译 | 用于具有外生特征的时间序列预测模型TimeXer
文章出自:出自:TimeXer: Empowering Transformers for Time Series Forecasting with Exogenous Variables
本篇技术亮点在于结合自注意力和交叉注意力机制,既捕捉时间序列的内在变化,又融合外部影响因素,提高预测准确度。该方法特别适合受外部因素影响明显的时间序列预测,如电力需求、产品销量等。
商业应用场景包括节假日促销预测、电力负荷管理、气象影响下的能源调度等。例如,利用历史销售数据和节假日信息预测商品需求,帮助企业合理备货和安排促销活动。整体方法适合需要考虑外部环境变量的复杂预测任务。
文章目录
- 1 TimeXer 介绍
- 1.1 TimeXer 的架构
- 1.2 内源性特征嵌入
- 1.3 外源性特征嵌入
- 1.4 内源性特征的自注意力
- 1.5 外源性到内源性交叉注意力
- 1.6 最后步骤与输出预测
- 2 使用 TimeXer 进行预测案例
- 2.1 初始设置
- 2.2 训练每个模型
- 2.3 评估
- 3 结论
- 4 参考文献

照片由 Michael Payne 在 Unsplash 提供
虽然在Time-MoE、Moirai或TimeGPT等基础预测模型上投入了大量研究工作,但新的特定数据模型仍在积极开发和发布中。
最新提出的方法之一是 TimeXer,于2024年2月发表在论文TimeXer:Empowering Transformers for Time Series Forecasting with Exogenous Variables[1]中。
顾名思义,TimeXer 是一个基于 Transformer 的模型,就像 PatchTST 和 iTransformer 一样,也考虑了外生特性。因此,它不仅依赖于该序列的过去值,还依赖于可能有助于预测目标的外部信息。
这对于受外部因素影响的时间序列特别有用。例如,如果有节假日,产品的需求可能会发生变化;或者电力需求会受到室外温度的影响。
在这些情况下,我们可以使用 TimeXer,因为它是专门为处理外生特征而构建的。
本文中,我们首先探讨 TimeXer 的架构和内部工作原理,然后将其应用到一个小型实验中,将其性能与其他模型进行比较。
有关更多详细信息,请务必阅读原始论文。
让我们开始吧!
1 TimeXer 介绍
如前所述,TimeXer 是一个基于 Transformer 的模型。TimeXer 背后的动机来自于意识到现有的基于 Transformer 的模型缺乏一些关键功能。
例如,PatchTST 执行单变量预测,这意味着它无法对多个序列的相互依赖性进行建模。此外,它不支持外生特征。
iTransformer 可以执行单变量和多变量预测,但不支持外生特征。
而 TimeXer 不仅能执行单变量和多变量预测,还能利用外生特征来辅助预测。
1.1 TimeXer 的架构
下图展示了 TimeXer 的总体架构。
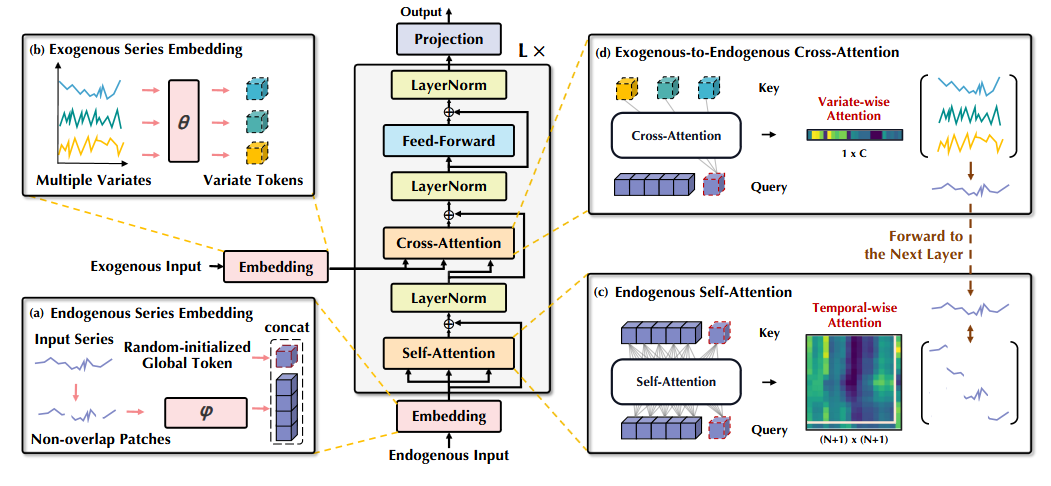
从图中可以看出,TimeXer 基本复用了原始 Transformer 架构,没有修改其组件。
主要的变化在于 TimeXer 如何采用自注意力机制学习时间依赖关系,以及采用交叉注意力机制捕捉外生特征对目标序列的影响。
当然,细节还有很多,我们接下来逐一深入了解各个组件。
1.2 内源性特征嵌入
TimeXer 的第一步是从输入时间序列创建嵌入。普通的 Transformer 会对每个时间步单独进行标记化,而 TimeXer 采用了 patching(分块)策略,将数据点分组后再进行标记化。
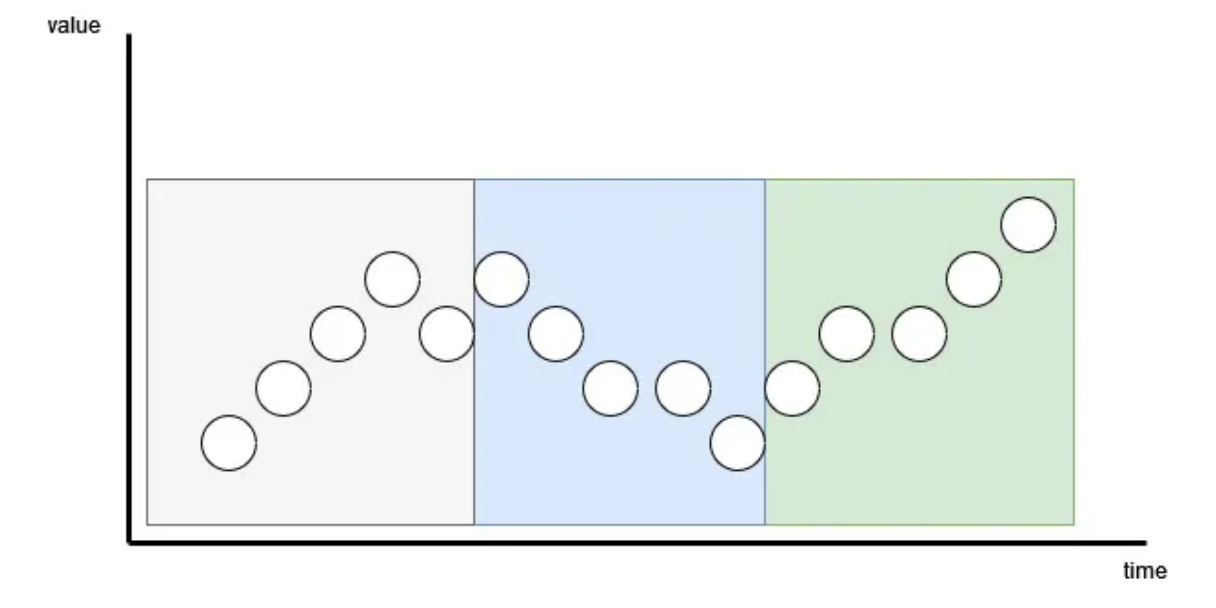
如图所示,序列长度为15,patch 长度为5,步幅也是5,因此产生了3个不重叠的补丁。
这种分块策略最初在 PatchTST 中提出,iTransformer 则是分块的极端版本。
分块的主要优点是减少了标记数量,降低了模型的空间和时间复杂度,同时帮助捕获时间依赖关系。
因此,TimeXer 采用相同的非重叠分块策略,将输入序列嵌入后送入自注意力机制。
1.3 外源性特征嵌入
与输入序列类似,外生特征也必须经过嵌入步骤,之后才能送入交叉注意力机制。
作者选择了变量级表示方法,如下图所示:
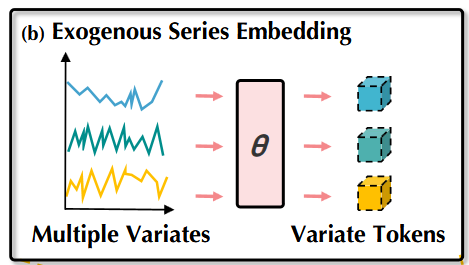
这里,每个外生序列被嵌入成一个唯一的 token。
这种策略允许模型处理缺失值或频率与目标序列不同的外生特征。
同时,它也降低了计算复杂度,因为每个变量只对应一个 token。这是分块的极端情况,整个序列被压缩成一个 token(类似 iTransformer)。
1.4 内源性特征的自注意力
对于目标序列,TimeXer 使用自注意力机制来学习时间依赖关系:
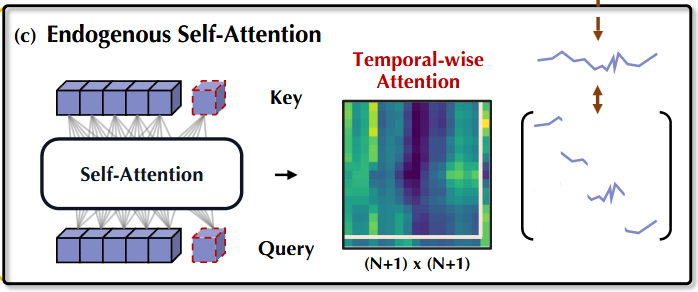
这里,注意力机制学习输入序列中的时间依赖。
关键创新是引入了一个全局 token(图中带虚线边缘的立方体)。
该机制包含三种主要注意力操作:
- Patch-to-patch:标准的自注意力,学习不同时间段(patch)之间的关系。
- Patch-to-global:全局 token 关注所有时间 patch,学习全局模式。
- Global-to-patch:每个时间 patch 关注全局 token,接收全局信息。
通过这种策略,模型能同时捕获局部和全局模式,有助于提升预测准确性。
1.5 外源性到内源性交叉注意力
TimeXer 的另一个关键机制是交叉注意力,用于捕获外部特征与目标序列之间的关系:
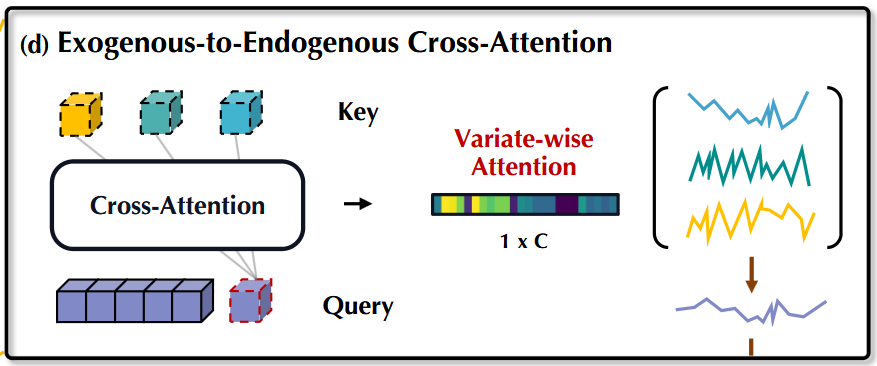
这里,全局 token 再次发挥关键作用。
交叉注意力机制有效地从外部因素中提取相关信息。
由于外生变量被编码为变量级 token,全局 token 聚合这些外部信息,并在前面提到的全局到 patch 操作中传递给时间 patch。
这使得 TimeXer 能够同时捕获时间依赖和目标序列与外部变量间的关系。
1.6 最后步骤与输出预测
经过两种注意力机制处理后,输出先经过归一化和前馈层,然后进入最终归一化层。
归一化层有助于稳定训练,前馈层进一步从注意力机制产生的深层抽象表示中学习。
最后一步是将输出投影到与预测任务一致的维度。
- 如果只预测一个序列,输出为长度等于预测范围的一维向量。
- 如果预测多个序列,输出为二维向量,维度为序列数 × 预测范围。
2 使用 TimeXer 进行预测案例
本节将 TimeXer 应用于流行的 EPF 基准数据集。
该数据集包含五个欧洲市场的电价信息,且附带已知的外生特征。数据集可在 GitHub 根据 MIT 许可获取。
本实验将 TimeXer 与 NHITS 和 TSMixerx 进行比较,它们都是支持外生特征的强大模型。
我们使用 neuralforecast 中的实现,因为它是使用深度学习模型进行时间序列预测最简单快捷的方式。
完整代码可在 GitHub 获取。
2.1 初始设置
首先导入实验所需的包,包括常用的数据处理和可视化包,以及 neuralforecast 和 utilsforecast:
import pandas as pd
import numpy as np
import matplotlib.pyplot as pltfrom neuralforecast.core import NeuralForecast
from neuralforecast.models import TimeXer, NHITS, TSMixerxfrom utilsforecast.evaluation import evaluate
from utilsforecast.losses import mae, mse
读取数据,并格式化为 neuralforecast 期待的格式。主要是创建 unique_id 列标识序列,时间戳列命名为 ds,目标列命名为 y。同时去除外生特征名称前的多余空格。
BE_url = "https://raw.githubusercontent.com/thuml/TimeXer/refs/heads/main/dataset/EPF/BE.csv"
DE_url = "https://raw.githubusercontent.com/thuml/TimeXer/refs/heads/main/dataset/EPF/DE.csv"BE_df = pd.read_csv(BE_url, parse_dates=["date"])
BE_df["unique_id"] = "BE"
BE_df = BE_df.rename(columns={ "date": "ds", " Generation forecast": "Generation forecast", " System load forecast": "System load forecast", "OT": "y"
})
DE_df = pd.read_csv(DE_url, parse_dates=["date"])
DE_df["unique_id"] = "DE"
DE_df = DE_df.rename(columns={ "date": "ds", " Wind power forecast": "Wind power forecast", " Ampirion zonal load forecast": "Ampirion zonal load forecast", "OT": "y"
})
为了简化,本文只对数据集中五个市场中的两个进行预测。你可以自由扩展到所有市场,只需确保变量名正确。
设置实验常量:
HORIZON = 24
INPUT_SIZE = 168
FREQ = "h"
BE_EXOG_LIST = ["Generation forecast", "System load forecast"]
DE_EXOG_LIST = ["Wind power forecast", "Ampirion zonal load forecast"]
这里,预测范围为24小时,输入长度为168小时(7天),数据频率为每小时,并定义了外生特征名称。
2.2 训练每个模型
在 neuralforecast 中,可以初始化一个模型列表,在数据集上训练。这里使用 TimeXer、NHITS 和 TSMixerx。
以下为比利时市场模型初始化示例:
models = [ TimeXer( h=HORIZON, input_size=INPUT_SIZE, n_series=1, futr_exog_list=BE_EXOG_LIST, patch_len=HORIZON, max_steps=1000 ), NHITS( h=HORIZON, input_size=INPUT_SIZE, futr_exog_list=BE_EXOG_LIST, max_steps=1000 ), TSMixerx( h=HORIZON, input_size=INPUT_SIZE, n_series=1, futr_exog_list=BE_EXOG_LIST, max_steps=1000 )
]
futr_exog_list 参数用于指定外生特征列名。
TSMixerx 和 TimeXer 使用 n_series 参数,因为它们是多变量模型,可以学习多个序列间的依赖。由于本例中一次只建模一个市场,故设为1。NHITS 是多变量模型,但不使用该参数。
接着使用交叉验证训练模型,获得多个预测窗口以便与实际值直接比较。
本例使用十个不重叠的交叉验证窗口:
nf = NeuralForecast(models=models, freq=FREQ)
BE_cv_preds = nf.cross_validation(BE_df, step_size=HORIZON, n_windows=10)
BE_cv_preds.head()
丹麦市场重复相同步骤:
models = [ TimeXer( h=HORIZON, input_size=INPUT_SIZE, n_series=1, futr_exog_list=DE_EXOG_LIST, patch_len=HORIZON, max_steps=1000 ), NHITS( h=HORIZON, input_size=INPUT_SIZE, futr_exog_list=DE_EXOG_LIST, max_steps=1000 ), TSMixerx( h=HORIZON, input_size=INPUT_SIZE, n_series=1, futr_exog_list=DE_EXOG_LIST, max_steps=1000 )
]nf = NeuralForecast(models=models, freq=FREQ)
DE_cv_preds = nf.cross_validation(DE_df, step_size=HORIZON, n_windows=10)
DE_cv_preds.head()
2.3 评估
在计算性能指标前,先可视化两个市场的预测结果。
比利时市场预测:
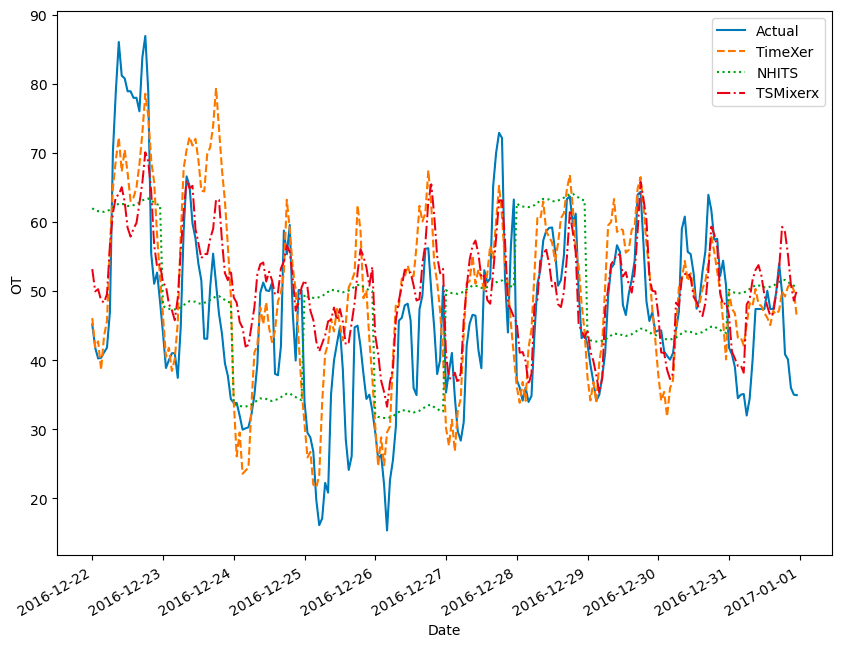
图片由作者提供
图中可见 NHITS 错过了数据中的细微波动,而 TSMixerx 和 TimeXer 的预测更好。
丹麦市场预测:
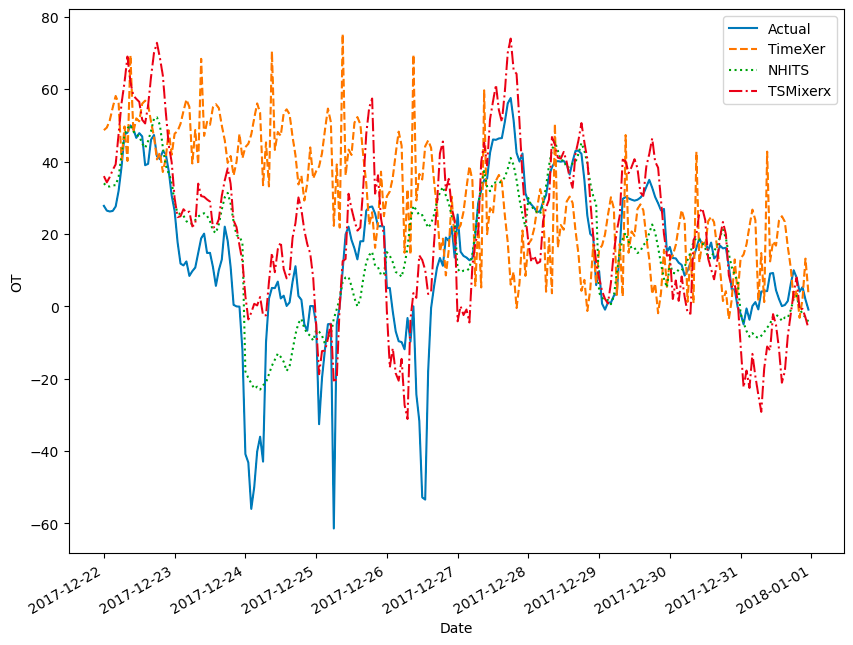
图片由作者提供
令人惊讶的是,TimeXer 在此表现最差,完全错过了早期的下跌,而 NHITS 和 TSMixerx 大致跟随实际趋势。
性能指标表进一步证实了这一观察:
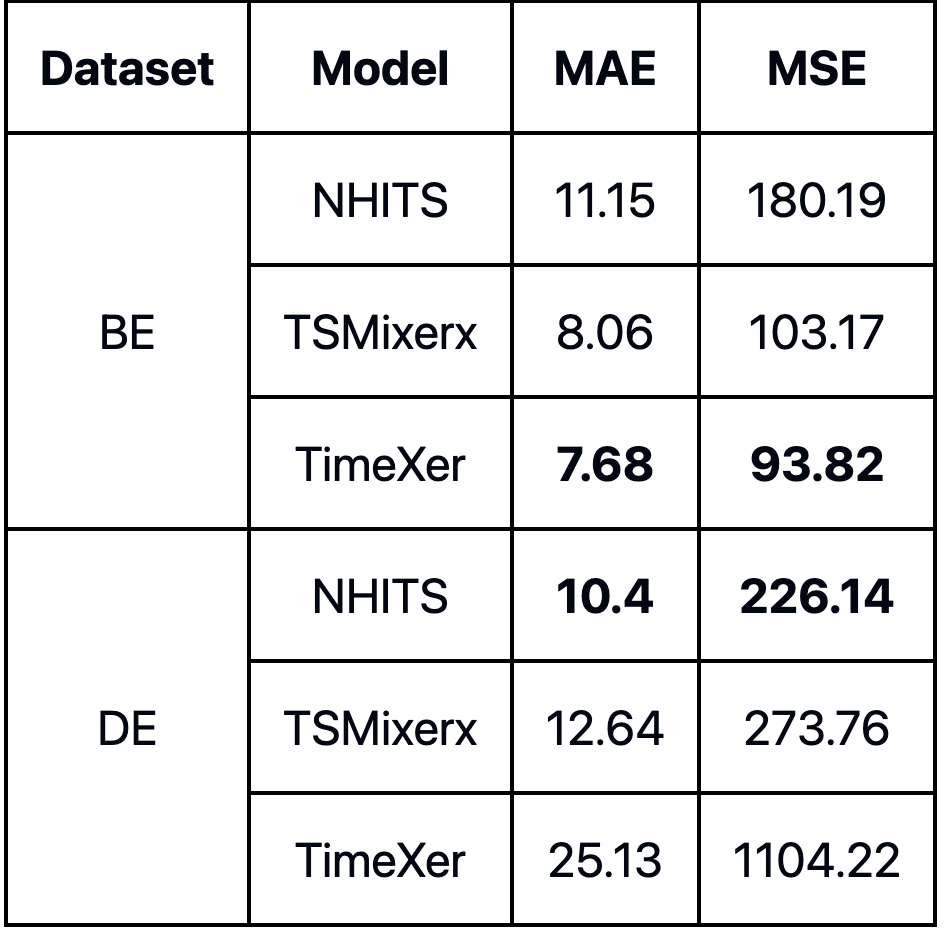
图片由作者提供
TimeXer 在比利时数据集表现最好,而 NHITS 表现最差;丹麦数据集则相反,NHITS 最佳,TimeXer 最差。
我很难解释这种差异的原因。但在其他数据集测试中,TimeXer 似乎受益于更长的训练时间,可能对丹麦数据集而言,1000步训练不够。
当然,本实验不是全面基准,主要目的是展示如何在自己的数据集上实现 TimeXer。
请注意:
- TimeXer 在 neuralforecast 中作为多变量模型实现,能建模多个序列间的依赖关系。
- TimeXer 受益于更长训练,建议训练步数大于1000。
- 模型支持外生特征,需在
futr_exog_list参数中传入。这意味着预测时外生特征的未来值是已知的。
3 结论
TimeXer 是一个结合自注意力和交叉注意力机制的基于 Transformer 的模型。
自注意力建模目标序列的时间依赖,交叉注意力捕获目标序列与外部变量的关系。
使用 TimeXer 时,建议训练步数超过1000,因为它似乎从更长训练中获益。
在本小型实验中,TimeXer 在一个数据集表现最佳,在另一个数据集表现最差。再次强调,这不是完整的基准测试,但其表现足够有趣,值得在你自己的项目中尝试。
每个问题都有其最佳解决方案,现在你可以测试 TimeXer 是否适合你的场景。
4 参考文献
[1] Y. Wang et al., “TimeXer: Empowering Transformers for Time Series Forecasting with Exogenous Variables,” arXiv.org, 2024. https://arxiv.org/abs/2402.19072
[2] TimeXer 官方实现 — GitHub