OpenVLA: 论文阅读 -- 开源视觉-语言-行动模型
更多内容:XiaoJ的知识星球
目录
- OpenVLA:开源视觉-语言-行动模型
- 1. 介绍
- 2. 相关工作
- 1)视觉条件语言模型(Visually-Conditioned Language Models)
- 2)通用型机器人策略(Generalist Robot Policies)
- 3)视觉-语言-行动模型(Vision-Language-Action Models)
- 3. OpenVLA 模型
- 1)视觉语言模型VLM
- 2)OpenVLA 训练流程
- 3)训练数据
- 4)OpenVLA 设计决策
- (1)VLM主干模型
- (2)图像分辨率
- (3)微调视觉编码器
- (4)训练轮数(Training Epochs)
- (5)学习率(Learning Rate)
- 5)训练与推理基础设施
- 4. OpenVLA 代码库
- 5. 实验
- 1)多机器人平台上直接评估
- (1)机器人设置与任务
- (2)对比
- 2)数据高效地适应新的机器人设置
- (1)机器人设置与任务
- (2)对比方法
- 3)参数高效微调
- 4)通过量化实现内存高效的推理
- 6. 讨论与局限
.
OpenVLA:开源视觉-语言-行动模型
.
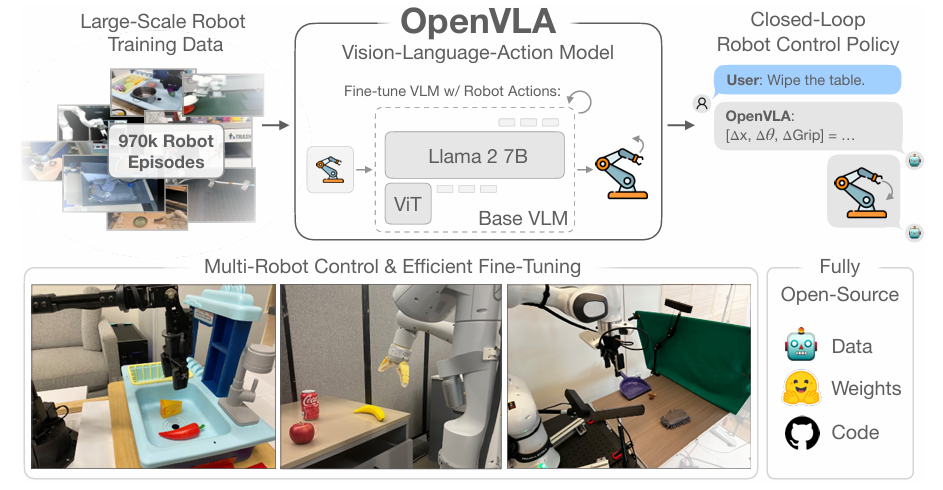
图1:提出OpenVLA,7B的开源视觉-语言-动作模型(VLA)
.
摘要
在互联网规模视觉语言数据与多样化机器人演示相结合的大型策略预训练,有潜力改变教机器人新技能的方式:无需从零开始训练新行为,而是通过对这类视觉-语言-动作(VLA)模型进行微调,获得用于视觉运动控制的鲁棒且可泛化的策略。
然而,VLA模型广泛应用面临挑战:
-
现有VLA模型大多闭源;
-
先前研究缺乏对VLA模型高效微调方法的探索,以适应新任务。
为此,本文推出OpenVLA:7B开源VLA模型,基于Llama 2和融合DINOv2与SigLIP的视觉编码器。
-
OpenVLA凭借增强的数据多样性和新颖模型结构,在29项通用操作任务上超越闭源RT-2-X模型16.5%成功率,参数量仅为其七分之一。
-
OpenVLA支持高效微调,在多物体多任务场景中泛化性强,语言理解能力优,性能上比从头训练的先进模仿学习方法(如Diffusion Policy)高出20.4%。
-
OpenVLA通过LoRA方法,可在消费级GPU上高效微调,并通过量化技术实现高效部署。
本文开源了模型 checkpoints、微调代码、基于 PyTorch 的代码库,并内置支持在 Open X-Embodiment 数据集上大规模训练 VLA。
.
1. 介绍
现有机器人操作策略的主要弱点是无法泛化至训练数据集之外的场景。相比之下,CLIP、SigLIP、Llama 2等视觉语言基础模型得益于互联网规模的预训练,具备更强的泛化能力。由此,利用现成的视觉语言基础模型作为核心组件,构建可泛化至新物体、场景和任务的机器人策略。
已有探索将预训练语言和视觉语言模型用于机器人表征学习,或作为模块化系统组件用于任务规划与执行。更进一步,直接用于训练视觉-语言-动作模型(VLA)以实现控制。VLA通过微调基于互联网规模数据训练的视觉语言模型(如PaLI),使其输出机器人动作,显著提升了对新物体和新任务的泛化能力。
然而,现有VLA的广泛应用仍受限于两点:
-
模型闭源,架构、训练方法和数据构成不透明;
-
缺乏在通用硬件(如消费级GPU)上部署和适配新机器人、环境与任务的有效方法。
为此推出OpenVLA,树立了通用机器人操作策略的新标杆。
.
2. 相关工作
1)视觉条件语言模型(Visually-Conditioned Language Models)
视觉条件语言模型(VLM)利用互联网规模数据,根据图像和语言提示生成自然语言,已广泛应用于视觉问答、目标定位等任务。其核心进展在于将预训练视觉编码器(如CLIP、SigLIP、DINOv2)与语言模型(如Llama、PaLM)结合,构建强大的多模态系统。
早期方法多采用复杂的跨模态注意力结构,而近期开源VLM(如Kosmos、Flamingo、PaLI)趋向“图像块即token”的简化架构,将视觉Transformer的图像块特征视为语言模型的输入token,便于复用大规模语言模型训练工具。
OpenVLA中采用此类架构,以VLM为预训练骨干,其融合DINOv2的低层级的空间信息(low-level spatial information)与SigLIP的高层级的语义信息(higher-level semantics),支持多分辨率输入,增强视觉泛化能力,为VLA训练奠定基础。
.
2)通用型机器人策略(Generalist Robot Policies)
近年来,机器人领域趋向于在大规模、多样化的机器人数据集上训练多任务“通用型”策略,覆盖多种机器人形态。例如Octo训练出可直接控制多种机器人的通用策略,并支持灵活微调。
与这类方法的关键区别在于,OpenVLA采用更端到端的架构:不额外拼接从零训练的模块,而是直接将机器人动作视为语言模型词汇中的token,对预训练视觉语言模型(VLM)进行微调以输出动作。实验表明,这一简单且可扩展的范式显著提升了性能与泛化能力,优于以往通用策略。
.
3)视觉-语言-行动模型(Vision-Language-Action Models)
已有研究探索将视觉语言模型(VLM)用于机器人,如视觉表征、目标检测、高层规划或反馈生成。部分工作将其融入端到端控制策略,但常依赖特定架构或标定相机,限制了通用性。
近期一些研究与作者思路相近,直接微调大型VLM以预测机器人动作,这类模型称为视觉-语言-动作模型(VLA),将动作融入VLM主干。其优势在于:
-
利用互联网规模数据完成视觉与语言组件的预对齐;
-
通用架构便于复用现有VLM训练基础设施,轻松扩展至十亿参数模型;
-
使机器人可直接受益于VLM的快速进展。
然而,现有VLA研究多局限于单一机器人或仿真环境,泛化性不足,或为闭源模型,缺乏对新机器人配置的高效微调支持。
最接近的是RT-2-X在Open X-Embodiment数据集上训练了550亿参数的VLA模型,实现了当前最优的通用操作性能。相比之下,OpenVLA与RT-2-X的关键不同:
-
OpenVLA采用更强的开源VLM主干和更丰富的机器人预训练数据,在模型规模小一个数量级的情况下性能超越RT-2-X;
-
OpenVLA在新场景下有微调能力,而RT-2-X未探讨此问题;
-
首次验证了现代参数高效微调(如LoRA)和量化技术在VLA上的有效性;
-
是首个开源的通用VLA模型,支持未来在训练方法、数据组合、目标函数和推理等方面的开放研究。
.
3. OpenVLA 模型
OpenVLA是一个基于Open X-Embodiment数据集97万条机器人演示训练的70亿参数视觉-语言-动作模型(VLA)。当前VLA模型在主干网络、数据集和超参数等最佳实践方面仍存在诸多未充分探索的问题。
本文详细介绍了OpenVLA的构建方法与关键经验:
-
首先简述作为其主干的现代视觉语言模型(VLM);
-
然后介绍基础训练方案与数据集);
-
讨论关键设计选择;
-
最后,说明训练与推理所用的基础设施。
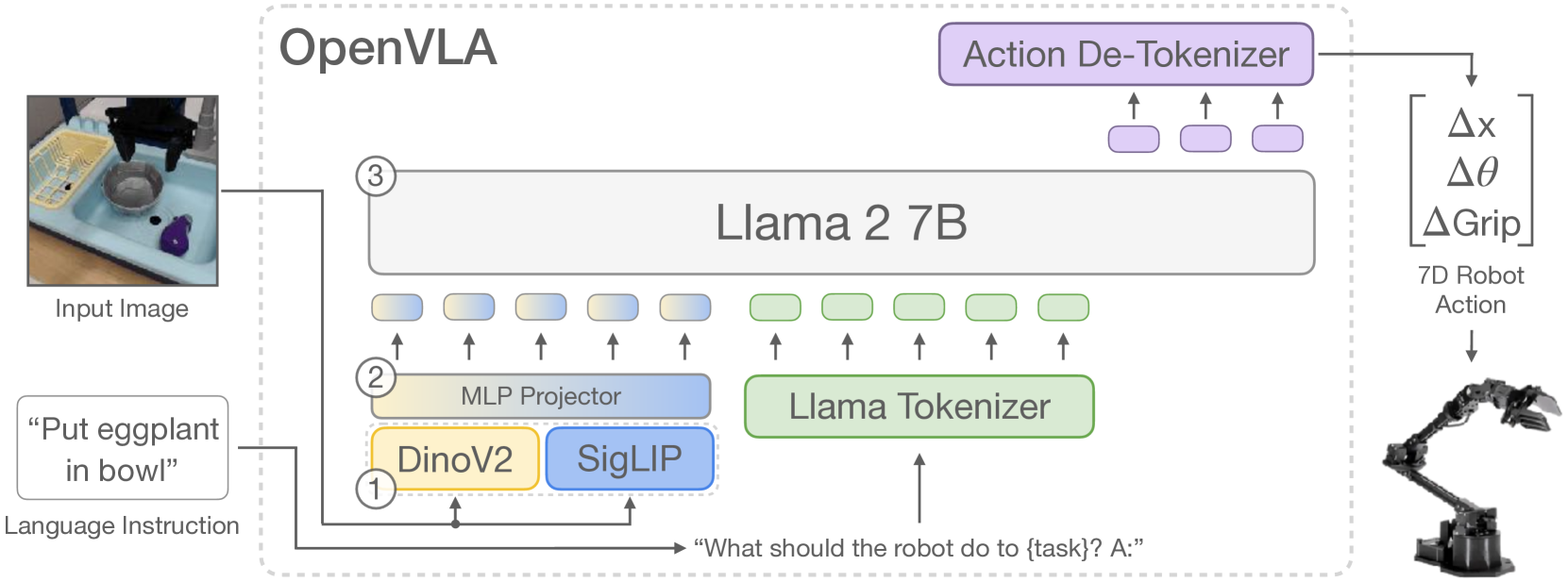
图2:OpenVLA 模型架构
.
1)视觉语言模型VLM
大多数最新视觉语言模型(VLM)的架构由三个主要部分组成(见图2):
-
视觉编码器,将图像输入转换为多个“图像块嵌入(image patch embeddings)”;
-
投影器,将视觉编码器的输出嵌入映射到语言模型的输入空间;
-
大语言模型(LLM)主干。
训练时,模型在来自互联网的配对或交错的视觉-语言数据上,以预测下一个文本token(即语言模型能识别的最小文本单位)为目标进行端到端训练。
OpenVLA基于Prismatic-7B视觉语言模型(VLM)构建。Prismatic包含:
-
视觉编码器:6亿参数的DinoV2+SigLIP 双分支视觉编码器;
-
投影器:两层MLP;
-
LLM主干:Llama2 7B语言模型主干。
其显著特点是,采用SigLIP和DINOv2模型双分支视觉编码器:输入图像块分别通过两个编码器处理,输出的特征向量在通道维度上拼接。相比常用的CLIP或单一SigLIP编码器,添加 DinoV2 特征有助于提升空间推理能力。
.
2)OpenVLA 训练流程
为训练OpenVLA,对预训练的Prismatic-7B进行微调,使其能预测机器人动作。具体来说,将动作预测问题转化为"视觉-语言"任务:输入一张观察图和一条语言指令,模型输出对应的机器人动作序列。
为让语言模型能处理这些动作,将机器人动作转换为离散的token。对每个动作维度单独进行离散化处理:
-
将一个N维机器人动作转换为N个范围在[0, 255]的离散整数。
-
区间范围根据训练数据中该动作,排除最小的1%和最大的1%的极端值。可有效避免异常动作数据导致的区间过宽问题,从而保证动作预测的精度。
OpenVLA采用的语言模型Llama的分词器仅保留了100个“特殊token”用于微调时新增的token,不足以容纳所需的256个动作token。为此沿用前人方案:直接用动作token覆盖Llama分词器词表中使用频率最低的末尾256个token。
动作序列转化为token后,OpenVLA采用标准的下一token预测目标进行训练,仅对动作token部分计算交叉熵损失。
.
3)训练数据
构建OpenVLA训练数据的目标是覆盖多样化的机器人形态、场景和任务,以实现开箱即用的多机器人控制与高效微调。基于Open X-Embodiment(OpenX)数据集,整合了70多个、超200万条轨迹的机器人数据。为提升训练可行性,进行了多步数据整理。
整理目标包括:
-
(1)确保所有训练数据集的输入输出空间的一致性;
-
(2)平衡最终数据中机器人形态、任务和场景的分布。
针对(1)仅保留含第三人称视角相机且使用单臂末端执行器控制的操作数据。针对(2)采用Octo的数据混合权重,对多样性高的数据集增权,低多样性的降权或剔除。
此外,还尝试加入Octo发布后新增的数据集(如DROID),但混合权重设为保守的10%。训练中发现其动作token准确率始终偏低,表明需更大模型或权重才能充分学习。为避免影响最终性能,我们在最后三分之一训练阶段移除了DROID。
.
4)OpenVLA 设计决策
开发OpenVLA时,先在小规模实验中探索了多种设计选择,再启动最终的大规模训练。具体而言,初期实验使用BridgeData V2而非完整的OpenX混合数据集进行训练与评估,以加快迭代速度并降低计算成本。
(1)VLM主干模型
VLM主干模型选择。最初测试了多种VLM主干,包括IDEFICS-1、LLaVA和 Prismatic,用于机器人动作预测。
实验发现,在单物体任务中,LLaVA与IDEFICS-1表现相近,但在涉及多物体且需根据语言指令操作特定物体的任务中,LLaVA的语言对齐能力更强,在BridgeData V2水槽环境的五个语言接地任务上,绝对成功率比IDEFICS-1高35%。
而微调后的Prismatic VLM进一步提升性能,在单物体和多物体任务上均优于LLaVA约10%。作者归因于其融合SigLIP与DINOv2的主干增强了空间推理能力。此外,Prismatic还具备模块化、易用的代码库,因此最终选用Prismatic作为OpenVLA的主干模型。
(2)图像分辨率
输入图像的分辨率显著影响VLA训练的计算开销:更高分辨率会产生更多图像块token,导致上下文长度增加,训练计算量呈平方级上升。
作者对比了输入分辨率为224×224和384×384的VLA模型,发现性能无显著差异,但后者训练耗时高出3倍。因此,OpenVLA最终采用224×224的分辨率。
需注意,在多数VLM基准上,更高分辨率通常能提升性能,但在当前VLA任务中尚未观察到此趋势。
(3)微调视觉编码器
以往VLM研究发现,训练时冻结视觉编码器通常能获得更好性能,因其有助于保留互联网预训练学到的鲁棒特征。然而,作者发现对VLA训练而言,微调视觉编码器至关重要。作者推测,预训练的视觉主干可能未能充分捕捉场景中关键区域的细粒度空间细节,难以支持精确的机器人控制。
(4)训练轮数(Training Epochs)
典型的LLM或VLM训练通常仅完成1到2个epoch。相比之下,作者发现VLA训练需要对数据集进行更多轮迭代,机器人实际性能会持续提升,直到动作token准确率超过95%。最终模型共完成了27个epoch的训练。
(5)学习率(Learning Rate)
对VLA训练的学习率进行了多数量级的搜索,发现使用固定的2e-5学习率效果最佳(与VLM预训练所用学习率相同)。学习率预热(warmup)未发现带来明显收益。
.
5)训练与推理基础设施
最终的OpenVLA模型在64块A100 GPU集群上训练14天,总计消耗约 21,500 小时的 A100 计算资源,批量大小为2048。
推理时,OpenVLA在bfloat16精度下(未量化)占用约15GB GPU显存,在单块NVIDIA RTX 4090上运行速度约为6Hz(未使用编译、推测解码等加速技术)。通过量化可进一步降低推理内存占用,且不影响真实机器人任务性能。
为方便使用,作者实现了一个远程VLA推理服务器,支持将动作预测实时流式传输至机器人,无需本地配备高性能计算设备。该远程推理方案将随开源代码一并发布。
.
4. OpenVLA 代码库
作者随模型一并发布了OpenVLA代码库——一个模块化的PyTorch代码库,用于训练视觉-语言-动作(VLA)模型(详见 https://openvla.github.io)。
该代码库可灵活扩展,支持从单GPU微调到多节点GPU集群上训练十亿参数级VLA模型,并集成了现代大模型训练技术,如自动混合精度(AMP,PyTorch)、FlashAttention和完全分片数据并行(FSDP,Zhao等)。
开箱即用,代码库原生支持在Open X数据集上训练,集成HuggingFace的AutoModel类,并支持LoRA微调和量化模型推理。
.
5. 实验
本实验旨在评估OpenVLA作为通用多机器人控制策略的开箱即用能力,以及其作为新任务微调初始化的潜力。具体围绕以下问题展开:
-
在多种机器人和不同泛化场景下,OpenVLA相较于以往通用机器人策略表现如何?
-
OpenVLA能否有效适配新机器人设置和任务?与当前最先进的数据高效模仿学习方法相比如何?
-
能否通过参数高效微调和模型量化降低OpenVLA的训练与推理计算成本,使其更加易于使用,以及如何在性能与计算开销之间取得权衡?
.
1)多机器人平台上直接评估
(1)机器人设置与任务
作者在两种机器人平台上评估OpenVLA的“开箱即用”性能:
-
一是BridgeData V2的WidowX机械臂(见图1左);
-
二是RT-1和RT-2中使用的移动操作机器人“Google机器人”(见图1中)。
这两种平台被广泛用于评估通用机器人策略。
作者为每个环境设计了全面的评估任务,覆盖多种泛化维度:
-
视觉泛化(visual generalization):测试机器人在未见过的背景、干扰物体、物体颜色/外观变化等情况下的表现;
-
运动泛化(motion generalization):评估机器人是否能适应未见过的物体位置/方向;
-
物理泛化(physical generalization):考察机器人如何处理不同尺寸和形状的物体;
-
语义泛化(semantic generalization):测试机器人对未见过的目标物体、指令以及来自互联网的新概念的理解能力。
此外,在包含多个物体的场景中,作者测试模型的语言理解能力,即是否能根据用户指令操作正确的目标物体。
图3和图4底行分别展示了BridgeData V2和Google机器人任务的示例。
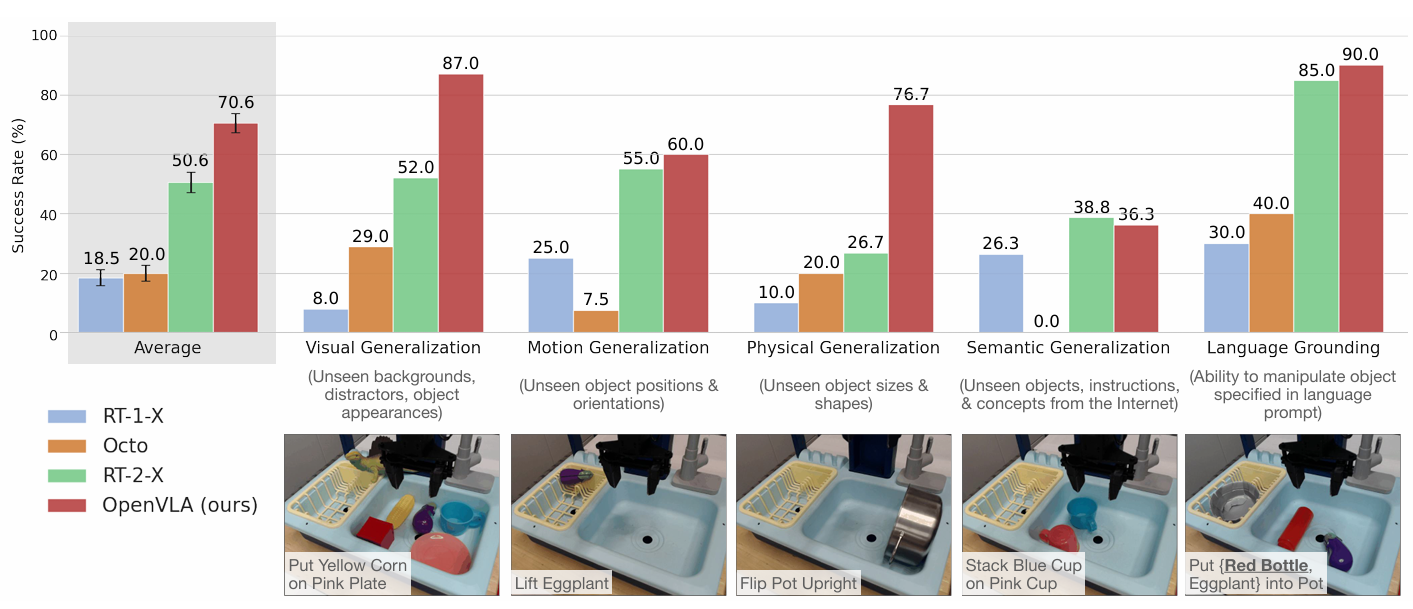
图3:BridgeData V2 WidowX机器人评估任务与结果。
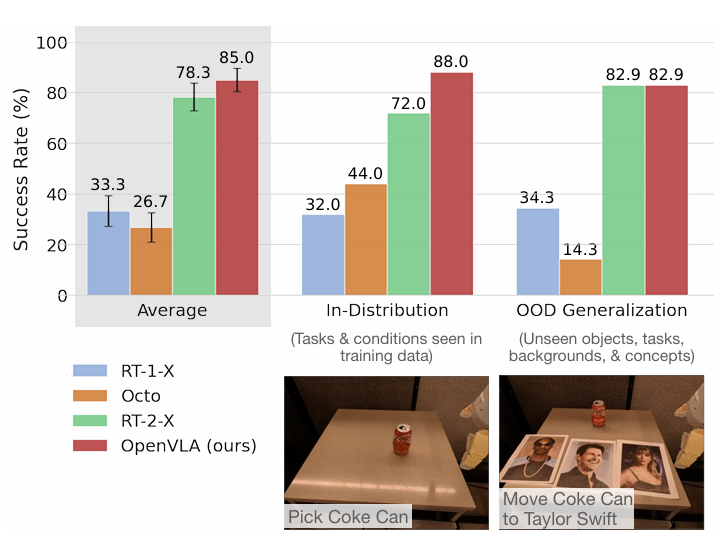
图4:Google机器人评估结果。
整体评估共进行230次实验:BridgeData V2环境下17个任务各10次(共170次),Google机器人环境下12个任务各5次(共60次)。
(2)对比
OpenVLA的性能与三种已有的通用操作策略进行比较:RT-1-X、RT-2-X和Octo。
-
RT-1-X(3500万参数)和Octo(9300万参数)是基于OpenX数据集子集从零开始训练的Transformer策略
-
其中Octo是当前最先进的开源操作策略。
-
RT-2-X(550亿参数)是当前最先进的闭源视觉-语言-动作(VLA)模型,其基于互联网预训练的视觉与语言主干网络构建。
结果总结于图3(BridgeData V2评估)和图4(Google机器人评估)。RT-1-X和Octo在测试任务中表现不佳,常无法操作正确目标,尤其在存在干扰物时,有时甚至导致机械臂无目的地挥动。
请注意,这里评估测试的泛化程度甚至比之前那些工作中执行的评估更大,以挑战互联网预训练的 VLA 模型。因此,预计没有互联网预训练的模型性能会降低。RT-2-X 的性能明显优于 RT-1-X 和 Octo,展示了大型预训练 VLM 对机器人技术的优势。
值得注意的是:
-
尽管OpenVLA的参数量(7B)仅为RT-2-X(55B)的七分之一,其在Google机器人上的表现与RT-2-X相当;
-
OpenVLA在BridgeData V2上的表现则显著优于后者。
-
定性分析显示,与其它模型相比,RT-2-X和OpenVLA行为更为鲁棒。
RT-2-X在语义泛化任务上有比OpenVLA更高的性能:这是意料之中的,因为它使用更大规模的互联网预训练数据,并与机器人动作数据和互联网预训练数据共同微调,以更好地保留预训练知识,而不是像 OpenVLA 那样仅根据机器人数据进行微调。
然而,在BridgeData V2和Google机器人的其他所有任务类别中,OpenVLA均达到与RT-2-X相当甚至更优的性能。这一优势主要归因于三点:
-
更大规模的训练数据:OpenVLA 训练数据集包含 97 万条轨迹,远多于 RT-2-X 的 35 万条轨迹;
-
更严格的数据清理:对训练数据进行了更仔细的筛选,例如,过滤掉了 Bridge 数据集中的全零动作;
-
更好的视觉编码器:OpenVLA 采用了融合型视觉编码器(fused vision encoder),结合了预训练的语义特征和空间特征,提升了模型的感知能力;
.
2)数据高效地适应新的机器人设置
如何有效微调VLA以适应新任务和新机器人配置仍鲜有探索,这对其广泛应用至关重要。本节将研究OpenVLA在真实世界中快速适配新机器人设置的能力。(仿真环境中的微调实验详见附录E。)
(1)机器人设置与任务
在实验中,测试了一种OpenVLA微调方案:在10~150条任务演示的小规模数据集上,对模型所有参数进行全量微调(见图5)。实验在两个Franka机器人平台上进行:
-
Franka-Tabletop:固定在桌面上的Franka Emika Panda 7自由度机械臂;
-
Franka-DROID:来自最新发布的DROID数据集的Franka机械臂,安装在可升降的站立式工作台上。
两个设置分别使用5Hz和15Hz的非阻塞控制器。选择Franka机械臂作为微调目标,因其在机器人学习社区中被广泛使用。采用不同控制频率的设置,旨在验证OpenVLA在多种应用场景中的适用性。
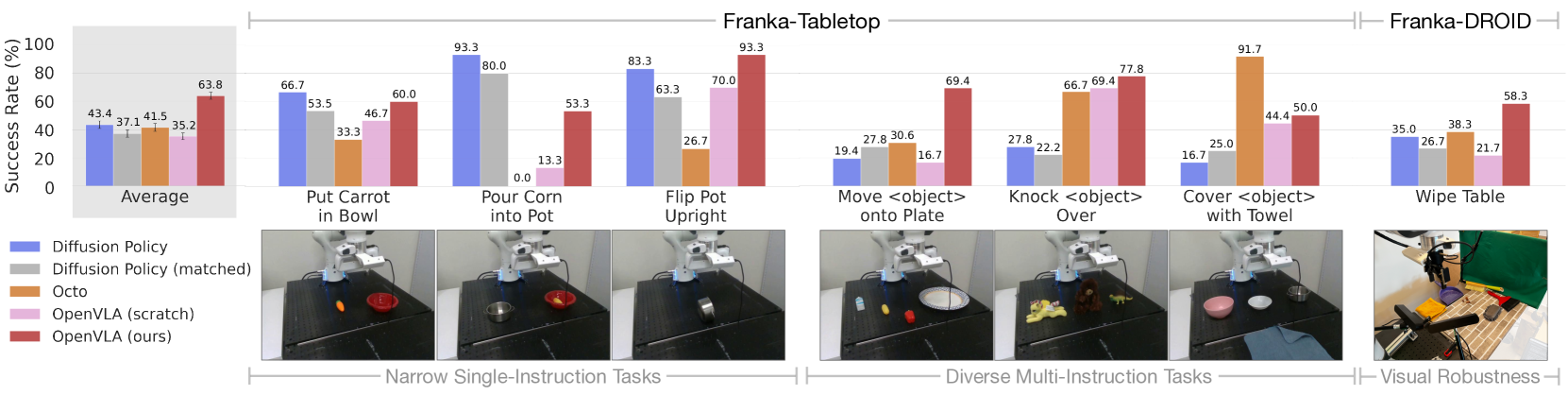
图5:适应新机器人设置。
(2)对比方法
实验将OpenVLA与以下方法进行比较:
-
Diffusion Policy:一种从零开始训练的最先进、数据高效的模仿学习方法;
-
Diffusion Policy (matched):即调整其输入输出格式以匹配OpenVLA的版本;
-
Octo(fine-tuned):目前支持微调的最佳通用策略,在目标数据集上对其进行微调;
-
OpenVLA(fine-tuned):在相同的目标数据集上对 OpenVLA 进行微调,结果模型仍然记作 OpenVLA;
-
OpenVLA (scratch):消融实验,直接在目标机器人上从零开始微调底层的 Prismatic VLM,而不是使用已经在 OpenX 预训练的 OpenVLA,以评估大规模机器人预训练的实际收益。
图5中结果表明:
-
两种版本的Diffusion Policy在单一指令的狭窄任务上,表现与通用策略Octo和OpenVLA相当甚至更优。
-
预训练模型在更多样化的微调任务上表现更佳,尤其是那些涉及多个物体并依赖语言条件的任务;
-
大规模 OpenX 预训练,使得 Octo 和 OpenVLA 在这些需要语言对齐的复杂任务中更具适应性(更强的泛化能力)。可以从 OpenVLA (scratch) 低于 OpenVLA(fine-tuned) 的看出。
总体而言,OpenVLA取得了最高的平均性能。值得注意的是,
-
大多数现有方法仅在单一指令或多样化多指令任务中表现良好,性能差异较大。
-
OpenVLA在所有测试中均达到至少50%成功率,表明其可作为模仿学习任务的强通用基线,尤其适用于涉及多样化语言指令的场景。
-
对于操作精度要求极高的狭窄任务,Diffusion Policy仍展现出更流畅、精确的动作轨迹。
未来引入动作分块(action chunking)和时序平滑等技术(如Diffusion Policy所采用)可能有助于提升OpenVLA的灵巧性,是值得探索的方向。
.
3)参数高效微调
本节将探索计算和参数效率更高的微调方法。具体地,实验比较了以下几种微调方法:
-
全量微调(Full fine-tuning):在微调过程中更新模型所有参数;
-
仅最后一层(Last layer only):仅微调OpenVLA Transformer主干的最后输出层和token嵌入矩阵;
-
冻结视觉编码器(Frozen vision):冻结视觉编码器,仅微调其余所有参数;
-
三明治微调(Sandwich fine-tuning):解冻视觉编码器、token嵌入矩阵和最后一层,仅微调这三部分;
-
LoRA(Low-Rank Adaptation):采用低秩适应技术,在模型所有线性层上应用,测试多个秩(r)值。
表1:参数高效微调评估。
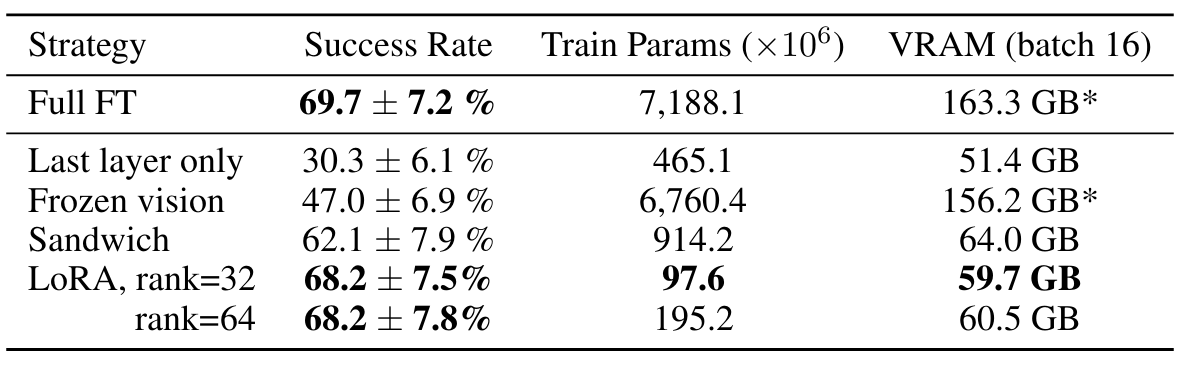
结果表明:
-
仅微调网络最后一层或冻结视觉编码器时,性能表现较差,表明对目标场景进行视觉特征的进一步适配至关重要。
-
三明治微调通过解冻视觉编码器提升了性能,同时因不微调完整的语言模型主干而降低了显存消耗。
-
LoRA在性能与显存占用间取得最佳平衡:仅微调1.4%参数即可超越三明治微调,并达到与全量微调相当的性能。
实验发现LoRA的秩(rank)对策略性能影响极小,因此推荐默认使用 r=32 。采用LoRA后,可在单块A100 GPU上10-15小时内完成新任务的微调,相比全量微调计算量减少8倍。
.
4)通过量化实现内存高效的推理
OpenVLA-7B 在推理时的显存占用比此前的开源通用模型(如 Octo,参数量 <100M)更高。默认以 bfloat16 精度存储和加载 OpenVLA,将显存占用减少一半使其能在 16GB GPU 上运行。
本节,将借鉴 LLM 推理中的量化方法,以更低的精度加载权重,但需要付出推理速度与精度降低的代价;具体地,实验在8个典型的BridgeData V2任务上评估了以8位和4位精度部署OpenVLA模型的效果。表2报告了显存占用和任务成功率;图6展示了在多种消费级和服务器级GPU上的可实现控制频率。
表2:量化推理的性能

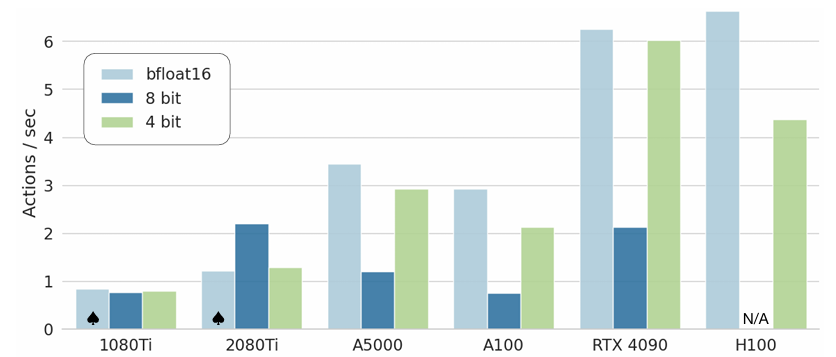
图6:各种GPU上OpenVLA推理速度
实验发现,8位量化因引入额外计算开销,导致多数GPU上推理速度变慢;而4位量化通过减少显存传输,抵消了量化开销,从而实现了更高的推理吞吐量。
由于推理速度下降,8位量化导致性能显著降低:在的A5000 GPU上,模型仅能以1.2Hz运行,相较于BridgeData V2任务中5Hz非阻塞控制器的训练数据,系统动态发生明显变化。
4位量化在显存占用不到一半的情况下,性能与bfloat16半精度推理相当,且在A5000上可达3Hz,更接近数据采集时的系统动态。
.
6. 讨论与局限
本文提出了OpenVLA,一个先进的开源视觉-语言-动作(VLA)模型,具备出色的跨机器人形态开箱即用控制能力,并可通过参数高效微调轻松适配新机器人系统。
然而,当前OpenVLA模型仍存在若干局限:
-
输入模态受限:目前仅支持单张图像观测。而真实机器人系统通常具备多样化的传感器输入(如多视角图像、本体感知数据、历史观测序列)。未来工作可探索支持多模态输入,并研究基于图文交错数据预训练的VLM,以实现更灵活的VLA微调。
-
推理速度不足:现有推理频率难以满足高频控制需求(如50Hz的ALOHA系统),限制了其在灵巧、双手机械臂等高动态任务中的应用。未来可通过动作分块(action chunking)或推测解码(speculative decoding)等技术提升吞吐量。
-
性能可靠性有待提升:尽管优于先前通用策略,但OpenVLA在多数任务上的成功率仍低于90%,尚未达到高可靠部署标准。
-
设计空间探索不足:受限于算力,许多关键问题尚未充分研究,例如:基础VLM模型规模对VLA性能的影响?机器人动作数据与互联网图文数据联合训练是否显著提升性能?何种视觉特征最适合VLA?我们期望OpenVLA模型与代码库的开源能推动社区共同探索这些问题。
.
声明:资源可能存在第三方来源,若有侵权请联系删除!