集成学习方法之随机森林:从原理到实战的深度解析
一、集成学习与随机森林概述
在机器学习领域,集成学习(Ensemble Learning)是一种通过组合多个弱学习器来构建强学习器的技术。其核心思想正如中国古话 “三个臭皮匠,赛过诸葛亮”,通过集体智慧提升预测性能。集成学习主要分为三大类:Bagging(并行训练多个模型并聚合结果)、Boosting(串行优化模型以聚焦难分样本)和Stacking(多层模型堆叠)。
随机森林(Random Forest)作为 Bagging 的经典代表,通过构建多棵决策树组成的 “森林”,在多个维度引入随机性,最终通过投票或平均实现高精度预测。其核心优势包括:
- 抗过拟合能力强:随机抽样和特征选择有效降低模型方差
- 高维数据处理能力:无需降维即可处理数千维特征
- 并行计算支持:每棵树独立训练,可充分利用多核资源
- 特征重要性评估:自动输出特征贡献度,辅助特征工程
二、算法原理与数学基础
2.1 随机性设计的双重保障
2.1.1 样本随机:Bootstrap 重采样
- 从原始训练集 T(含 N 个样本)中有放回地抽取 n 个样本(通常 n=N),生成新的训练子集
- 每个子集包含约 63.2% 的原始样本,剩余 36.8% 作为袋外数据(OOB)用于无偏误差估计
- 示例:1000 个样本的训练集,每次抽样约 632 个样本构成新训练集
2.1.2 特征随机:子空间抽样
- 在每个节点分裂时,从 d 个特征中随机选择 k 个(k<<d)进行最优划分
- 典型取值:k=√d(分类问题)或 k=d/3(回归问题)
- 作用:增加模型多样性,降低特征间相关性对预测的影响
2.2 决策树构建与集成策略
2.2.1 单棵决策树训练
- 采用 CART 算法构建二叉树,分类问题使用基尼系数,回归问题使用均方误差
- 完全生长不剪枝,避免因提前终止导致的信息损失
- 示例:在泰坦尼克号数据中,某棵树可能基于 "pclass" 和 "age" 进行分裂
2.2.2 森林集成机制
- 分类任务:多数投票制,得票最多的类别为最终结果
- 回归任务:算术平均,综合所有树的预测值
- 袋外误差估计:利用未被采样的样本计算误差,替代传统交叉验证
2.3 数学原理与理论支撑
2.3.1 方差 - 偏差分解
随机森林通过以下机制降低方差:
- 随机抽样使各树训练数据不同,减少模型间相关性
- 特征子空间抽样进一步增加模型多样性
- 集成投票平滑个体波动,实现方差压缩
2.3.2 基尼系数与信息增益
- 基尼系数:衡量数据不纯度,
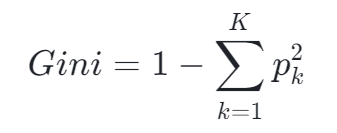
- 信息增益:基于信息熵计算,
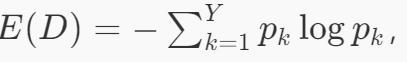
- 示例:当某特征划分使基尼系数从 0.4 降至 0.2 时,表明该特征对分类贡献显著
三、Scikit-learn API 深度解析
3.1 核心参数详解
3.1.1 控制森林结构的关键参数
- n_estimators:树的数量,建议从 100 开始逐步增加
- max_depth:树的最大深度,默认 None(完全生长)
- max_features:分裂时考虑的最大特征数,可选 "sqrt"、"log2" 等策略
3.1.2 优化性能的重要参数
- n_jobs:并行训练的 CPU 核心数,-1 表示使用所有可用核心
- class_weight:处理类别不平衡,支持 "balanced" 自动调整权重
- oob_score:是否使用袋外数据评估模型,节省验证集
3.1.3 决策树生成参数
- criterion:分裂准则,"gini"(默认)或 "entropy"
- min_samples_split:节点分裂所需最小样本数
- min_samples_leaf:叶子节点最小样本数
3.2 模型调优策略
3.2.1 网格搜索与随机搜索
# 网格搜索示例 param_grid = { 'n_estimators': [100, 200, 300], 'max_depth': [None, 10, 20], 'max_features': ['sqrt', 'log2'] } grid_search = GridSearchCV(RandomForestClassifier(), param_grid, cv=5) grid_search.fit(X_train, y_train) print("最佳参数:", grid_search.best_params_) |
3.2.2 学习曲线分析
通过绘制学习曲线(训练集大小 vs 误差),判断模型是否处于欠拟合或过拟合状态,示例代码如下:
from sklearn.model_selection import learning_curve train_sizes, train_scores, val_scores = learning_curve( RandomForestClassifier(), X, y, cv=5, train_sizes=np.linspace(0.1, 1.0, 5) ) |
四、泰坦尼克号生存预测实战
4.1 数据预处理全流程
4.1.1 缺失值处理
- 年龄(age):用均值填充(x["age"].fillna(x["age"].mean(), inplace=True))
- 登船港口(embarked):用众数填充
- 船舱号(cabin):缺失值较多,直接删除
4.1.2 特征工程
- 分类特征编码:性别(sex)转为 0/1,使用pd.get_dummies处理类别特征
- 衍生特征:创建家庭大小(family_size = sibsp + parch + 1)
- 特征选择:通过随机森林特征重要性筛选关键特征
4.1.3 数据转换与划分
from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler X = titanic[["pclass", "age", "sex", "fare", "family_size"]] y = titanic["survived"] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) scaler = StandardScaler() X_train_scaled = scaler.fit_transform(X_train) X_test_scaled = scaler.transform(X_test) |
4.2 模型训练与调优
4.2.1 基础模型训练
from sklearn.ensemble import RandomForestClassifier model = RandomForestClassifier( n_estimators=200, max_depth=10, max_features='sqrt', n_jobs=-1 ) model.fit(X_train_scaled, y_train) |
4.2.2 网格搜索优化
from sklearn.model_selection import GridSearchCV param_grid = { 'n_estimators': [100, 200, 300], 'max_depth': [None, 10, 20], 'min_samples_split': [2, 5, 10] } grid_search = GridSearchCV( model, param_grid, cv=5, scoring='roc_auc' ) grid_search.fit(X_train_scaled, y_train) |
4.3 模型评估与可视化
4.3.1 性能指标计算
from sklearn.metrics import classification_report y_pred = grid_search.predict(X_test_scaled) print(classification_report(y_test, y_pred)) |
4.3.2 特征重要性可视化
import matplotlib.pyplot as plt importances = grid_search.best_estimator_.feature_importances_ features = X.columns indices = np.argsort(importances)[::-1] plt.figure(figsize=(10, 6)) plt.title("Feature Importances") plt.bar(range(X.shape[1]), importances[indices]) plt.xticks(range(X.shape[1]), features[indices], rotation=45) plt.show() |
4.3.3 决策树结构可视化
from sklearn.tree import export_graphviz tree = grid_search.best_estimator_.estimators_[0] export_graphviz( tree, out_file='tree.dot', feature_names=X.columns, class_names=['Dead', 'Survived'], rounded=True, filled=True ) |
五、实际应用案例与场景扩展
5.1 金融风控:LendingClub 信用评分
5.1.1 数据挑战
- 高维稀疏特征:包含 100 + 个借款人属性
- 类别不平衡:违约样本占比约 10%
- 时间序列特性:需处理不同时间窗口的信用数据
5.1.2 解决方案
- 特征工程:创建信用历史长度、债务收入比等衍生特征
- 不平衡处理:使用class_weight='balanced'和 SMOTE 过采样
- 模型优化:结合随机森林与 XGBoost 构建混合模型
5.1.3 效果提升
- 违约预测 AUC 从 0.78 提升至 0.85
- 特征重要性分析发现 "fico_score" 和 "loan_term" 是关键指标
5.2 医疗诊断:慢性肾病预测
5.2.1 数据特点
- 混合数据类型:包含数值、类别和文本特征
- 专业领域知识:需结合医学指标(如血肌酐、尿素氮)
- 样本量有限:仅包含 300 + 条有效记录
5.2.2 处理策略
- 医学特征工程:计算肾小球滤过率(eGFR)等专业指标
- 类别特征编码:使用OrdinalEncoder处理 "appet" 等有序特征
- 模型验证:采用分层 5 折交叉验证确保结果稳健
5.2.3 应用价值
- 预测准确率达到 92%,优于传统逻辑回归
- 特征重要性显示 "血肌酐" 和 "血红蛋白" 是关键诊断指标
六、高级技巧与性能优化
6.1 并行计算加速
6.1.1 多核训练
通过设置n_jobs=-1,随机森林可利用所有 CPU 核心并行训练,示例代码:
model = RandomForestClassifier(n_jobs=-1, verbose=1) model.fit(X_train, y_train) |
6.1.2 分布式训练
对于超大规模数据(TB 级),可采用 Dask 或 Spark 进行分布式训练:
from dask_ml.ensemble import RandomForestClassifier model = RandomForestClassifier(n_estimators=1000, n_jobs=-1) model.fit(X_train, y_train) |
6.2 不平衡数据处理
6.2.1 类别权重调整
model = RandomForestClassifier(class_weight='balanced') |
6.2.2 采样方法结合
from imblearn.ensemble import BalancedRandomForestClassifier model = BalancedRandomForestClassifier( n_estimators=200, sampling_strategy='auto', replacement=True ) |
6.3 模型解释性增强
6.3.1 SHAP 值分析
import shap explainer = shap.TreeExplainer(model) shap_values = explainer.shap_values(X_test) shap.summary_plot(shap_values, X_test, feature_names=X.columns) |
6.3.2 局部解释工具
使用lime库生成单个样本的预测解释:
from lime import lime_tabular explainer = lime_tabular.LimeTabularExplainer( X_train_scaled, feature_names=X.columns, class_names=['Dead', 'Survived'] ) exp = explainer.explain_instance(X_test_scaled[0], model.predict_proba) exp.show_in_notebook() |
七、与其他算法的对比分析
7.1 随机森林 vs Adaboost
维度 | 随机森林 | Adaboost |
集成方式 | Bagging(并行) | Boosting(串行) |
抗噪能力 | 高(通过随机抽样) | 低(聚焦难分样本易过拟合) |
训练速度 | 快(可并行) | 慢(串行训练) |
适用场景 | 高维数据、噪声数据 | 低维数据、需要高精度的场景 |
7.2 随机森林 vs XGBoost
维度 | 随机森林 | XGBoost |
模型复杂度 | 低(树深度可控) | 高(需精细调参) |
特征处理 | 自动处理高维数据 | 需要特征工程 |
并行支持 | 原生支持 | 部分支持(特征并行) |
内存占用 | 高(存储多棵树) | 低(梯度累加) |
八、常见问题与解决方案
8.1 模型过拟合
8.1.1 症状表现
- 训练集准确率接近 100%,测试集准确率显著下降
- 特征重要性波动大,出现不合理特征排名
8.1.2 解决方法
- 增加min_samples_leaf(如设置为 5)
- 降低max_depth(如从 30 降至 15)
- 采用随机特征选择(max_features='sqrt')
- 增加n_estimators并观察 OOB 误差变化
8.2 预测速度慢
8.2.1 原因分析
- 树的数量过多(如 n_estimators=1000)
- 单棵树深度过大(max_depth=None)
- 数据量过大(百万级样本)
8.2.2 优化策略
- 减少树的数量(如从 1000 降至 300)
- 限制树的深度(设置max_depth=20)
- 使用n_jobs=-1启用并行预测
- 模型压缩:剪枝后树的数量减少 30%
8.3 特征重要性异常
8.3.1 可能原因
- 特征间存在强相关性(如身高和体重)
- 类别特征未正确编码(如字符串未转为数值)
- 数据预处理不当(如未标准化连续特征)
8.3.2 解决步骤
- 检查特征编码方式,确保类别特征正确转换
- 计算特征相关性矩阵,去除高度相关特征
- 重新进行数据标准化(使用StandardScaler)
- 对比 Permutation Importance 和 Gini Importance 结果
九、总结与展望
随机森林作为机器学习领域的 “瑞士军刀”,凭借其鲁棒性、可解释性和高效性,在金融、医疗、电商等多个领域取得了广泛应用。其核心优势在于:
- 简单易用:无需复杂调参即可取得不错效果
- 可解释性强:特征重要性分析辅助业务决策
- 适应性广:能处理结构化、非结构化等多种数据类型
未来,随机森林可能在以下方向进一步发展:
- 与深度学习结合:构建混合模型处理图像、文本等非结构化数据
- 联邦学习应用:在隐私保护场景下进行分布式训练
- 动态森林优化:根据数据分布实时调整树的结构
作为数据科学家,我们应充分利用随机森林的优势,同时结合领域知识进行特征工程和模型调优,让机器学习真正成为解决实际问题的强大工具。