷:
“幅度放大” 的陷阱
假设模型故意放大输出信号XXX的幅度(如橙色向量变长,接近蓝色向量的幅度),会发生:
- 分子不变,分母分母变小。两者共同作用下,SNR 会升高—— 但这是 “虚假提升”:模型可能只是放大了输出的幅度,而信号的相位、细节并未匹配真实信号。
这种 “幅度作弊” 会导致:
- 听觉失真:模型输出幅度正确,但波形细节错误(如相位不对),人耳听感仍差。
- 下游任务失效:若用于语音识别(ASR),幅度正确但内容错误的信号会严重降低识别率。
所以SNR不是一个很好的评估方法。
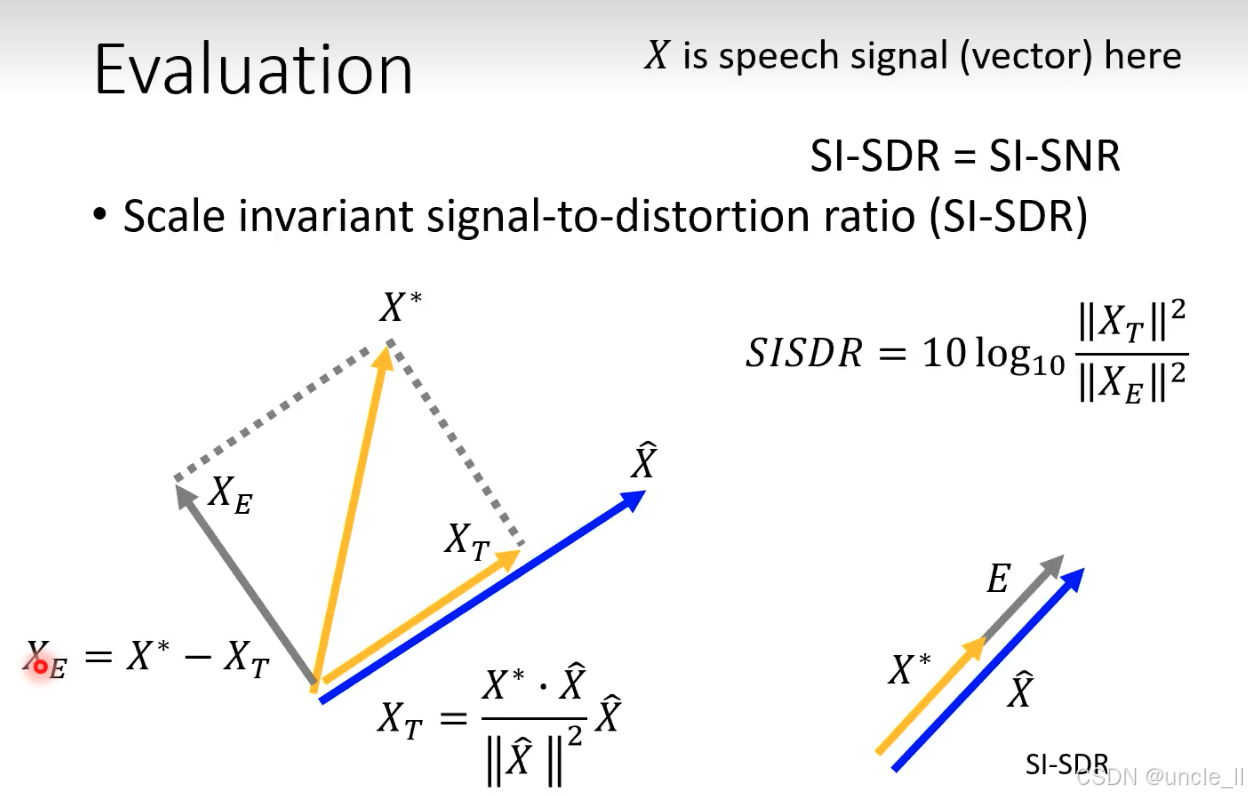
尺度不变信号失真比(SI-SDR,也称为 SI-SNR)
SI-SDR 通过 信号分解 + 投影,消除 “尺度缩放” 对评估的干扰,只关注信号的 结构一致性(如相位、波形形态)。将信号质量评估从 “能量对比” 升级为 “结构对比”,彻底解决了传统 SNR 的 “尺度作弊” 问题,更精准地衡量语音处理模型的实际效果。
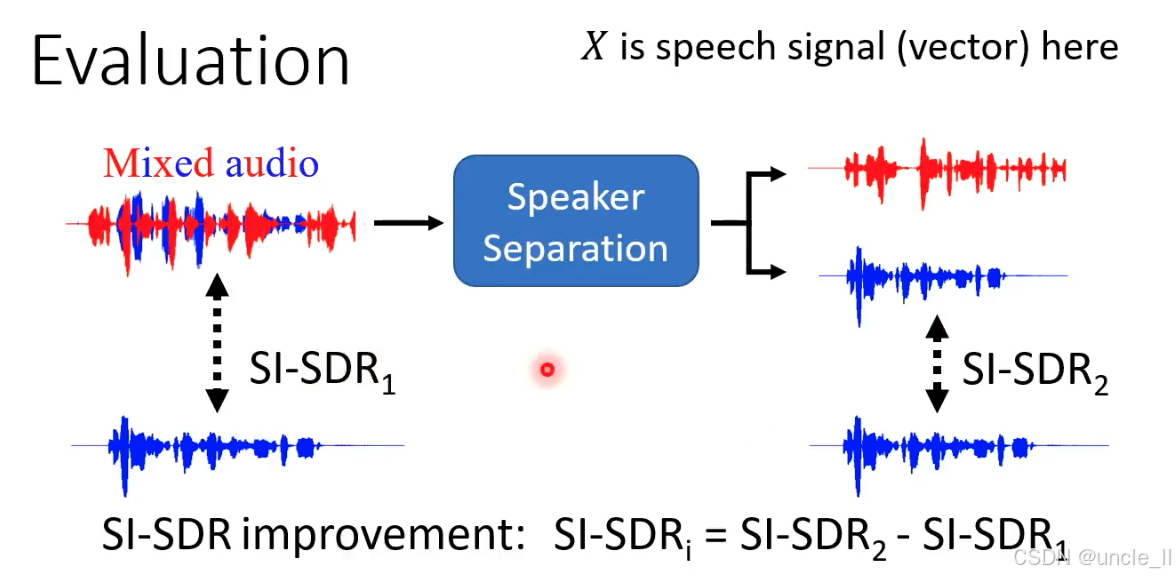
说话人分离系统的 SI-SDR 评估
SI-SDR₁:混合音频 vs 真实参考
- 混合音频(含干扰)与其中一个真实参考信号的 SI-SDR。
- 衡量 混合状态下目标语音的质量(因含干扰,结构一致性差,故
SI-SDR₁值低)。
SI-SDR₂:分离输出 vs 真实参考
- 分离模型输出的语音与对应真实参考信号的 SI-SDR。
- 衡量 分离后目标语音的质量(干扰减少,结构更接近真实信号,故
SI-SDR₂值高)。
核心指标:SI-SDR 提升量(SI-SDRᵢ)
SI−SDRi=SI−SDR2−SI−SDR1SI-SDR_i=SI-SDR_2 − SI-SDR_1SI−SDRi=SI−SDR2−SI−SDR1
模型分离后,目标语音相对于混合状态的质量提升幅度。另外还有其他的方法,比如感知语音质量评估(PESQ)和短时客观可懂度(STOI):
-
PESQ:评估语音信号的感知质量(即人耳主观感受到的清晰度、自然度)。
- 分数范围:−0.5(最差)到4.5(最优)。
- 典型参考:
- 4.0以上:接近无失真的高质量语音(如高清通话);
- 3.0~4.0:良好质量,轻微失真但不影响理解;
- 2.0~3.0:可接受质量,有明显失真但内容可懂;
- 低于2.0:质量较差,难以清晰理解。
- 典型参考:
- 技术特点:通过模拟人耳听觉系统,对比原始语音与处理后语音的差异,综合考虑响度、频率响应、时间波形失真等因素,结果与人类主观评分高度相关。
- 分数范围:−0.5(最差)到4.5(最优)。
-
STOI:评估语音信号的可懂度(即语音内容被正确理解的程度)。
- 分数范围:0(完全不可懂)到1(完全可懂)。
- 典型参考:
- 0.8以上:高可懂度,几乎所有内容可被理解;
- 0.5~0.8:中等可懂度,部分词汇可能混淆;
- 低于0.5:低可懂度,大部分内容无法识别。
- 典型参考:
- 技术特点:聚焦语音的短时频谱包络特征(与语义理解密切相关),通过计算原始语音与处理后语音在短时帧上的相关性来量化可懂度,对噪声、 reverberation(混响)等干扰的鲁棒性较强。
- 分数范围:0(完全不可懂)到1(完全可懂)。

说话人分离任务中的 “置换问题(Permutation Issue),即模型输出的分离语音可能与真实说话人标签错位的现象。输出标签与真实说话人无法稳定对应
- 场景:当输入混合音频包含多个说话人(如图中 “male + female” 的混合语音)时,模型输出的分离结果(X1X_1X1、X2X_2X2)可能出现标签置换—— 第一次分离时X1X_1X1对应女性、X2X_2X2对应男性,第二次分离时x1x_1x1却对应男性、X2X_2X2对应女性。
- 矛盾:模型训练需要稳定的 “输入 - 输出标签对应”,但置换问题导致输出标签随机切换,直接使用 L1/L2 损失函数会误导训练(模型可能因标签错位而学习错误映射)。
解决的方法有一些,先讲解deep cluster方法:
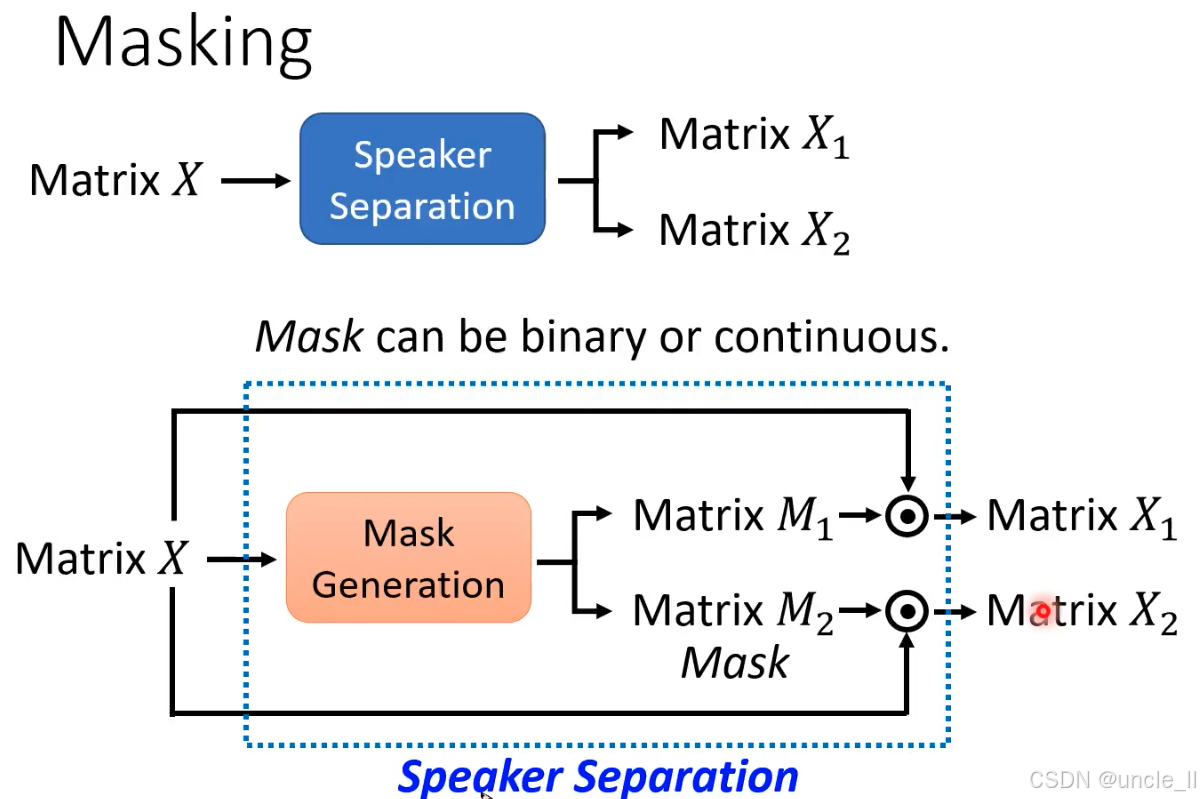
说话人分离(Speaker Separation)中基于 “掩码(Masking)” ,**通过生成掩码矩阵从混合音频中分离出不同说话人的语音。 **
- 整体流程:从混合音频矩阵到分离结果
- 输入:混合音频的时频矩阵 X(如通过 STFT 将音频转换为 “时间 - 频率” 二维矩阵,每个元素代表特定时刻和频率的能量)。
- 输出:两个分离后的说话人音频矩阵 X1 和 X2(对应不同说话人)。
- 核心逻辑:通过 “掩码生成” 模块创建掩码矩阵 M1 和 M2,分别与混合矩阵 X 相乘,过滤出目标说话人的能量成分,抑制其他说话人。
- 掩码生成(Mask Generation):分离的关键
- 掩码的作用:掩码矩阵M的每个元素取值范围通常为 0~1,用于 “保留” 或 “抑制” 混合矩阵中对应位置的能量:
- 若 Mt,f=1M_{t,f}=1Mt,f=1(接近 1):表示时频点 (t,f) 的能量属于目标说话人,应保留;
- 若 Mt,fM_{t,f}Mt,f=0(接近 0):表示该能量属于干扰说话人,应抑制。
- 掩码类型:
- 二值掩码(Binary Mask):元素非 0 即 1,强制划分每个时频点属于某一说话人(如理想二值掩码 IBM);
- 连续掩码(Continuous Mask):元素取值为 0~1 的连续值(如软掩码 Soft Mask),更灵活地表示归属概率(如 0.8 表示 80% 概率属于目标说话人)。
- 分离过程:掩码与混合矩阵的乘积
- 数学表达:分离出的说话人音频矩阵 X1=X⊙M1,X2=X⊙M2(⊙ 表示逐元素相乘):
- 混合矩阵 X 同时输入 “掩码生成” 模块;
- 模块输出两个掩码矩阵 M1 和 M2;
- 每个掩码与 X 相乘,得到仅包含对应说话人能量的矩阵 X1 和 X2;
- 最终通过逆 STFT 将 X1、X2 转换回时域音频波形。