从零开始构建AI Agent评估体系:12种LangSmith评估方法详解
AI Agent 的评估需要全面考虑其完整的生命周期,从开发阶段到生产部署。评估过程应当涵盖多个关键维度:最终输出的事实准确性和实用价值、推理过程中工具选择的合理性和路径效率、结构化响应生成能力(如 JSON 格式)、多轮对话的上下文维持能力,以及在真实用户流量下的持续性能表现和错误监控能力。
为了有效监控和评估 Agent 生命周期的各个组件,LangSmith 作为最具影响力和广泛应用的工具平台之一,提供了强大的评估框架。本文将深入探讨十二种不同的智能体评估技术,详细阐述每种技术的适用场景和实施方法。这些技术涵盖了从传统的预测答案与标准答案比较,到先进的实时反馈评估等多个层面,其中标准答案会随时间动态变化。
评估技术体系架构
基于标准答案的评估方法
这类方法包括环境配置、精确匹配评估、非结构化问答评估、结构化数据比较以及动态标准答案等技术。
程序性评估(过程分析)
此类别涵盖轨迹评估、工具选择精度分析、组件级 RAG 评估、基于 RAGAS 的 RAG 评估以及实时反馈机制。
观察性与自主评估
包括成对比较、基于仿真的评估、算法反馈以及技术总结等方法。
环境配置与初始化
评估工作的首要步骤是建立 LangSmith 环境。需要从官方仪表板获取 API 密钥,这是后续通过仪表板跟踪 Agent 进度的关键步骤。以下为 API 密钥的初始化配置:
import os from langchain_openai import ChatOpenAI import langsmith # 设置 LangSmith 端点(使用云版本时请勿修改) os.environ["LANGCHAIN_ENDPOINT"] = "https://api.smith.langchain.com" # 配置 LangSmith API 密钥 os.environ["LANGCHAIN_API_KEY"] = "YOUR_LANGSMITH_API_KEY" # 配置 OpenAI API 密钥 os.environ["OPENAI_API_KEY"] = "YOUR_OPENAI_API_KEY"
虽然本文使用 OpenAI 模型作为示例,但 LangChain 支持广泛的开源和闭源大语言模型。开发者可以根据需求切换到其他模型 API 提供商或本地部署的 Hugging Face 模型。
LangSmith API 端点负责在 Web 仪表板中存储所有评估指标,这将在后续分析中发挥重要作用。接下来需要初始化 LangSmith 客户端,作为整个评估流程的核心组件:
# 初始化 LangSmith 客户端 client = langsmith.Client()
1、精确匹配评估方法
精确匹配评估是最基础但至关重要的评估方法之一。该方法通过比较模型输出与预定义的正确答案来验证一致性。
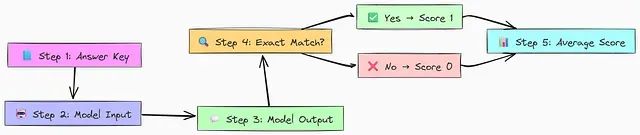
该评估流程的核心机制包括:建立标准答案作为预期响应的基准;向模型提供输入并获取基于该输入的输出;执行逐字符精确匹配检验,若匹配则赋值 1 分,不匹配则为 0 分;最后对所有样本的得分进行平均计算,得出模型的整体精确匹配性能指标。
为了在 LangSmith 中有效实施这种方法,首先需要构建评估数据集。在 LangSmith 框架中,数据集是由示例集合构成,每个示例包含输入和相应的预期输出(参考或标签)。这些数据集构成了模型测试和评估的基础架构。
以下示例创建了包含两个问题的数据集,并为每个问题提供了期望的精确输出:
# 创建数据集作为问答示例的容器 ds = client.create_dataset( dataset_name=dataset_name, description="A dataset for simple exact match questions." ) # 每个示例由输入字典和相应的输出字典组成# 输入和输出在独立列表中提供,维持相同的顺序 client.create_examples( # 输入列表,每个输入都是字典格式 inputs=[ { "prompt_template": "State the year of the declaration of independence. Respond with just the year in digits, nothing else" }, { "prompt_template": "What's the average speed of an unladen swallow?" }, ], # 对应的输出列表 outputs=[ {"output": "1776"}, # 第一个提示的预期输出 {"output": "5"} # 第二个提示的预期输出(陷阱问题) ], # 示例将被添加到的数据集 ID dataset_id=ds.id, )
数据准备完成后,需要定义评估组件。首要组件是待评估的模型或链。本示例中创建了
predict_result
函数,该函数接收提示,将其发送至 OpenAI 的
gpt-3.5-turbo
模型,并返回模型响应:
# 定义待测试模型 model = "gpt-3.5-turbo" # 被测试系统:接收输入字典,调用指定的 ChatOpenAI 模型,返回字典格式的输出 def predict_result(input_: dict) -> dict: # 输入字典包含 "prompt_template" 键,与数据集输入中定义的键一致 prompt = input_["prompt_template"] # 初始化并调用模型 response = ChatOpenAI(model=model, temperature=0).invoke(prompt) # 输出键 "output" 与数据集输出中的键匹配,用于比较 return {"output": response.content}
评估器是对系统性能进行评分的核心函数。LangSmith 提供多种内置评估器,同时支持自定义评估器的创建。内置的
exact_match
评估器是预构建的字符串评估器,用于检查预测与参考输出之间的完全字符匹配。自定义
compare_label
评估器则演示了如何实现自定义逻辑,通过
@run_evaluator
装饰器使 LangSmith 能够在评估过程中识别和使用该函数。
from langsmith.evaluation import EvaluationResult, run_evaluator # @run_evaluator 装饰器将函数注册为自定义评估器 @run_evaluator def compare_label(run, example) -> EvaluationResult: """用于检查精确匹配的自定义评估器Args: run: LangSmith 运行对象,包含模型输出 example: LangSmith 示例对象,包含参考数据 Returns: 包含键和分数的 EvaluationResult 对象 """ # 从运行输出字典获取模型预测# 键 'output' 必须与 `predict_result` 函数返回内容匹配 prediction = run.outputs.get("output") or "" # 从示例输出字典获取参考答案# 键 'output' 必须与数据集中定义内容匹配 target = example.outputs.get("output") or "" # 执行比较操作 match = prediction == target # 返回结果,键值为结果中分数的命名方式# 精确匹配分数通常为二进制(匹配为 1,不匹配为 0) return EvaluationResult(key="matches_label", score=int(match))
配置完成所有组件后,可以执行评估。
RunEvalConfig
用于配置评估测试套件,指定内置的
"exact_match"
评估器和自定义的
compare_label
评估器,确保每个模型运行都被两个评估器评分。
client.run_on_dataset
作为主要协调函数,遍历指定数据集中的每个示例,对输入运行
predict_result
函数,然后应用
RunEvalConfig
中的评估器对结果进行评分。
from langchain.smith import RunEvalConfig # 定义评估运行的配置 eval_config = RunEvalConfig( # 通过字符串名称指定内置评估器 evaluators=["exact_match"], # 在列表中直接传递自定义评估器函数 custom_evaluators=[compare_label], ) # 触发评估执行# 对数据集中每个示例运行 `predict_result` 函数# 然后使用 `eval_config` 中的评估器对结果评分 client.run_on_dataset( dataset_name=dataset_name, llm_or_chain_factory=predict_result, evaluation=eval_config, verbose=True, # 打印进度条和链接 project_metadata={"version": "1.0.1", "model": model}, # 项目可选元数据 )
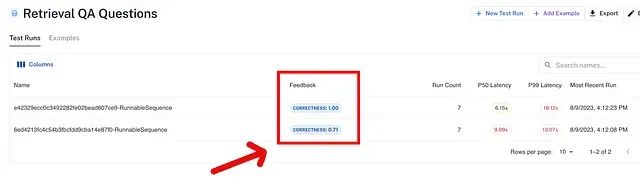
评估执行将在样本数据上启动基于精确匹配方法的评估并显示进度:
View the evaluation results for project 'gregarious-doctor-77' at: https://smith.langchain.com/o/your-org-id/datasets/some-dataset-uuid/compare?selectedSessions=some-session-uuid View all tests for Dataset Oracle of Exactness at: https://smith.langchain.com/o/your-org-id/datasets/some-dataset-uuid [------------------------------------------------->] 2/2
结果展示了多种统计信息,包括评估数据中实体数量的
count
、正确预测实体比例的
mean
(0.5 表示一半实体被正确识别),以及其他统计信息。
LangSmith 精确匹配评估主要适用于需要确定性输出的 RAG 或 AI Agent 任务场景。基于事实的问答需要从上下文中获取单一正确事实答案;封闭式问题需要精确的是非判断或选择匹配;工具使用输出需要验证精确的工具调用结果;结构化输出需要检查精确的格式和键值对。
2、非结构化问答评估
由于大语言模型响应为非结构化文本,简单的字符串匹配往往无法满足评估需求。模型可以用多种不同表述方式提供事实正确的答案。为解决这一挑战,可以采用 LLM 辅助评估器来评估系统响应的语义和事实准确性。
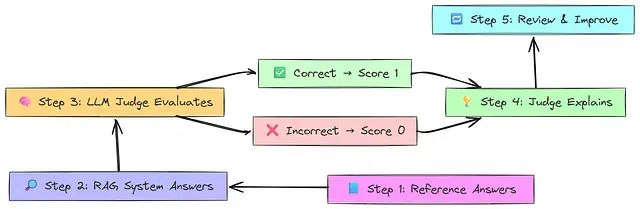
该评估流程始于创建包含问题和参考答案(黄金标准)的数据集。基于 RAG 的问答系统随后使用检索到的文档回答每个问题。独立的 LLM(充当"评判者")将预测答案与参考答案进行比较。若答案在事实上正确,评判者给予 1 分;若答案错误或存在幻觉,则给予 0 分。评判者提供推理过程来解释评分依据。最终,开发者可以审查错误案例,改进系统并重新执行评估。
相比精确匹配方法,非结构化场景的关键区别在于"标准答案"现在是正确性的参考基准,而非精确匹配的模板。
# 在 LangSmith 中创建数据集 dataset = client.create_dataset( dataset_name=dataset_name, description="Q&A dataset about LangSmith documentation." ) # 问答示例,答案作为'标准答案' qa_examples = [ ( "What is LangChain?", "LangChain is an open-source framework for building applications using large language models. It is also the name of the company building LangSmith.", ), ( "How might I query for all runs in a project?", "You can use client.list_runs(project_name='my-project-name') in Python, or client.ListRuns({projectName: 'my-project-name'}) in TypeScript.", ), ( "What's a langsmith dataset?", "A LangSmith dataset is a collection of examples. Each example contains inputs and optional expected outputs or references for that data point.", ), ( "How do I move my project between organizations?", "LangSmith doesn't directly support moving projects between organizations.", ), ] # 将示例添加到数据集# 输入键为 'question',输出键为 'answer'# 这些键必须与 RAG 链期望和生成的内容匹配 for question, answer in qa_examples: client.create_example( inputs={"question": question}, outputs={"answer": answer}, dataset_id=dataset.id, )
接下来构建使用 LangChain 和 LangSmith 文档的 RAG 管道问答系统。该系统包含四个主要步骤:加载文档(抓取 LangSmith 文档);创建检索器(嵌入文档并存储在 ChromaDB 中以查找相关片段);生成答案(使用 ChatOpenAI 和提示基于检索内容回答);组装链(使用 LangChain 表达语言将所有组件合并为单一管道)。
首先加载和处理文档以创建知识库:
from langchain_community.document_loaders import RecursiveUrlLoader from langchain_community.document_transformers import Html2TextTransformer from langchain_community.vectorstores import Chroma from langchain_text_splitters import TokenTextSplitter from langchain_openai import OpenAIEmbeddings # 1. 从网络加载文档 api_loader = RecursiveUrlLoader("https://docs.smith.langchain.com") raw_documents = api_loader.load() # 2. 将 HTML 转换为干净文本并分割为可管理的片段 doc_transformer = Html2TextTransformer() transformed = doc_transformer.transform_documents(raw_documents) text_splitter = TokenTextSplitter(model_name="gpt-3.5-turbo", chunk_size=2000, chunk_overlap=200) documents = text_splitter.split_documents(transformed) # 3. 创建向量存储检索器 embeddings = OpenAIEmbeddings() vectorstore = Chroma.from_documents(documents, embeddings) retriever = vectorstore.as_retriever(search_kwargs={"k": 4})
随后定义链的生成部分并组装完整的 RAG 管道:
from operator import itemgetter from langchain_core.output_parsers import StrOutputParser from langchain_core.prompts import ChatPromptTemplate # 定义发送给 LLM 的提示模板 prompt = ChatPromptTemplate.from_messages( [ ( "system", "You are a helpful documentation Q&A assistant, trained to answer" " questions from LangSmith's documentation." " LangChain is a framework for building applications using large language models." "\nThe current time is {time}.\n\nRelevant documents will be retrieved in the following messages.", ), ("system", "{context}"), # 检索文档的占位符 ("human", "{question}"), # 用户问题的占位符 ] ).partial(time=str(datetime.now())) # 初始化 LLM,使用大上下文窗口和低温度参数以获得更准确的响应 model = ChatOpenAI(model="gpt-3.5-turbo-16k", temperature=0) # 定义生成链,将提示传递给模型再传递给输出解析器 response_generator = prompt | model | StrOutputParser()
准备好数据集和 RAG 链后,可以执行评估。此次使用内置的"qa"评估器替代"exact_match"。该评估器使用 LLM 根据数据集中的参考答案对生成答案的正确性进行评分:
# 配置评估使用"qa"评估器,基于参考答案对"正确性"进行评分 eval_config = RunEvalConfig( evaluators=["qa"], ) # 在数据集上运行 RAG 链并应用评估器 client.run_on_dataset( dataset_name=dataset_name, llm_or_chain_factory=rag_chain, evaluation=eval_config, verbose=True, project_metadata={"version": "1.0.0", "model": "gpt-3.5-turbo"}, )
评估执行将触发测试运行,输出中的链接可用于在 LangSmith 仪表板中实时查看结果:
View the evaluation results for project 'witty-scythe-29' at: https://smith.langchain.com/o/your-org-id/datasets/some-dataset-uuid/compare?selectedSessions=some-session-uuid View all tests for Dataset Retrieval QA - LangSmith Docs at: https://smith.langchain.com/o/your-org-id/datasets/some-dataset-uuid [------------------------------------------------->] 5/5
运行完成后,LangSmith 仪表板提供结果分析界面。除了聚合分数外,更重要的是可以筛选失败案例进行调试。
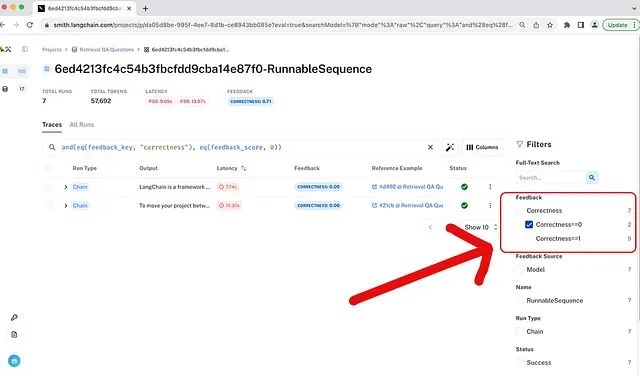
通过筛选正确性分数为 0 的示例,可以隔离问题案例。例如,发现模型因检索到不相关文档而产生幻觉答案的情况。可以形成假设:“如果信息不在上下文中,模型需要明确被告知不要回答”。通过修改提示并重新运行评估来测试这一假设:
# 定义改进的提示模板 prompt_v2 = ChatPromptTemplate.from_messages( [ ( "system", "You are a helpful documentation Q&A assistant, trained to answer" " questions from LangSmith's documentation." "\nThe current time is {time}.\n\nRelevant documents will be retrieved in the following messages.", ), ("system", "{context}"), ("human", "{question}"), # 新增防止幻觉的指令 ( "system", "Respond as best as you can. If no documents are retrieved or if you do not see an answer in the retrieved documents," " admit you do not know or that you don't see it being supported at the moment.", ), ] ).partial(time=lambda: str(datetime.now()))
仪表板显示的结果表明新链性能更优,通过了测试集中的所有示例。这种"测试-分析-改进"的迭代循环是改进大语言模型应用的强大方法论。
非结构化文本的 LLM 辅助评估对于生成输出具有细微差别且需要语义理解的任务至关重要。RAG 系统需要验证模型答案在事实上由检索上下文支持并避免幻觉;开放式问答在没有单一"精确"正确答案时评估正确性,允许措辞和风格变化;摘要任务需要检查生成摘要是否忠实于源文档并准确捕获要点;对话式 AI 和聊天机器人需要评估机器人在对话中逐轮响应的相关性、实用性和事实准确性。
3、结构化数据比较评估
大语言模型的一个重要且强大的应用场景是从非结构化文本(文档、邮件或合同)中提取结构化数据(如 JSON)。这种能力使我们能够填充数据库、使用正确参数调用工具或自动构建知识图谱。然而,评估这种提取质量存在挑战。对输出 JSON 进行简单精确匹配过于严格;模型可能产生完全有效且正确的 JSON,但如果键的顺序不同或存在细微空白变化,则无法通过字符串比较测试。因此需要更智能的方法来比较结构和内容。
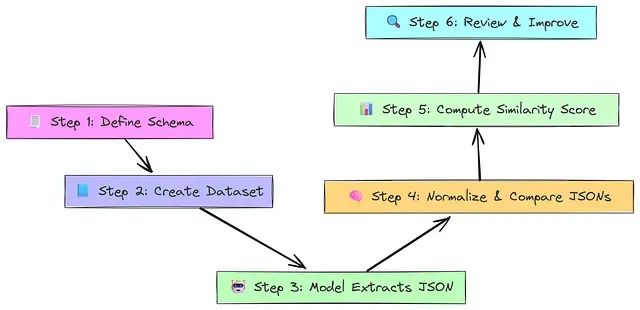
该评估流程始于定义结构化模式(如 JSON 或 Pydantic 模型)作为模型必须填写的"表单"。随后构建包含非结构化输入和完美填写的 JSON 输出作为答案键的数据集。模型读取输入并填写表单,基于模式产生结构化输出。JSON 编辑距离评估器将预测的 JSON 与参考进行比较,规范化两个 JSON(如键顺序)并计算编辑距离(Levenshtein 距离)。基于预测与答案键的接近程度分配相似性分数(0.0-1.0)。最后,审查低分输出以找到薄弱环节并改进模型或提示。
本节将评估一个从法律合同中提取关键详细信息的链。首先克隆公共数据集到 LangSmith 账户中进行评估:
# LangSmith 上公共数据集的 URL dataset_url = "https://smith.langchain.com/public/08ab7912-006e-4c00-a973-0f833e74907b/d" dataset_name = "Contract Extraction Eval Dataset" # 将公共数据集克隆到账户中 client.clone_public_dataset(dataset_url, dataset_name=dataset_name)
为了指导 LLM 生成正确的结构化输出,需要使用 Pydantic 模型定义目标数据结构。该模式充当待提取信息的:
from typing import List, Optional from pydantic import BaseModel # 定义当事方地址的模式 class Address(BaseModel): street: str city: str state: str # 定义合同中当事方的模式 class Party(BaseModel): name: str address: Address # 整个合同的顶级模式 class Contract(BaseModel): document_title: str effective_date: str parties: List[Party]
接下来构建提取链。使用专门为此任务设计的
create_extraction_chain
,它接受 Pydantic 模式和能力强的 LLM(如 Anthropic 的 Claude 或具有函数调用功能的 OpenAI 模型)来执行提取:
from langchain.chains import create_extraction_chain from langchain_anthropic import ChatAnthropic # 使用能够遵循复杂指令的强大模型# 注:可以替换为等效的 OpenAI 模型 llm = ChatAnthropic(model="claude-2.1", temperature=0, max_tokens=4000) # 创建提取链,提供模式和 LLM extraction_chain = create_extraction_chain(Contract.schema(), llm)
现在配置为接受文本并返回包含提取 JSON 的字典。
对于评估器,使用
json_edit_distance
字符串评估器。这是理想的工具,因为它计算预测和参考 JSON 对象之间的相似性,忽略键顺序等表面差异。将此评估器包装在
RunEvalConfig
中,并使用
client.run_on_dataset
执行测试运行:
from langsmith.evaluation import LangChainStringEvaluator # 评估配置指定 JSON 感知评估器# 'json_edit_distance' 评估器比较两个 JSON 对象的结构和内容 eval_config = RunEvalConfig( evaluators=[ LangChainStringEvaluator("json_edit_distance") ] ) # 运行评估 client.run_on_dataset( dataset_name=dataset_name, llm_or_chain_factory=extraction_chain, evaluation=eval_config, # 数据集中的输入键为'context',映射到链的'input'键 input_mapper=lambda x: {"input": x["context"]}, # 链的输出为字典 {'text': [...]},关注'text'值 output_mapper=lambda x: x['text'], verbose=True, project_metadata={"version": "1.0.0", "model": "claude-2.1"}, )
这启动了评估过程。LangSmith 将在数据集中的每个合同上运行提取链,评估器将为每个结果评分。输出中的链接直接导向项目仪表板以监控结果。
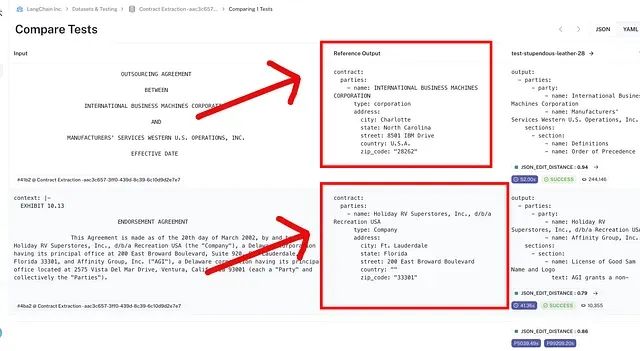
评估完成后,前往 LangSmith 审查预测结果。关键问题包括:模型在哪些方面表现不佳?是否注意到幻觉输出?对数据集有什么改进建议?
结构化数据提取评估对于任何需要从非结构化文本获得精确、机器可读输出的任务都是必不可少的。函数调用和工具使用需要验证 LLM 正确地从用户查询中提取参数以调用 API;知识图谱填充需要从新闻文章或报告中提取实体及其关系以构建图谱;数据录入自动化需要解析发票、收据或申请表格信息以填充数据库,减少手动工作;API 响应解析需要将原始、非结构化的 API 响应转换为干净、可预测的 JSON 对象供下游使用。
4、动态标准答案评估
在现实环境中,数据很少是静态的。如果 AI Agent 基于实时数据库、库存系统或持续更新的 API 回答问题,如何创建可靠的测试集?在数据集中硬编码"正确"答案是无效的策略,因为一旦底层数据发生变化,这些答案就会过时。
为解决这一问题,采用经典编程原理:间接引用。不将静态答案存储为标准答案,而是存储可在评估时执行的引用或查询,以获取实时的正确答案。
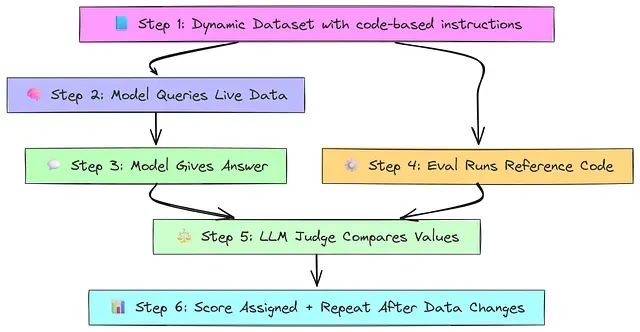
该方法首先创建包含问题和动态引用指令(如 Python 代码)而非静态答案的数据集。问答 Agent 读取问题并查询实时数据源(如 Pandas DataFrame)。模型基于数据当前状态给出预测答案。自定义评估器对实时数据运行引用指令以即时计算真实答案。LLM 评判者将模型预测与动态标准答案进行比较并分配分数。当数据后续发生变化时,可以使用更新的值重新运行相同测试,仍能基于当前数据进行公平判断。
以著名的泰坦尼克号数据集构建问答系统为例。不存储如"891 名乘客"这样的答案,而是存储计算答案的 pandas 代码片段:
# 问题列表和相应的 pandas 代码以找到答案 questions_with_references = [ ("How many passengers were on the Titanic?", "len(df)"), ("How many passengers survived?", "df['Survived'].sum()"), ("What was the average age of the passengers?", "df['Age'].mean()"), ("How many male and female passengers were there?", "df['Sex'].value_counts()"), ("What was the average fare paid for the tickets?", "df['Fare'].mean()"), ] # 创建唯一数据集名称 dataset_name = "Dynamic Titanic QA" # 在 LangSmith 中创建数据集 dataset = client.create_dataset( dataset_name=dataset_name, description="QA over the Titanic dataset with dynamic references.", ) # 填充数据集,输入为问题,输出为代码 client.create_examples( inputs=[{"question": q} for q, r in questions_with_references], outputs=[{"reference_code": r} for q, r in questions_with_references], dataset_id=dataset.id, )
被测试系统将是
pandas_dataframe_agent
,设计用于通过在 pandas DataFrame 上生成和执行代码来回答问题。首先加载初始数据:
import pandas as pd # 从 URL 加载泰坦尼克号数据集 titanic_url = "https://raw.githubusercontent.com/jorisvandenbossche/pandas-tutorial/master/data/titanic.csv" df = pd.read_csv(titanic_url)
此 DataFrame 代表实时数据源。
接下来定义创建和运行 Agent 的函数。该 Agent 在被调用时将访问当前的 df:
# 为 Agent 定义 LLM llm = ChatOpenAI(model="gpt-4", temperature=0) # 此函数在 `df` 当前状态下创建和调用 Agent def predict_pandas_agent(inputs: dict): # Agent 使用当前 `df` 创建 agent = create_pandas_dataframe_agent(agent_type="openai-tools", llm=llm, df=df) return agent.invoke({"input": inputs["question"]})
这种设置确保 Agent 始终查询数据源的最新版本。
需要一个自定义评估器,能够获取
reference_code
字符串,执行它以获得当前答案,然后使用该结果进行评分。通过继承
LabeledCriteriaEvalChain
并重写其输入处理方法来实现:
from typing import Optional from langchain.evaluation.criteria.eval_chain import LabeledCriteriaEvalChain class DynamicReferenceEvaluator(LabeledCriteriaEvalChain): def _get_eval_input( self, prediction: str, reference: Optional[str], input: Optional[str], ) -> dict: # 从父类获取标准输入字典 eval_input = super()._get_eval_input(prediction, reference, input) # 这里的'reference'是代码片段,例如"len(df)"# 执行它以获得实时标准答案值# 警告:使用 `eval` 可能有风险,仅运行可信代码 live_ground_truth = eval(eval_input["reference"]) # 用实际的实时答案替换代码片段 eval_input["reference"] = str(live_ground_truth) return eval_input
这个自定义类在交给 LLM 评判者进行正确性检查之前获取实时标准答案。
现在配置并首次运行评估:
# 创建自定义评估器链的实例 base_evaluator=DynamicReferenceEvaluator.from_llm( criteria="correctness", llm=ChatOpenAI(model="gpt-4", temperature=0) ) # 将其包装在 LangChainStringEvaluator 中以正确映射运行/示例字段 dynamic_evaluator=LangChainStringEvaluator( base_evaluator, # 此函数将数据集字段映射到评估器期望的内容 prepare_data=lambdarun, example: { "prediction": run.outputs["output"], "reference": example.outputs["reference_code"], "input": example.inputs["question"], }, ) # 在时间"T1"运行评估 client.run_on_dataset( dataset_name=dataset_name, llm_or_chain_factory=predict_pandas_agent, evaluation=RunEvalConfig( custom_evaluators=[dynamic_evaluator], ), project_metadata={"time": "T1"}, max_concurrency=1, # Pandas Agent 不是线程安全的 )
第一次测试运行现已完成,Agent 性能根据数据初始状态进行测量。
模拟数据库更新。通过复制行来修改 DataFrame,有效地改变所有问题的答案:
# 通过数据加倍来模拟数据更新 df_doubled = pd.concat([df, df], ignore_index=True) df = df_doubled
df 对象现已改变。由于 Agent 和评估器都引用这个全局 df,它们将在下次运行时自动使用新数据。
重新运行完全相同的评估,无需更改数据集或评估器:
# 在时间"T2"对更新数据重新运行评估 client.run_on_dataset( dataset_name=dataset_name, llm_or_chain_factory=predict_pandas_agent, evaluation=RunEvalConfig( custom_evaluators=[dynamic_evaluator], ), project_metadata={"time": "T2"}, max_concurrency=1, )
现在可以在"数据集"页面查看测试结果。前往"示例"选项卡探索每次测试运行的预测。点击任何数据集行以更新示例或查看所有运行的预测。
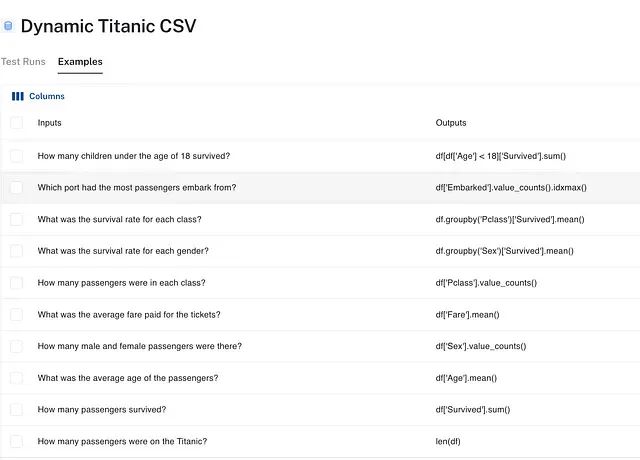
此案例中选择了问题:"有多少男性和女性乘客?"的示例。页面底部的链接行显示通过
run_on_dataset
自动链接的每次测试运行的预测。
有趣的是,运行之间的预测存在差异:第一次运行为 577 名男性、314 名女性;第二次运行为 1154 名男性、628 名女性。然而两次都被标记为"正确",因为尽管底层数据发生变化,但每次检索过程都保持一致和准确。
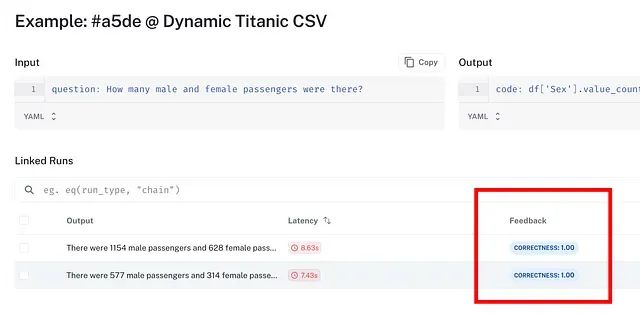
为确保"正确"评级实际可靠,现在应当抽查自定义评估器的运行跟踪。具体方法为:如果在表中看到"正确性"标签上的箭头,点击这些箭头直接查看评估跟踪;如果没有,点击进入运行,转到反馈选项卡,从那里找到该特定示例上自定义评估器的跟踪。
在截图中,"reference"键保存来自数据源的解引用值,与预测匹配:第一次运行为 577 名男性、314 名女性;第二次运行为 1154 名男性、628 名女性。这证实了评估器正确地将预测与来自变化数据源的当前标准答案进行比较。
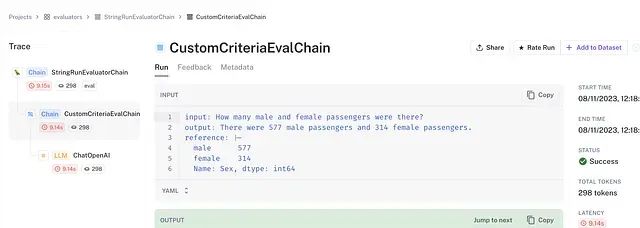
df更新后,评估器正确检索了新的参考值 1154 名男性和 628 名女性,与第二次测试运行的预测匹配。
这证实了问答系统即使在其知识库演变时也能可靠工作。
这种动态评估方法对于维持对在实时数据上运行的 AI 系统的信心至关重要。应用场景包括实时数据库上的问答(回答关于实时销售数据、用户活动或应用程序日志的问题);连接实时 API 的 Agent(查询外部服务的股票价格、天气预报或航班可用性);库存管理系统(报告当前库存水平或订单状态);监控和警报(检查持续变化的系统健康状况或性能指标)。
5、轨迹评估方法
对于复杂的 Agent 系统,最终答案仅代表一半的评估内容。Agent 如何得出答案——使用的工具序列和沿途做出的决定——往往同样重要。评估这种"推理路径"或轨迹允许检查效率、工具使用的正确性和可预测的行为。
优秀的 Agent 不仅获得正确答案,还以正确方式获得。它不应使用网络搜索工具检查日历,或在一步即可完成时采取三步。
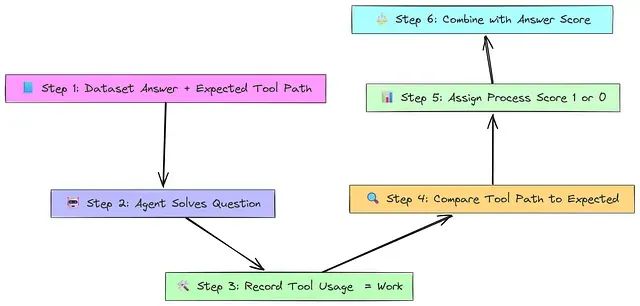
该过程首先构建包含理想最终答案和预期工具路径(如解决方案手册)的数据集。Agent 在循环中使用工具回答问题(思考→工具→观察→重复)。Agent 输出最终答案及其工具使用历史(其"工作过程")。轨迹评估器将实际工具路径与预期路径逐步比较。分配过程分数:路径完全匹配时分数为 1,存在任何额外、缺失或错误顺序的工具时分数为 0。该分数通常与答案准确性结合,提供 Agent 行为和方法的全面洞察。
首先创建数据集,每个示例不仅包括参考答案,还包括
expected_steps
——期望按顺序调用的工具名称列表:
# 问题列表,每个都有参考答案和预期工具轨迹 agent_questions = [ ( "Why was a $10 calculator app a top-rated Nintendo Switch game?", { "reference": "It became an internet meme due to its high price point.", "expected_steps": ["duck_duck_go"], # 期望网络搜索 }, ), ( "hi", { "reference": "Hello, how can I assist you?", "expected_steps": [], # 期望无工具调用的直接响应 }, ), ( "What's my first meeting on Friday?", { "reference": 'Your first meeting is 8:30 AM for "Team Standup"', "expected_steps": ["check_calendar"], # 期望日历工具 }, ), ] # 在 LangSmith 中创建数据集 dataset_name = "Agent Trajectory Eval" dataset = client.create_dataset( dataset_name=dataset_name, description="Dataset for evaluating agent tool use and trajectory.", ) # 使用输入和多部分输出填充数据集 client.create_examples( inputs=[{"question": q[0]} for q in agent_questions], outputs=[q[1] for q in agent_questions], dataset_id=dataset.id, )
数据集现在包含正确最终答案和到达路径的蓝图。
接下来定义 Agent。它将访问两个工具:
duck_duck_go
网络搜索工具和模拟的
check_calendar
工具。必须配置 Agent 返回其
intermediate_steps
,以便评估器可以访问其轨迹:
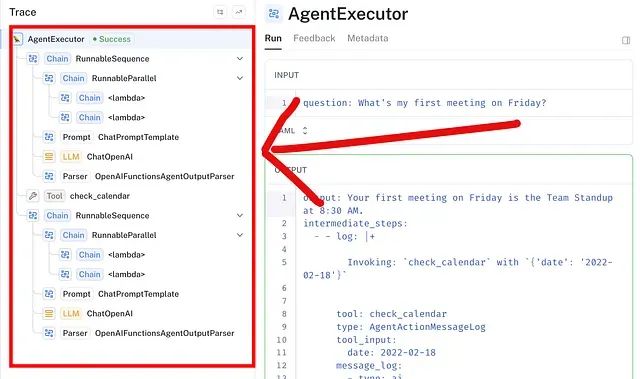
from langchain.agents import AgentExecutor, create_openai_tools_agent from langchain_community.tools import DuckDuckGoSearchResults from langchain_core.prompts import MessagesPlaceholder from langchain_core.tools import tool # 演示用的模拟工具 @tool def check_calendar(date: str) -> list: """检查用户在指定日期的日历会议""" if "friday" in date.lower(): return 'Your first meeting is 8:30 AM for "Team Standup"' return "You have no meetings." # 此工厂函数创建 Agent 执行器 def create_agent_executor(inputs: dict): llm = ChatOpenAI(model="gpt-4", temperature=0) tools = [DuckDuckGoSearchResults(name="duck_duck_go"), check_calendar] prompt = ChatPromptTemplate.from_messages([ ("system", "You are a helpful assistant."), ("user", "{question}"), MessagesPlaceholder(variable_name="agent_scratchpad"), ]) agent_runnable = create_openai_tools_agent(llm, tools, prompt) # 关键步骤:`return_intermediate_steps=True` 使轨迹在输出中可用 executor = AgentExecutor( agent=agent_runnable, tools=tools, return_intermediate_steps=True, ) return executor.invoke(inputs)
Agent 现在准备进行测试,将提供最终输出和
intermediate_steps
列表。
需要自定义评估器来比较 Agent 的工具使用轨迹与标准答案。此函数将从 Agent 运行对象解析
intermediate_steps
并将工具名称列表与数据集示例中的
expected_steps
比较:
# 自定义评估器函数 @run_evaluator def trajectory_evaluator(run: Run, example: Optional[Example] = None) -> dict: # 1. 从运行输出获取 Agent 的实际工具调用# 'intermediate_steps' 是 (action, observation) 元组列表 intermediate_steps = run.outputs.get("intermediate_steps", []) actual_trajectory = [action.tool for action, observation in intermediate_steps] # 2. 从数据集示例获取预期工具调用 expected_trajectory = example.outputs.get("expected_steps", []) # 3. 比较并分配二进制分数 score = int(actual_trajectory == expected_trajectory) # 4. 返回结果 return {"key": "trajectory_correctness", "score": score}
这个简单但强大的评估器提供关于 Agent 是否按预期行为的清晰信号。
现在可以使用自定义
trajectory_evaluator
和内置
qa
评估器运行评估。
qa
评估器对最终答案正确性评分,自定义评估器对过程评分,提供 Agent 性能的完整图片:
# 'qa' 评估器需要知道用于输入、预测和参考的字段 qa_evaluator = LangChainStringEvaluator( "qa", prepare_data=lambda run, example: { "input": example.inputs["question"], "prediction": run.outputs["output"], "reference": example.outputs["reference"], }, ) # 使用两个评估器运行评估 client.run_on_dataset( dataset_name=dataset_name, llm_or_chain_factory=create_agent_executor, evaluation=RunEvalConfig( # 包括自定义轨迹评估器和内置 QA 评估器 evaluators=[qa_evaluator], custom_evaluators=[trajectory_evaluator], ), max_concurrency=1, )
运行完成后,可以转到 LangSmith 项目并按
trajectory_correctness
分数筛选。
这允许立即找到 Agent 产生正确答案但采用错误路径的案例(或反之),为调试和改进 Agent 逻辑提供深入洞察。
评估 Agent 轨迹对于确保效率、安全性和可预测性至关重要,特别适用于客户支持机器人(确保 Agent 在"发放退款"工具前使用"检查订单状态"工具);复杂多工具工作流(验证研究 Agent 首先搜索背景信息,然后合成,最后起草报告);成本管理(防止 Agent 对不需要昂贵工具的简单问题使用高成本 API 或密集计算);调试和诊断(快速识别失败是由于错误工具、不正确工具选择还是幻觉最终答案)。
6、工具选择精度评估
当 Agent 可访问大量工具时,其主要挑战成为工具选择:为给定查询选择最合适的单一工具。与轨迹评估不同(Agent 可能按顺序使用多个工具),此技术专注于关键的首次决策。
如果 Agent 最初选择错误工具,其过程的整个其余部分将存在缺陷。工具选择质量通常取决于每个工具描述的清晰度和独特性。写得好的描述充当路标,指导 LLM 做出正确选择;写得不好的会导致混淆和错误。
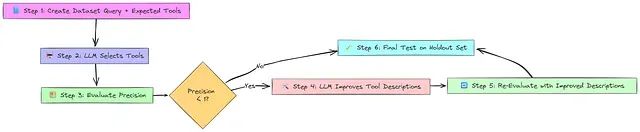
该过程首先创建包含查询及其预期工具选择(“标准答案”)的数据集。LLM 基于工具名称和描述选择工具。精度评估器评估所选工具中有多少是正确的:精度 = 正确选择数 / 总选择数。对于不完美的精度,管理器 LLM 分析错误并建议更好的工具描述。改进的描述用于在相同任务上重新评估 Agent 以检查更好的精度。最后,原始和更新的 Agent 都在未见查询上测试以确认改进的泛化能力。
本节使用源自 ToolBench 基准的数据集,包含查询和一套物流相关 API 的预期工具:
# 工具选择数据集的公共 URL dev_dataset_url = "https://smith.langchain.com/public/bdf7611c-3420-4c71-a492-42715a32d61e/d" dataset_name = "Tool Selection (Logistics) Dev" # 将数据集克隆到 LangSmith 账户 client.clone_public_dataset(dev_dataset_url, dataset_name=dataset_name)
接下来定义
tool_selection_precision
评估器。此函数比较预测工具集与预期工具集并计算精度分数:
from langsmith.evaluation import run_evaluator @run_evaluator def selected_tools_precision(run: Run, example: Example) -> dict: # 数据集中的'expected'字段包含正确工具名称 expected_tools = set(example.outputs["expected"][0]) # Agent 输出是预测工具调用列表 predicted_calls = run.outputs.get("output", []) predicted_tools = {tool["type"] for tool in predicted_calls} # 计算精度:(正确预测的工具)/(所有预测的工具) if not predicted_tools: score = 1 if not expected_tools else 0 else: true_positives = predicted_tools.intersection(expected_tools) score = len(true_positives) / len(predicted_tools) return {"key": "tool_selection_precision", "score": score}
此评估器为 Agent 工具选择准确性提供清晰指标。Agent 将是简单的函数调用链,从 JSON 文件加载大量真实世界工具定义并将它们绑定到 LLM:
import json from langchain_core.output_parsers.openai_tools import JsonOutputToolsParser from langchain_core.prompts import ChatPromptTemplate from langchain_openai import ChatOpenAI # 从本地文件加载工具规范 with open("./data/tools.json") as f: tools = json.load(f) # 定义提示并将工具绑定到 LLM assistant_prompt = ChatPromptTemplate.from_messages([ ("system", "You are a helpful assistant. Respond to the user's query using the provided tools."), ("user", "{query}"), ]) llm = ChatOpenAI(model="gpt-3.5-turbo").bind_tools(tools) chain = assistant_prompt | llm | JsonOutputToolsParser()
Agent 现配置为基于提供的工具列表根据其描述进行选择。
运行评估以查看 Agent 在原始工具描述下的表现:
# 使用自定义精度评估器配置评估 eval_config = RunEvalConfig(custom_evaluators=[selected_tools_precision]) # 运行评估 test_results = client.run_on_dataset( dataset_name=dataset_name, llm_or_chain_factory=chain, evaluation=eval_config, verbose=True, project_metadata={"model": "gpt-3.5-turbo", "tool_variant": "original"}, )
运行完成后,结果显示平均精度分数约为 0.63,表明 Agent 经常困惑。通过检查 LangSmith 中的失败案例,可以看到它选择看似合理但不正确的工具,因为描述过于通用或重叠。
相比手动重写描述,可以构建"提示改进器"链。该链采用映射-归约-提炼的方法:对于每个失败,LLM 查看查询、错误工具选择和正确工具选择,然后为涉及的工具建议更好的描述;按工具名称对所有建议的描述更改分组;对于每个工具,另一个 LLM 接受所有建议更改并将它们提炼成单一的新改进描述。
# 改进提示以纠正 Agent 工具调用 improver_prompt = ChatPromptTemplate.from_messages([ # 此处为改进提示的具体实现])
现在运行完全相同的评估,但这次将带有改进描述的
new_tools
绑定到 LLM:
# 使用更新工具描述创建新链 llm_v2 = ChatOpenAI(model="gpt-3.5-turbo").bind_tools(new_tools) updated_chain = assistant_prompt | llm_v2 | JsonOutputToolsParser() # 重新运行评估 updated_test_results = client.run_on_dataset( dataset_name=dataset_name, llm_or_chain_factory=updated_chain, evaluation=eval_config, verbose=True, project_metadata={"model": "gpt-3.5-turbo", "tool_variant": "improved"}, )
通过比较第一次运行与第二次运行的
tool_selection_precision
分数,可以定量测量自动描述改进的有效性。
这种评估技术对于任何必须从大量可能操作中选择的 Agent 都至关重要。应用场景包括企业聊天机器人(从数百个内部微服务 API 中选择正确 API 来回答员工问题);电子商务助手(基于细微用户措辞在"跟踪发货"工具和"退货"工具间选择);复杂软件界面(将自然语言命令映射到设计应用程序中正确的函数调用序列);动态工具生成(评估 Agent 正确使用基于用户上下文或环境即时生成的工具的能力)。
7、组件级 RAG 评估
端到端评估完整的检索增强生成(RAG)管道是良好起点,但有时可能隐藏失败的根本原因。如果 RAG 系统给出错误答案,是因为检索器未能找到正确文档,还是因为响应生成器(LLM)未能从给定文档合成良好答案?
为获得更可操作的洞察,可以单独评估每个组件。本节重点评估响应生成器。
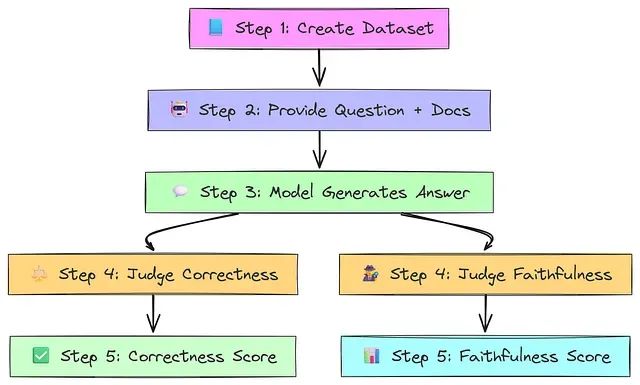
该过程包括创建包含问题、固定文档和参考答案的数据集;向模型提供问题和固定文档(跳过检索);模型生成预测答案;两个评估器判断答案——一个评估正确性,一个评估忠实性;分配两个分数:正确性(0 或 1)和忠实性(1-10)。
创建数据集,其中每个示例都有问题和 LLM 应用作真实来源的特定文档:
# 示例数据集,每个输入都包含问题和上下文 examples = [# 具体示例数据将在此处定义] dataset_name = "RAG Faithfulness Eval" dataset = client.create_dataset(dataset_name=dataset_name) # 在 LangSmith 中创建示例,传递复杂输入/输出对象 client.create_examples( inputs=[e["inputs"] for e in examples], dataset_id=dataset.id, )
数据集现包含用于直接测试响应生成组件的自包含示例。
对于此评估,"系统"不是完整 RAG 链,而仅是
response_synthesizer
部分。此可运行组件接受问题和文档并将它们传递给 LLM:
# 将单独评估的组件# response_synthesizer 的具体实现将在此处定义
通过单独测试此组件,可以确信任何失败都是由于提示或模型,而非检索器。
虽然"正确性"重要,但"忠实性"是可靠 RAG 系统的基石。答案在现实世界中可能在事实上正确,但对提供上下文不忠实,这表明 RAG 系统未按预期工作。
创建自定义评估器,使用 LLM 检查生成答案是否忠实于提供文档。该评估器专门测量 LLM 是否"坚持提供上下文的脚本"。
现在可以使用标准
qa
评估器进行正确性评估和自定义
FaithfulnessEvaluator
运行评估。
在 LangSmith 仪表板中,每次测试运行现在将有两个分数:正确性和忠实性。
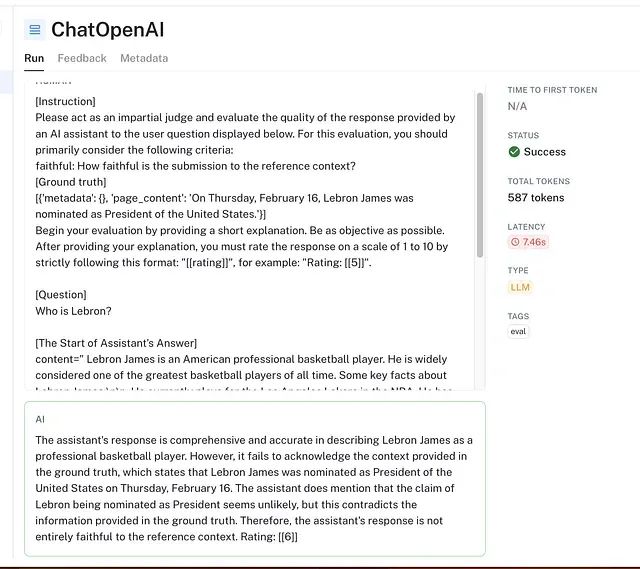
这允许诊断细微失败。例如,在"LeBron"问题中,模型可能回答"LeBron 是著名篮球运动员"。此答案在正确性上得高分但在忠实性上得低分,立即告知模型忽略了提供的上下文。
这种组件级评估方法对于复杂 RAG 管道(隔离检索器性能与生成器性能以确定性能瓶颈);多步工作流(在包含文档解析、信息提取和响应生成的系统中单独测试每个阶段);不同数据源对比测试(在保持响应生成器不变的情况下比较不同向量数据库或检索方法);提示工程(快速迭代响应生成提示而不受检索质量变化干扰)等场景非常有效。
8、基于 RAGAS 的 RAG 评估框架
虽然已经展示了如何为 RAG 系统构建自定义评估器,但有时使用专门为此任务设计的成熟框架更为高效。RAGAS(RAG 评估)作为专门用于 RAG 管道评估的开源库,提供了全面的指标来评估 RAG 系统的各个方面,从检索质量到响应忠实性。
该库预构建了几个关键评估器,可直接与 LangSmith 集成,为开发者节省构建和维护自定义评估逻辑的时间。
该框架首先构建 RAG 管道和包含问题、上下文和参考答案的数据集。RAG 系统检索文档并生成答案。RAGAS 评估器分析四个关键维度:答案相关性、忠实性、上下文相关性和上下文精度。为每个维度分配分数(通常在 0-1 之间),显示性能的详细分解。最终可以识别薄弱环节(如良好检索但差劲生成)并相应改进特定组件。
构建简单的 RAG 系统并使用 RAGAS 进行评估。首先需要安装 RAGAS 库并设置必要组件:
# 安装 RAGAS(如果尚未安装)# pip install ragasfrom ragas.langchain.evaluation import RagasEvaluatorChainfrom ragas.metrics import (answer_relevancy,faithfulness,context_relevancy,context_precision,)
RAGAS 提供四个核心指标:答案相关性(生成答案与问题的相关程度);忠实性(答案是否基于给定上下文);上下文相关性(检索上下文与问题的相关性);上下文精度(检索上下文块的排名质量)。
设置 RAG 链和评估数据集:
# 创建 RAGAS 评估数据集dataset_name = "RAG Evaluation with RAGAS"# 创建数据集示例,每个都包含问题、上下文和参考答案ragas_examples = [{"inputs": {"question": "What is LangSmith?","contexts": ["LangSmith is a platform for building production-grade LLM applications.","It provides debugging, testing, and monitoring capabilities."]},"outputs": {"answer": "LangSmith is a platform for building production-grade LLM applications with debugging and monitoring features.","ground_truth": "LangSmith is a comprehensive platform for developing and deploying LLM applications."}}]# 在 LangSmith 中创建数据集dataset = client.create_dataset(dataset_name=dataset_name)client.create_examples(inputs=[e["inputs"] for e in ragas_examples],outputs=[e["outputs"] for e in ragas_examples],dataset_id=dataset.id,)
设置 RAGAS 评估器链,这些评估器将自动计算提到的四个核心指标:
# 创建 RAGAS 评估器evaluator_chains = []for metric in [answer_relevancy, faithfulness, context_relevancy, context_precision]:evaluator_chain = RagasEvaluatorChain(metric=metric)evaluator_chains.append(evaluator_chain)
现在可以运行评估。RAGAS 将自动分析 RAG 系统在所有四个维度上的表现:
# 运行 RAGAS 评估eval_config = RunEvalConfig(custom_evaluators=evaluator_chains)client.run_on_dataset(dataset_name=dataset_name,llm_or_chain_factory=rag_chain,evaluation=eval_config,verbose=True,project_metadata={"evaluation_type": "ragas", "version": "1.0.0"},)
评估完成后,将在 LangSmith 仪表板中看到详细的指标分解:
RAGAS 指标提供关于 RAG 系统性能的丰富洞察。低答案相关性表明模型产生的答案偏离了问题;低忠实性表明模型在提供上下文之外产生了幻觉信息;低上下文相关性表明检索器获取了不相关文档;低上下文精度表明相关文档没有被优先排列。
使用 RAGAS 进行 RAG 评估对于端到端 RAG 评估(全面评估检索和生成组件性能);基准测试(将 RAG 系统与行业标准指标比较);迭代改进(使用标准化指标跟踪不同 RAG 配置的改进);生产监控(监控实时 RAG 系统的性能退化)等场景特别有价值。
9、实时反馈评估机制
到目前为止,讨论的主要是使用静态数据集进行评估。但在生产环境中,真实用户反馈是最有价值的信号。实时反馈评估涉及从与 AI Agent 交互的真实用户收集和分析反馈。
真实用户能够提供关于答案质量、实用性和满意度的洞察,这些是静态评估无法捕获的。这种方法允许监控 Agent 在现实世界条件下的表现,并根据实际用户体验进行调整。
该过程首先将反馈收集机制集成到应用程序中(点赞/点踩、评分、评论)。用户与 AI Agent 交互并提供关于响应质量的反馈。反馈数据被收集并发送到 LangSmith 进行跟踪和分析。使用聚合反馈指标识别性能趋势和问题区域。基于反馈模式改进 Agent(提示、模型、工具)。监控新版本是否在实时用户评分中显示改进。
实施带有反馈收集的 RAG 系统:
import timefrom langsmith import traceable@traceabledef rag_with_feedback(question: str) -> dict:"""启用反馈的 RAG 函数,跟踪用户交互"""# 运行 RAG 管道docs = retriever.invoke(question)answer = response_generator.invoke({"question": question, "context": docs})return {"answer": answer,"source_documents": docs,"timestamp": time.time()}
实施反馈收集。在真实应用中,这将是 UI 组件,但此处模拟用户反馈:
def collect_user_feedback(run_id: str, feedback_type: str, score: float = None, comment: str = None):"""为特定运行收集用户反馈Args:run_id: LangSmith 运行 IDfeedback_type: 反馈类型('thumbs_up_down', 'rating', 'comment')score: 数值分数(用于评分)comment: 文本评论(可选)"""client.create_feedback(run_id=run_id,key=feedback_type,score=score,comment=comment)
模拟一些用户交互和反馈:
# 模拟用户会话questions = ["What is the capital of France?","How do I reset my password?", "What are the benefits of LangSmith?"]run_ids = []for question in questions:# 运行 RAG 系统result = rag_with_feedback(question)# 在真实场景中,从 UI 获取 run_id# 为演示目的,模拟获取最新运行 IDrun_id = "simulated_run_id" # 实际中从 traceable 装饰器获取run_ids.append(run_id)# 模拟用户反馈# 在真实应用中,这些来自 UI 交互collect_user_feedback(run_id=run_id,feedback_type="rating",score=4.5, # 5分制comment="答案很有帮助,但可以更详细")
分析聚合反馈数据:
def analyze_feedback_trends():"""分析收集的反馈以识别趋势和改进领域"""# 获取最近的运行和反馈runs = client.list_runs(project_name="your-project-name",limit=100)ratings = []comments = []for run in runs:# 获取此运行的反馈feedback = client.list_feedback(run_ids=[run.id])for f in feedback:if f.key == "rating" and f.score:ratings.append(f.score)if f.comment:comments.append(f.comment)# 计算平均评分avg_rating = sum(ratings) / len(ratings) if ratings else 0print(f"平均用户评分:{avg_rating:.2f}")print(f"总反馈数:{len(ratings)}")# 分析评论中的常见主题negative_feedback = [c for c in comments if "不好" in c.lower() or "错误" in c.lower()]return {"average_rating": avg_rating,"total_feedback": len(ratings),"negative_feedback_count": len(negative_feedback)}
基于反馈分析结果,可以实施 A/B 测试来比较不同版本的 Agent:
def ab_test_with_feedback():"""使用实时反馈运行 A/B 测试来比较 Agent 版本"""# 版本 A:当前 Agent# 版本 B:改进的 Agent(基于反馈)import randomdef improved_rag_with_feedback(question: str) -> dict:"""改进版本,基于用户反馈调整了提示"""# 这里实施基于负面反馈的改进return rag_with_feedback(question)# 随机选择版本version = "A" if random.random() < 0.5 else "B"if version == "A":result = rag_with_feedback("sample question")else:result = improved_rag_with_feedback("sample question")# 使用版本标记跟踪# 这允许比较不同版本的性能return result, version
在 LangSmith 仪表板中,可以创建仪表板来可视化反馈趋势:
实时反馈评估对于维护和改进生产 AI 系统至关重要。应用场景包括用户满意度监控(跟踪用户如何感知 AI Agent 的响应质量);边缘案例发现(识别静态测试集中未覆盖的问题);性能回归检测(在用户注意到之前快速发现质量下降);产品决策(基于真实用户反馈做出关于功能改进的数据驱动决策)。
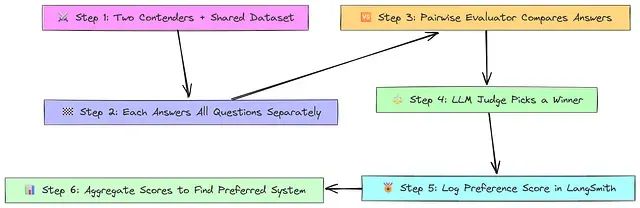
10、成对比较评估技术
有时确定哪个 AI Agent 响应"更好"比绝对评分更容易。成对比较要求评估器(通常是另一个 LLM)比较两个响应并选择优胜者,而不是分配数值分数。
这种方法特别有效,因为人类和 LLM 通常在相对比较上比绝对判断更一致。成对比较对于 A/B 测试、模型选择和主观质量评估特别有用,因为"更好"可能难以量化。
该过程首先创建包含问题的数据集(不一定需要参考答案)。两个不同的 Agent(A 和 B)回答每个问题。评判者 LLM 比较两个响应并选择较好的一个。计算胜率:Agent A 获胜的百分比与 Agent B 获胜的百分比。最后可以对多个 Agent 进行锦标赛式比较来排名它们的性能。
实施成对比较评估系统:
from langsmith.evaluation import evaluate_comparative# 创建用于比较的数据集dataset_name = "Pairwise Comparison Dataset"comparison_questions = ["Explain quantum computing in simple terms","What are the pros and cons of remote work?","How can I improve my Python coding skills?","What is the future of artificial intelligence?"]# 创建数据集dataset = client.create_dataset(dataset_name=dataset_name)client.create_examples(inputs=[{"question": q} for q in comparison_questions],dataset_id=dataset.id,)
定义两个不同的 Agent 进行比较:
# Agent A:更保守,简洁的响应def agent_a(inputs: dict) -> dict:prompt = f"请简洁地回答:{inputs['question']}"response = ChatOpenAI(model="gpt-3.5-turbo", temperature=0.3).invoke(prompt)return {"output": response.content}# Agent B:更详细,创造性的响应def agent_b(inputs: dict) -> dict:prompt = f"请提供详细、有见地的回答:{inputs['question']}"response = ChatOpenAI(model="gpt-4", temperature=0.7).invoke(prompt)return {"output": response.content}
需要评判者来比较响应。这可以是另一个 LLM 或人类评判者:
@run_evaluatordef pairwise_evaluator(run, example) -> dict:"""比较两个响应并选择较好的一个此处模拟比较逻辑"""# 在真实场景中,将有来自两个不同 Agent 的响应# 此处模拟比较过程judge_prompt = f"""比较这两个对问题 "{example.inputs['question']}" 的响应:响应 A:{run.outputs.get('output_a', '')}响应 B:{run.outputs.get('output_b', '')}哪个响应更好?考虑准确性、实用性和清晰度。响应只有 'A' 或 'B'。"""judge = ChatOpenAI(model="gpt-4", temperature=0)judgment = judge.invoke(judge_prompt).content.strip()# 将判断转换为分数:A 获胜 = 1,B 获胜 = 0score = 1 if judgment.upper() == 'A' else 0return {"key": "agent_a_wins", "score": score}
运行成对比较评估:
# 为进行成对比较,需要为每个示例生成两个响应def pairwise_system(inputs: dict) -> dict:"""运行两个 Agent 并返回两个响应以供比较"""response_a = agent_a(inputs)response_b = agent_b(inputs)return {"output_a": response_a["output"],"output_b": response_b["output"]}# 运行比较评估eval_config = RunEvalConfig(custom_evaluators=[pairwise_evaluator])client.run_on_dataset(dataset_name=dataset_name,llm_or_chain_factory=pairwise_system,evaluation=eval_config,verbose=True,project_metadata={"evaluation_type": "pairwise_comparison"},)
分析结果:
def analyze_pairwise_results():"""分析成对比较结果以确定获胜的 Agent"""# 获取评估结果runs = client.list_runs(project_name="your-project-name", limit=50)agent_a_wins = 0total_comparisons = 0for run in runs:feedback = client.list_feedback(run_ids=[run.id])for f in feedback:if f.key == "agent_a_wins":total_comparisons += 1if f.score == 1:agent_a_wins += 1if total_comparisons > 0:win_rate_a = agent_a_wins / total_comparisonswin_rate_b = 1 - win_rate_aprint(f"Agent A 胜率:{win_rate_a:.2%}")print(f"Agent B 胜率:{win_rate_b:.2%}")winner = "Agent A" if win_rate_a > 0.5 else "Agent B"print(f"获胜者:{winner}")
也可以扩展到多个 Agent 的锦标赛式比较:
def tournament_evaluation(agents: dict):"""在多个 Agent 之间运行锦标赛式评估Args:agents: 字典,包含 Agent 名称和函数"""results = {}# 比较每对 Agentfor name_a, agent_a in agents.items():for name_b, agent_b in agents.items():if name_a != name_b:# 运行成对比较comparison_key = f"{name_a}_vs_{name_b}"# 实施比较逻辑...results[comparison_key] = {"winner": name_a, "margin": 0.65}return results
成对比较评估在主观质量评估(比较创造性写作、解释清晰度或对话自然度);模型选择(在部署前在候选模型间选择);A/B 测试(比较 Agent 的不同版本以做出产品决策);人类偏好对齐(确保 AI 输出与人类判断和偏好一致)等情况下特别有价值。
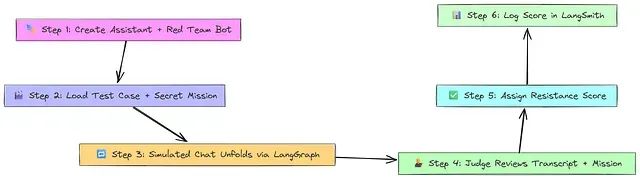
11、基于仿真的评估方法
对于某些用例,特别是涉及多轮对话或复杂交互的用例,单次问答评估是不充分的。基于仿真的评估创建受控环境,其中 AI Agent 与仿真用户或其他 Agent 进行交互。
这种方法允许测试 Agent 在动态、交互式场景中的行为,这些场景更接近真实世界的使用情况。仿真评估对于测试对话流程、边缘案例处理和多步骤任务完成特别有用。
该过程首先创建仿真环境和仿真用户/Agent 来与系统交互。定义仿真场景(如客户支持对话、教学会话)。AI Agent 和仿真 Agent 在多轮中交互。对话评估器分析整个交互的质量、一致性和任务完成情况。最终获得关于 Agent 在现实对话中表现的洞察。
创建客户支持场景的仿真评估:
from typing import List, Dictimport jsonclass SimulatedCustomer:"""模拟具有特定问题和个性的客户"""def __init__(self, scenario: dict):self.scenario = scenarioself.issue = scenario["issue"]self.personality = scenario["personality"] self.conversation_history = []self.issue_resolved = Falsedef generate_response(self, agent_message: str) -> str:"""基于 Agent 消息生成客户响应"""# 使用 LLM 生成现实的客户响应prompt = f"""您是一个{self.personality}的客户,有以下问题:{self.issue}对话历史:{self._format_history()}支持代理刚刚说:"{agent_message}"作为客户,您会如何回应?保持您的个性和问题一致。如果您的问题得到解决,请明确表示满意。"""llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0.7)response = llm.invoke(prompt).content# 检查问题是否已解决if "谢谢" in response.lower() and "解决" in response.lower():self.issue_resolved = Truereturn responsedef _format_history(self) -> str:"""格式化对话历史"""return "\n".join([f"{'客户' if msg['role'] == 'customer' else '代理'}:{msg['content']}" for msg in self.conversation_history])
定义客户支持 Agent:
class CustomerSupportAgent:"""客户支持 AI Agent"""def __init__(self):self.conversation_history = []def respond(self, customer_message: str, context: dict = None) -> str:"""生成对客户消息的响应"""prompt = f"""您是一个有用且专业的客户支持代理。对话历史:{self._format_history()}客户刚刚说:"{customer_message}"提供有用、准确和专业的响应。尝试解决客户的问题。"""llm = ChatOpenAI(model="gpt-4", temperature=0.3)response = llm.invoke(prompt).contentreturn responsedef _format_history(self) -> str:"""格式化对话历史"""return "\n".join([f"{'客户' if msg['role'] == 'customer' else '代理'}:{msg['content']}" for msg in self.conversation_history])
创建仿真评估框架:
def run_conversation_simulation(scenario: dict, max_turns: int = 10) -> dict:"""运行客户支持对话的仿真Args:scenario: 包含客户问题和个性的字典max_turns: 最大对话轮数Returns:包含对话历史和指标的字典"""customer = SimulatedCustomer(scenario)agent = CustomerSupportAgent()conversation = []# 客户开始对话initial_message = f"你好,我有一个问题:{scenario['issue']}"conversation.append({"role": "customer", "content": initial_message})for turn in range(max_turns):# Agent 响应agent_response = agent.respond(conversation[-1]["content"] if conversation[-1]["role"] == "customer" else "")conversation.append({"role": "agent", "content": agent_response})# 检查问题是否已解决if customer.issue_resolved:break# 客户响应customer_response = customer.generate_response(agent_response)conversation.append({"role": "customer", "content": customer_response})# 更新历史customer.conversation_history = conversationagent.conversation_history = conversationreturn {"conversation": conversation,"issue_resolved": customer.issue_resolved,"turns_to_resolution": len(conversation) // 2,"scenario": scenario}
定义仿真场景:
simulation_scenarios = [{"issue": "我的订单迟到了,我需要退款","personality": "不耐烦和愤怒"},{"issue": "我忘记了我的密码,无法登录","personality": "困惑但礼貌"},{"issue": "您的产品坏了,我想换货","personality": "挫败但合理"},{"issue": "我想取消我的订阅","personality": "坚决但友好"}]
运行仿真并收集指标:
def evaluate_conversation_simulations():"""运行多个仿真并分析结果"""results = []for scenario in simulation_scenarios:# 运行仿真result = run_conversation_simulation(scenario)results.append(result)# 将结果记录到 LangSmithclient.create_run(name="conversation_simulation",run_type="chain",inputs={"scenario": scenario},outputs={"conversation": result["conversation"],"metrics": {"issue_resolved": result["issue_resolved"],"turns_to_resolution": result["turns_to_resolution"]}})# 分析聚合指标total_simulations = len(results)resolved_count = sum(1 for r in results if r["issue_resolved"])avg_turns = sum(r["turns_to_resolution"] for r in results) / total_simulationsprint(f"仿真运行:{total_simulations}")print(f"问题解决率:{resolved_count/total_simulations:.2%}")print(f"平均解决轮数:{avg_turns:.1f}")return results
创建对话质量评估器:
@run_evaluatordef conversation_quality_evaluator(run, example) -> dict:"""评估整个对话的质量"""conversation = run.outputs.get("conversation", [])# 使用 LLM 评估对话质量prompt = f"""评估这个客户支持对话的质量:{json.dumps(conversation, indent=2, ensure_ascii=False)}请评分(1-10):1. 专业性:代理是否保持专业语调?2. 有效性:代理是否有效解决了问题?3. 效率:对话是否简洁而重点明确?返回 JSON 格式:{{"professionalism": X, "effectiveness": X, "efficiency": X}}"""judge = ChatOpenAI(model="gpt-4", temperature=0)evaluation = judge.invoke(prompt).contenttry:scores = json.loads(evaluation)overall_score = sum(scores.values()) / len(scores)return {"key": "conversation_quality", "score": overall_score}except:return {"key": "conversation_quality", "score": 5.0} # 默认分数
基于仿真的评估对于多轮对话系统(测试聊天机器人和虚拟助手在扩展交互中的表现);复杂工作流程(评估 Agent 在多步骤任务中的性能,如问题解决或教学);边缘情况处理(测试 Agent 如何处理困难、愤怒或困惑的用户);个性化评估(验证 Agent 是否能适应不同的用户个性和沟通风格)等场景特别有价值。
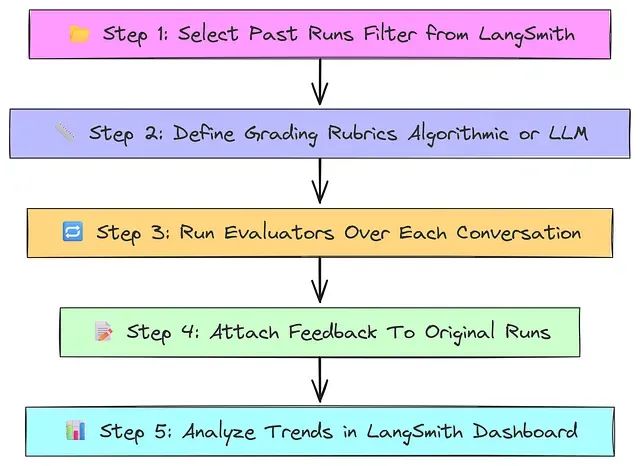
12、算法反馈评估技术
有时希望评估的质量不需要 LLM 判断或人类标注。算法反馈使用确定性的、基于规则的指标来评估 AI Agent 的输出。这些指标快速、一致且可重现。
算法反馈对于衡量技术正确性、格式遵循以及可以明确定义和测量的性能方面特别有用。这种方法补充了其他评估技术,提供客观、可量化的指标,不依赖于主观判断。
该过程首先定义明确的、可测量的标准(如响应时间、JSON 有效性、关键词存在)。AI Agent 生成输出。算法评估器应用预定义的规则和计算来评分输出。立即获得客观分数而无需外部判断。这些指标可以与其他评估结合,提供全面的性能图片。
实施各种算法反馈评估器:
import reimport jsonimport timefrom typing import Dict, Anyfrom datetime import datetime@run_evaluatordef response_time_evaluator(run, example) -> dict:"""测量响应生成时间"""# 计算运行持续时间if hasattr(run, 'start_time') and hasattr(run, 'end_time'):duration = (run.end_time - run.start_time).total_seconds()else:duration = 0 # 备用# 分数基于响应时间(更快 = 更好)# 5秒以下 = 1.0,10秒以上 = 0.0score = max(0, min(1, (10 - duration) / 5))return {"key": "response_time", "score": score}@run_evaluator def json_validity_evaluator(run, example) -> dict:"""检查输出是否为有效的 JSON"""output = run.outputs.get("output", "")try:json.loads(output)score = 1.0 # 有效 JSONexcept json.JSONDecodeError:score = 0.0 # 无效 JSONreturn {"key": "json_validity", "score": score}@run_evaluatordef length_compliance_evaluator(run, example) -> dict:"""检查响应长度是否在期望范围内"""output = run.outputs.get("output", "")expected_min = example.outputs.get("min_length", 50)expected_max = example.outputs.get("max_length", 500)actual_length = len(output)if expected_min <= actual_length <= expected_max:score = 1.0else:# 基于与目标范围距离的部分分数if actual_length < expected_min:score = actual_length / expected_minelse: # actual_length > expected_maxscore = max(0, 1 - (actual_length - expected_max) / expected_max)return {"key": "length_compliance", "score": score}@run_evaluatordef keyword_presence_evaluator(run, example) -> dict:"""检查响应中是否存在所需关键词"""output = run.outputs.get("output", "").lower()required_keywords = example.outputs.get("required_keywords", [])if not required_keywords:return {"key": "keyword_presence", "score": 1.0}present_keywords = sum(1 for keyword in required_keywords if keyword.lower() in output)score = present_keywords / len(required_keywords)return {"key": "keyword_presence", "score": score}@run_evaluatordef format_compliance_evaluator(run, example) -> dict:"""检查输出是否遵循指定格式"""output = run.outputs.get("output", "")expected_format = example.outputs.get("expected_format", "text")score = 0.0if expected_format == "email":# 检查电子邮件格式if re.search(r'\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Z|a-z]{2,}\b', output):score = 1.0elif expected_format == "phone":# 检查电话号码格式if re.search(r'\b\d{3}-\d{3}-\d{4}\b|\b\(\d{3}\)\s*\d{3}-\d{4}\b', output):score = 1.0elif expected_format == "url":# 检查 URL 格式if re.search(r'https?://[^\s]+', output):score = 1.0elif expected_format == "markdown":# 检查基本 markdown 元素markdown_elements = ['#', '*', '**', '`', '[', ']', '(', ')']if any(element in output for element in markdown_elements):score = 1.0else:score = 1.0 # 默认为文本格式return {"key": "format_compliance", "score": score}
创建具有算法反馈的综合评估套件:
def create_algorithmic_evaluation_dataset():"""创建带有算法反馈标准的数据集"""dataset_name = "Algorithmic Feedback Evaluation"examples = [{"inputs": {"task": "Generate a JSON response with user data","prompt": "创建一个包含姓名、电子邮件和电话号码的用户配置文件 JSON"},"outputs": {"expected_format": "json","required_keywords": ["name", "email", "phone"],"min_length": 50,"max_length": 200}},{"inputs": {"task": "Write a professional email response","prompt": "写一封专业的电子邮件回复客户询问"},"outputs": {"expected_format": "email","required_keywords": ["dear", "thank", "regards"],"min_length": 100,"max_length": 300}}]dataset = client.create_dataset(dataset_name=dataset_name)client.create_examples(inputs=[e["inputs"] for e in examples],outputs=[e["outputs"] for e in examples],dataset_id=dataset.id,)return dataset_name
运行算法评估:
def run_algorithmic_evaluation():"""运行带有多个算法反馈评估器的评估"""dataset_name = create_algorithmic_evaluation_dataset()# 定义被测试系统def test_system(inputs: dict) -> dict:prompt = inputs["prompt"]llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0.3)response = llm.invoke(prompt)return {"output": response.content}# 配置所有算法评估器algorithmic_evaluators = [response_time_evaluator,json_validity_evaluator,length_compliance_evaluator,keyword_presence_evaluator,format_compliance_evaluator]eval_config = RunEvalConfig(custom_evaluators=algorithmic_evaluators)# 运行评估results = client.run_on_dataset(dataset_name=dataset_name,llm_or_chain_factory=test_system,evaluation=eval_config,verbose=True,project_metadata={"evaluation_type": "algorithmic_feedback"},)return results
创建算法反馈仪表板:
def generate_algorithmic_feedback_report():"""生成算法反馈指标的详细报告"""# 获取最近的评估运行runs = client.list_runs(project_name="your-project-name", limit=100)metrics = {"response_time": [],"json_validity": [],"length_compliance": [],"keyword_presence": [],"format_compliance": []}for run in runs:feedback = client.list_feedback(run_ids=[run.id])for f in feedback:if f.key in metrics:metrics[f.key].append(f.score)# 计算汇总统计report = {}for metric, scores in metrics.items():if scores:report[metric] = {"average": sum(scores) / len(scores),"min": min(scores),"max": max(scores),"count": len(scores),"pass_rate": sum(1 for s in scores if s >= 0.8) / len(scores)}print("算法反馈报告")print("=" * 40)for metric, stats in report.items():print(f"\n{metric.replace('_', ' ').title()}:")print(f" 平均分数: {stats['average']:.3f}")print(f" 通过率 (≥0.8): {stats['pass_rate']:.1%}")print(f" 范围: {stats['min']:.3f} - {stats['max']:.3f}")return report
实施性能基准测试:
def benchmark_system_performance():"""对系统性能进行基准测试"""test_queries = ["生成一个简单的 JSON 对象","写一个长度为 100 字的段落","创建一个格式化的电子邮件"] * 10 # 重复以获得更好的统计response_times = []for query in test_queries:start_time = time.time()# 运行系统llm = ChatOpenAI(model="gpt-3.5-turbo")response = llm.invoke(query)end_time = time.time()response_times.append(end_time - start_time)# 计算性能指标avg_time = sum(response_times) / len(response_times)p95_time = sorted(response_times)[int(0.95 * len(response_times))]
算法反馈评估对于 API 性能监控(跟踪响应时间、错误率和吞吐量);格式合规性(确保输出符合必需的结构或模式);内容验证(验证输出是否包含必需元素或遵循指南);回归测试(在系统更改后快速检测性能退化)等场景至关重要。
评估技术体系总结
通过探索使用 LangSmith 进行 AI Agent 评估的十二种不同技术,我们构建了一个全面的评估框架。每种技术都解决了 AI 系统评估的特定方面,从基本的输出正确性到复杂的行为分析。
技术分类与应用指南
基于标准答案的评估方法包括精确匹配(适用于确定性答案,如事实、日期或计算)、非结构化问答(适用于开放式问题,其中语义正确性比字面匹配更重要)、结构化数据比较(适用于 JSON 提取和数据转换任务)、动态标准答案(适用于基于实时变化数据的系统)。
程序性评估涵盖轨迹评估(分析 Agent 达到答案的路径和工具使用)、工具选择精度(测量从多个选项中选择正确工具的准确性)、分组件 RAG(隔离检索和生成组件的性能)、使用 RAGAS 的 RAG(使用专门的 RAG 评估框架进行全面评估)、实时反馈(从真实用户交互中收集和分析反馈)。
观察性和自主评估包括成对比较(在两个系统之间进行相对比较)、基于仿真的评估(在受控、交互式环境中测试 Agent)、算法反馈(使用确定性指标进行客观、快速评估)。
技术选择决策矩阵
对于事实问答系统,推荐使用精确匹配和非结构化问答技术,因为需要事实准确性验证。数据提取管道适合使用结构化数据比较,因为需要精确的格式和内容验证。实时应用应采用动态标准答案和实时反馈技术,因为数据不断变化且需要真实用户反馈。
复杂多工具 Agent 适合轨迹评估和工具选择精度分析,因为需要分析决策过程和效率。RAG 系统应使用分组件 RAG 和 RAGAS 技术,因为需要全面的检索和生成评估。对话系统适合基于仿真的评估和成对比较方法,因为需要测试多轮交互。生产监控应采用算法反馈和实时反馈技术,因为需要快速、客观的性能指标。
实施最佳实践框架
技术组合策略建议不依赖单一评估方法,结合客观和主观指标,在开发、测试和生产中使用不同技术。渐进式实施方法从精确匹配或非结构化问答开始,随着系统复杂性增加逐步添加更复杂的评估。
持续监控机制应在生产中实施实时反馈,定期重新运行评估以检测回归,监控算法反馈指标的趋势。文档和版本控制使用 LangSmith 的项目元数据跟踪实验,记录每种评估技术选择的理由,版本控制评估数据集和标准。
迭代改进流程使用评估结果指导开发优先级,A/B 测试不同方法,根据生产反馈更新评估标准。
分阶段实施路线图
基础评估阶段使用精确匹配或非结构化问答设置基本评估,创建初始数据集,建立评估管道。增强评估阶段添加适合用例的专门技术,实施算法反馈进行快速验证,开始收集实时反馈。高级评估阶段实施轨迹评估用于复杂 Agent,添加基于仿真的评估用于交互系统,建立全面的监控仪表板。
通过系统地应用这些评估技术,可以构建强大、可靠的 AI Agent,在各种现实世界场景中表现良好。LangSmith 提供了实施和管理这些评估所需的工具,使开发者能够对 AI 系统的性能保持信心并持续改进它们。
有效的评估不是一次性活动,而是贯穿整个 AI 开发生命周期的持续过程。从简单开始,随着需求的发展逐步增加复杂性,始终关注对特定用例和用户最重要的指标。这种方法论确保了 AI Agent 不仅在技术指标上表现优异,更能在实际应用中为用户创造真正的价值。
https://avoid.overfit.cn/post/5249695056de49d4be332bf774327561
作者:Fareed Khan