03 基于sklearn的机械学习-线性回归、损失函数及其推导
线性回归
分类的目标变量是标称型数据,回归是对连续型的数据做出预测。
一、标称型数据(Nominal Data)
标称型数据属于分类数据(Categorical Data) 的一种,用于描述事物的类别或属性,没有顺序或数值意义,仅用于区分不同的组别。
- 核心特征
- 离散性:数据值是有限的、离散的类别,无法进行数学运算(如加减乘除)。
- 无顺序性:类别之间没有高低、大小或先后顺序,彼此平等。
- 标签化:通常用字符串或整数标签表示(如 “红色”“蓝色”,或用 0、1、2 代表不同类别),但标签的数值不具备实际意义。
- 常见例子
- 性别:男 / 女
- 颜色:红 / 黄 / 蓝
- 职业:教师 / 医生 / 工程师
- 学历:高中 / 本科 / 硕士(注意:学历若仅作为类别则是标称型,若强调顺序则是有序型数据,属于分类数据的另一种)
二、连续型数据(Continuous Data)
连续型数据是可以取无限多个数值的定量数据,通常用于衡量事物的数量或程度,具有数值意义和顺序性。
连续型数据可直接参与数值计算,但为了提升模型效果,通常需要预处理:标准化/归一化/离散化
- 核心特征
- 连续性:在一定范围内可以取任意值(理论上可无限细分),如身高 175cm、体重 62.5kg 等。
- 可运算性:支持加减乘除等数学运算,且结果有实际意义(如身高差、体重和)。
- 有序性:数值之间有明确的大小关系(如 180cm > 170cm)。
- 常见例子
- 物理量:身高、体重、温度、时间
- 统计量:收入、成绩、点击率、年龄(严格来说年龄可视为离散型,但通常按连续型处理)
线性回归
线性回归(Linear Regression)是监督学习中最基础的算法之一,用于建模自变量(特征或者X)与因变量(目标,y)之间的线性关系。
需要预测的值:即目标变量,target,y
影响目标变量的因素:X1,X2...XnX_1,X_2...X_nX1,X2...Xn,可以是连续值也可以是离散值
因变量和自变量之间的关系:即模型,model
对于数学中的线性回归通常为数学公式,例如y=w**x+b,是完全对的,但是在现实生活中,预测的结果与实际结果不完全一致,因此机器学习中的线性回归的目的是通过拟合一条直线,使预测值尽可能地接近真实值。
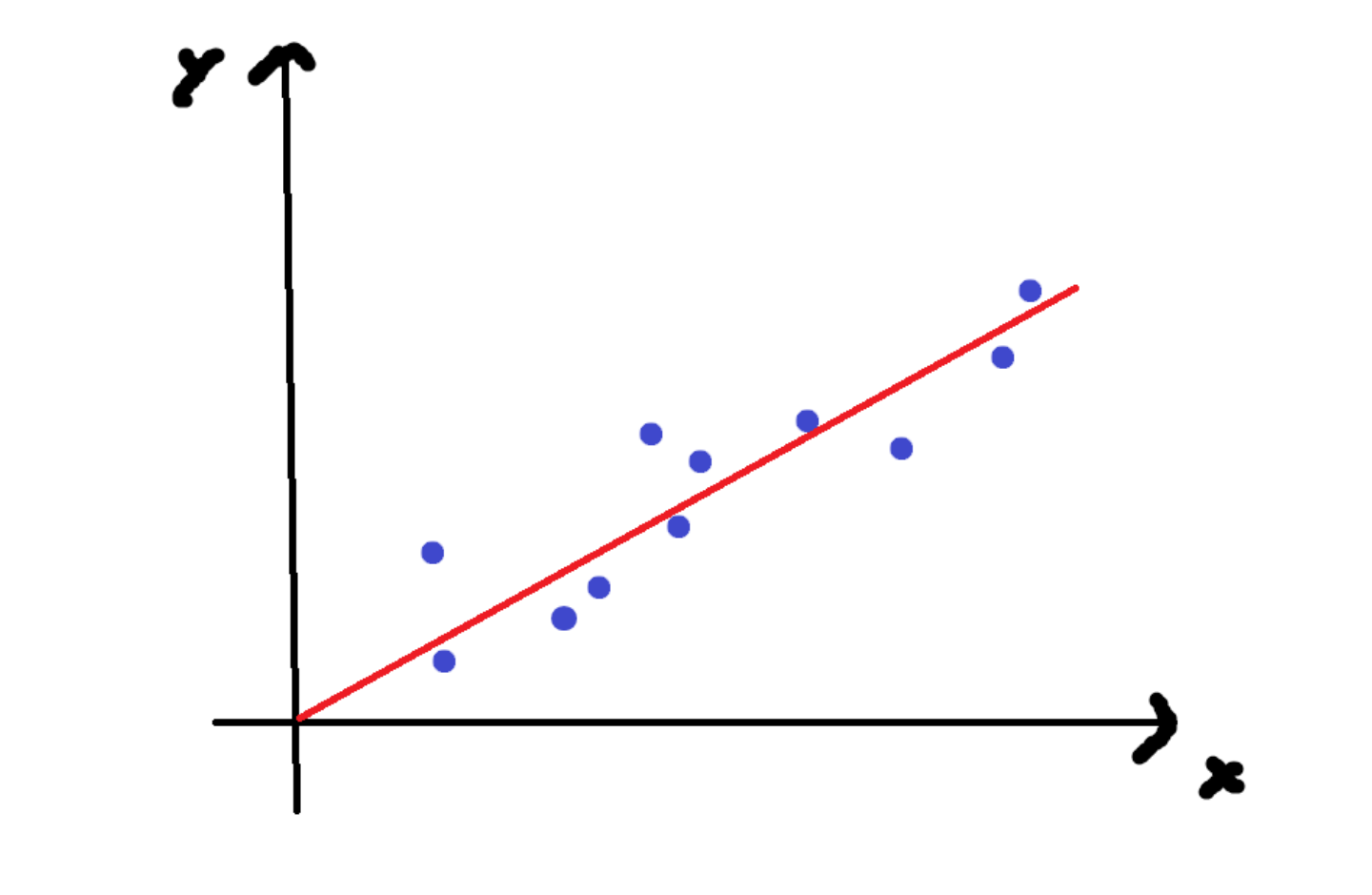
损失函数
损失函数(Loss Function)是衡量模型预测错误程度的函数,定义为预测值与真实值之间的差异。
假设: y=wx+by=wx+by=wx+b
把x1,x2,x3...x_1,x_2,x_3...x1,x2,x3...带入进去 然后得出:
y1,=wx1+by_1^,=wx_1+by1,=wx1+b
y2,=wx2+by_2^,=wx_2+by2,=wx2+b
y3,=wx3+by_3^,=wx_3+by3,=wx3+b
…
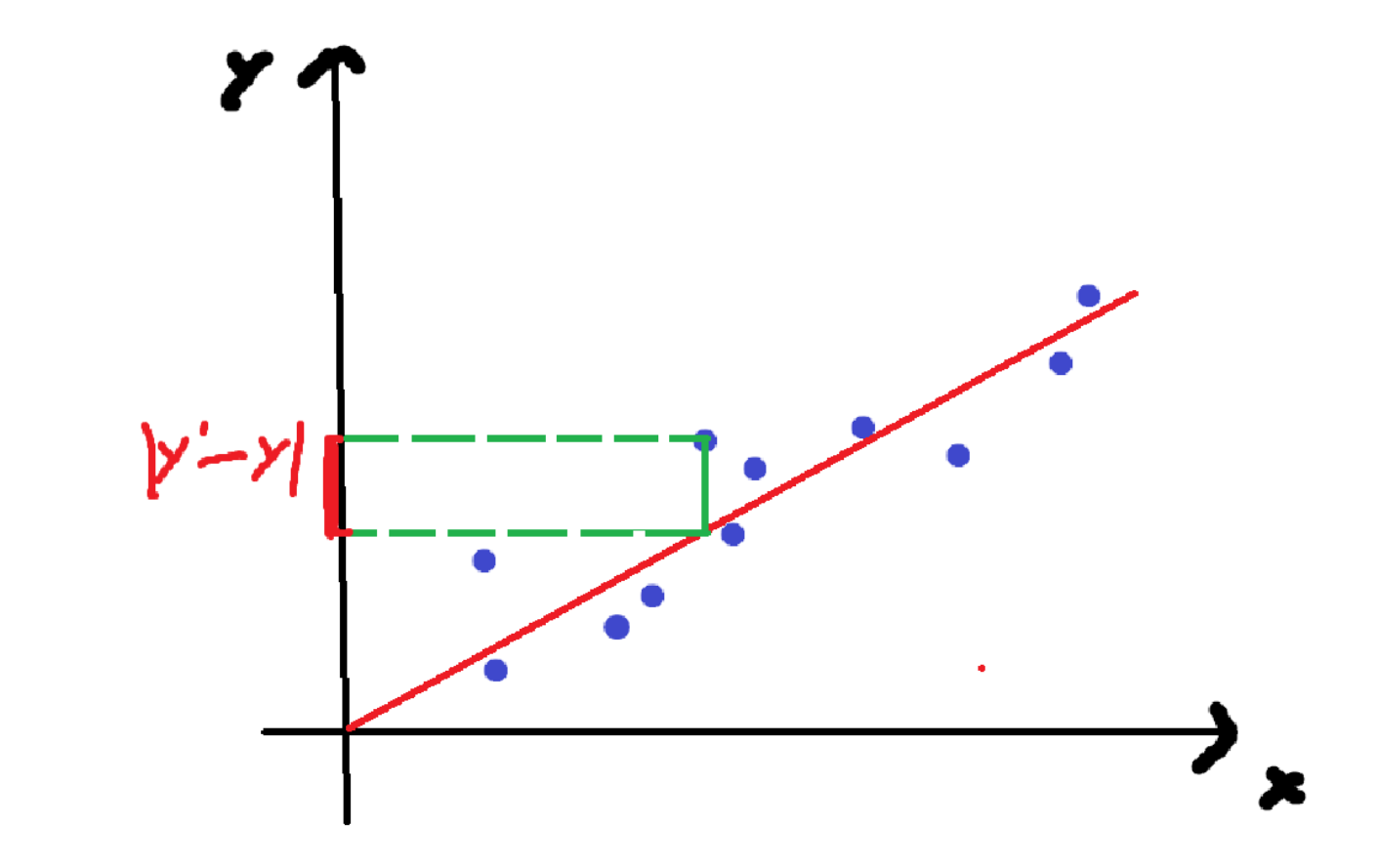
将每个点的真实值与计算值的差值全部算出来
总误差(损失):
loss=(y1−y1,)2+(y2−y2,)2+....(yn−yn,)2{(y_1-y_1^,)^2}+{(y_2-y_2^,)^2}+....{(y_n-y_n^,)^2}(y1−y1,)2+(y2−y2,)2+....(yn−yn,)2
总误差会受到样本点的个数的影响,样本点越多,该值就越大,所以我们可以对其平均化,求得平均值
这样就得到了损失函数:
eˉ=1n∑i=1n(yi−wxi−b)2\bar e = \frac{1}{n} \textstyle\sum_{i=1}^{n}(y_{i}-w x_{i} - b)^{2}eˉ=n1∑i=1n(yi−wxi−b)2
线性回归的目标是找到最优参数 w,使总损失最小化。
方法 1:解析解(最小二乘法)
通过对损失函数求导并令导数为 0,直接参数的解析解。
步骤 1:将预测值表示为矩阵形式
设特征矩阵为 X(含截距项时,首列全为 1),维度为 m X (n+1);
参数向量为 (w = (w_0, w_1, …, w_n)^T);
真实标签向量为 y=(y1,…,y**m)T。则预测值向量为: y’ = Xw
步骤 2:将总损失函数表示为矩阵形式
loss=12∣∣(XW−y)∣∣2求导:loss=\frac{1}{2}||(XW-y)||^2 求导:loss=21∣∣(XW−y)∣∣2求导:
loss=12(XW−y)T(XW−y)loss=\frac{1}{2}(XW-y)^T(XW-y)loss=21(XW−y)T(XW−y)
loss=12(WTXT−yT)(XW−y)loss=\frac{1}{2}(W^TX^T-y^T)(XW-y)loss=21(WTXT−yT)(XW−y)
loss=12(WTXTXW−WTXTy−yTXW+yTy)loss=\frac{1}{2}(W^TX^TXW-W^TX^Ty-y^TXW+y^Ty)loss=21(WTXTXW−WTXTy−yTXW+yTy)
步骤 3:对 w 求导并令导数为 0
loss′=12(WTXTXW−WTXTy−yTXW+yTy)′loss'=\frac{1}{2}(W^TX^TXW-W^TX^Ty-y^TXW+y^Ty)'loss′=21(WTXTXW−WTXTy−yTXW+yTy)′
loss′=12(XTXW+(WTXTX)T−XTy−(yTX)T)loss'=\frac{1}{2}(X^TXW+(W^TX^TX)^T-X^Ty-(y^TX)^T)loss′=21(XTXW+(WTXTX)T−XTy−(yTX)T)
loss′=12(XTXW+XTXW−XTy−XTy)loss'=\frac{1}{2}(X^TXW+X^TXW-X^Ty-X^Ty)loss′=21(XTXW+XTXW−XTy−XTy)
loss′=12(2XTXW−2XTy)loss'=\frac{1}{2}(2X^TXW-2X^Ty)loss′=21(2XTXW−2XTy)
loss′=XTXW−XTyloss'=X^TXW-X^Tyloss′=XTXW−XTy
令导数loss′=0loss'=0loss′=0
0=XTXW−XTy0=X^TXW-X^Ty0=XTXW−XTy
XTXW=XTyX^TXW=X^TyXTXW=XTy
矩阵没有除法,使用逆矩阵转化
(XTX)−1(XTX)W=(XTX)−1XTy(X^TX)^{-1}(X^TX)W=(X^TX)^{-1}X^Ty(XTX)−1(XTX)W=(XTX)−1XTy
W=(XTX)−1XTyW=(X^TX)^{-1}X^TyW=(XTX)−1XTy
方法 2:链式求导(梯度下降法)
当XTXX^TXXTX不可逆(如特征存在多重共线性)或样本量极大时,解析解计算复杂,需用梯度下降法迭代求解:
内部函数是 f(W) = XW - y ,外部函数是 g(u) = 1/2 *u^2 ,其中 u = f(W) 。
外部函数的导数:
∂g∂u=u=XW−y
\frac{\partial g}{\partial u} = u = XW - y
∂u∂g=u=XW−y
内部函数的导数:
∂f∂W=XT
\frac{\partial f}{\partial W} = X^T
∂W∂f=XT
应用链式法则,我们得到最终的梯度:
∂L∂W=(∂g∂u)(∂f∂W)=(XW−y)XT
\frac{\partial L}{\partial W} = \left( \frac{\partial g}{\partial u} \right) \left( \frac{\partial f}{\partial W} \right) = (XW - y) X^T
∂W∂L=(∂u∂g)(∂W∂f)=(XW−y)XT
sklearn.linear_model.LinearRegression()
-
fit_intercept:是否计算此模型的截距(偏置)b, default=True
-
属性
-
coef_ 回归后的权重系数w
-
intercept_ 偏置
-
from sklearn.linear_model import LinearRegression
import numpy as np
data=np.array([[0,14,8,0,5,-2,9,-3,399],[-4,10,6,4,-14,-2,-14,8,-144],[-1,-6,5,-12,3,-3,2,-2,30],[5,-2,3,10,5,11,4,-8,126],[-15,-15,-8,-15,7,-4,-12,2,-395],[11,-10,-2,4,3,-9,-6,7,-87],[-14,0,4,-3,5,10,13,7,422],[-3,-7,-2,-8,0,-6,-5,-9,-309]])
x = data[:,:-1]
y = data[:,-1]
# fit_intercept=True : 有w0
model = LinearRegression(fit_intercept=True)
# 训练
model.fit(x,y)# 查看参数
print(model.coef_)
# 查看w0
print(model.intercept_)
[ 3.41704677 9.64733333 9.96900258 0.49065266 10.67072206 4.5085292217.60894156 12.27111727]
18.18163864119797