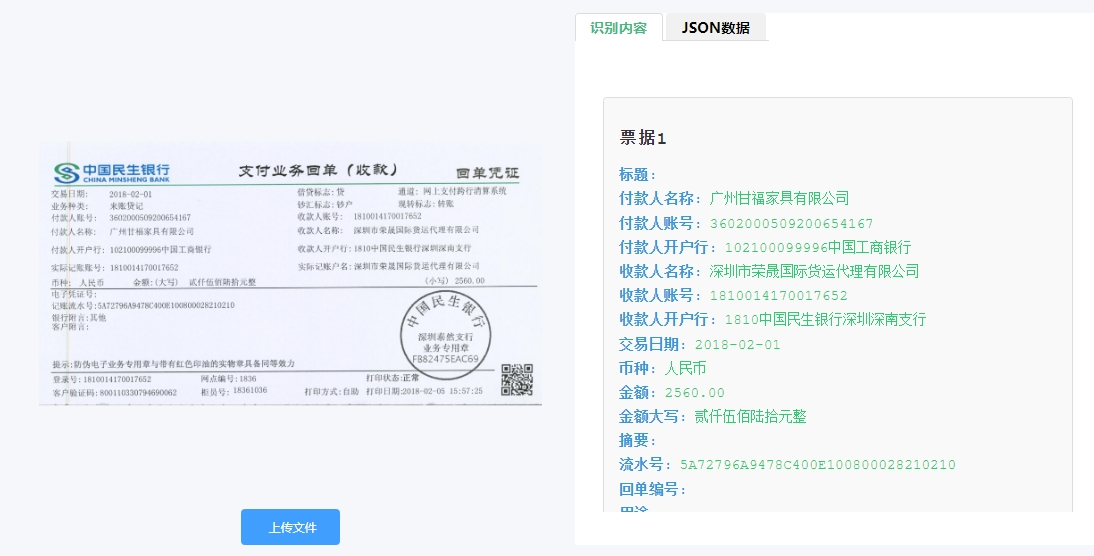
智能文本抽取技术:精准识别、定位并提取出关键信息
在信息爆炸的时代,海量的文本数据蕴藏着巨大的价值,但如何从中快速、准确地定位并提取出所需的关键信息?文本抽取技术正是解决这一难题的核心利器。它如同一位训练有素的“信息矿工”,能够深入非结构化或半结构化的文本“矿藏”,精准识别、定位并提取出用户感兴趣的特定信息片段。
工作原理:从规则到智能的进化
文本抽取的核心目标是从文本中识别并提取预定义类别的信息片段(如人名、地名、机构名、日期、金额、产品名、事件、特定关系等)。其工作原理经历了显著演变:
基于规则与模式匹配:
- 正则表达式: 用于匹配具有固定模式的字符串(如电话号码、邮箱地址、身份证号)。
- 词典匹配: 利用预先构建的词典(如公司名录、产品列表)进行精确匹配。
- 模式规则: 定义复杂的句法或语义模式(如“<人名> 担任 <职位> 于 <公司>”)。
- 优点: 在特定领域、格式固定的文本中准确率高,规则透明可控。
- 缺点: 规则编写维护成本高,泛化能力差,难以处理语言歧义和复杂结构。
基于统计机器学习:
- 序列标注: 将抽取任务建模为序列标注问题(如 BIO 标注:B-Begin, I-Inside, O-Outside)。常用模型:
- 隐马尔可夫模型: 较早的序列模型。
- 条件随机场: 考虑标签间的依赖关系,在 NER 等任务上表现出色。
- 特征工程: 依赖人工设计特征,如词本身、词性、词根、上下文词、词在句子中的位置、字符特征等。
- 优点: 相比规则方法泛化能力有所提升,能处理一定程度的语言变化。
- 缺点: 特征工程繁琐且依赖经验,模型性能受特征质量限制,对复杂语义理解有限。
基于深度学习:
- 词嵌入: 将词表示为稠密向量(如 Word2Vec, GloVe),捕捉语义和语法相似性。
- 循环神经网络: 特别是 LSTM 和 GRU,擅长处理序列数据,能捕捉长距离依赖。
- 卷积神经网络: 提取局部特征,可用于分类或短文本处理。
- 注意力机制: 让模型关注输入序列中与当前预测最相关的部分,提升效果。
- Transformer 与大模型: 如 BERT, GPT, RoBERTa 等预训练语言模型,通过在海量文本上预训练,学习到丰富的语言知识和上下文表示。微调后,成为当前文本抽取(特别是 NER 和关系抽取)的 SOTA 方法。它们能有效处理歧义、长距离依赖和复杂语义。
- 优点: 强大的特征自动学习能力,卓越的上下文理解能力,泛化性能好,对复杂语言现象处理能力强。
- 缺点: 模型训练需要大量标注数据,计算资源消耗大,模型可解释性相对较差。
技术难点:挑战无处不在
尽管技术不断进步,文本抽取仍面临诸多挑战:
- 语言歧义性: 同一词语在不同语境下含义不同(如“苹果”指水果还是公司?),同一实体可能有多种表达形式(如“特朗普”、“川普”、“唐纳德·特朗普”、“美国总统”)。
- 表达多样性: 相同的信息可以用多种句式、词汇表达,口语化、非正式表达普遍存在。
- 上下文依赖性: 信息的含义和边界高度依赖上下文。例如,“北京”在“北京天气”中是地点,在“北京烤鸭”中可能指风味。
- 领域迁移: 在特定领域(如金融、医疗、法律)训练的模型,迁移到新领域时效果常大幅下降,因术语、表达习惯、知识体系不同。
- 长距离依赖: 关键信息词可能相隔很远(如主句和从句中主语与谓语的关系)。
- 非结构化文本复杂性: 文本可能包含拼写错误、语法错误、缩写、网络用语、特殊符号等噪声。
- 关系抽取的复杂性: 识别实体间的关系需要理解文本语义,涉及逻辑推理(如因果、时序、条件等)。
- 小样本/低资源场景: 对于冷门领域或小众语言,标注数据稀缺,难以训练高质量模型。
- 实时性要求: 某些应用(如舆情监控)要求近实时处理海量流式文本。
- 评估困难: 如何全面、客观地评估抽取结果的准确性和实用性,尤其在不同粒度和复杂关系上。
功能特点:精准、灵活、高效
现代文本抽取技术通常具备以下核心特点:
- 高精度: 利用深度学习和预训练模型,在各类任务上达到前所未有的准确率。
- 强泛化性: 能够处理未见过的词汇、表达方式和一定程度的语言变化。
- 上下文感知: 深度理解词语和短语在句子或篇章中的具体含义。
- 多任务集成: 常与实体链接、关系抽取、事件抽取等任务结合,提供更丰富的信息。
- 领域自适应: 可通过微调、迁移学习或领域预训练模型,快速适应特定领域需求。
- 自动化与高效: 自动化处理海量文本,大幅提升信息处理效率,降低人工成本。
- 结构化输出: 将非结构化文本转化为结构化或半结构化数据(如 JSON, XML),便于后续存储、分析和应用。
- 支持多种语言: 主流框架和模型通常支持多语言抽取。
- 可扩展性: 能够处理从短文本到长文档的不同规模输入。
应用场景:价值无处不在
文本抽取技术已深度融入众多行业和场景,释放数据价值:
金融科技:
- 风控与合规: 识别合同中的关键条款(如违约责任、支付条件)、客户资料信息;监控公告和新闻中的违规风险信号。
- 自动化报告生成: 从海量数据源中提取信息,自动生成市场分析报告、信用报告。
医疗健康:
- 电子病历结构化: 抽取患者症状、疾病诊断、检查检验结果、用药记录、手术信息等,辅助诊疗和科研。
- 医学文献挖掘: 快速定位药物、疾病、基因、靶点、副作用、治疗方法等信息,加速药物研发和临床决策。
法律与合规:
- 合同智能审查: 自动识别合同主体、金额、期限、关键义务、权利、风险条款、管辖法律等。
- 法规遵从: 监控法律法规变化,提取适用条款和要求。
- 证据挖掘与案情分析: 从案卷材料中提取关键事实、人物关系、时间线。
文本抽取技术作为自然语言处理领域的基石性任务,已经从早期的规则驱动迈入了以深度学习和大模型驱动的智能时代。尽管仍面临语言复杂性、领域迁移等挑战,但其在提升信息处理效率、挖掘数据价值、赋能智能决策方面的巨大潜力已得到充分验证。随着模型能力的持续进化(如大语言模型在零样本/小样本抽取上的突破)以及多模态信息抽取的发展,文本抽取技术将变得更加精准、鲁棒和易用,继续深刻地改变我们获取、理解和利用文本信息的方式,在数字化转型的浪潮中扮演愈发关键的角色。