大数据之Hive
Hive
由Facebook开源用于解决海量结构化日志的数据统计工具。
基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类SQL查询功能。
本质:将HQL(Hive Query Language)转化成MapReduce程序
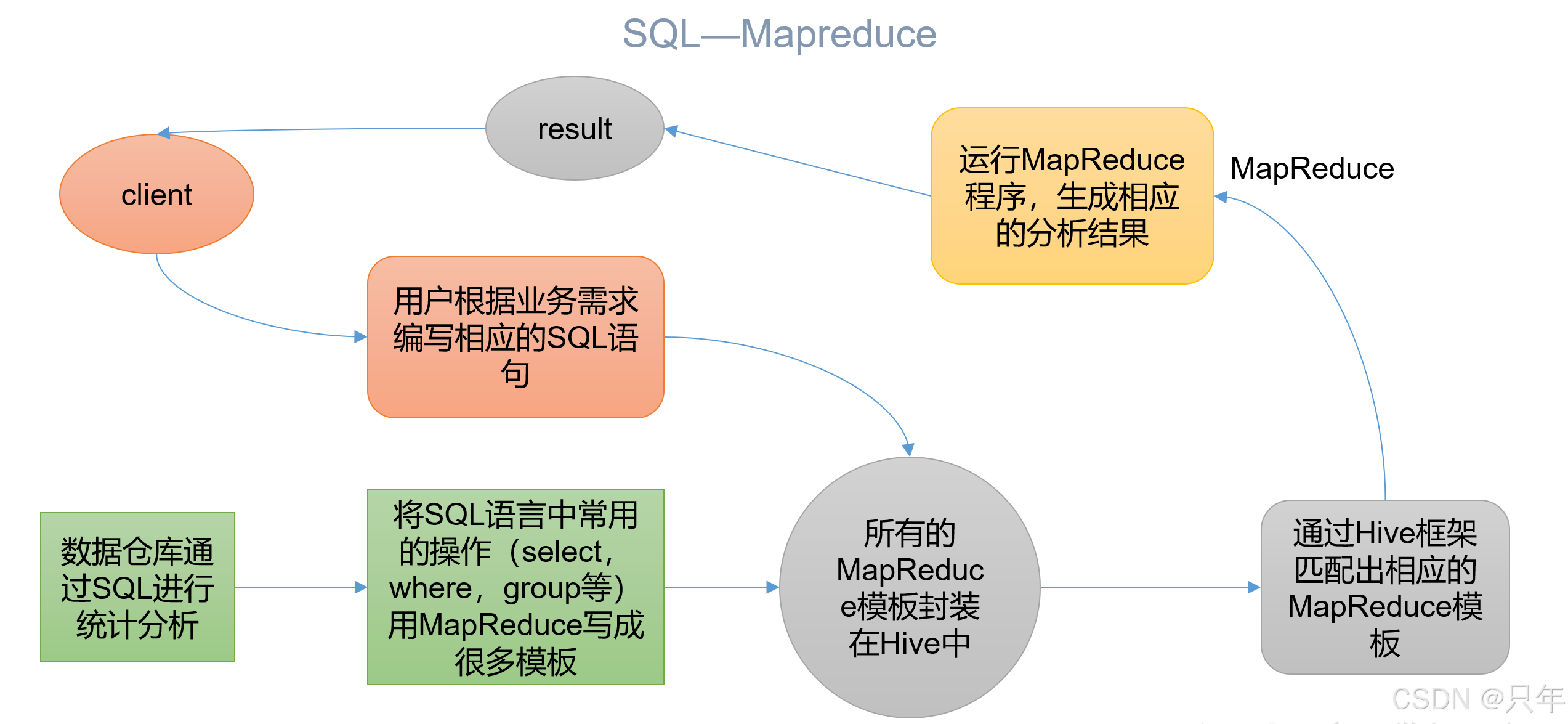
- Hive处理的数据存储在HDFS
- Hive分析数据底层的实现是MapReduce
- 执行程序运行在Yarn上
一、Hive安装
1.1 Hive安装地址
- 官网地址:http://hive.apache.org/
- 文档查看地址:https://cwiki.apache.org/confluence/display/Hive/GettingStarted
- 下载地址:http://archive.apache.org/dist/hive/
- github地址:https://github.com/apache/hive
1.2 MySQL安装
参考我博客:https://blog.csdn.net/qq_41594280/article/details/135798548
此处MySQL密码已改为:HiveMeta123456!
1.3 Hive安装部署
Hive和MySQL仅在102安装
# 1.解压
tar -zxvf /opt/software/apache-hive-3.1.2-bin.tar.gz -C /opt/module/
# 2.重命名
mv /opt/module/apache-hive-3.1.2-bin/ /opt/module/hive-3.1.2
# 3.环境变量
vim /etc/profile.d/my_env.sh---
#HIVE_HOME
HIVE_HOME=/opt/module/hive-3.1.2
PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HIVE_HOME/bin
export PATH JAVA_HOME HADOOP_HOME HIVE_HOME
---# 4.解决日志Jar包冲突
mv $HIVE_HOME/lib/log4j-slf4j-impl-2.10.0.jar $HIVE_HOME/lib/log4j-slf4j-impl-2.10.0.bak
mv $HIVE_HOME/lib/guava-19.0.jar $HIVE_HOME/lib/guava-19.0.bak
cp $HADOOP_HOME/share/hadoop/common/lib/guava-27.0-jre.jar $HIVE_HOME/lib/
1.4 Hive元数据配置到MySQL
1.4.1 拷贝驱动
# 将MySQL的JDBC驱动拷贝到Hive的lib目录下
cp /opt/software/mysql-connector-java-8.0.30.jar $HIVE_HOME/lib
1.4.2 配置Metastore到MySQL
# 在$HIVE_HOME/conf目录下新建hive-site.xml文件
vim $HIVE_HOME/conf/hive-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration><!-- jdbc连接的URL --><property><name>javax.jdo.option.ConnectionURL</name><value>jdbc:mysql://hadoop102:3306/metastore?useSSL=false</value></property><!-- jdbc连接的Driver--><property><name>javax.jdo.option.ConnectionDriverName</name><value>com.mysql.cj.jdbc.Driver</value></property><!-- jdbc连接的username--><property><name>javax.jdo.option.ConnectionUserName</name><value>root</value></property><!-- jdbc连接的password --><property><name>javax.jdo.option.ConnectionPassword</name><value>HiveMeta123456!</value></property><!-- Hive默认在HDFS的工作目录 --><property><name>hive.metastore.warehouse.dir</name><value>/user/hive/warehouse</value></property><!-- Hive元数据存储版本的验证 --><property><name>hive.metastore.schema.verification</name><value>false</value></property><!-- 指定存储元数据要连接的地址 --><property><name>hive.metastore.uris</name><value>thrift://hadoop102:9083</value></property><!-- 指定hiveserver2连接的端口号 --><property><name>hive.server2.thrift.port</name><value>10000</value></property><!-- 指定hiveserver2连接的host --><property><name>hive.server2.thrift.bind.host</name><value>hadoop102</value></property><!-- 元数据存储授权 --><property><name>hive.metastore.event.db.notification.api.auth</name><value>false</value></property></configuration>
1.5 启动Hive
1.5.1 初始化元数据库
# 登录MySQL
mysql -uroot -pHiveMeta123456!
# 新建Hive元数据库
mysql> create database metastore;
# 初始化Hive元数据库
schematool -initSchema -dbType mysql -verbose
1.5.2 启动metastore和hiveserver2
-
Hive 2.x以上版本,要先启动这两个服务,否则会报错:
FAILED: HiveException java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient
-
启动metastore
[atguigu@hadoop102 ~]$ hive --service metastore 2025-07-20 03:31:21: Starting Hive Metastore Server # 注意: 启动后窗口不能再操作,需打开一个新的shell窗口做别的操作 -
启动 hiveserver2
[atguigu@hadoop102 ~]$ hive --service hiveserver2 which: no hbase in (/usr/local/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/opt/module/jdk1.8.0_212/bin:/opt/module/hadoop-3.1.3/bin:/opt/module/hadoop-3.1.3/sbin:/opt/module/hive-3.1.2/bin:/home/atguigu/.local/bin:/home/atguigu/bin) 2025-07-20 03:31:27: Starting HiveServer2 # 注意: 启动后窗口不能再操作,需打开一个新的shell窗口做别的操作
-
-
编写hive服务启动脚本
-
前台启动的方式导致需要打开多个shell窗口,可以使用如下方式后台方式启动
-
nohup: 放在命令开头,表示不挂起,也就是关闭终端进程也继续保持运行状态
-
2>&1 : 表示将错误重定向到标准输出上
-
&: 放在命令结尾,表示后台运行
一般会组合使用: nohup [xxx命令操作]> file 2>&1 & , 表示将xxx命令运行的
结果输出到 file 中,并保持命令启动的进程在后台运行。
如上命令不要求掌握。
nohup hive --service metastore 2>&1 & nohup hive --service hiveserver2 2>&1 & # 或 nohub hive --service metastore>/opt/module/hive-3.1.2/logs/metastore.log 2>&1 & nohub hive --service hiveserver2>/opt/module/hive-3.1.2/logs/hiveserver2.log 2>&1 & -
-
为了方便使用,可以直接编写脚本来管理服务的启动和关闭
vim ~/bin/hiveservice.sh#!/bin/bash HIVE_LOG_DIR=$HIVE_HOME/logs if [ ! -d $HIVE_LOG_DIR ] thenmkdir -p $HIVE_LOG_DIR fi #检查进程是否运行正常,参数1为进程名,参数2为进程端口 function check_process() {pid=$(ps -ef 2>/dev/null | grep -v grep | grep -i $1 | awk '{print $2}')ppid=$(netstat -nltp 2>/dev/null | grep $2 | awk '{print $7}' | cut -d '/' -f 1)echo $pid[[ "$pid" =~ "$ppid" ]] && [ "$ppid" ] && return 0 || return 1 }function hive_start() {metapid=$(check_process HiveMetastore 9083)cmd="nohup hive --service metastore >$HIVE_LOG_DIR/metastore.log 2>&1 &"cmd=$cmd" sleep 4; hdfs dfsadmin -safemode wait >/dev/null 2>&1"[ -z "$metapid" ] && eval $cmd || echo "Metastroe服务已启动"server2pid=$(check_process HiveServer2 10000)cmd="nohup hive --service hiveserver2 >$HIVE_LOG_DIR/hiveServer2.log 2>&1 &"[ -z "$server2pid" ] && eval $cmd || echo "HiveServer2服务已启动" }function hive_stop() {metapid=$(check_process HiveMetastore 9083)[ "$metapid" ] && kill $metapid || echo "Metastore服务未启动"server2pid=$(check_process HiveServer2 10000)[ "$server2pid" ] && kill $server2pid || echo "HiveServer2服务未启动" }case $1 in "start")hive_start;; "stop")hive_stop;; "restart")hive_stopsleep 2hive_start;; "status")check_process HiveMetastore 9083 >/dev/null && echo "Metastore服务运行正常" || echo "Metastore服务运行异常"check_process HiveServer2 10000 >/dev/null && echo "HiveServer2服务运行正常" || echo "HiveServer2服务运行异常";; *)echo Invalid Args!echo 'Usage: '$(basename $0)' start|stop|restart|status';; esac
-
-
添加执行权限
chmod +x ~/bin/hiveservice.sh -
启动Hive后台服务
hiveservice.sh start
1.5.3 HiveJDBC访问
# 启动beeline客户端
[atguigu@hadoop102 bin]$ beeline -u jdbc:hive2://hadoop102:10000 -n atguigu
Connecting to jdbc:hive2://hadoop102:10000
Connected to: Apache Hive (version 3.1.2)
Driver: Hive JDBC (version 3.1.2)
Transaction isolation: TRANSACTION_REPEATABLE_READ
Beeline version 3.1.2 by Apache Hive
0: jdbc:hive2://hadoop102:10000>
1.5.4 Hive访问
[atguigu@hadoop102 bin]$ hive
which: no hbase in (/usr/local/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/opt/module/jdk1.8.0_212/bin:/opt/module/ha/hadoop-3.1.3/bin:/opt/module/ha/hadoop-3.1.3/sbin:/opt/module/hive-3.1.2/bin:/home/atguigu/.local/bin:/home/atguigu/bin:/opt/module/jdk1.8.0_212/bin:/opt/module/hadoop-3.1.3/bin:/opt/module/hadoop-3.1.3/sbin:/opt/module/hive-3.1.2/bin)
Hive Session ID = 4d66d45a-72d1-4c60-9a40-5e290459297cLogging initialized using configuration in jar:file:/opt/module/hive-3.1.2/lib/hive-common-3.1.2.jar!/hive-log4j2.properties Async: true
Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
Hive Session ID = 42610dc3-1475-4c42-8cb4-fe9323058951
hive>
hive> show databases;
OK
default
打印当前库和表头 → 编辑 hive-site.xml 添加如下两个配置(可从hive-default.xml.template查找)
<!-- 打印当前所在库 --><property><name>hive.cli.print.current.db</name><value>true</value><description>Whether to include the current database in the Hive prompt.</description></property><!-- 打印表头 --><property><name>hive.cli.print.header</name><value>true</value><description>Whether to print the names of the columns in query output.</description></property>
再次hive命令进入,执行 show databases 可以看到表头和当前库。
hive (default)> show databases;
OK
database_name
default
Time taken: 0.222 seconds, Fetched: 1 row(s)
1.6 Hive常用交互命令
[atguigu@hadoop102 hive-3.1.2]$ hive -help
usage: hive-d,--define <key=value> Variable substitution to apply to Hivecommands. e.g. -d A=B or --define A=B--database <databasename> Specify the database to use-e <quoted-query-string> SQL from command line-f <filename> SQL from files-H,--help Print help information--hiveconf <property=value> Use value for given property--hivevar <key=value> Variable substitution to apply to Hivecommands. e.g. --hivevar A=B-i <filename> Initialization SQL file-S,--silent Silent mode in interactive shell-v,--verbose Verbose mode (echo executed SQL to theconsole)
hive (default)> create table mytbl (id int, name string);
OK
Time taken: 0.694 secondshive (default)> insert into table mytbl values(1001, 'zhangsan');
Query ID = atguigu_20250720041953_4e7bc730-a702-4fe1-9d33-5e460d62004e
Total jobs = 3
Launching Job 1 out of 3
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:set mapreduce.job.reduces=<number>
Starting Job = job_1752953039146_0001, Tracking URL = http://hadoop103:8088/proxy/application_1752953039146_0001/
Kill Command = /opt/module/hadoop-3.1.3/bin/mapred job -kill job_1752953039146_0001
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2025-07-20 04:19:59,543 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 1.34 sec
MapReduce Total cumulative CPU time: 1 seconds 340 msec
Ended Job = job_1752953039146_0001
Stage-4 is selected by condition resolver.
Stage-3 is filtered out by condition resolver.
Stage-5 is filtered out by condition resolver.
Moving data to directory hdfs://hadoop102:8020/user/hive/warehouse/mytbl/.hive-staging_hive_2025-07-20_04-19-53_086_7783016678375823197-1/-ext-10000
Loading data to table default.mytbl
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 1.34 sec HDFS Read: 22707 HDFS Write: 780936 SUCCESS
Total MapReduce CPU Time Spent: 1 seconds 340 msec
OK
col1 col2
Time taken: 9.134 seconds
-
-e不进入 hive 的交互窗口执行 sql 语句[atguigu@hadoop102 hive-3.1.2]$ hive -e "select * from default.mytbl" -
-f执行脚本中 sql 语句[atguigu@hadoop102 hive-3.1.2]$ touch hive.sql [atguigu@hadoop102 hive-3.1.2]$ vim hive.sql --- select * from default.mytbl --- [atguigu@hadoop102 hive-3.1.2]$ hive -f hive.sql # 若要将hive数据写出,执行如下命令(极少用) [atguigu@hadoop102 hive-3.1.2]$ hive -f hive.sql > hive.result
1.7 Hive其他命令操作
-
退出 hive 窗口
hive (default)> exit; hive (default)> quit;在新版的 hive 中没区别了。以前版本有区别。exit 是先隐性提交数据,再退出,而 quit 是不提交数据,退出。
beeline 的退出是
!quit -
在 hive cli 命令窗口中如何查看 hdfs 文件系统
hive (default)> dfs -ls / ; -
查看在 hive 中输入的所有历史命令
# 进入到当前用户的根目录 /root 或 /home/atguigu cd ~ # 查看 .hivehistory 文件 cat .hivehistory
1.8 Hive常见属性配置
1.8.1 Hive运行日志信息配置
# Hive 的 log 默认存放在 /tmp/atguigu/hive.log 目录下(当前用户名下)
# 修改 hive 的 log 存放日志到 /opt/module/hive-3.1.2/logs
# 修改/opt/module/hive-3.1.2/conf/hive-log4j2.properties.template 文件名称为hive-log4j2.properties(此处我复制一个)
cp $HIVE_HOME/conf/hive-log4j2.properties.template $HIVE_HOME/conf/hive-log4j2.properties---
#property.hive.log.dir = ${sys:java.io.tmpdir}/${sys:user.name}
property.hive.log.dir = /opt/module/hive-3.1.2/logs
---
1.8.2 参数配置方式
[atguigu@hadoop102 hive-3.1.2]$ hive -hiveconf hive.cli.print.current.db=false
which: no hbase in (/usr/local/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/opt/module/jdk1.8.0_212/bin:/opt/module/hadoop-3.1.3/bin:/opt/module/hadoop-3.1.3/sbin:/opt/module/hive-3.1.2/bin:/home/atguigu/.local/bin:/home/atguigu/bin)
Hive Session ID = cc1dba40-c8fb-43c7-b245-2ecead4aeae4Logging initialized using configuration in file:/opt/module/hive-3.1.2/conf/hive-log4j2.properties Async: true
Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
Hive Session ID = 2c29883f-ded4-408b-9505-460828bc444a
hive> set hive.cli.print.current.db;
hive.cli.print.current.db=false
hive> set hive.cli.print.current.db=true;
hive (default)> set hive.cli.print.current.db;
hive.cli.print.current.db=true
hive (default)>
可以看到,配置优先级 配置文件方式 (hive-site.xml) < 命令行参数方式(-hiveconf) < 参数声明方式(set)
注意:命令行方式 和 参数声明方式 仅对本次 hive 启动有效。
默认配置文件:hive-default.xml。用户自定义配置文件:hive-site.xml。用户自定义配置会覆盖默认配置。另外,Hive也会读入Hadoop的配置,因为Hive是作为Hadoop的客户端启动的,Hive的配置会覆盖Hadoop的配置。配置文件的设定对本机启动的所有Hive进程都有效。
上述三种设定方式的优先级依次递增。即配置文件<命令行参数<参数声明。注意某些系统级的参数,例如log4j相关的设定,必须用前两种方式设定,因为那些参数的读取在会话建立以前已经完成了。
二、Hive数据类型
2.1 基本数据类型
| Hive数据类型 | Java数据类型 | 长度 | 例子 |
|---|---|---|---|
| TINYINT | byte | 1byte有符号整数 | 20 |
| SMALINT | short | 2byte有符号整数 | 20 |
| INT | int | 4byte有符号整数 | 20 |
| BIGINT | long | 8byte有符号整数 | 20 |
| BOOLEAN | boolean | 布尔类型,true或者false | TRUE FALSE |
| FLOAT | float | 单精度浮点数 | 3.14159 |
| DOUBLE | double | 双精度浮点数 | 3.14159 |
| STRING | string | 字符系列。可以指定字符集。可以使用单引号或者双引号。 | ‘now is the time’ “for all good men” |
| TIMESTAMP | 时间类型 | ||
| BINARY | 字节数组 |
对于Hive的String类型相当于数据库的varchar类型,该类型是一个可变的字符串,不过它不能声明其中最多能存储多少个字符,理论上它可以存储2GB的字符数。
2.2 集合数据类型
| 数据类型 | 描述 | 语法示例 |
|---|---|---|
| STRUCT | 和c语言中的struct类似,都可以通过“点”符号访问元素内容。例如,如果某个列的数据类型是STRUCT{first STRING, last STRING},那么第1个元素可以通过字段.first来引用。 | struct() 例如struct<street:string, city:string> |
| MAP | MAP是一组键-值对元组集合,使用数组表示法可以访问数据。例如,如果某个列的数据类型是MAP,其中键->值对是’first’->’John’和’last’->’Doe’,那么可以通过字段名[‘last’]获取最后一个元素 | map() 例如map<string, int> |
| ARRAY | 数组是一组具有相同类型和名称的变量的集合。这些变量称为数组的元素,每个数组 |