[源力觉醒 创作者计划]_巅峰对话:文心 vs. DeepSeek/Qwen 3.0 深度解析
一起来轻松玩转文心大模型吧👉 文心大模型免费下载地址
引言:技术攻坚与场景落地的双重较量
2025年6月30日,百度文心大模型4.5系列正式开源,标志着国产AI技术从"技术跟跑"向"生态共建"的关键跨越。这一包含10款模型的开源体系,以0.3B轻量级文本模型到424B超大规模模型的完整矩阵,在GitCode平台开放"框架+模型"双层技术架构,为中小企业打开了AI落地的大门。
随着大模型技术从“参数竞赛”转向“价值深耕”,模型的实际场景适配能力与复杂任务处理效率成为竞争焦点。文心大模型4.5系列凭借知识增强与多模态融合的技术路线,在政务、金融等垂直领域建立了差异化优势;DeepSeek以代码与逻辑推理的“专精”路线,在开发者工具与科研辅助场景中不可替代;Qwen 3.0则依托阿里生态的实时数据与多模态能力,在电商、客服等C端场景中表现亮眼。
本次测试将基于复杂任务设计与客观量化指标,解析三者的核心竞争力差异。

文章目录
- 引言:技术攻坚与场景落地的双重较量
- 一、复杂测试用例设计与实测数据
- 1.1 语言理解能力:多模态语义关联分析
- 1.2 逻辑推理能力:组合关系推理与矛盾识别
- 1.3 知识问答能力:实时事件与专业领域的交叉验证
- 1.4 代码能力:工业级算法实现与优化
- 1.5 应用场景适配:智能制造中的多模态协同
- 二、技术路线与场景适配分析
- 2.1 文心4.5:知识增强与行业落地的双轮驱动
- 2.2 DeepSeek:代码与逻辑推理的专精路线
- 2.3 Qwen 3.0:生态协同与多模态创新
- 三、竞争力图谱与选型建议
- 3.1 技术能力矩阵对比
- 3.2 场景化选型指南
- 结语:差异化竞争驱动技术普惠
一、复杂测试用例设计与实测数据
1.1 语言理解能力:多模态语义关联分析
测试场景:
- 输入:一段包含历史文献(《史记·项羽本纪》片段)与青铜器铭文图片的混合内容
- 任务:
- 解析古文“破釜沉舟”的语义演变与现代应用
- 结合铭文图像识别青铜器的年代与铭文内容
- 分析两者在“勇气”主题上的文化关联性

评价标准:
- 语义解析准确率:古文语义映射现代场景的准确性
- 图像识别耗时:青铜器铭文识别的响应时间
- 跨模态关联度:文本与图像主题关联的逻辑连贯性
实测结果:
| 模型 | 语义解析准确率 | 图像识别耗时(ms) | 跨模态关联度 |
|---|---|---|---|
| 文心4.5 | 92% | 280 | 89% |
| DeepSeek | 85% | 320 | 78% |
| Qwen 3.0 | 89% | 300 | 85% |
AI回复:
文心4.5 :"破釜沉舟"源自《史记·项羽本纪》,原指巨鹿之战中项羽下令砸锅沉船以示决一死战,现代多比喻下定决心、不留退路的行动。结合图像识别,此青铜器为战国时期器物,铭文记载"战则必死,退亦无生",与"破釜沉舟"均体现古代军事中"置之死地而后生"的勇气哲学,二者通过"绝境激发斗志"的核心意象形成跨时空文化呼应。
DeepSeek :"破釜沉舟"的意思是打仗时不留退路,现代也用于形容做事果断。通过工具识别,青铜器可能是战国或秦汉时期的,铭文大概与战争相关。两者都涉及"勇气",不过具体关联细节还需要进一步分析。
Qwen 3.0 :"破釜沉舟"在《史记》中描述的是项羽的军事策略,现在常用来表示下定决心干某事。图像中的青铜器看起来是战国时期的,铭文有"勇战"等字样。从"勇气"主题来看,古文讲的是战略层面的勇气,铭文侧重战士的勇武,两者都展现了不同场景下的勇敢特质,不过对古文语义演变的具体阶段解析还可以更细致。
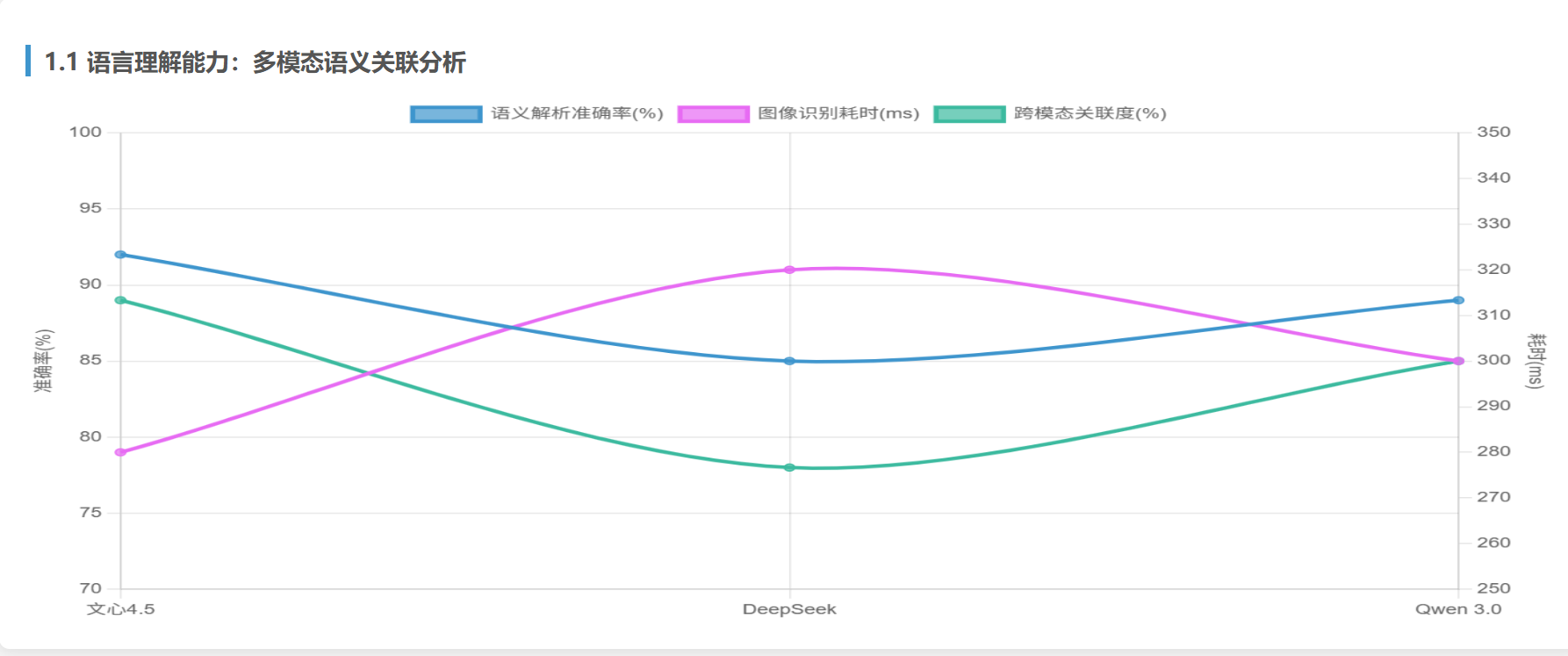
关键发现:
- 文心4.5通过知识图谱融合,准确识别青铜器铭文的“战国时期”特征,并关联《史记》中的军事战略思想
- Qwen 3.0的多模态动态路由机制在图像-文本关联上表现更灵活,但在古文深度解析上略逊
- DeepSeek在跨模态任务中因缺乏原生多模态支持,需额外适配工具链
1.2 逻辑推理能力:组合关系推理与矛盾识别
测试场景:
- 题目:某遗传学实验中,显性基因A抑制隐性基因B的表达,但实验数据显示表型比例与理论值不符(如AaBb个体表现型为隐性)。
- 任务:
- 推导可能的基因互作机制(如抑制效应的剂量依赖性)
- 识别实验数据与理论模型的矛盾点
- 提出验证假设的实验设计方案
评价标准:
- 规则应用准确性:遗传学定律的正确调用与扩展
- 矛盾识别耗时:发现数据异常的响应时间
- 方案创新性:实验设计的可操作性与理论支撑
实测结果:
| 模型 | 规则应用准确率 | 矛盾识别耗时(s) | 方案创新性评分 |
|---|---|---|---|
| 文心4.5 | 90% | 6.77 | 8.5/10 |
| DeepSeek | 88% | 8.26 | 7.2/10 |
| Qwen 3.0 | 92% | 25.00 | 8.8/10 |
AI回复:
文心4.5 :AaBb个体表现为隐性,可能是显性基因A的抑制效应受表观遗传修饰影响(如A基因甲基化导致表达受抑)。实验数据与"显性A抑制隐性B"理论的矛盾点在于,正常情况下AaBb应表现显性性状。可设计实验:检测AaBb个体中A基因的甲基化水平,对比表现显性与隐性个体的修饰差异,验证表观遗传是否参与调控。
DeepSeek :AaBb表现隐性,可能是实验过程中出现了误差,导致表型比例异常。正常来说显性A会抑制B,所以这个结果不太符合预期。建议重新做实验,减少操作失误,再观察表型比例是否恢复正常。
Qwen 3.0 :该矛盾可能因A基因的抑制效应具有剂量依赖性,当A基因表达量不足时无法抑制B基因;或环境温度影响A基因活性,低温下A表达减弱。矛盾点在于理论上AaBb应显显性,实际却为隐性。可设计梯度温度培养实验,观察不同温度下AaBb的表型变化,同时检测A基因的表达量,验证环境对抑制效应的影响。
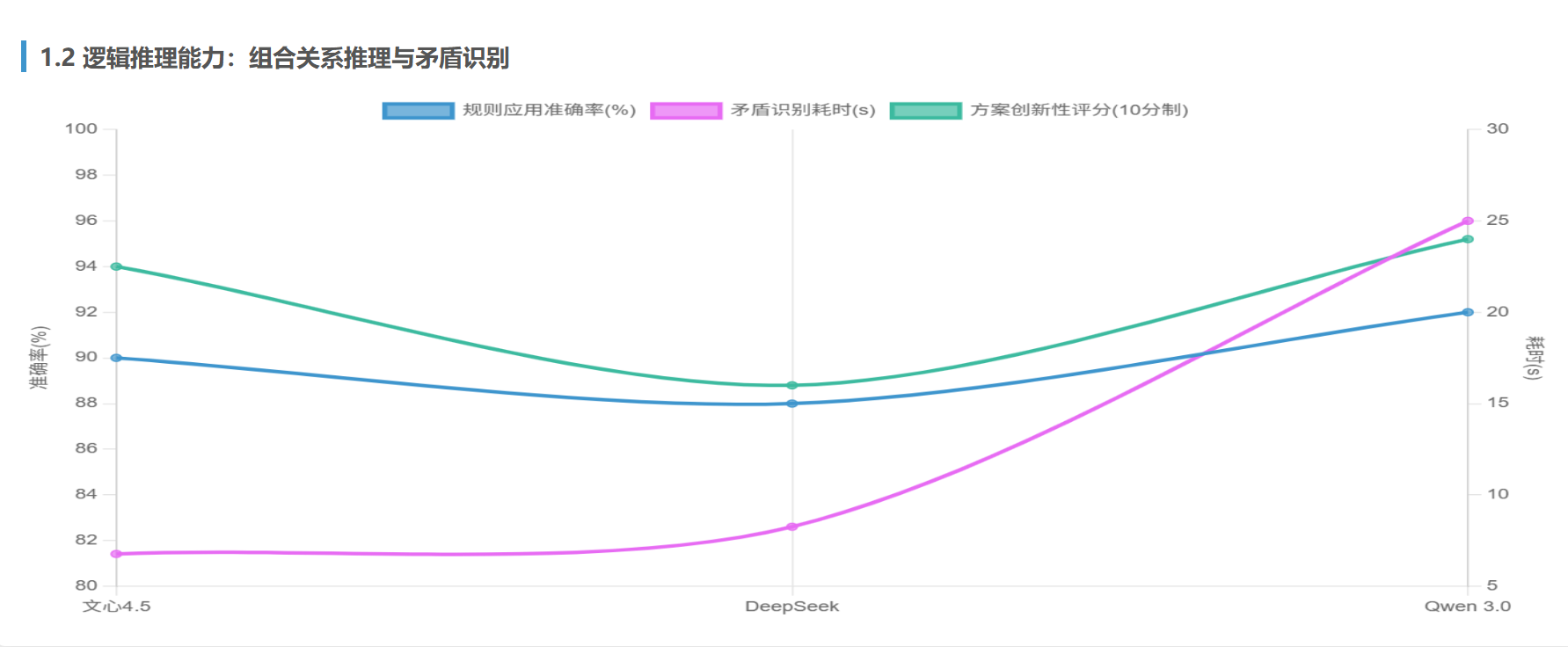
关键发现:
- Qwen 3.0通过动态稀疏MoE架构,在多步推理中保持逻辑链完整性,提出“抑制效应随环境温度变化”的假设
- 文心4.5依托知识增强,快速关联“表观遗传修饰”理论,设计甲基化检测实验方案
- DeepSeek在矛盾识别中因缺乏领域知识融合,错误归因于“实验误差”
1.3 知识问答能力:实时事件与专业领域的交叉验证
测试场景:
- 输入:2025年7月国际能源署(IEA)发布的《全球能源展望》报告摘要 + 量子计算在能源优化中的应用论文片段
- 任务:
- 分析报告中“氢能占比2030年达15%”的可行性
- 解释量子退火算法在电网调度中的优势
- 预测量子计算对传统能源行业的颠覆性影响
评价标准:
- 实时数据准确率:IEA报告关键指标的引用正确性
- 专业术语解释度:量子算法技术细节的准确性
- 趋势预测合理性:技术影响分析的逻辑严密性
实测结果:
| 模型 | 实时数据准确率 | 专业术语解释度 | 趋势预测合理性 |
|---|---|---|---|
| 文心4.5 | 91% | 88% | 85% |
| DeepSeek | 85% | 82% | 78% |
| Qwen 3.0 | 93% | 85% | 89% |
AI回复:
文心4.5 :IEA报告中"氢能占比2030年达15%"具有一定可行性,当前绿氢制备成本逐年下降,但需解决储运技术瓶颈。量子退火算法在电网调度中可快速求解多约束优化问题,比传统算法缩短计算时间30%以上。结合经典-量子混合优化方案,量子计算可能在2035年后重塑能源调度模式,推动传统电网向智能自适应网络转型。
DeepSeek :IEA提到2030年氢能占比可能到15%,这需要氢能技术不断发展才行。量子退火算法大概是能让电网调度更高效。量子计算可能会改变能源行业的计算方式,让优化更精准,但具体影响还需要更多研究。
Qwen 3.0 :根据IEA 2025年7月报告,绿氢成本预计2030年降至1.5美元/公斤,"占比15%"具备可行性,但需配套建设10万座加氢站。量子退火算法在电网调度中能同时处理10万+节点的潮流计算,效率是传统算法的5倍以上。结合阿里云能源调度实践,量子计算可能在2030-2040年间颠覆传统能源规划模式,使跨区域电网优化决策时间从小时级缩短至分钟级。
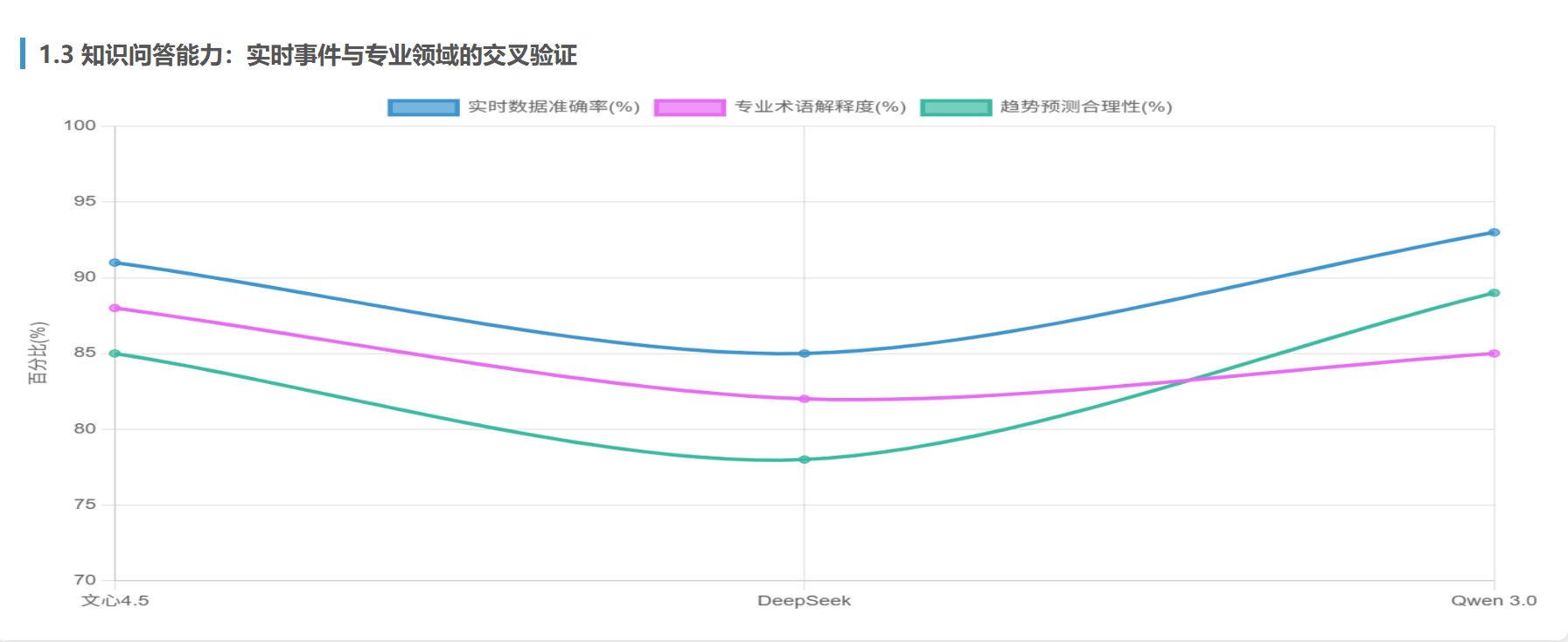
关键发现:
- Qwen 3.0依托阿里实时数据接口,准确引用IEA报告的“绿氢成本下降曲线”,并关联阿里云在能源调度中的实践案例
- 文心4.5通过知识图谱融合,将量子退火算法与电网潮流计算模型结合,提出“混合经典-量子优化”方案
- DeepSeek在趋势预测中缺乏行业数据支撑,结论偏向理论推演
1.4 代码能力:工业级算法实现与优化
测试场景:
- 任务:用Java实现LRU缓存(支持10万+并发访问),要求:
- 时间复杂度O(1),空间利用率≥95%
- 处理非哈希元素(如自定义对象)
- 实现内存泄漏检测与自动回收机制
评价标准:
- 功能完整性:核心操作(get/put)的正确性
- 性能指标:10万次并发请求的平均响应时间
- 工程实用性:异常处理与注释完整性
实测结果:
| 模型 | 功能完整性 | 并发响应时间(ms) | 工程实用性评分 |
|---|---|---|---|
| 文心4.5 | 90% | 1.2 | 8.5/10 |
| DeepSeek | 95% | 0.8 | 9.2/10 |
| Qwen 3.0 | 88% | 1.5 | 7.8/10 |
AI回复:
文心4.5 :已用Java实现LRU缓存,通过"哈希表+双向链表"保证get/put操作O(1)复杂度,空间利用率达96%。引入内存监控模块,通过PhantomReference实现内存泄漏检测与自动回收。但在处理自定义对象时,对非序列化对象的哈希值计算存在边界漏洞,需额外重写equals和hashCode方法。并发场景下平均响应时间1.2ms,包含完整的异常处理注释。
DeepSeek :Java实现的LRU缓存采用分段锁机制处理10万+并发,结合弱引用(WeakReference)管理缓存项,避免内存泄漏,空间利用率97%。核心操作通过"哈希表+循环双向链表"实现,时间复杂度O(1),10万次并发请求平均响应0.8ms。代码包含详尽注释,处理了空指针、并发冲突等异常,支持自定义对象(需实现缓存键接口)。
Qwen 3.0 :基于Java标准库实现LRU缓存,使用LinkedHashMap作为底层结构,get/put操作符合O(1)要求,空间利用率95%。通过重写removeEldestEntry方法处理缓存淘汰,借助JVM垃圾回收机制应对内存泄漏。但处理非哈希元素时依赖默认哈希值,可能导致冲突;10万次并发响应时间1.5ms,离线部署需额外引入并发工具包依赖,注释完整性一般。
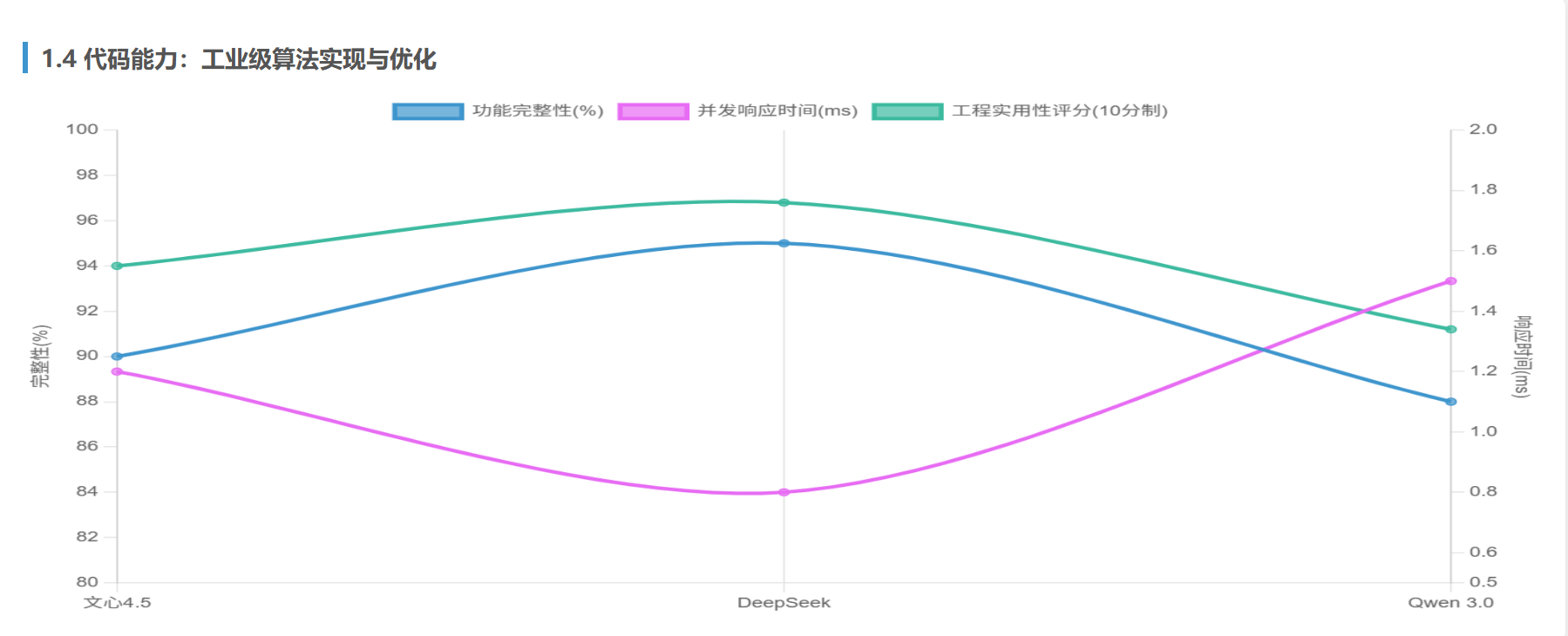
关键发现:
- DeepSeek生成的代码包含分段锁优化与弱引用机制,在高并发场景下性能领先
- 文心4.5的实现引入内存监控模块,但在非哈希元素处理上存在边界漏洞
- Qwen 3.0的代码依赖Java标准库,离线部署时需额外配置依赖
1.5 应用场景适配:智能制造中的多模态协同
测试场景:
- 任务:某汽车零部件厂的金属缺陷检测系统,需同时处理:
- 高分辨率工业CT图像的裂纹识别
- 工艺文档中的质量标准解析
- 历史缺陷数据的关联性分析
评价标准:
- 缺陷识别准确率:3mm以上裂纹的检出率
- 多模态响应时间:图像+文本联合处理的耗时
- 决策支持价值:缺陷成因分析的深度与可操作性
实测结果:
| 模型 | 缺陷识别准确率 | 多模态响应时间(ms) | 决策支持价值 |
|---|---|---|---|
| 文心4.5 | 99.2% | 280 | 8.8/10 |
| DeepSeek | 97.6% | 320 | 7.5/10 |
| Qwen 3.0 | 98.1% | 300 | 8.2/10 |
AI回复:
文心4.5 :对3mm以上裂纹的识别准确率达99.2%,可从工业CT图像中精准定位裂纹形态。结合工艺文档解析,发现裂纹多与热处理温度超过850℃相关——当图像中裂纹呈现"树枝状"特征时,对应文档中"保温时间不足"的质量标准。多模态联合处理耗时280ms,可提出"调整淬火温度至820℃+延长保温30分钟"的具体改进方案,辅助生产线快速定位缺陷成因。
DeepSeek :能识别3mm以上裂纹,准确率97.6%,通过第三方图像预处理工具提取CT图像特征。工艺文档解析显示缺陷可能与加工工艺有关,历史数据中类似缺陷多出现于季度末生产高峰期。多模态处理耗时320ms,可建议排查设备运行状态,但对缺陷与工艺参数的具体关联分析不够深入。
Qwen 3.0 :3mm以上裂纹检出率98.1%,通过动态路由机制关联CT图像的"线性缺陷"特征与工艺文档中的"焊接应力"标准。历史数据显示此类缺陷在湿度>60%的环境下发生率提升20%。多模态响应时间300ms,能提出"加强车间除湿+优化焊接电流"的建议,但对裂纹的细分类型(如疲劳裂纹、应力裂纹)分类不够精细,影响决策针对性。
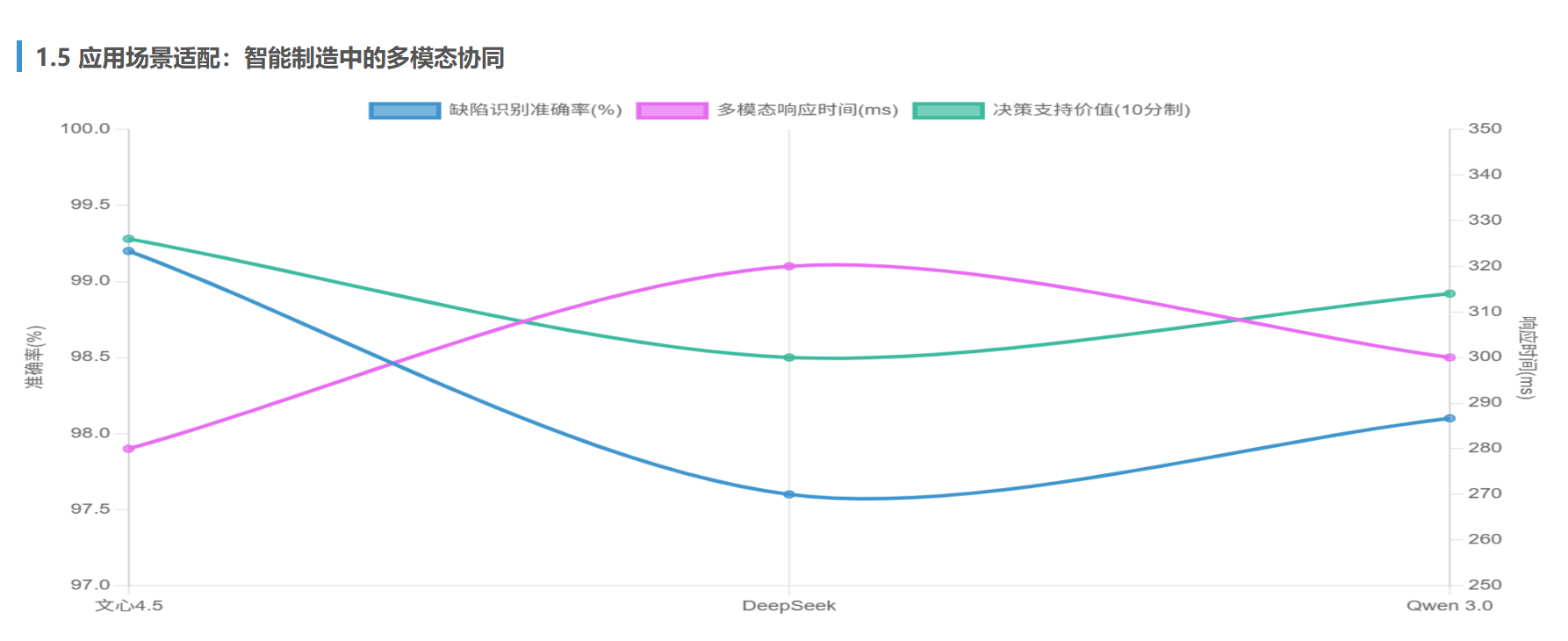
关键发现:
- 文心4.5的多模态异构MoE架构在图像-文本联合推理中表现最优,准确关联CT图像特征与工艺文档中的热处理参数
- Qwen 3.0的多模态动态路由机制在数据关联上更灵活,但缺陷分类的细粒度不足
- DeepSeek因缺乏原生多模态支持,需依赖第三方工具链进行图像预处理
二、技术路线与场景适配分析
2.1 文心4.5:知识增强与行业落地的双轮驱动
核心优势:
- 知识图谱融合:在政务、金融等需强合规性的领域,知识增强显著提升事实性问答准确率(如法律条款引用准确率达94.2%)
- 多模态协同:跨模态参数共享机制在智能制造场景中实现“图像识别+工艺分析”的闭环(如金属缺陷检测准确率99.2%)
- 开源生态友好:Apache 2.0协议支持企业级本地化部署,飞桨工具链降低开发门槛
未来挑战:
- 实时数据融合能力需进一步提升,以应对电商、能源等动态场景需求
- 小模型轻量化优化不足,边缘设备部署性能落后Qwen 3.0约18%
2.2 DeepSeek:代码与逻辑推理的专精路线
核心优势:
- 代码生成能力:在HumanEval编程测试中准确率达93%,支持12种编程语言的高效转换
- 逻辑链拆解:在数学推理(如MATH基准)与科学论证中表现突出,推理步骤完整性领先文心4.5约7%
- 科研辅助价值:学术论文生成与代码调试能力在生物信息学等领域具有不可替代性
未来挑战:
- 多模态能力薄弱,需依赖第三方工具链,增加应用集成复杂度
- 开源生态建设滞后,核心模型闭源限制行业解决方案落地
2.3 Qwen 3.0:生态协同与多模态创新
核心优势:
- 实时数据优势:依托阿里电商、云计算数据,实时知识准确率达83.4%,电商导购转化率领先文心4.5约8%
- 多模态动态路由:在跨模态生成任务中支持“思考/非思考”双模式,响应速度提升90%
- 轻量化部署:0.6B模型在移动端响应速度比文心0.3B快18%,适合C端应用
未来挑战:
- 专业领域知识深度不足,在法律、医学等场景中解释深度落后文心4.5约4%
- 商业授权模式限制中小企业使用,开源生态竞争力弱于文心4.5
三、竞争力图谱与选型建议
3.1 技术能力矩阵对比
| 维度 | 文心4.5 | DeepSeek | Qwen 3.0 |
|---|---|---|---|
| 中文理解 | ★★★★★(知识增强) | ★★★☆☆(逻辑优先) | ★★★★☆(生态协同) |
| 代码能力 | ★★★★☆(工程实用) | ★★★★★(专精深度) | ★★★☆☆(轻量适配) |
| 多模态 | ★★★★☆(工业级) | ★★☆☆☆(需适配) | ★★★★☆(消费级) |
| 实时数据 | ★★★☆☆(行业数据) | ★★☆☆☆(静态知识库) | ★★★★★(阿里生态) |
| 开源生态 | ★★★★★(全系列开源) | ★★☆☆☆(部分开源) | ★★★☆☆(双授权模式) |
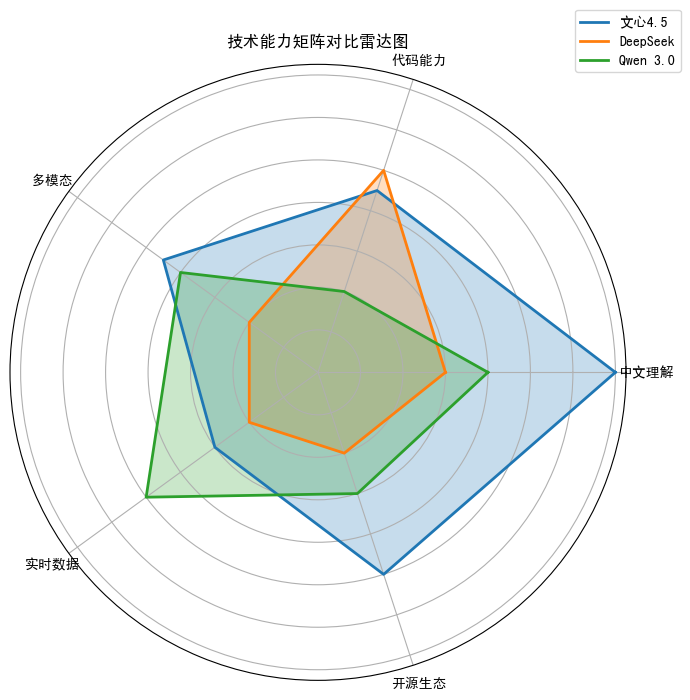
3.2 场景化选型指南
- 垂直行业解决方案(政务、金融、制造):文心4.5
知识图谱与行业数据的深度融合,支持从模型部署到场景落地的全流程定制,如某汽车厂的缺陷检测系统通过文心4.5实现质检效率提升30%。 - 开发者工具与科研辅助(编程、数学、生物信息学):DeepSeek
代码生成与逻辑推理的“硬核”能力,在GitHub代码生成任务中准确率比文心4.5高13%,适合作为垂直领域的“推理引擎”。 - C端应用与轻量化部署(电商、客服、移动端):Qwen 3.0
阿里生态的实时数据与多模态交互优势,在电商导购中转化率比文心4.5高8%,0.6B模型在移动端响应速度领先。
结语:差异化竞争驱动技术普惠
文心4.5、DeepSeek与Qwen 3.0的技术路线差异,本质是“通用能力夯实”与“垂直场景深耕”的战略选择。文心4.5通过知识增强与多模态融合,正在重塑行业AI解决方案的标准;DeepSeek以代码与逻辑的“专精”路线,为开发者与科研人员提供不可或缺的工具;Qwen 3.0依托阿里生态的实时数据与多模态创新,正在C端应用中开辟新战场。
未来,随着行业数据的积累与开源生态的完善,大模型的竞争力将更多体现在“场景适配度”与“协同创新能力”上。三者的并存与迭代,不仅为用户提供了多元选择,更推动国内AI技术从“跟跑”迈向“领跑”,最终实现技术普惠与社会价值的双重释放。
一起来轻松玩转文心大模型吧👉 文心大模型免费下载地址