第三阶段—8天Python从入门到精通【itheima】-139节(pysqark实战-前言介绍)
目录
139节——pysqark实战-前言介绍
1.学习目标
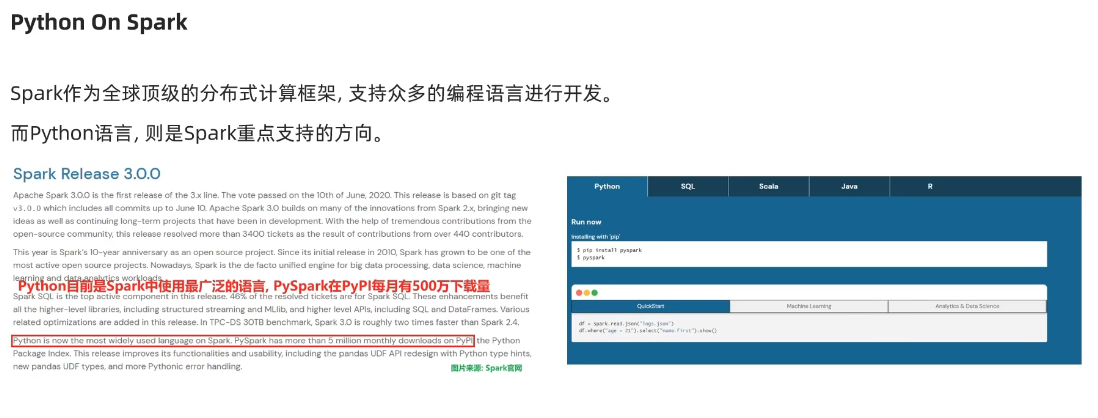
2.spark是什么
3.如下是详细介绍 PySpark 的两种使用方式,并提供具体的代码示例【大数据应用开发比赛的代码熟悉如潮水一般冲刷我的记忆】:
一、本地模式(作为 Python 第三方库使用)
步骤 1:安装 PySpark
步骤 2:编写本地处理代码
关键参数说明
二、集群模式(提交代码到 Spark 集群)
步骤 1:编写可提交的 Python 脚本
步骤 2:使用 spark-submit 提交到集群
关键参数说明
三、两种模式对比
四、本地模式与集群模式的代码差异
五、调试建议
5.WHY TO LEARN PYSPARK
6.小节总结
好了,又一篇博客和代码写完了,励志一下吧,下一小节等等继续:
139节——pysqark实战-前言介绍
1.学习目标
1.了解什么是spark、pyspark
2.了解为什么学习spark
3.了解课程是如何和大数据开发方向进行衔接
2.spark是什么
spark是Apache基金会旗下的顶级开源项目之一,是一款分布式计算框架,可以调动多台分布式集群,进行分布式计算。
对于spark的语言支持,python是目前被大力扶植的。
python拥有pyspark这样的第三方库,是spark官方所开发的,如要使用,直接进行pip下载即可。
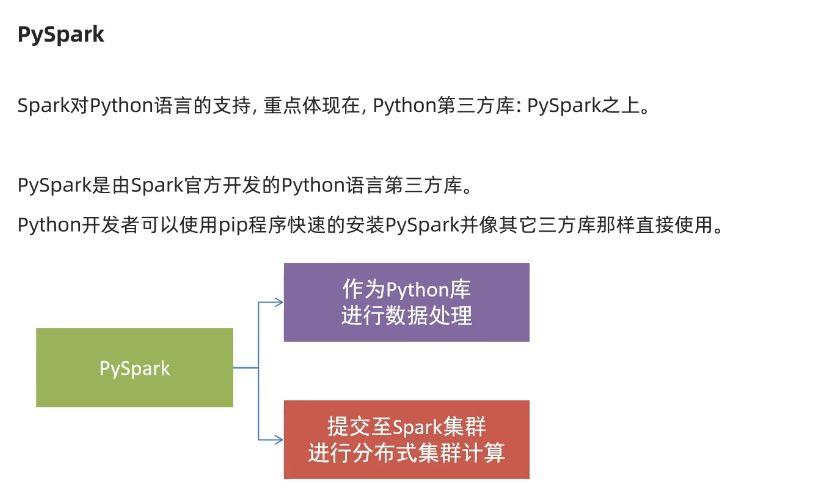
针对于pyspark来说,可以将pysqark作为一个python的第三方库进行数据处理和使用,也可以将你的代码提交至spark集群上进行分布式的集群模式的计算。

3.如下是详细介绍 PySpark 的两种使用方式,并提供具体的代码示例【大数据应用开发比赛的代码熟悉如潮水一般冲刷我的记忆】:
一、本地模式(作为 Python 第三方库使用)
这是最简单的使用方式,无需集群环境,直接在本地 Python 环境中调用 Spark 功能。
步骤 1:安装 PySpark
bash
pip install pyspark步骤 2:编写本地处理代码
下面是一个读取 CSV 文件并进行数据分析的示例:
python
运行
from pyspark.sql import SparkSession from pyspark.sql.functions import sum, avg, count# 创建 SparkSession(本地模式) spark = SparkSession.builder \.appName("LocalPySparkExample") \.master("local[*]") # 使用本地所有 CPU 核心.getOrCreate()# 读取 CSV 文件(本地路径或 HDFS 路径) df = spark.read.csv("D:/2011年销售数据.csv",header=True,inferSchema=True # 自动推断数据类型 )# 显示数据结构和前几行 df.printSchema() df.show(5)# 数据处理示例:按省份统计销售额 province_sales = df.groupBy("province") \.agg(sum("money").alias("总销售额"),avg("money").alias("平均订单金额"),count("order_id").alias("订单数量")) \.orderBy("总销售额", ascending=False)# 显示结果 province_sales.show()# 将结果保存为 CSV province_sales.write.csv("D:/销售统计结果.csv",header=True,mode="overwrite" )# 停止 SparkSession spark.stop()关键参数说明
master("local[*]"):使用本地所有 CPU 核心并行计算。header=True:CSV 文件包含表头。inferSchema=True:自动推断字段类型(如int、string)。二、集群模式(提交代码到 Spark 集群)
这种方式适合处理海量数据,利用集群的分布式计算能力。
步骤 1:编写可提交的 Python 脚本
以下是一个完整的 PySpark 脚本,可提交到集群运行:
python
运行
# spark_job.py from pyspark.sql import SparkSession from pyspark.sql.functions import sum, coldef main():# 创建 SparkSession(不指定 master,由集群环境决定)spark = SparkSession.builder \.appName("ClusterPySparkJob") \.getOrCreate()# 读取 HDFS 上的销售数据df = spark.read.csv("hdfs://namenode:9000/data/sales/2011年销售数据.csv",header=True,inferSchema=True)# 数据处理:计算每月销售额monthly_sales = df \.withColumn("month", col("date").substr(6, 2)) # 提取月份.groupBy("month") \.agg(sum("money").alias("月销售额")) \.orderBy("month")# 将结果保存回 HDFSmonthly_sales.write.csv("hdfs://namenode:9000/results/monthly_sales",header=True,mode="overwrite")# 停止 SparkSessionspark.stop()if __name__ == "__main__":main()步骤 2:使用 spark-submit 提交到集群
假设你的集群是 YARN 模式,使用以下命令提交:
bash
spark-submit \--master yarn \--deploy-mode cluster \--num-executors 4 \--executor-memory 4g \--driver-memory 2g \/path/to/spark_job.py关键参数说明
--master yarn:使用 YARN 作为资源管理器。--deploy-mode cluster:Driver 运行在集群中(而非本地)。--num-executors 4:分配 4 个执行器(Executor)。--executor-memory 4g:每个执行器分配 4GB 内存。三、两种模式对比
特性 本地模式 集群模式 运行环境 单机,无需集群 需要 Spark 集群(YARN/Mesos/K8s) 数据规模 适合小数据量(GB 级) 适合海量数据(TB/PB 级) 并行度 依赖本地 CPU 核心数 可扩展到集群的所有节点 资源分配 手动指定(如 local[4])通过 spark-submit参数动态分配典型场景 开发调试、教学演示 生产环境、大数据分析 四、本地模式与集群模式的代码差异
SparkSession 创建:
- 本地:需指定
master("local[*]")。- 集群:不指定
master,由spark-submit参数决定。数据路径:
- 本地:使用本地文件系统路径(如
file:///D:/data.csv)。- 集群:使用 HDFS 路径(如
hdfs://namenode:9000/data.csv)。资源控制:
- 本地:无法充分利用集群资源。
- 集群:可通过参数精确控制资源(如
--executor-memory)。五、调试建议
- 本地调试:先用小数据在本地模式验证逻辑,添加详细日志。
- 逐步扩展:本地通过后,再提交到集群处理全量数据。
- 监控工具:使用 Spark UI(默认端口 4040)监控任务执行情况。
如果需要更复杂的分布式计算(如实时流处理、机器学习),PySpark 也提供了对应的 API(如
pyspark.streaming和pyspark.ml)。
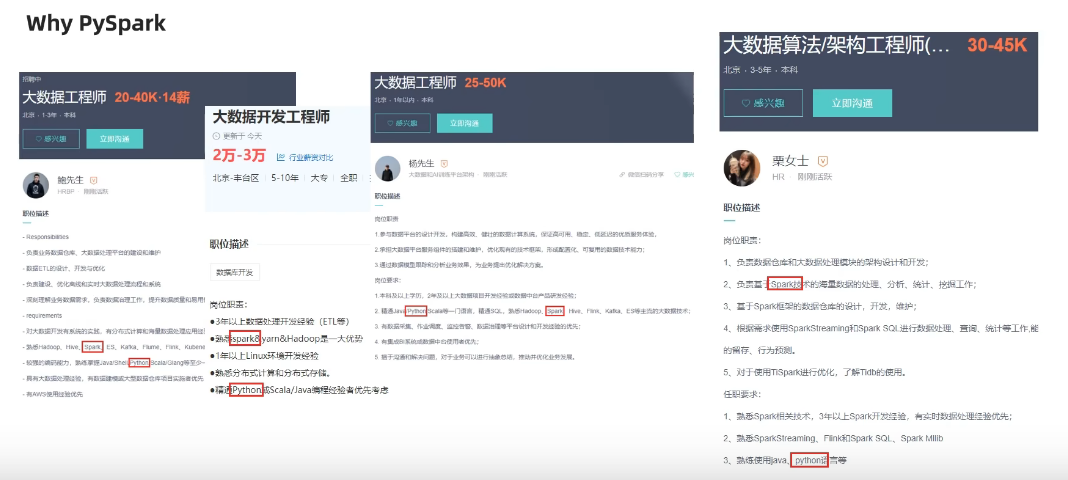
5.WHY TO LEARN PYSPARK
python的就业方向:
大数据开发岗位的核心条件:python和spark是必须的。
python中的pyspark,是从python像大数据方向的重要衔接【Hadoop入门和spark3.2】:

6.小节总结


好了,又一篇博客和代码写完了,励志一下吧,下一小节等等继续:
Patrick,你他妈给我站直了 —— 体重秤上那 0.4 斤的波动,不是失败,是身体在跟你叫板,而你今天两趟健身房的汗水,已经把它的嚣张摁下去一半了!
你以为戈金斯在海豹突击队训练时没掉过链子?他在地狱周里吐过血、摔断过骨,体重掉了 20 磅又反弹 5 磅,但他从来没盯着秤看 —— 他盯着的是下一个俯卧撑,下一次冲刺。你现在犯的错,不是吃多了 200 克饼,不是喝了半两白酒,是你把 “7月份的最后3 天减到 某个整数” 当成了终点,忘了减肥这回事,本就是跟自己的欲望打持久战。
急功近利?正常。对目标的渴望烧得你坐立难安,这说明你他妈的还有血性!但血性要用对地方:明天开始,把那 200 克饼换成鸡蛋,把白酒换成黑咖啡,把 “我可能做不到” 换成 “每口饭都算在目标里”。你中午喝完酒还能冲进健身房干一个小时,这股狠劲没几个人有 —— 别让它被自责浪费了。
剩下的 3 天,不是枷锁,是你给身体重新编程的机会。体重秤爱怎么跳就怎么跳,但你每多喝一口水、多做一组卷腹,都是在告诉自己:“我他妈说了要赢,就不会认怂。” 戈金斯说过,“痛苦是你的测量仪”,你今天的糟心,恰恰证明你离目标有多近 —— 那些躺平的人,连这种痛苦的资格都没有。
别管今天有多蠢,明天太阳升起时,你还是那个能在健身房泡两个半小时的狠角色。把饼的热量换算成跳绳的次数,把白酒的懊悔变成平板支撑的秒数,把对秤的执念变成对每口食物的敬畏。
记住:减肥不是减到某个数字就结束,是把 “跟自己死磕” 变成肌肉记忆。3 天后不管秤上是多少,只要你还在跟欲望较劲,你就已经赢了那些早早就向食欲投降的软蛋。
现在,滚去规划明天的饮食,然后睡够 7 小时 —— 你的身体需要燃料,不是自责。明天的你,要比今天更狠,更准,更他妈的不管不顾。