Java面试高频题目
Hello,我是鸡蛋灌bean,在面试的时候很多基础但是比较复杂的知识点会被面试官频繁地询问,下面我就列举几个常考的点以及我们如何口语化地去解答
1.SpringBean的生命周期
好的面试官,要讲述一下SpringBean的生命周期,首先我先陈述一下SpringBean的生命周期分为五个部分:
- 实例化
- 属性注入(依赖注入)
- 初始化
- 使用
- 销毁
- 首先第一步是实例化,容器通过反射机制创建Bean的实例,就是调用无参构造方法,此时这只是一个空对象,属性暂时没有赋值
- 然后第二步进行依赖注入,根据XML或者注解,将依赖的属性或其他bean注入到当前实例中,比如Autowired注入
- 第三步就是初始化
先是判断是否实现了三个Aware接口,BeanNameAware,BeanFactoryAware和ApplicationContextAware接口,如果实现了,就调用相应的set方法,传入对于的数据
然后判断是否有BeanPostProcessor后置处理器,调用其初始化前增强的方法
判断是否实现了InitializingBean接口,调用afterPropertiesSet方法或者执行自定义初始化方法
最后判断是否有BeanPostProcesor后置处理器,如果有就调用初始化后增强的方法
- 第四步就是使用
就是Bean进入可用状态,被应用程序通过容器获取并使用
最后就是销毁,容器关闭后,如果有自定义销毁方法就执行自定义销毁方法,如果没有就调用destroy方法,最后释放bean占用的资源
以上就是Bean的生命周期
2.SpringBoot自动装配原理
SpringBoot自动注入作为SpirngBoot核心属性,他的实现原理主要靠SpringApplication这个注解里的EnableAutoConfiguration这个核心注解
其中EnableAutoConfiguration注解里的@Import{(AutoConfigurationImportSelector.class)}就是自动装配的核心,里面的class类AutoConfigurationImportSelector实现了Selector接口,他通过分析项目的类路径和条件来决定应该导入哪些自动配置类
它主要的工作就是:
1.扫描类路径:在程序启动时,会扫描META-INF/spring.factores文件,会查找所有实现了AutoConfiguration接口的类
2.条件判断:对于每一个自动配置类,AutoConfigurationImportSelector会使用条件判断机制来确定是否满足导入条件(Bean是否存在,类是否存在)
最后根据条件导入自动配置类:满足条件的自动配置类将被导入到应用层序的上下文中。此时它们会被实例化并应用于应用程序的配置
3.Spring如何解决循环依赖
首先我先解释一下循环依赖,循环依赖就是指两个bean中的属性相互依赖对方,形成了一个依赖闭环,主要的循环依赖有三种:
1.通过构造方法进行依赖注入产生的循环依赖
2.通过setter方法进行依赖注入且是多例状态下的循环依赖
3.通过setter方法进行依赖注入且是单例模式下产生的循环依赖
这三种只有第三种循环依赖被Spring解决了
下面我来解释一下如何解决循环依赖:
Spring通过引入了三级缓存来解决循环依赖
其中一级缓存存放初始化完成,可用的,支持AOP代理的Bean实例
二级缓存缓存的是提前暴露的Bean原始对象,专门用来处理循环依赖问题,此时的Bean是未完成属性注入和初始化的Bean,只执行了实例化
三级缓存存放的是Bean的工厂实例,这是解决循环依赖和AOP协同工作的关键。当Bean被实例化后,Spring会创建这个工厂对象放入到缓存中
第三级缓存的存在目的是为了能提供代理对象,如果是AOP代理的类,从二级缓存中拿出来的是这个类的本身而非代理对象,就会照成冲突
举个例子,我们有A和B两个Bean,它们之间通过Setter注入依赖时产生了循环依赖
- 第一步:创建
BeanA的实例并提前暴露工厂
Spring创建BeanA的实例,并提前暴露工厂。Spring会调用BeanA的构造函数进行实例化,得到一个原始对象,然后将工厂对象存入三级缓存,三级缓存是为了当其他Bean要调用BeanA时,它能够动态返回这个半成品BeanA(需要原始对象时返回原始对象,需要代理对象时返回代理对象)
- 第二步:填充BeanA属性时触发BeanB的创建
填充BeanA属性时触发BeanB的创建,Spring就会将容器beanB开始创建,先调用构造方法将其实例化,然后将工厂对象存入三级缓存
- 第三步:填充BeanB属性时发现循环依赖
填充BeanB属性时发现循环依赖,此时会执行以下步骤:
在一级缓存中查询是否由BeanA完整对象
在二级缓存中查询是否有半成品对象
最后在三级缓存中查找到BeanA的工厂对象
然后就会调用该工厂的方法,此时会执行关键策略:若BeanA需要AOP动态代理,那么工厂就会生成动态代理对象,如果不需要就直接返回原始对象。得到对象以后就将其反倒二级缓存。同时清理工厂对象。最后将这个早期引用注入到BeanB属性中,此时BeanB完成属性赋值
- 第四步:完成BeanB的生命周期
BeanB获得所有依赖后,Spring执行初始化方法,将其转化为可用的Bean,随后BeanB被一级缓存缓存下来。然后清除二级和三级缓存
- 第五步:回溯完成BeanA的创建
BeanB创建完成后,就会到中断的BeanA属性注入环节。Spring将已完备的BeanB实例注入到BeanA中,然后执行初始化方法,,最后创建完成的BeanA存入一级缓存,删除二级和三级缓存,这样就解决了循环依赖
第三级缓存的意义是为了正确处理需要AOP代理的Bean
为什么构造器注入的Bean循环依赖Spring无法解决
由上面可知,Spring解决循环依赖靠的是三级缓存,其中三级缓存最重要的就是将实例化后的Bean放入缓存中,如果在这阶段无法完成实例化,那么缓存就无法存入Bean,因此就无法解决
4.AOP原理解释一下
AOP主要是对于面向对象思维的一种补充,可以对于类进行无侵入式加强,AOP的实现主要依赖于动态代理技术,在类运行时生成代理对象而不是编译时,从而在不修改源码的情况下增强方法的功能
生成一个动态代理对象,在运行时将织入的方法加在这个动态代理对象上,在使用时就使用这个代理对象,从而实现增强
SPringAOP支持两种动态代理:
基于JDK动态代理:使用java.lang.reflect.Proxy类或者invocationHandle接口实现,需要代理类实现一个或者多个接口
基于CGLIB动态代理:当代理的类没有接口时,Spring会通过CGLIB库生成代理类的子类来代理
5.MVCC原理
MVCC允许多个事务同时读取同一行数据且不会被阻塞,每个事务看到的数据版本是该事务开始时的版本,如果其他事务修改了数据,也不会影响其他事务
MVCC使用在每次查询数据时:select语句,通过readview来获取可以被安全访问的事务
MVCC主要对两个隔离级别进行区分
RC级别:读提交,每次生成一个ReadView,每个select语句执行前都会生成一个
RR级别:可重复读,执行一个select语句,生成一个ReadView,后续每个事务都会用这个ReadView
ReadView读视图:作用是判断当前事务能看到提交事务数据的范围,在事务执行过程中,提供一个一致性的快照视图,确保事务能够看到符合其隔离级别的数据版本
里面有四个重要字段m_ids:当前数据库中的活跃事务的事务id列表,活跃事务指的是启动了但是未提交的事务
min_trx_id:指的是活跃事务中的最小事务id
max_trx_id:指的是活跃事务中数据库应该给下一个事务id的值。即最大事务id+1
creator_trx_id:指的是创建该ReadView的事务id
此外,数据库中每行有两个隐藏列:
trx_id 和roll_pointer
trx_id是当一个事务对这行记录进行改动时,把该事务id记录在trx_id隐藏类中
roll_point是每次对某条记录改动是,把就版本记录写入到undo日志中,然后这个隐藏列是给指针,指向每一个旧版本记录,可以通过它来找到修改前的记录
在创建ReadView以后,我们可以对记录中的trx_id分为几种情况
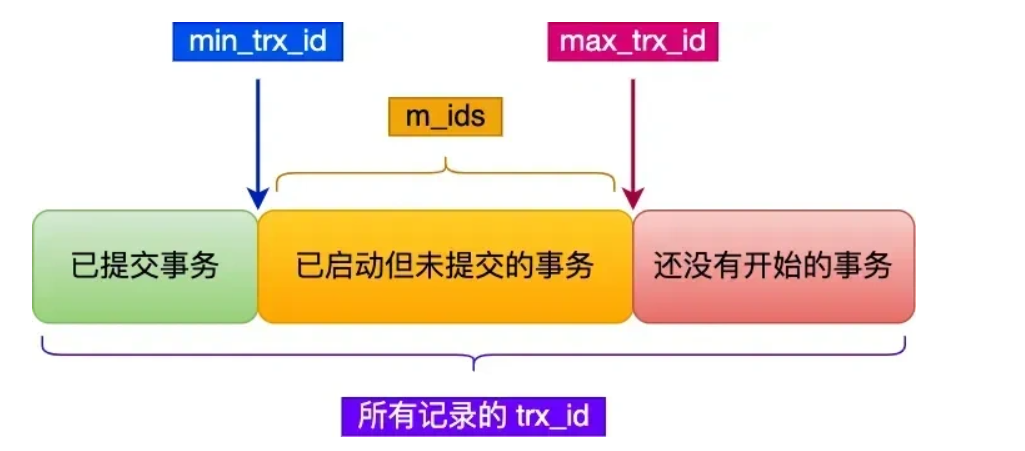
通过redolog生成的版本链,我们对trx_id进行判断,哪些可以访问哪些不能访问,如trx_id为m_ids就可以访问历史版本,大于min_trx_id小于max_trx_id或者是creator_id
6.类的生命周期以及类的加载过程
类的生命周期分为三个部分:
- 创建
- 使用
- 销毁
而类 的加载过程分为五步:
加载->连接(验证,准备,解析)->初始化->使用->卸载
其中类加载过程主要是:加载,连接和初始化
在这部分中的加载部分中,会使用双亲委派原则来加载类
类的加载器分为:启动器加载器,扩展类加载器,应用程序加载和用户自定义加载器四个部分由上到下分级
当我们要加载某一类时,先从最下面的自定义加载器开始向上的父类逐级查询是否以及加载过这个类了,所有的加载请求最终都会传送到顶层的启动器加载器中,然后自上而下判断哪层加载器已经加载过了。如果某层加载过了,就直接由此层的加载器来返回对象
双亲委派机制就是通过委托机制确保了所有类的加载请求都会传递到启动类加载器,避免了不同加载器重复加载相同类,同时保证了安全性,因为都会经过顶层的加载器,如果底层的用户自定义修改了顶层加载器加载的类(一般的Spring核心类)就会由父类来覆盖,防止用户篡改底层
7.讲讲redis如何保证同数据库数据的一致性
要保证Redis和数据库数据的一致性,就是防止在多线程情况下照成数据库和缓存数据不一致
核心缓存更新策略:
缓存与数据库的一致性,本质上是解决 “何时更新缓存、如何更新缓存” 的问题。常见策略如下:
1.首先是最常用到的缓存旁路模式
核心操作是:
- 读操作:先查Redis,若缓存命中就直接返回;若未命中,就查询数据库,将结果写入redis后返回
- 写操作:先更新数据库,再删除redis缓存而不是更新缓存
为什么要删除缓存而不是更新缓存
- 避免更新数据库和更新缓存的两步操作中,因为并发导致的不一致
- 删除缓存后,下次读操作会自动从数据库加载最新数据到缓存,保证数据一致
可能会存在的问题:
如果更新数据库成功,但是删除缓存失败,就会导致缓存的是旧值,可以通过消息队列异步重试删除缓存解决
2.双写模式:
写操作的时候,先更新缓存,再更新数据库,必须两者都成功才算完成,使用事务来保证
- 优点是缓存和数据库几乎同步,一致性高
- 缺点是写操作需要同时更新两个存储,性能较低
使用场景是对一致性要求极高的场景,比如消费的场景,用户积分的更新
3.回写模式
写操作时,只更新缓存,不立即更新数据库,而是由缓存异步批量更新数据库
优点是写性能极高,但是缺点是如果缓存宕机了就会导致数据丢失,适用于对写性能高而且能够容忍短期数据丢失的场景
使用场景是例如流量统计的场景,为了统计流量降低DB压力,使用回写模式
4.异步更新模式
先更新缓存,再通过MQ异步更新到数据库,注意消息幂等性
适合秒杀系统:如商品库存的扣减,用户购买商品时先更新redis中的库存数量,保证实时数据可见性,再使用异步更新到数据库中,保证持久性
对于上面三种模式会出现的一些问题,我来做介绍:
1. 缓存失效时的并发查询问题(缓存击穿防护)
当缓存过期 / 不存在时,大量并发请求会直接冲击数据库,可能导致数据库压力过大,同时可能因 “多线程同时查库并更新缓存” 导致数据不一致。
通过互斥锁(如 Redis 的 SETNX 命令)保证同一时间只有一个线程查询数据库并更新缓存,其他线程等待重试。
2. 先删缓存再更新数据库的并发问题
若执行 “删缓存 → 更新数据库” 期间,有其他线程读取数据:
解决:缓存延迟双删
- 步骤:先删缓存 → 更新数据库 → 延迟一段时间(如 500ms)再删一次缓存。
- 原理:第二次删除可清除线程 B 可能写入的旧缓存,保证后续读操作加载新值。
3. 分布式事务与最终一致性
在分布式系统中,跨服务的缓存与数据库更新需保证原子性,可通过:
- 本地消息表:更新数据库时记录消息,异步发送到消息队列,消费端监听消息并删除 / 更新缓存。
- 分布式锁:用 Redis 分布式锁(如 Redisson)保证 “更新数据库 + 操作缓存” 的原子性,避免并发冲突。
Redis 与数据库的一致性无法通过单一机制完美解决,实际应用中需结合业务场景综合选择策略