C++ lambda表达式与线程库
lambda

当我们要使用 sort 进行排序时,由于sort 是支持模板的,所以说Compare 是一个可调用对象,而所有的可调用对象又可以进行分成三种情况:
函数指针:指向独立的普通函数。
函数对象(仿函数):具有
operator()的类或结构体对象。Lambda 表达式:匿名的、内联定义的函数对象。
上面的两种我们都进行接触过,下面我们就来学习一下lambda 表达式。
直观感受lanbda的便利
#define _CRT_SECURE_NO_WARNINGS 1
#include<iostream>
#include<string>
#include<vector>
#include<algorithm>
using namespace std;class fruit
{
public:fruit(const string& name,double price,int evaluate):_name(name),_price(price),_evaluate(evaluate){}string _name;double _price; // 价格int _evaluate; // 评价
};class ComparePriceLess
{
public:bool operator()(const fruit& f1, const fruit& f2){return f1._price < f2._price;}
};class ComparePriceGreater
{
public:bool operator()(const fruit& f1, const fruit& f2){return f1._price > f2._price;}
};void test1()
{vector<fruit> v{ {"苹果",3.5,9},{"香蕉",6,8},{"桃子",3.3,10} };sort(v.begin(), v.end(), ComparePriceLess());for (auto& e : v){cout << e._name << endl;}cout << "-----------------------" << endl;sort(v.begin(), v.end(), ComparePriceGreater());for (auto& e : v){cout << e._name << endl;}
}void test2()
{vector<fruit> v{ {"苹果",3.5,9},{"香蕉",6,8},{"桃子",3.3,10} };sort(v.begin(), v.end(), [](const fruit& f1, const fruit& f2) {return f1._price < f2._price; });for (auto& e : v){cout << e._name << endl;}cout << "-----------------------" << endl;sort(v.begin(), v.end(), [](const fruit& f1, const fruit& f2) {return f1._price > f2._price; });for (auto& e : v){cout << e._name << endl;}
}
int main()
{//test1();test2();
}简洁性:
lambda表达式具有非常简洁的语法,避免了为每种排序条件单独定义一个类或函数对象。你可以直接在
std::sort中内联定义比较逻辑,代码更加紧凑和易于理解。
对比:
在
test1中,ComparePriceLess和ComparePriceGreater是两个类,它们的实现相对较长,每次需要创建一个类对象来传递给std::sort。在
test2中,lambda表达式可以直接在排序函数中使用,不需要定义额外的类,只需简单的语法[](const fruit& f1, const fruit& f2) {...}。
lambda 表达式的语法
[ 捕获列表 ] (函数参数) mutable → 返回值类型 { 函数体 }
对于lambda表达式的理解:
整体的理解
lambda 表达式的返回值是一个可调用的对象,举个例子:
[](int x,int y)mutable->int {return x + y;}(1,2)可以将 lambda 看作是一个临时的、匿名的函数对象。构造时,lambda 会创建一个可调用对象,该对象的成员方法是定义在 {} 中的操作。当你调用它时,实际执行的就是这些方法。
上面这种写法还是比较抽象不好看,换一种写法直接就焕然大悟了
auto add = [](int x,int y)mutable->int {return x + y;};
add(1,2);捕获列表
捕捉列表,该列表总是出现在lambda函数的开始位置,编译器根据[]来 判断接下来的代码是否为lambda函数,捕捉列表能够捕捉上下文中的变量供lambda 函数使用。
一般情况下是不需要进行使用捕获列表的,但是使用捕获列表可以增加lambda表达式的灵活性。
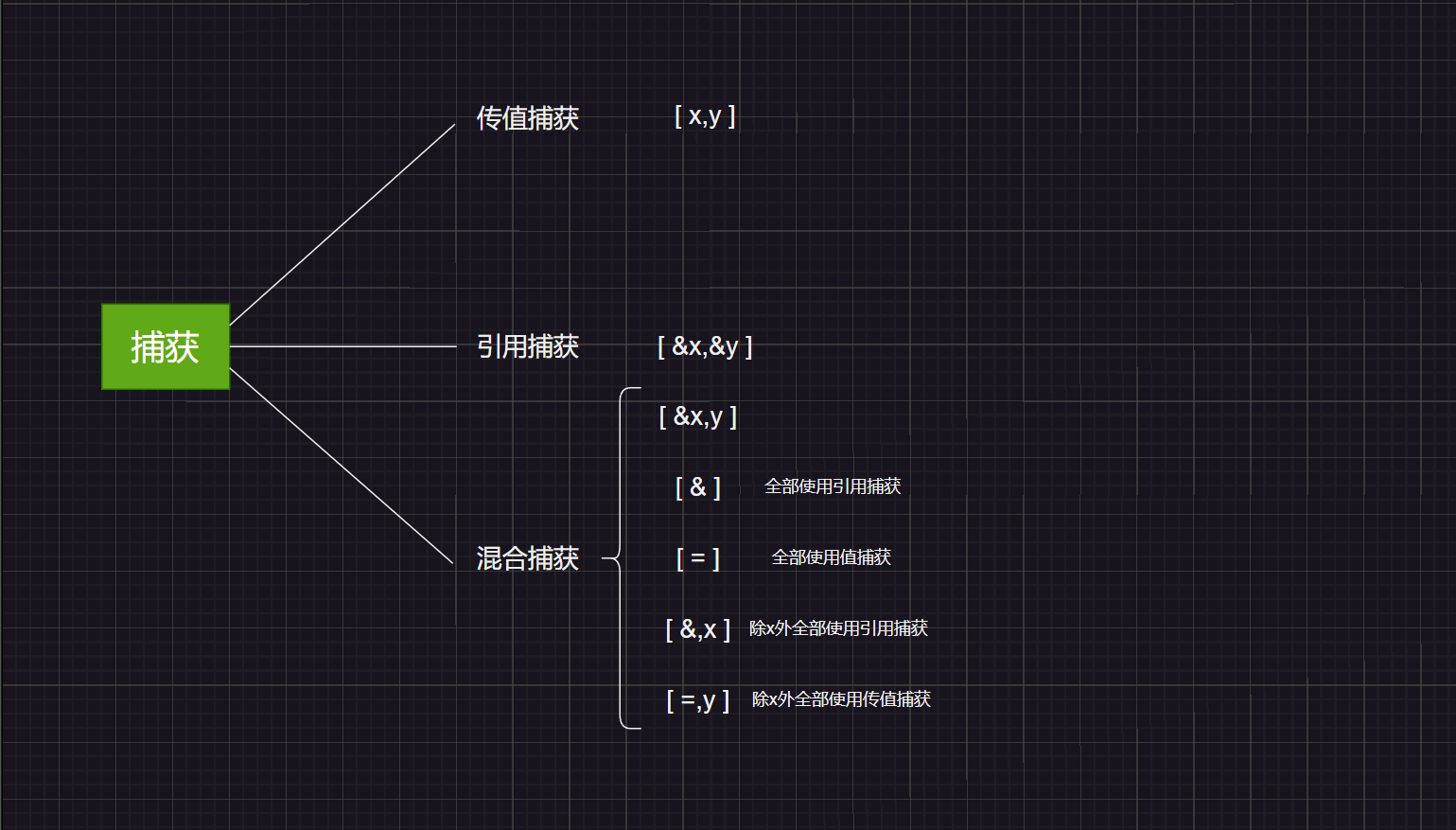
对于捕获列表的理解
捕获列表最浅层的理解就是可以通过捕捕获列表进行避免参数的显示传递
那么什么情况下会出现不能通过显示传递参数来进行替代lambda的值捕获呢
1. 在线程、任务、异步执行时
你无法传参数给线程体函数,只能让 lambda 把外部变量捕获进去。
#include <iostream>
#include <thread>void launch_worker() {int counter = 0;std::thread t([&counter]() {for (int i = 0; i < 10; ++i) {++counter;}});t.join();std::cout << "Counter: " << counter << std::endl;
}
你不能这样写:
❌ 错误:std::thread 的函数体签名固定,不能多加参数 std::thread t(worker_function, counter);
除非你封装一堆额外结构体或函数对象,lambda 简化了这些操作。
2. 成员函数中访问成员变量
你想传一个带上下文的函数给某个接口,而这个函数需要访问成员变量。
class A {int threshold = 5;
public:void process(const std::vector<int>& v) {auto f = [this](int x) { return x > threshold; };auto it = std::find_if(v.begin(), v.end(), f);if (it != v.end()) std::cout << "Found: " << *it << std::endl;}
};
你不能这样改:
auto f = isGreaterThanThreshold;
因为 isGreaterThanThreshold 是成员函数,不能作为普通函数指针直接传入,除非你自己额外绑定 this,代码就很繁琐。
3. 状态封装并延迟执行
比如你想封装当前上下文的数据,稍后再执行。
std::function<void()> task;{int x = 42;task = [x]() {std::cout << "Delayed value: " << x << std::endl;};
}
// 即使 x 已经超出作用域,捕获值仍然保留
task();
你无法通过参数传递 x,因为定义 task 时你并不知道什么时候执行它。
对于剩下部分的说明
参数列表。与普通函数的参数列表一致,如果不需要参数传递,则可以 连同()一起省略
mutable:默认情况下,lambda函数总是一个const函数,mutable可以取消其常量 性。使用该修饰符时,参数列表不可省略(即使参数为空)。
->returntype:返回值类型。用追踪返回类型形式声明函数的返回值类型,没有返回 值时此部分可省略。返回值类型明确情况下,也可省略,由编译器对返回类型进行推 导。
{statement}:函数体。在该函数体内,除了可以使用其参数外,还可以使用所有捕获 到的变量。
注意:lambda表达式之间不能相互赋值,即使看起来类型相同
lambda底层
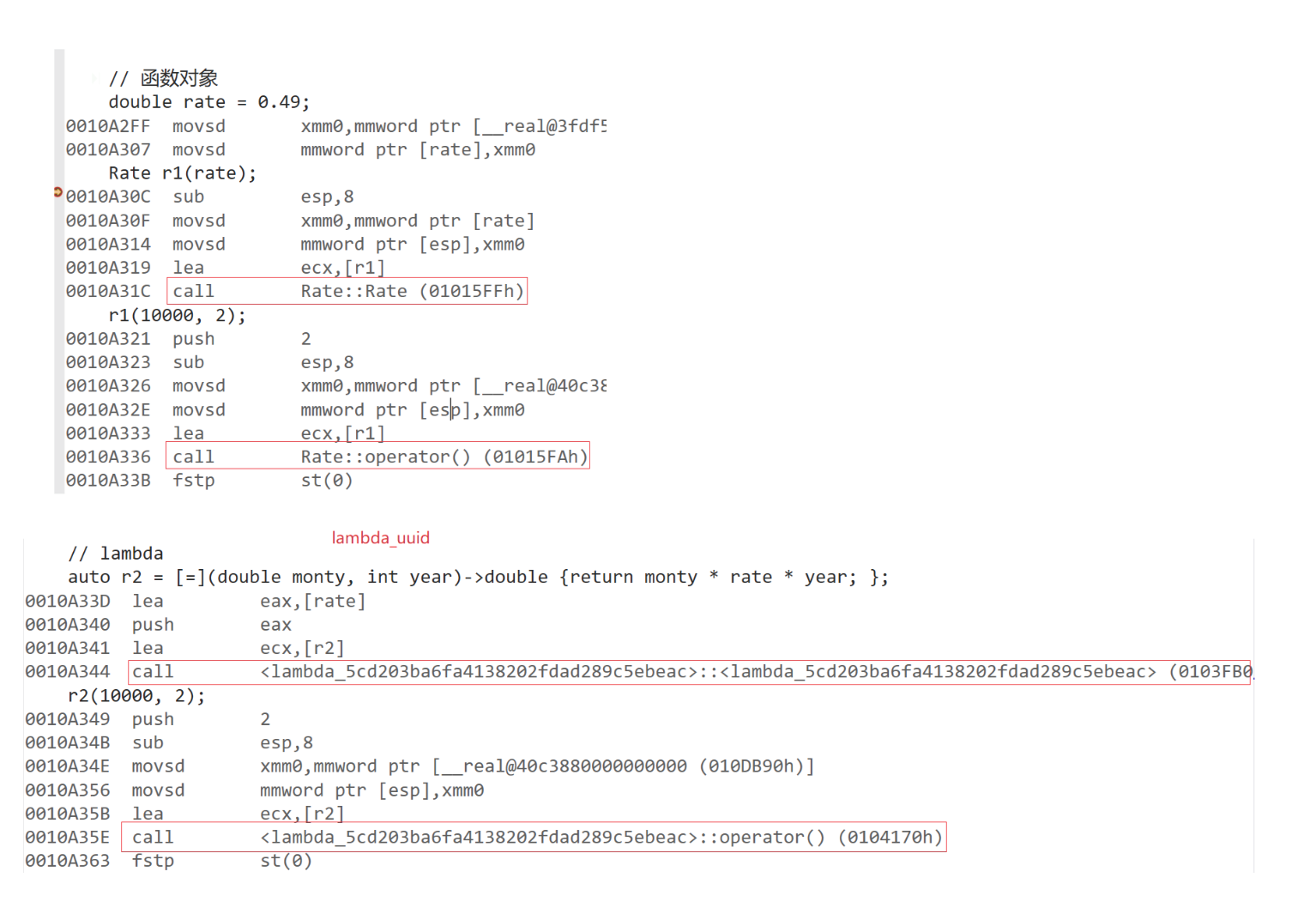
对于编译器来说,其实没有什么lambda,完全就是按照函数对象的方式处理的,即:如 果定义了一个lambda表达式,编译器会自动生成一个类,在该类中重载了operator()。
那为什么成员函数只有1字节呢??
class __AnonymousLambda {
public:void operator()() const { /* 生成的代码 */ }// 无成员变量 => 空类
};线程库
Linux下的线程库和window下的线程库是不同的,在C++98种我们要进行让编写的程序在不同的系统下都能跑通必须要进行使用条件编译,让程序在不同的系统下使用不同的线程库
C++11种线程库的到来将这种情况直接由C++种的thread库来进行实现,从而避免了手动的实现,实现了跨平台性。
| 功能 | C++11 标准库组件 | 替代的原生 API |
|---|---|---|
| 线程创建/等待 | std::thread | pthread_create / CreateThread |
| 互斥锁 | std::mutex、std::lock_guard | pthread_mutex_t / CRITICAL_SECTION |
| 条件变量 | std::condition_variable | pthread_cond_t / CONDITION_VARIABLE |
| 异步任务 | std::async、std::future | 需手动封装线程池或回调 |
构造函数
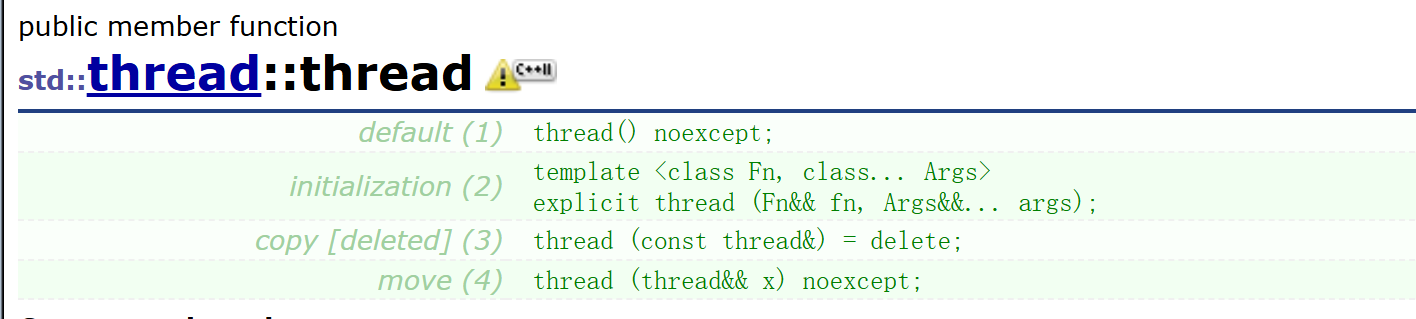
注意:thread 构造函数是不支持拷贝构造的。
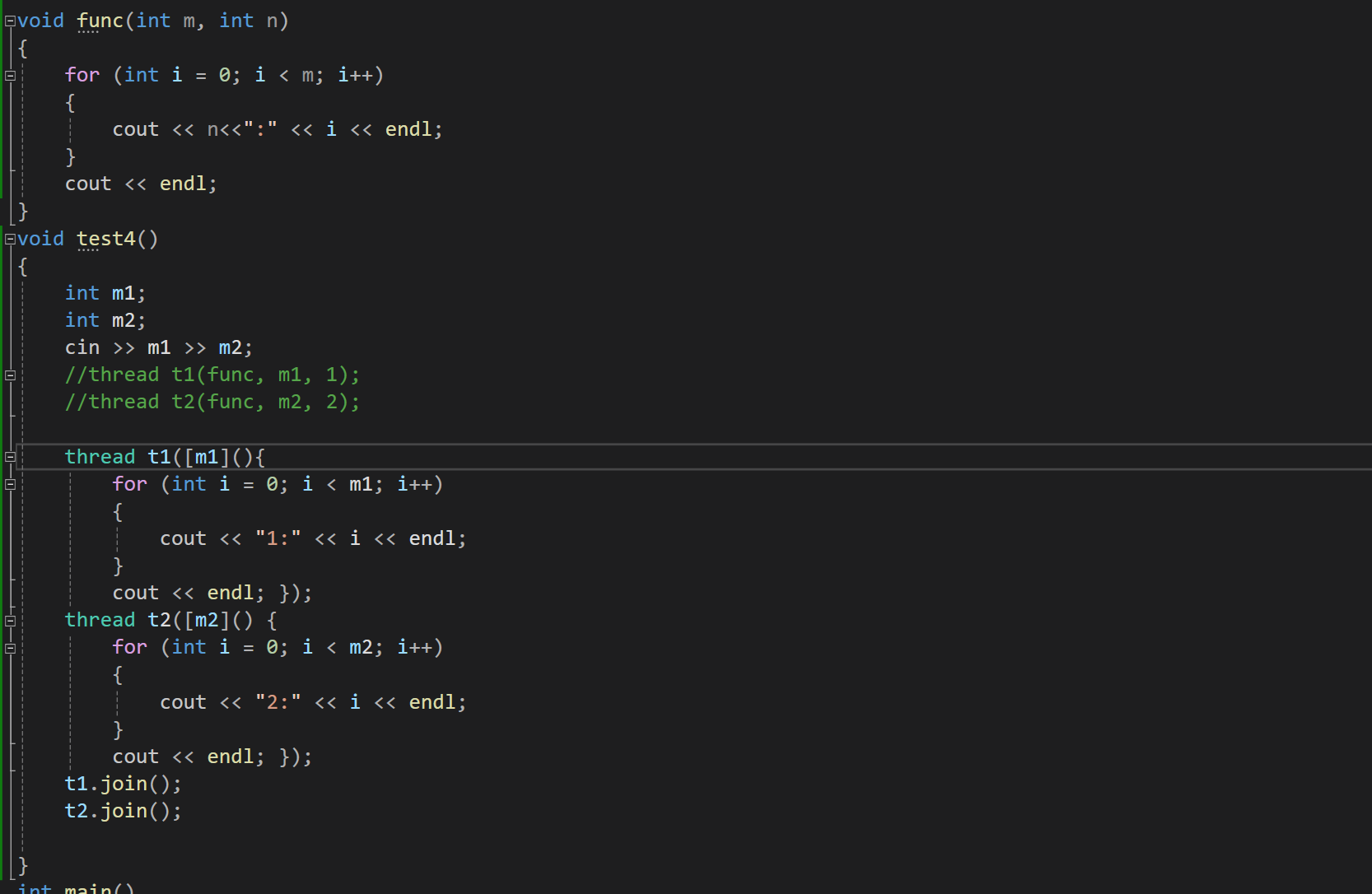
线程和lambda 进行联动也是非常的爽的。
获取线程ID
std::this_thread::get_id()
所属命名空间:
std::this_thread(定义在<thread>头文件中)。调用方式:直接调用,不需要
thread对象。作用:返回 当前执行线程 的 ID(即调用该函数的线程的 ID)。
典型用途:
在某个线程内部获取自己的线程 ID。
用于日志记录、调试或线程识别。
std::thread::get_id()
所属类:
std::thread的成员函数(定义在<thread>头文件中)。调用方式:必须通过
thread对象调用。作用:返回 该
thread对象管理的线程 的 ID。如果
thread对象 未关联任何线程(如默认构造或已join()/detach()),返回std::thread::id()(表示无效 ID)。
典型用途:
获取某个特定线程的 ID(例如,主线程查询子线程的 ID)。
检查线程是否有效(
if (t.get_id() != std::thread::id()))。
无锁编程

其实简简单单的 ++ 操作在汇编层面都是如上所示的三条指令,在多线程条件下如果不进行加锁就容易出现数据不一致的问题,虽然通过锁可以进行解决这种数据不一致的问题,但是频繁的加锁解锁是非常消耗性能的,有没有不使用锁但是可以确保数据不一致的问题呢?
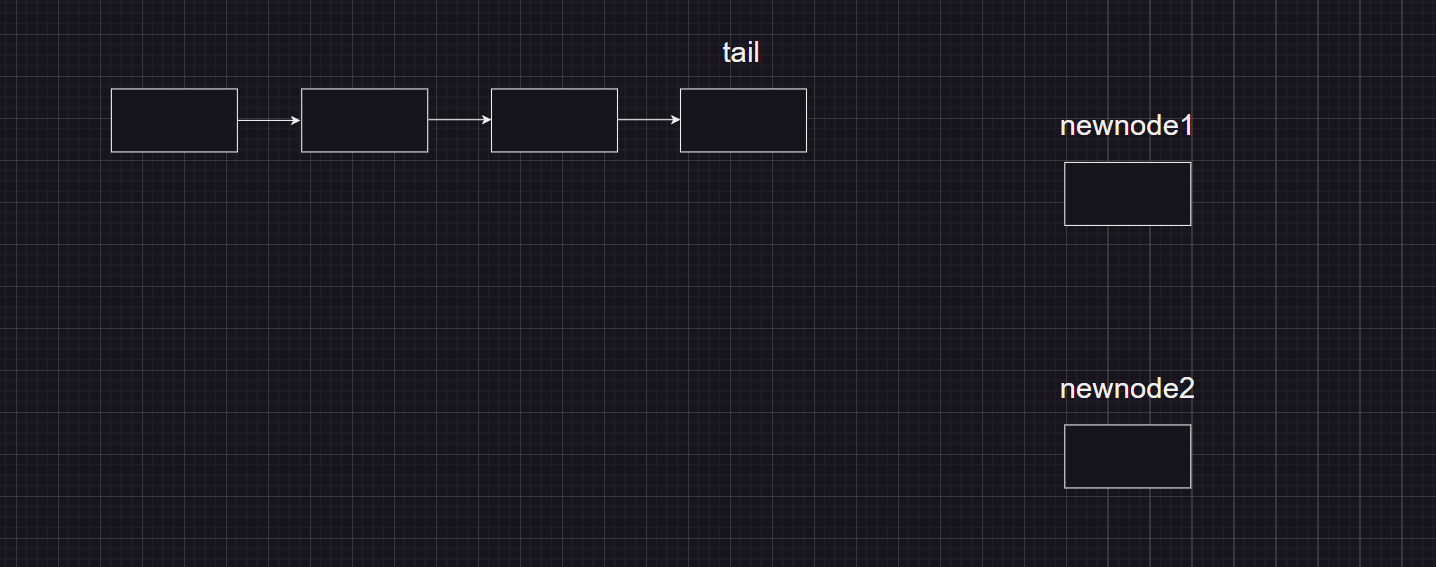
其实通过队列就可以进行实现无锁编程,具体的原理如下:
当线程在进行执行任务的时候先将任务进行加载到队列中,只有当任务进行执行完毕后,才进行将队列的尾指针进行更新,当线程1在进行执行任务时,线程2也想进行执行时发现队列的尾指针的next不为空,则需要进行等待。
#include <atomic>
#include <memory>template<typename T>
class LockFreeQueue {
private:struct Node {std::shared_ptr<T> data;std::atomic<Node*> next;Node(T val) : data(std::make_shared<T>(val)), next(nullptr) {}};std::atomic<Node*> head;std::atomic<Node*> tail;public:LockFreeQueue() : head(new Node(T{})), tail(head.load()) {}void push(T val) {Node* new_node = new Node(val);Node* current_tail;do {current_tail = tail.load();Node* tail_next = current_tail->next.load();if (tail_next != nullptr) {// 帮助其他线程推进 tailtail.compare_exchange_weak(current_tail, tail_next);}} while (!current_tail->next.compare_exchange_weak(nullptr, new_node));tail.compare_exchange_weak(current_tail, new_node);}std::shared_ptr<T> pop() {Node* current_head;Node* current_tail;std::shared_ptr<T> res;do {current_head = head.load();current_tail = tail.load();if (current_head->next.load() == nullptr) {return nullptr; // 队列为空}res = current_head->next.load()->data;} while (!head.compare_exchange_weak(current_head, current_head->next.load()));delete current_head;return res;}
};相对时间

绝对时间

| 特性 | sleep_until(绝对时间) | sleep_for(相对时间) |
|---|---|---|
| 参数类型 | std::chrono::time_point | std::chrono::duration |
| 语义 | "休眠直到 时钟到达某个时间点" | "休眠 指定的时长" |
| 示例 | sleep_until(now + 5s)(目标时间点) | sleep_for(5s)(固定 5 秒) |
| 受时钟调整影响 | 是(系统时间修改会影响实际休眠时长) | 否(始终休眠指定时长) |